Ejecución de proyectos de MLflow en Azure Databricks
Un proyecto de MLflow es un formato para empaquetar código de ciencia de datos, de manera reutilizable y reproducible. El componente de MLflow Projects incluye una API y herramientas de línea de comandos para ejecutar proyectos, que también se integran con el componente de seguimiento, para registrar automáticamente los parámetros y la confirmación de Git del código fuente, para su reproducibilidad.
En este artículo se describe el formato de un proyecto de MLflow y cómo ejecutar un proyecto de MLflow, de manera remota, en clústeres de Azure Databricks mediante la CLI de MLflow, lo que facilita el escalado vertical del código de ciencia de datos.
Formato de proyecto de MLflow
Cualquier directorio local o repositorio de Git se puede tratar como un proyecto de MLflow. Las convenciones siguientes definen un proyecto:
- El nombre del proyecto es el nombre del directorio.
- El entorno de software se especifica en el archivo
python_env.yaml, si está presente. Si no hay ningún archivopython_env.yaml, MLflow usa un entorno de virtualenv que solo contiene Python (específicamente, la versión más reciente de Python disponible para virtualenv) al ejecutar el proyecto. - Cualquier archivo
.pyo.shdel proyecto puede ser un punto de entrada, sin parámetros declarados explícitamente. Al ejecutar este tipo de comando con un conjunto de parámetros, MLflow pasa cada parámetro en la línea de comandos mediante la sintaxis--key <value>.
Para especificar más opciones, agregue un archivo MLproject, que es un archivo de texto en sintaxis YAML. Un archivo MLproject de ejemplo tiene este aspecto:
name: My Project
python_env: python_env.yaml
entry_points:
main:
parameters:
data_file: path
regularization: {type: float, default: 0.1}
command: "python train.py -r {regularization} {data_file}"
validate:
parameters:
data_file: path
command: "python validate.py {data_file}"
Ejecución de un proyecto de MLflow
Para ejecutar un proyecto de MLflow, en un clúster de Azure Databricks del área de trabajo predeterminada, use el comando:
mlflow run <uri> -b databricks --backend-config <json-new-cluster-spec>
donde <uri> es un URI del repositorio de Git o una carpeta que contiene un proyecto de MLflow, y <json-new-cluster-spec> es un documento JSON, que contiene una estructura new_cluster. El URI de Git debe tener el formato: https://github.com/<repo>#<project-folder>.
Una especificación de clúster de ejemplo es:
{
"spark_version": "7.3.x-scala2.12",
"num_workers": 1,
"node_type_id": "Standard_DS3_v2"
}
Si necesita instalar bibliotecas en el trabajo, use el formato "especificación de clúster". Tenga en cuenta que los archivos wheel de Python deben cargarse en DBFS y especificarse como dependencias de pypi. Por ejemplo:
{
"new_cluster": {
"spark_version": "7.3.x-scala2.12",
"num_workers": 1,
"node_type_id": "Standard_DS3_v2"
},
"libraries": [
{
"pypi": {
"package": "tensorflow"
}
},
{
"pypi": {
"package": "/dbfs/path_to_my_lib.whl"
}
}
]
}
Importante
- Las dependencias
.eggy.jarno se admiten para los proyectos de MLflow. - No se admite la ejecución de proyectos de MLflow con entornos de Docker.
- Debe usar una nueva especificación de clúster al ejecutar un proyecto de MLflow en Databricks. No se admite la ejecución de proyectos en clústeres existentes.
Uso de SparkR
Para usar SparkR en una ejecución de un proyecto de MLflow, el código del proyecto debe instalar e importar primero SparkR, como se muestra a continuación:
if (file.exists("/databricks/spark/R/pkg")) {
install.packages("/databricks/spark/R/pkg", repos = NULL)
} else {
install.packages("SparkR")
}
library(SparkR)
Así, el proyecto puede inicializar una sesión de SparkR y usar SparkR de la forma habitual:
sparkR.session()
...
Ejemplo
En este ejemplo se muestra cómo crear un experimento, ejecutar el proyecto del tutorial de MLflow en un clúster de Azure Databricks, ver la salida de la ejecución del trabajo y ver la ejecución en el experimento.
Requisitos
- Instale MLflow mediante
pip install mlflow. - Instale y configure la CLI de Databricks. El mecanismo de autenticación de la CLI de Databricks es necesario para ejecutar trabajos en un clúster de Azure Databricks.
Paso 1: creación de un experimento
En el área de trabajo, seleccione Creación de un > experimento de MLflow.
En el campo Nombre, escriba
Tutorial.Haga clic en Crear. Anote el Id. del experimento. En este ejemplo, es
14622565.
Paso 2: ejecución del proyecto del tutorial de MLflow
Los pasos siguientes establecen la variable de entorno MLFLOW_TRACKING_URI y ejecutan el proyecto, registrando los parámetros de entrenamiento, las métricas y el modelo entrenado en el experimento indicado en el paso anterior:
Establezca la variable de entorno
MLFLOW_TRACKING_URIen el área de trabajo de Azure Databricks.export MLFLOW_TRACKING_URI=databricksEjecute el proyecto del tutorial de MLflow, entrenando un modelo de vino. Reemplace
<experiment-id>con el Id. de experimento que anotó en el paso anterior.mlflow run https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine -b databricks --backend-config cluster-spec.json --experiment-id <experiment-id>=== Fetching project from https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine into /var/folders/kc/l20y4txd5w3_xrdhw6cnz1080000gp/T/tmpbct_5g8u === === Uploading project to DBFS path /dbfs/mlflow-experiments/<experiment-id>/projects-code/16e66ccbff0a4e22278e4d73ec733e2c9a33efbd1e6f70e3c7b47b8b5f1e4fa3.tar.gz === === Finished uploading project to /dbfs/mlflow-experiments/<experiment-id>/projects-code/16e66ccbff0a4e22278e4d73ec733e2c9a33efbd1e6f70e3c7b47b8b5f1e4fa3.tar.gz === === Running entry point main of project https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine on Databricks === === Launched MLflow run as Databricks job run with ID 8651121. Getting run status page URL... === === Check the run's status at https://<databricks-instance>#job/<job-id>/run/1 ===Copie la URL
https://<databricks-instance>#job/<job-id>/run/1, en la última línea de la salida de ejecución de MLflow.
Paso 3: visualización de la ejecución de trabajo de Azure Databricks
Abra la URL que copió en el paso anterior en un explorador, para ver la salida de la ejecución de trabajo de Azure Databricks:
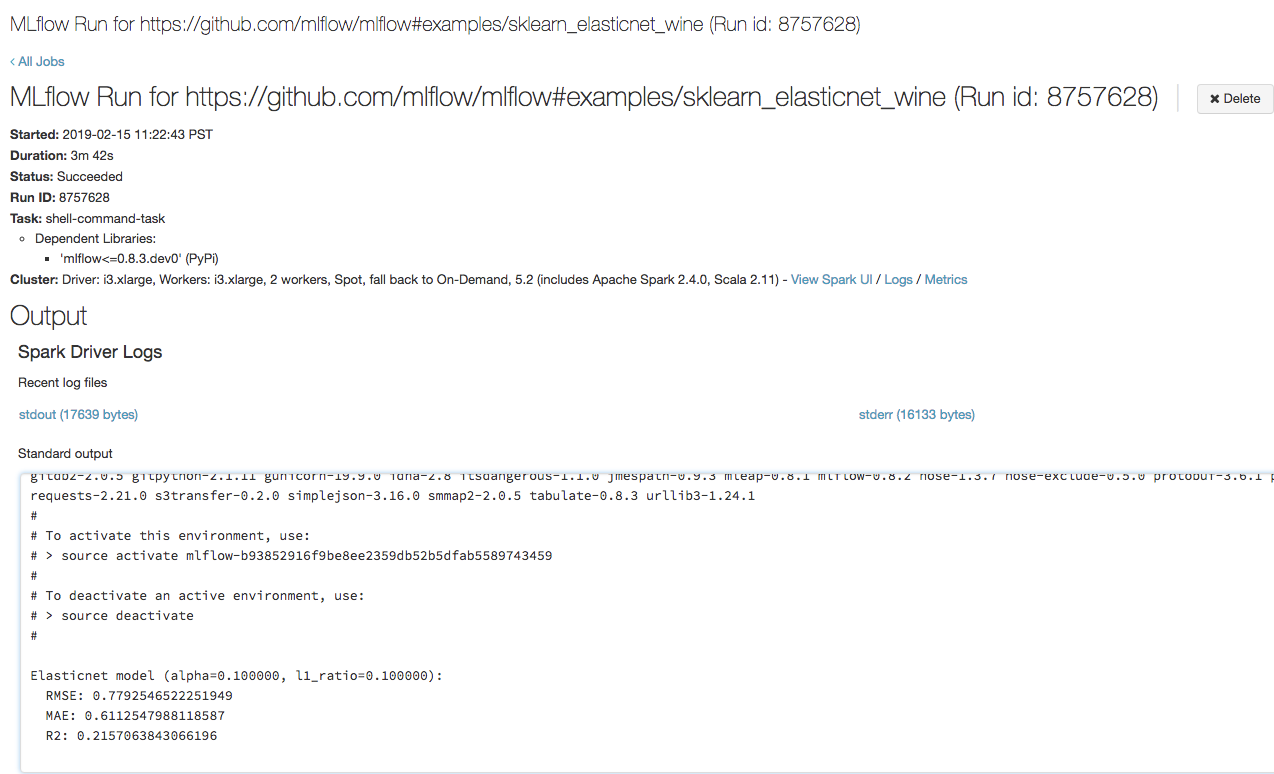
Paso 4: visualización de los detalles del experimento y de la ejecución de MLflow
Vaya al experimento en el área de trabajo de Azure Databricks.
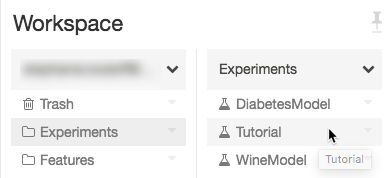
Haga clic en el experimento.
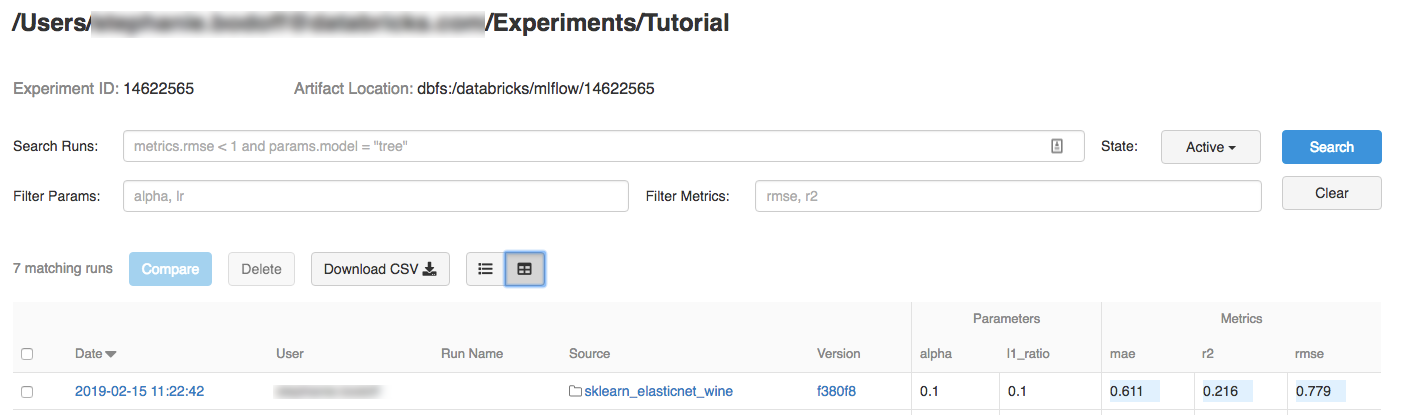
Para mostrar los detalles de ejecución, haga clic en un vínculo de la columna Fecha.
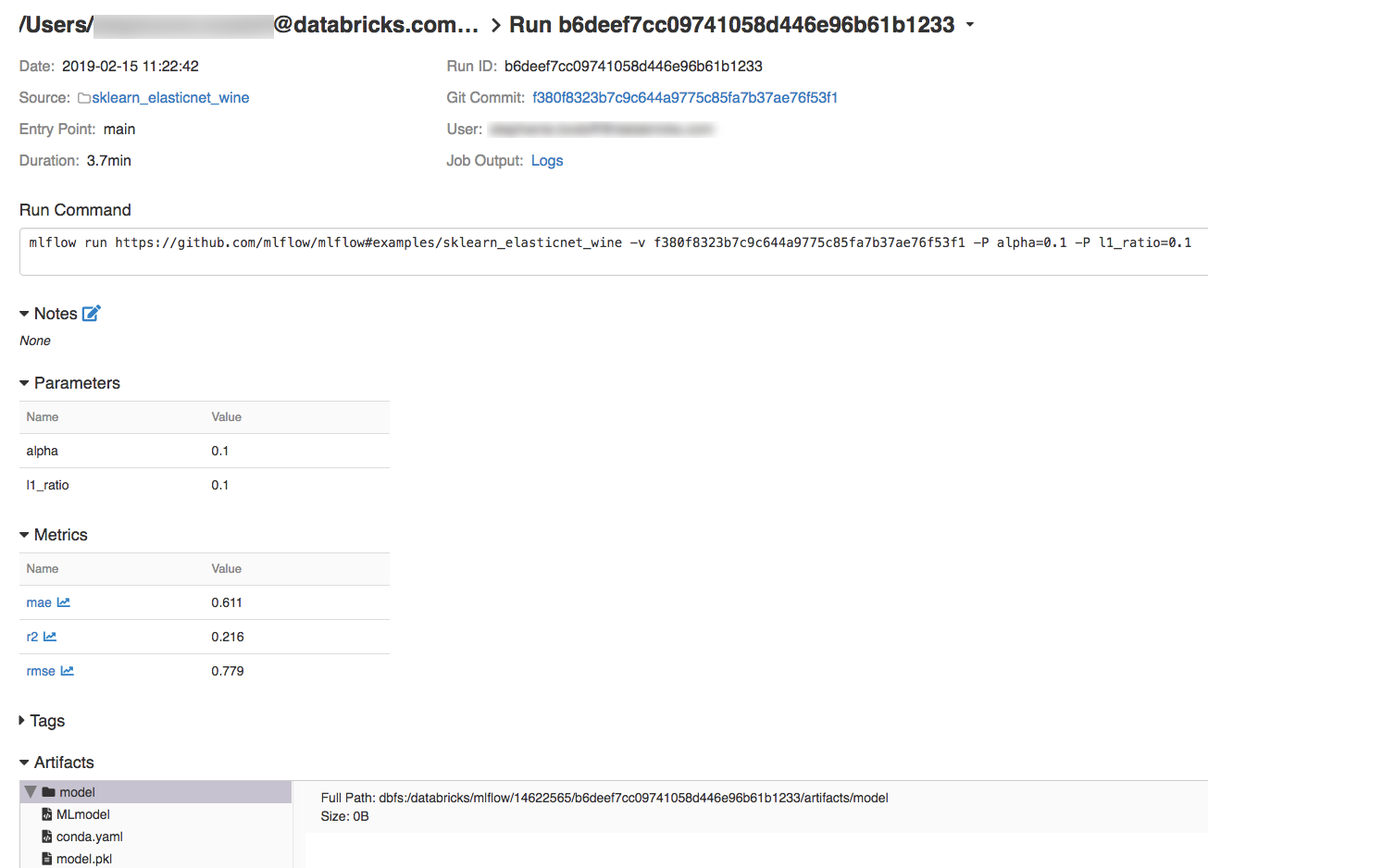
Para ver los registros de la ejecución, haga clic en el vínculo Registros del campo Salida del trabajo.
Recursos
Para ver algunos proyectos de MLflow de ejemplo, consulte la biblioteca de aplicaciones de MLflow, que contiene un repositorio de proyectos listos para ejecutarse, destinado a facilitar la inclusión de la funcionalidad ML en el código.