Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En esta página se describen las opciones de los recursos de computación de notebooks. Puede ejecutar un cuaderno en un recurso de cómputo de propósito general, cómputo sin servidor o, para comandos SQL, puede usar un almacén de SQL, un tipo de recurso optimizado para análisis SQL. Para obtener más información sobre los tipos de proceso, consulte Proceso.
Cómputo predeterminado
En las áreas de trabajo habilitadas para el Catálogo de Unity, los nuevos cuadernos están predeterminados a usar cómputo sin servidor. Si no selecciona manualmente un recurso de cómputo y ejecuta una celda, el cuaderno se conecta automáticamente al cómputo sin servidor.
Proceso de asociación automática
En la configuración del desarrollador, puede configurar cuadernos para asociarse automáticamente a un recurso de proceso e iniciar una sesión cuando interactúe con el editor:
Haga clic en el icono de usuario en la parte superior izquierda.
Haga clic en Configuración.
Haga clic en Desarrollador para ir a la configuración del desarrollador.
Para activar o desactivar, cambia el botón de alternancia Crear sesión automáticamente en la interacción del editor para iniciar automáticamente una sesión de cálculo durante la interacción con el editor. Databricks tiene como valor predeterminado un recurso de proceso en función de sus preferencias (sin servidor o SQL Warehouse) y el último recurso de proceso usado.
OR
Desactive esta configuración si no desea que el cuaderno se conecte automáticamente y inicie un recurso de proceso.
Las características de asistencia de código, como autocompletar, el formato de código y el depurador, requieren que el cuaderno se adjunte a una sesión de cálculo activa. Si el cuaderno no ha iniciado una sesión de cálculo, las funcionalidades de asistencia de código están inactivas.
Proceso sin servidor para cuadernos
El proceso sin servidor le permite conectar su cuaderno rápidamente a recursos informáticos a petición.
Para adjuntar al cómputo sin servidor, haga clic en el menú desplegable de cómputo en el cuaderno y seleccione Sin Servidor.
Consulte Proceso sin servidor para cuadernos para obtener más información.
Restauración automatizada de sesiones para cuadernos sin servidor
La terminación de inactividad de la computación sin servidor puede hacer que pierda el trabajo en curso, como los valores de variables de Python, en los notebooks. Para evitar esto, active Restauración automatizada de sesiones para cuadernos sin servidor.
- Haga clic en el nombre de usuario en la esquina superior derecha del área de trabajo y, a continuación, haga clic en Configuración en la lista desplegable.
- En la barra lateral Configuración, seleccione Desarrollador.
- En Características experimentales, active la opción Restauración de sesión automatizada para cuadernos sin servidor .
Al habilitar esta configuración, Databricks puede tomar una instantánea del estado de memoria del notebook sin servidor antes de la finalización por inactividad. Cuando vuelva a un cuaderno después de una desconexión inactiva, aparecerá un banner en la parte superior de la página. Haga clic en Volver a conectar para restaurar el estado de trabajo.
Al volver a conectarse, Databricks restablece todo el entorno de trabajo, lo que incluye:
- Variables, funciones y definiciones de clase en Python: El estado de Python se serializa en el proceso mediante pickle/cloudpickle y se restaura en una nueva REPL, por lo que no es necesario volver a importar ni volver a declarar.
- Tramas de datos de Spark, vistas almacenadas en caché y temporales: se conservan los datos que ha cargado, transformado o almacenado en caché (incluidas las vistas temporales), por lo que se evitan costosas recargas o recomputaciones.
- Estado de sesión de Spark: las opciones de configuración de nivel de Spark, las vistas temporales, las modificaciones del catálogo y las funciones definidas por el usuario (UDF) se restauran a través de la migración de sesión de Spark Connect, por lo que no es necesario restablecerlas.
Si el entorno ha cambiado de forma que la deserialización no sea segura, por ejemplo, versiones de paquete o Python incompatibles, la instantánea se invalida y el cuaderno vuelve a una sesión nueva.
Almacenamiento de datos de instantáneas
Los datos de instantánea se almacenan en el almacenamiento predeterminado del área de trabajo. El propio cuaderno solo almacena metadatos, incluido un puntero con el identificador del cuaderno, una marca de tiempo e información de sesión. La carga de datos no se almacena en el cuaderno. Las rutas de acceso de blob se cifran antes de almacenarse en atributos de cuaderno y las rutas de acceso de instantánea se excluyen de la exportación e importación de cuadernos para evitar la restauración del estado en un área de trabajo diferente.
Las instantáneas siguen los valores predeterminados de tiempo de vida (TTL) del almacenamiento en la nube (aproximadamente un mes) y caducan automáticamente. Al eliminar un cuaderno también se eliminan sus instantáneas. La cuenta en la nube incurre en costos de almacenamiento como parte del uso estándar del almacenamiento del área de trabajo. La característica usa la serialización de procesos de Python en lugar de los puntos de comprobación a nivel de contenedor, lo que mantiene las instantáneas más pequeñas y más rápidas de crear.
Seguridad y control de acceso
La restauración de instantáneas respeta los permisos del notebook. Restaurar el estado requiere el permiso RUN en el notebook. Los metadatos cifrados impiden que los visores capturen directamente blobs de instantáneas y se apliquen comprobaciones de permisos en la restauración.
Limitaciones
Esta característica tiene limitaciones y no admite la restauración de lo siguiente:
- Estados de Spark anteriores a 4 días
- Estados de Spark de más de 50 MB
- Datos relacionados con scripts de SQL
- Identificadores de archivo
- Bloqueos y otros primitivos de simultaneidad
- Conexiones de red
Adjuntar un cuaderno a un recurso de cómputo de propósito general
Para asociar un cuaderno a un recurso de cálculo de propósito general, necesita el permiso CAN ATTACH TO en el recurso de cálculo.
Importante
Siempre que un cuaderno esté asociado a un recurso de proceso, cualquier usuario con el permiso CAN RUN en el cuaderno tenga permiso implícito para acceder al recurso de proceso.
Para asociar un cuaderno a un recurso de proceso, haga clic en el selector de proceso de la barra de herramientas del cuaderno y seleccione el recurso en el menú desplegable.
El menú muestra una selección de los almacenes de cálculo y almacenes SQL versátiles que ha utilizado recientemente o que están funcionando actualmente.
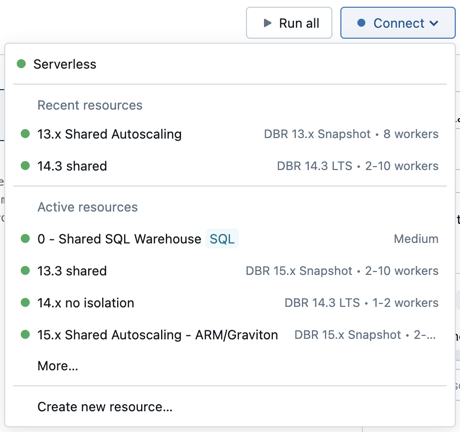
Para seleccionar entre todos los procesos disponibles, haga clic en Más.... Seleccione uno de los almacenes de computación general o SQL disponibles.
También puede crear un nuevo recurso informático de uso general seleccionando Crear nuevo recurso... en la lista desplegable.
Importante
Un cuaderno asociado tiene definidas las siguientes variables de Apache Spark.
| Clase | Nombre de variable |
|---|---|
SparkContext |
sc |
SQLContext/HiveContext |
sqlContext |
SparkSession (Spark 2.x) |
spark |
No cree un SparkSession, SparkContext, o SQLContext. Al hacerlo, se produce un comportamiento incoherente.
Uso de un cuaderno con un almacenamiento SQL
Cuando un cuaderno está asociado a un almacenamiento SQL, puede ejecutar celdas SQL y de Markdown. Al ejecutar una celda en cualquier otro lenguaje (como Python o R), se produce un error. Las celdas SQL ejecutadas en un almacén de SQL aparecen en el historial de consultas de SQL Warehouse. El usuario que ejecutó una consulta puede ver el perfil de la consulta desde el cuaderno haciendo clic en el tiempo transcurrido en la parte inferior de la salida.
Los cuadernos conectados a SQL Warehouse admiten sesiones de SQL Warehouse, donde puede definir variables, crear vistas temporales y conservar el estado entre varias ejecuciones de consultas. Puede compilar lógica de SQL de forma iterativa sin necesidad de ejecutar todas las instrucciones a la vez. Consulte ¿Qué son las sesiones de SQL Warehouse?.
La ejecución de un cuaderno requiere un almacenamiento SQL profesional o sin servidor. Debe tener acceso al área de trabajo y al almacenamiento SQL.
Para asociar un cuaderno a un almacenamiento SQL, haga lo siguiente:
Haga clic en el selector de proceso en la barra de herramientas del cuaderno. El menú desplegable muestra los recursos de proceso que se están ejecutando actualmente o que ha usado recientemente. Los almacenamientos SQL están marcados con la
 .
.En el menú, seleccione un almacenamiento SQL.
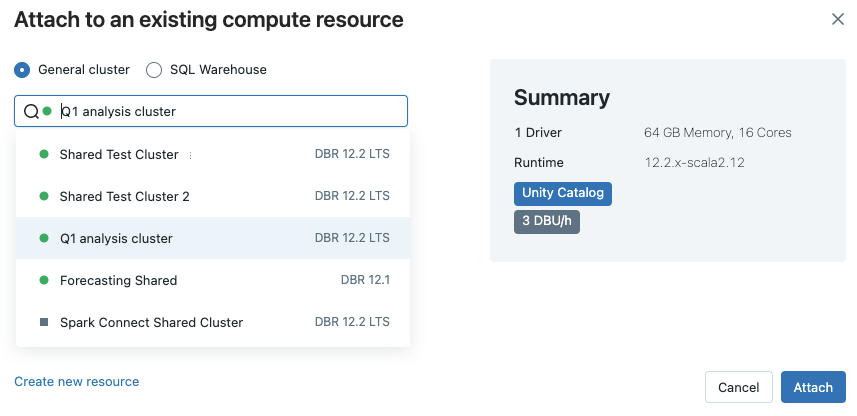
Para ver todos los almacenes de SQL disponibles, seleccione Más... en el menú desplegable. Aparece un cuadro de diálogo que muestra los recursos de proceso disponibles para el cuaderno. Seleccione SQL Warehouse, seleccione el almacén que desea usar y haga clic en Asociar.
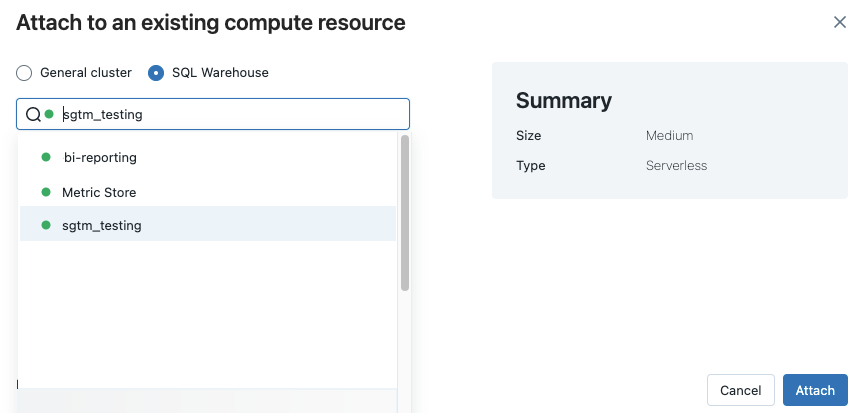
También puede seleccionar una instancia de SQL Warehouse como recurso de proceso para un cuaderno de SQL al crear un flujo de trabajo o un trabajo programado.
Limitaciones de los almacenes SQL
Consulte Limitaciones conocidas de los cuadernos de Databricks para obtener más información.