Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Nota:
En esta documentación se describe el Registro de modelos del área de trabajo. Azure Databricks recomienda usar Modelos del catálogo de Unity. Los modelos del catálogo de Unity proporcionan gobernanza de modelos centralizada, acceso entre áreas de trabajo, linaje e implementación. El Registro de modelos del área de trabajo quedará en desuso en el futuro.
En este ejemplo, se muestra cómo usar el registro de modelos del área de trabajo para crear una aplicación de aprendizaje automático que realice la previsión de la salida de energía diaria de un granja eólica. En el ejemplo se muestra cómo:
- Seguimiento y registro de modelos con MLflow
- Registro de modelos en el Registro de Modelos
- Describir modelos y realizar transiciones de fase de la versión del modelo
- Integración de modelos registrados con aplicaciones de producción
- Búsqueda y detección de modelos en el registro de modelos
- Archivado y eliminación de modelos
En el artículo se describe cómo realizar estos pasos mediante las interfaces de usuario y las API de seguimiento de MLflow y del Registro de Modelos de MLflow.
Para obtener un cuaderno que realice todos estos pasos mediante el seguimiento de MLflow y las API del registro, consulte el cuaderno de ejemplo del registro de modelos.
Carga del conjunto de datos, entrenamiento del modelo y seguimiento con MLflow
Para poder registrar un modelo en el registro de modelos, primero debe entrenar y registrar el modelo durante la ejecución de un experimento. En esta sección, se muestra cómo cargar el conjunto de datos de la granja eólica, entrenar un modelo y registrar la ejecución de entrenamiento en MLflow.
Carga del conjunto de datos
El código siguiente carga un conjunto de datos que contiene datos meteorológicos e información de la salida de energía de un granja eólica en los Estados Unidos. El conjunto de datos contiene las características wind direction, wind speed y air temperature muestreadas cada seis horas (una vez a las 00:00, otra a las 08:00 y otra a las 16:00), así como la salida de energía agregada diaria (power), a lo largo de varios años.
import pandas as pd
wind_farm_data = pd.read_csv("https://github.com/dbczumar/model-registry-demo-notebook/raw/master/dataset/windfarm_data.csv", index_col=0)
def get_training_data():
training_data = pd.DataFrame(wind_farm_data["2014-01-01":"2018-01-01"])
X = training_data.drop(columns="power")
y = training_data["power"]
return X, y
def get_validation_data():
validation_data = pd.DataFrame(wind_farm_data["2018-01-01":"2019-01-01"])
X = validation_data.drop(columns="power")
y = validation_data["power"]
return X, y
def get_weather_and_forecast():
format_date = lambda pd_date : pd_date.date().strftime("%Y-%m-%d")
today = pd.Timestamp('today').normalize()
week_ago = today - pd.Timedelta(days=5)
week_later = today + pd.Timedelta(days=5)
past_power_output = pd.DataFrame(wind_farm_data)[format_date(week_ago):format_date(today)]
weather_and_forecast = pd.DataFrame(wind_farm_data)[format_date(week_ago):format_date(week_later)]
if len(weather_and_forecast) < 10:
past_power_output = pd.DataFrame(wind_farm_data).iloc[-10:-5]
weather_and_forecast = pd.DataFrame(wind_farm_data).iloc[-10:]
return weather_and_forecast.drop(columns="power"), past_power_output["power"]
Entrenar modelo
El código siguiente entrena una red neuronal mediante TensorFlow Keras para predecir la salida de energía en función de las características meteorológicas del conjunto de datos. MLflow se usa para realizar un seguimiento de los hiperparámetros, las métricas de rendimiento, el código fuente y los artefactos del modelo.
def train_keras_model(X, y):
import tensorflow.keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
model = Sequential()
model.add(Dense(100, input_shape=(X_train.shape[-1],), activation="relu", name="hidden_layer"))
model.add(Dense(1))
model.compile(loss="mse", optimizer="adam")
model.fit(X_train, y_train, epochs=100, batch_size=64, validation_split=.2)
return model
import mlflow
X_train, y_train = get_training_data()
with mlflow.start_run():
# Automatically capture the model's parameters, metrics, artifacts,
# and source code with the `autolog()` function
mlflow.tensorflow.autolog()
train_keras_model(X_train, y_train)
run_id = mlflow.active_run().info.run_id
Registro y administración del modelo mediante la interfaz de usuario de MLflow
En esta sección:
- Creación de un nuevo modelo registrado
- Exploración de la interfaz de usuario del registro de modelos
- Adición de descripciones de modelos
- Cambiar la versión de un modelo
Creación de un nuevo modelo registrado
Vaya a la barra lateral de Ejecuciones del Experimento de MLflow, para ello, haga clic en el de la barra lateral derecha del cuaderno de Azure Databricks.

Busque el Run de MLflow correspondiente a la sesión de entrenamiento del modelo de TensorFlow Keras y ábralo en la UI de Run de MLflow haciendo clic en el icono Ver detalles de Run.
En la interfaz de usuario de MLflow, desplácese hacia abajo hasta la sección Artifacts (Artefactos) y haga clic en el directorio llamado model. Haga clic en el botón Register Model (Registrar modelo) que aparece.

Seleccione Create New Model (Crear modelo) en el menú desplegable y escriba el siguiente nombre de modelo:
power-forecasting-model.Haga clic en Registrar. Esto registra un nuevo modelo llamado
power-forecasting-modely crea una nueva versión del modelo:Version 1.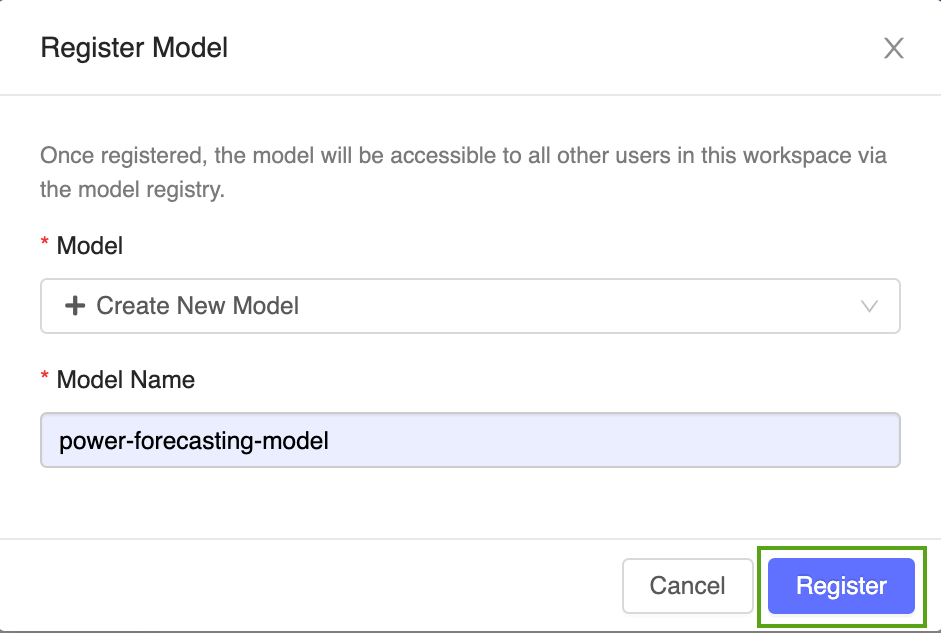
Después de unos momentos, la interfaz de usuario de MLflow muestra un vínculo al nuevo modelo registrado. Siga este vínculo para abrir la nueva versión del modelo en la interfaz de usuario del registro de modelos de MLflow.
Exploración de la interfaz de usuario del registro de modelos
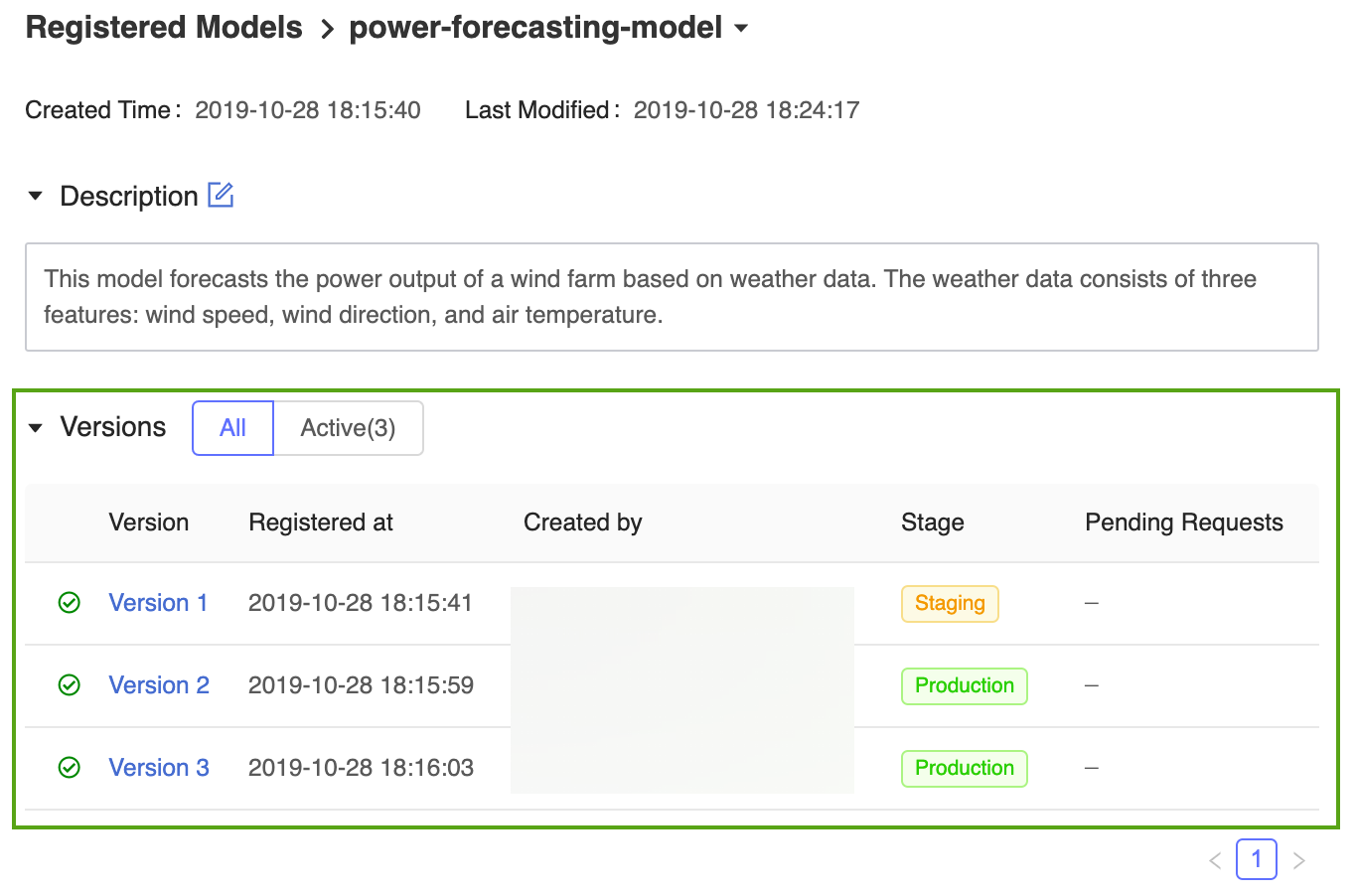
La página de versión del modelo de la interfaz de usuario del Registro de Modelos de MLflow proporciona información sobre la Version 1 del modelo de previsión registrado, incluido su autor, la hora de creación y su etapa actual.
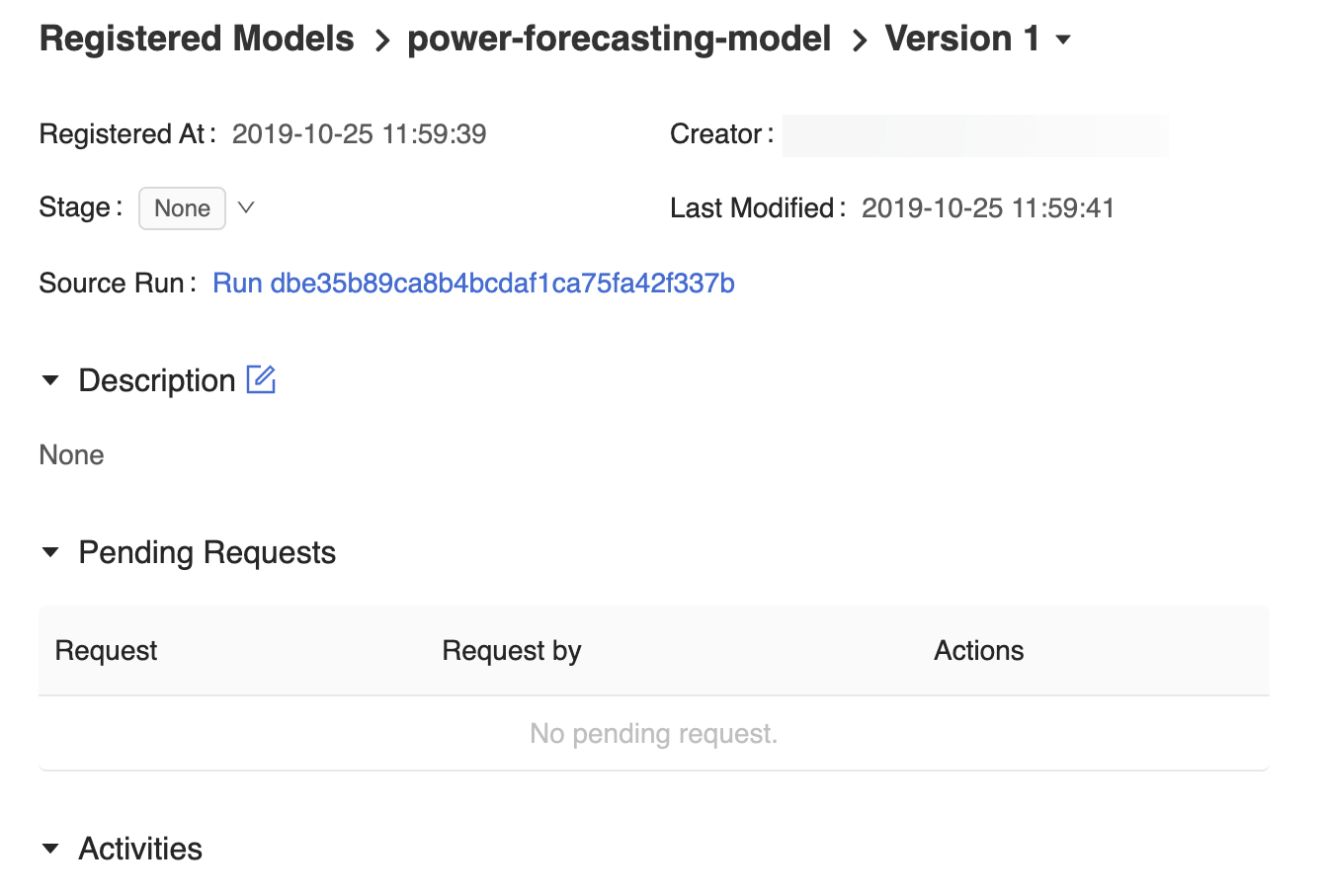
La página de versión del modelo también proporciona el vínculo Source Run (Ejecución de origen), que abre la ejecución de MLflow que se usó para crear el modelo en la interfaz de usuario de ejecución de MLflow. Desde la interfaz de usuario de ejecución de MLflow, puede acceder al enlace del cuaderno Source para ver una instantánea del cuaderno de Azure Databricks que se utilizó para entrenar el modelo.


Para volver al Registro de modelos de MLflow, haga clic en ![]() Modelos en la barra lateral.
Modelos en la barra lateral.
La página principal del registro de modelos de MLflow resultante muestra una lista de todos los modelos registrados en el área de trabajo de Azure Databricks, incluidas sus versiones y fases.
Haga clic en el vínculo power-forecasting-model para abrir la página del modelo registrado, que muestra todas las versiones del modelo de previsión.
Adición de descripciones de modelos
Puede agregar descripciones a los modelos registrados y a las versiones de los modelos. Las descripciones de modelos registrados son útiles para registrar información que se aplica a varias versiones del modelo (por ejemplo, una introducción general del problema de modelado y el conjunto de datos). Las descripciones de la versión del modelo son útiles para detallar los atributos únicos de una versión de modelo determinada (por ejemplo, la metodología y el algoritmo usados para desarrollar el modelo).
Agregue una descripción general al modelo de previsión de energía registrado. Haga clic en el icono
 y escriba la siguiente descripción:
y escriba la siguiente descripción:This model forecasts the power output of a wind farm based on weather data. The weather data consists of three features: wind speed, wind direction, and air temperature.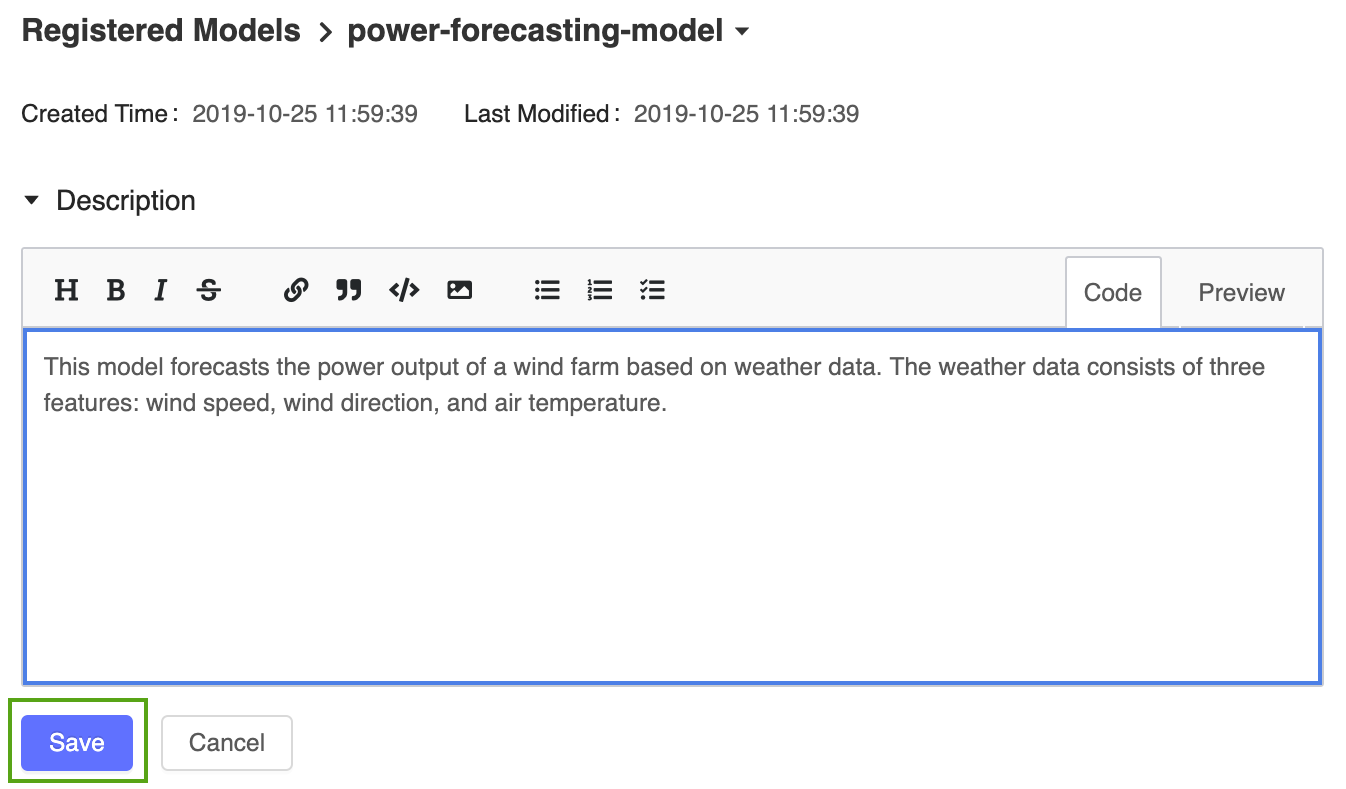
Haga clic en Save(Guardar).
Haga clic en el vínculo Version 1 (Versión 1) de la página del modelo registrado para volver a la página de la versión del modelo.
Haga clic en el icono
y escriba la siguiente descripción:This model version was built using TensorFlow Keras. It is a feed-forward neural network with one hidden layer.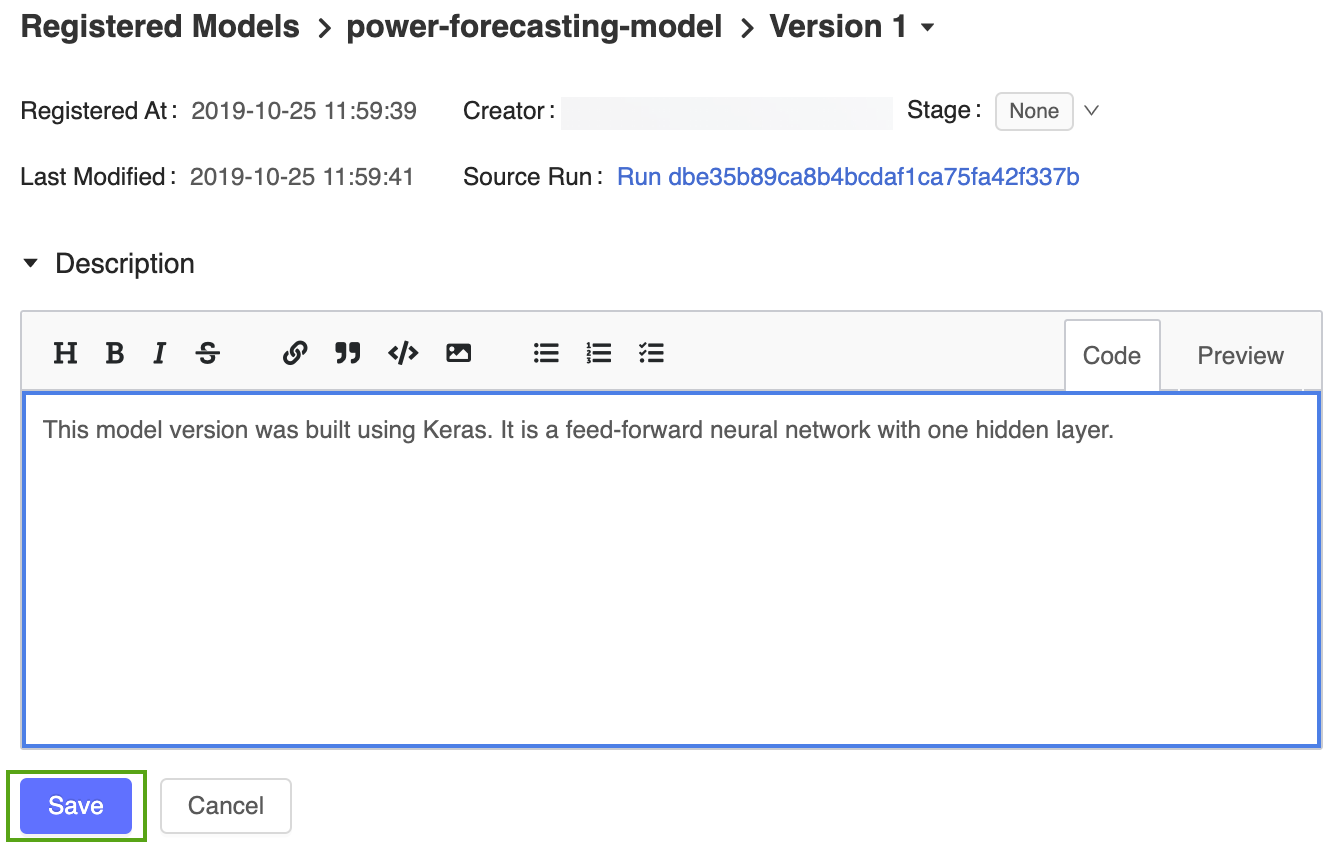
Haga clic en Save(Guardar).
Transicionar una versión del modelo
El registro de modelos de MLflow define varias etapas del modelo: Ninguna, Ensayo, Producción, y Archived. Cada fase tiene un significado único. La fase Staging (Ensayo) está pensada para las pruebas del modelo, mientras que la fase Production (Producción) es para modelos que han completado los procesos de pruebas o revisión, y se han implementado en aplicaciones.
Haga clic en el botón Stage (Fase) para mostrar la lista de fases del modelo disponibles y las opciones de transición de fase disponibles.
Seleccione Transition to -> Production (Transición a -> Producción) y pulse OK (Aceptar) en la ventana de confirmación de la transición de fase para realizar la transición del modelo a Production (Producción).
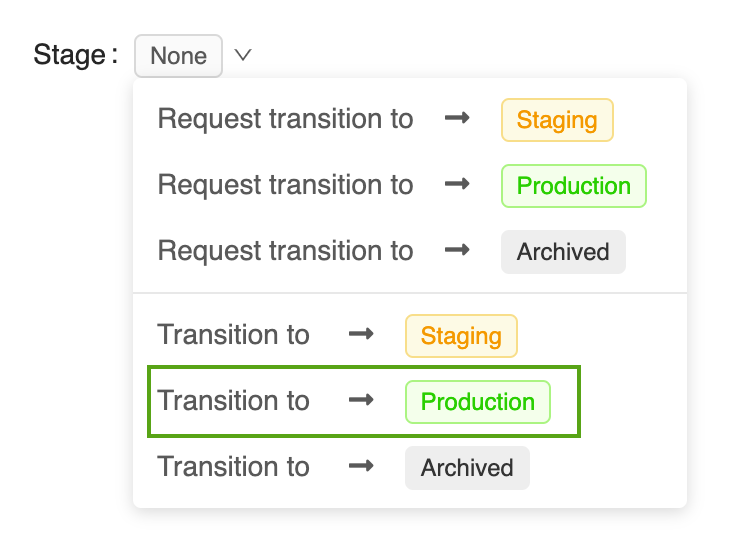
Una vez que la versión del modelo se pasa a Production (Producción), se muestra la fase actual en la interfaz de usuario y se agrega una entrada al registro de actividad para reflejar la transición.


El registro de modelos de MLflow permite que varias versiones del modelo compartan la misma fase. Al hacer referencia a un modelo por fase, el registro de modelos usa la versión del modelo más reciente (la versión del modelo con el identificador de versión más grande). La página del modelo registrado muestra todas las versiones de un modelo determinado.
Registro y administración del modelo mediante la API de MLflow
En esta sección:
- Definir el nombre del modelo mediante programación
- Registro del modelo
- Adición del modelo y las descripciones de las versiones del modelo mediante la API
- Transición de una versión del modelo y recuperación de los detalles mediante la API
Definir el nombre del modelo mediante programación
Ahora que el modelo se ha registrado y pasado a Production (Producción), puede hacer referencia a él mediante las API de programación de MLflow. Defina el nombre del modelo registrado de la siguiente manera:
model_name = "power-forecasting-model"
Registro del modelo
model_name = get_model_name()
import mlflow
# The default path where the MLflow autologging function stores the TensorFlow Keras model
artifact_path = "model"
model_uri = "runs:/{run_id}/{artifact_path}".format(run_id=run_id, artifact_path=artifact_path)
model_details = mlflow.register_model(model_uri=model_uri, name=model_name)
import time
from mlflow.tracking.client import MlflowClient
from mlflow.entities.model_registry.model_version_status import ModelVersionStatus
# Wait until the model is ready
def wait_until_ready(model_name, model_version):
client = MlflowClient()
for _ in range(10):
model_version_details = client.get_model_version(
name=model_name,
version=model_version,
)
status = ModelVersionStatus.from_string(model_version_details.status)
print("Model status: %s" % ModelVersionStatus.to_string(status))
if status == ModelVersionStatus.READY:
break
time.sleep(1)
wait_until_ready(model_details.name, model_details.version)
Adición del modelo y las descripciones de las versiones del modelo mediante la API
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
client.update_registered_model(
name=model_details.name,
description="This model forecasts the power output of a wind farm based on weather data. The weather data consists of three features: wind speed, wind direction, and air temperature."
)
client.update_model_version(
name=model_details.name,
version=model_details.version,
description="This model version was built using TensorFlow Keras. It is a feed-forward neural network with one hidden layer."
)
Transición de una versión del modelo y recuperación de los detalles mediante la API
client.transition_model_version_stage(
name=model_details.name,
version=model_details.version,
stage='production',
)
model_version_details = client.get_model_version(
name=model_details.name,
version=model_details.version,
)
print("The current model stage is: '{stage}'".format(stage=model_version_details.current_stage))
latest_version_info = client.get_latest_versions(model_name, stages=["production"])
latest_production_version = latest_version_info[0].version
print("The latest production version of the model '%s' is '%s'." % (model_name, latest_production_version))
Carga de versiones del modelo registrado mediante la API
El componente de modelos de MLflow define funciones para cargar modelos desde varios marcos de aprendizaje automático. Por ejemplo, mlflow.tensorflow.load_model() se usa para cargar modelos de TensorFlow que se guardaron en el formato de MLflow, y mlflow.sklearn.load_model() se usa para cargar modelos de scikit-learn guardados en el formato de MLflow.
Estas funciones pueden cargar modelos desde el registro de modelos de MLflow.
import mlflow.pyfunc
model_version_uri = "models:/{model_name}/1".format(model_name=model_name)
print("Loading registered model version from URI: '{model_uri}'".format(model_uri=model_version_uri))
model_version_1 = mlflow.pyfunc.load_model(model_version_uri)
model_production_uri = "models:/{model_name}/production".format(model_name=model_name)
print("Loading registered model version from URI: '{model_uri}'".format(model_uri=model_production_uri))
model_production = mlflow.pyfunc.load_model(model_production_uri)
Previsión de la salida de energía con el modelo de producción
En esta sección, se usa el modelo de producción para evaluar los datos de previsión meteorológica de la granja eólica. La aplicación forecast_power() carga la versión más reciente del modelo de previsión desde la fase especificada y la usa para pronosticar la producción de energía durante los próximos cinco días.
def plot(model_name, model_stage, model_version, power_predictions, past_power_output):
import pandas as pd
import matplotlib.dates as mdates
from matplotlib import pyplot as plt
index = power_predictions.index
fig = plt.figure(figsize=(11, 7))
ax = fig.add_subplot(111)
ax.set_xlabel("Date", size=20, labelpad=20)
ax.set_ylabel("Power\noutput\n(MW)", size=20, labelpad=60, rotation=0)
ax.tick_params(axis='both', which='major', labelsize=17)
ax.xaxis.set_major_formatter(mdates.DateFormatter('%m/%d'))
ax.plot(index[:len(past_power_output)], past_power_output, label="True", color="red", alpha=0.5, linewidth=4)
ax.plot(index, power_predictions.squeeze(), "--", label="Predicted by '%s'\nin stage '%s' (Version %d)" % (model_name, model_stage, model_version), color="blue", linewidth=3)
ax.set_ylim(ymin=0, ymax=max(3500, int(max(power_predictions.values) * 1.3)))
ax.legend(fontsize=14)
plt.title("Wind farm power output and projections", size=24, pad=20)
plt.tight_layout()
display(plt.show())
def forecast_power(model_name, model_stage):
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
model_version = client.get_latest_versions(model_name, stages=[model_stage])[0].version
model_uri = "models:/{model_name}/{model_stage}".format(model_name=model_name, model_stage=model_stage)
model = mlflow.pyfunc.load_model(model_uri)
weather_data, past_power_output = get_weather_and_forecast()
power_predictions = pd.DataFrame(model.predict(weather_data))
power_predictions.index = pd.to_datetime(weather_data.index)
print(power_predictions)
plot(model_name, model_stage, int(model_version), power_predictions, past_power_output)
Creación de una nueva versión del modelo
Las técnicas clásicas de aprendizaje automático también son eficaces para la previsión de energía. El código siguiente entrena un modelo de bosque aleatorio mediante scikit-learn y lo registra en el registro de modelos de MLflow mediante la función mlflow.sklearn.log_model().
import mlflow.sklearn
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
with mlflow.start_run():
n_estimators = 300
mlflow.log_param("n_estimators", n_estimators)
rand_forest = RandomForestRegressor(n_estimators=n_estimators)
rand_forest.fit(X_train, y_train)
val_x, val_y = get_validation_data()
mse = mean_squared_error(rand_forest.predict(val_x), val_y)
print("Validation MSE: %d" % mse)
mlflow.log_metric("mse", mse)
# Specify the `registered_model_name` parameter of the `mlflow.sklearn.log_model()`
# function to register the model with the MLflow Model Registry. This automatically
# creates a new model version
mlflow.sklearn.log_model(
sk_model=rand_forest,
artifact_path="sklearn-model",
registered_model_name=model_name,
)
Recuperación del nuevo identificador de versión del modelo mediante la búsqueda del registro de modelos de MLflow
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
model_version_infos = client.search_model_versions("name = '%s'" % model_name)
new_model_version = max([model_version_info.version for model_version_info in model_version_infos])
wait_until_ready(model_name, new_model_version)
Adición de una descripción a la nueva versión del modelo
client.update_model_version(
name=model_name,
version=new_model_version,
description="This model version is a random forest containing 100 decision trees that was trained in scikit-learn."
)
Transición de la nueva versión del modelo a la fase de ensayo y prueba del modelo
Antes de implementar un modelo en una aplicación de producción, suele ser un procedimiento recomendado probarlo en un entorno de ensayo. El código siguiente pasa la nueva versión del modelo a Staging (Ensayo) y evalúa su rendimiento.
client.transition_model_version_stage(
name=model_name,
version=new_model_version,
stage="Staging",
)
forecast_power(model_name, "Staging")
Implementación de la nueva versión del modelo en producción
Después de comprobar que la nueva versión del modelo funciona bien en la fase de ensayo, el código siguiente realiza la transición del modelo a Production (Producción) y usa exactamente el mismo código de aplicación de la sección Previsión de la salida de energía con el modelo de producción para generar una previsión de energía.
client.transition_model_version_stage(
name=model_name,
version=new_model_version,
stage="production",
)
forecast_power(model_name, "production")
Ahora hay dos versiones del modelo de previsión en la etapa de Producción: la versión entrenada en Keras y la versión entrenada en scikit-learn.
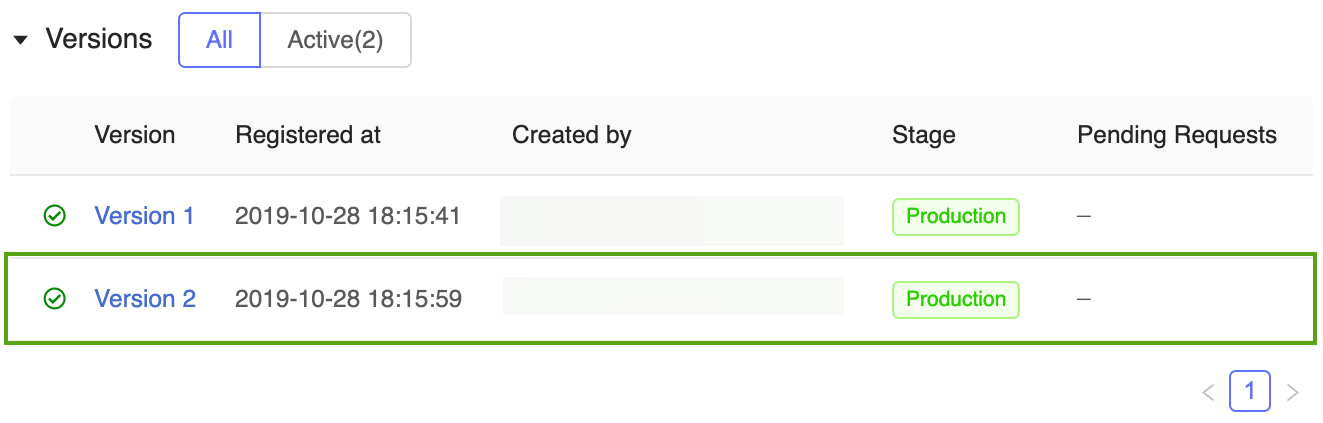
Nota:
Al hacer referencia a un modelo por fase, el registro de modelos de MLflow usa automáticamente la versión de producción más reciente. Esto le permite actualizar los modelos de producción sin cambiar el código de la aplicación.
Archivado y eliminación de modelos
Cuando ya no se usa una versión del modelo, puede archivarla o eliminarla. También puede eliminar un modelo registrado completo; esto quita todas sus versiones de modelo asociadas.
Archivo Version 1 del modelo de previsión de energía
Archive el Version 1 del modelo de previsión de potencia porque ya no se está utilizando. Puede archivar modelos en la interfaz de usuario del registro de modelos de MLflow o mediante la API de MLflow.
Archivar Version 1 en la interfaz de usuario de MLflow
Para guardar Version 1 del modelo de previsión de energía:
Abra su página de versión del modelo correspondiente en la interfaz de usuario del registro de modelos de MLflow:
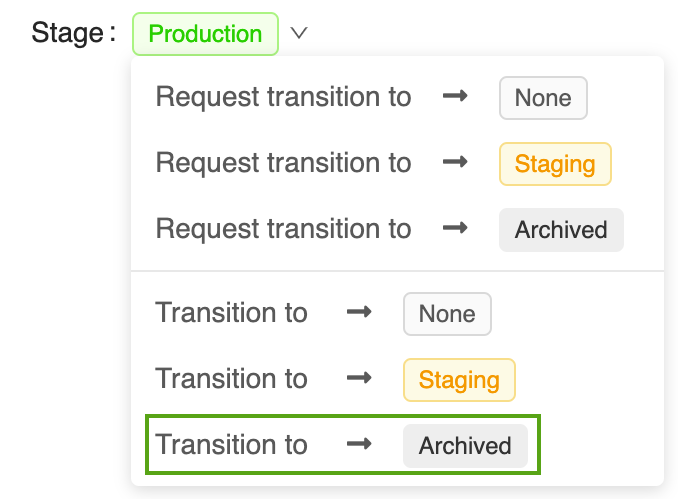
Haga clic en el botón Stage y seleccione Transición hacia -> Archivado.
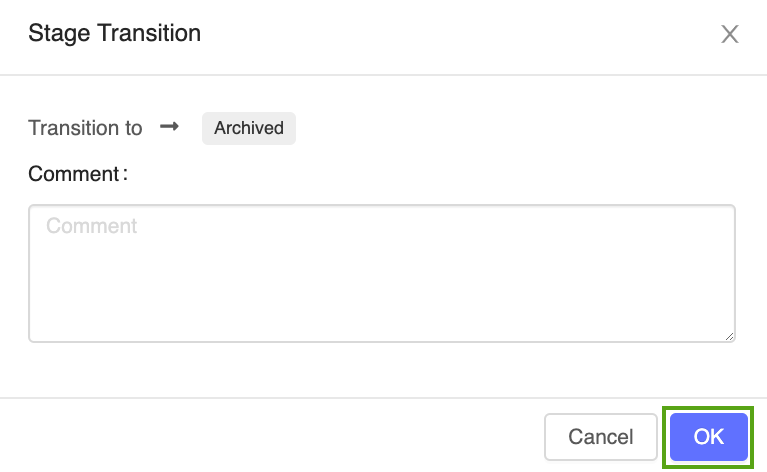
Pulse OK (Aceptar) en la ventana de confirmación de la transición de fase.

Archivar Version 1 con la API de MLflow
En el siguiente código, se utiliza la función MlflowClient.update_model_version() para almacenar Version 1 del modelo de predicción de energía.
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
client.transition_model_version_stage(
name=model_name,
version=1,
stage="Archived",
)
Eliminar Version 1 del modelo de previsión de energía
También puede usar la interfaz de usuario de MLflow o la API de MLflow para eliminar versiones del modelo.
Advertencia
La eliminación de una versión del modelo es permanente y no se puede deshacer.
Eliminación de la Version 1 en la interfaz de usuario de MLflow
Para eliminar la Version 1 del modelo de previsión de energía:
Abra su página de versión del modelo correspondiente en la interfaz de usuario del registro de modelos de MLflow.
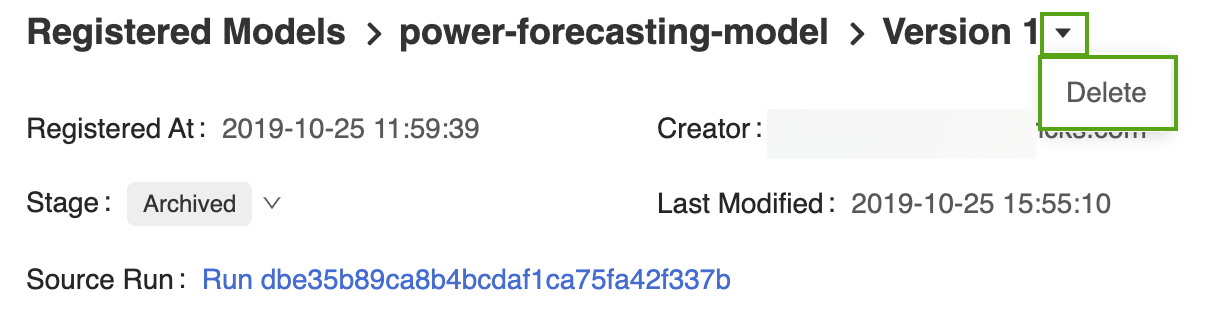
Seleccione la flecha desplegable situada junto al identificador de versión y haga clic en Delete (Eliminar).
Eliminación de la Version 1 mediante la API de MLflow
client.delete_model_version(
name=model_name,
version=1,
)
Eliminación del modelo mediante la API de MLflow
Debe primero cambiar todas las etapas restantes de la versión del modelo a None o Archived.
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
client.transition_model_version_stage(
name=model_name,
version=2,
stage="Archived",
)
client.delete_registered_model(name=model_name)