Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Importante
El escalado automático de Lakebase es la versión más reciente de Lakebase, con proceso de escalado automático, escalado a cero, bifurcación y restauración instantánea. Para ver las regiones admitidas, consulte Disponibilidad de regiones. Si es un usuario aprovisionado de Lakebase, consulte Aprovisionamiento de Lakebase.
Las tablas sincronizadas permiten servir datos de lakehouse a través de Lakebase Postgres. Las tablas del catálogo de Unity se sincronizan con Postgres para que las aplicaciones puedan consultar datos de lakehouse directamente con baja latencia. Este proceso se conoce normalmente como ETL inverso. El lakehouse está optimizado para análisis y enriquecimiento, mientras que Lakebase está diseñado para cargas de trabajo operativas que requieren consultas rápidas de tipo búsqueda y coherencia transaccional.
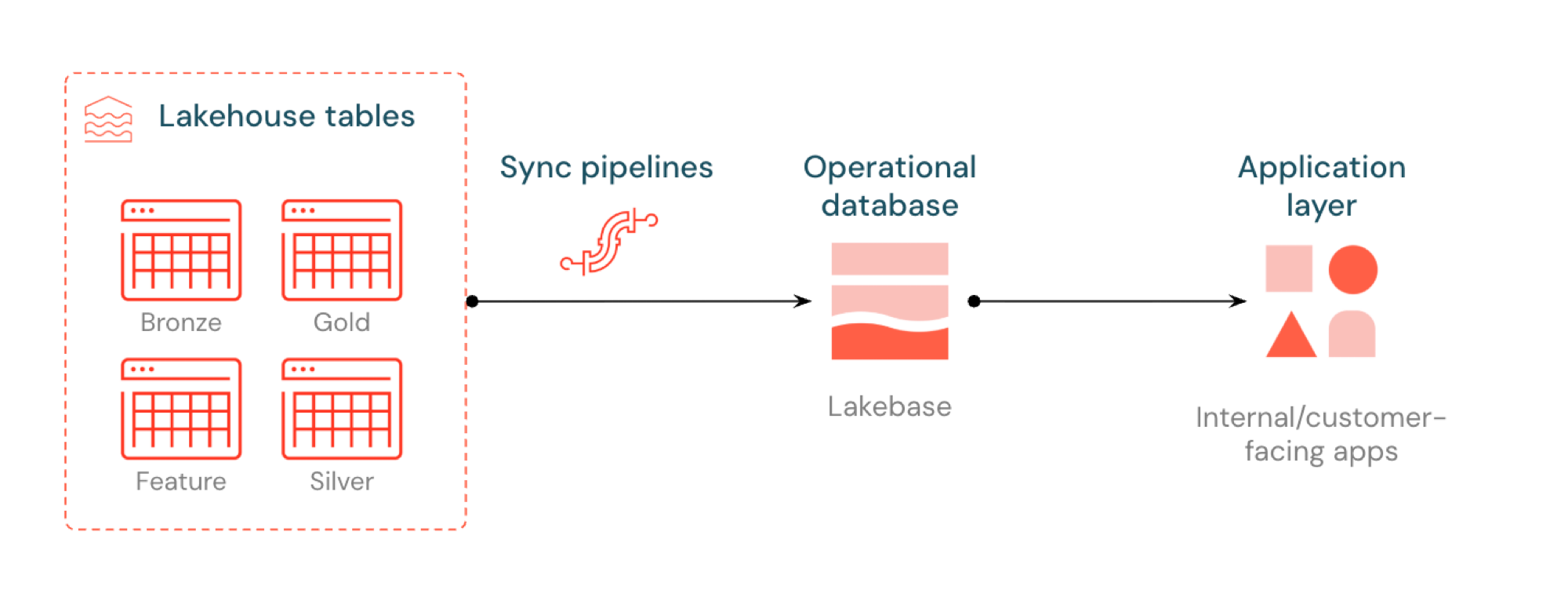
¿Qué son las tablas sincronizadas?
Las tablas sincronizadas permiten servir datos de nivel de análisis desde el catálogo de Unity a través de Lakebase Postgres, lo que hace que esté disponible para las aplicaciones que necesitan consultas de baja latencia (sub-10 ms) y transacciones ACID completas. Puenten la brecha entre el almacenamiento analítico y los sistemas operativos manteniendo los datos listos para servir en aplicaciones en tiempo real.
Fuentes compatibles
Las tablas sincronizadas admiten los siguientes tipos de origen del catálogo de Unity:
- Tablas delta administradas y externas
- Tablas de Iceberg administradas y externas
- Vistas y vistas materializadas
Cómo funciona
Las tablas sincronizadas de Databricks crean una copia administrada de los datos del catálogo de Unity en Lakebase. Al crear una tabla sincronizada, obtendrá lo siguiente:
- Una tabla que está sincronizada en el catálogo de Unity que hace referencia al pipeline de sincronización.
- Una tabla de Postgres en Lakebase (solo lectura, consultable por las aplicaciones)
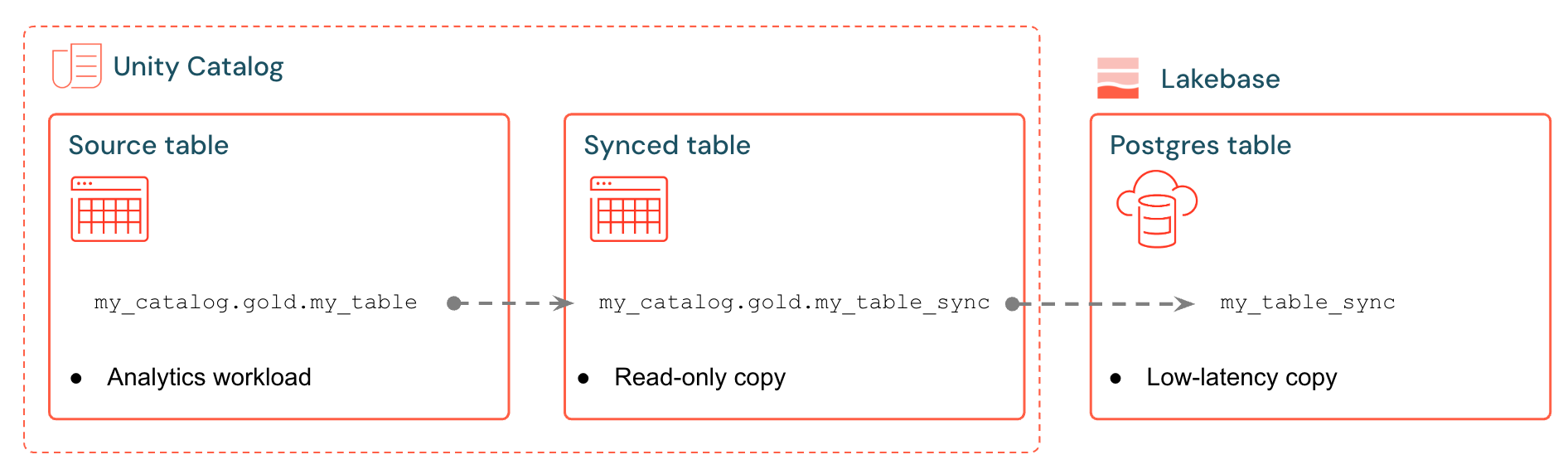
Por ejemplo, puede sincronizar tablas doradas, características diseñadas o salidas de aprendizaje automático desde analytics.gold.user_profiles en una nueva tabla analytics.gold.user_profiles_synced sincronizada. En Postgres, el nombre del esquema del catálogo de Unity se convierte en el nombre del esquema de Postgres, por lo que aparece como "gold"."user_profiles_synced":
SELECT * FROM "gold"."user_profiles_synced" WHERE "user_id" = 12345;
Las aplicaciones se conectan con controladores de Postgres estándar y consultan los datos sincronizados junto con su propio estado operativo.
Advertencia
Aunque es posible modificar una tabla sincronizada directamente en Postgres, Azure Databricks recomienda estrictamente ejecutar solo consultas de lectura para proteger la integridad de los datos con el origen. Para ver las operaciones admitidas en tablas sincronizadas, consulte Operaciones admitidas.
Las canalizaciones de sincronización utilizan las canalizaciones declarativas de Spark de Lakeflow administrado para actualizar continuamente tanto la tabla sincronizada del Unity Catalog como la tabla de Postgres con los cambios de la tabla de origen. Cada sincronización puede usar hasta 16 conexiones a la base de datos de Lakebase.
Lakebase Postgres admite hasta 1000 conexiones simultáneas con garantías transaccionales, por lo que las aplicaciones pueden leer datos enriquecidos al mismo tiempo que controlan inserciones, actualizaciones y eliminaciones en la misma base de datos.
Modos de sincronización
Elija el modo de sincronización adecuado en función de las necesidades de la aplicación:
| Modo | Descripción | Cuándo se deben usar | Rendimiento |
|---|---|---|---|
| Instantánea | Copia única de todos los datos | El origen cambia >el 10% de las filas por ciclo, o el origen no admite CDF (vistas, tablas de Iceberg) | 10 veces más eficaz si se modifican >10% de datos de origen |
| Desencadenado | Actualizaciones programadas que se ejecutan a petición o a intervalos | Las filas de origen cambian en una cadencia conocida. Las inserciones, actualizaciones y eliminaciones se propagan cada actualización. | Buen equilibrio entre costo y latencia. Costoso si se ejecutan <intervalos de 5 minutos |
| Continuo | Streaming en tiempo real con segundos de latencia | Los cambios deben aparecer en Lakebase casi en tiempo real | Retraso más bajo, costo más alto. Intervalos mínimos de 15 segundos |
Los modos desencadenados y continuos requieren que el flujo de datos de cambios (CDF) esté habilitado en la tabla de origen. Si CDF no está habilitado, verá una advertencia en la interfaz de usuario con el comando exacto ALTER TABLE que se va a ejecutar. Para más detalles sobre el flujo de datos de cambios, consulte Usar el flujo de datos de cambios de Delta Lake en Databricks.
Ejemplos de casos de uso
Puede usar tablas sincronizadas para casos de uso de servicio de datos como:
- Motores de personalización que sirven perfiles de usuario nuevos a Databricks Apps
- Aplicaciones que sirven a predicciones de modelos o valores de características calculados en lakehouse
- Paneles orientados al cliente que sirven KPI en tiempo real
- Servicios de detección de fraudes que sirven puntuaciones de riesgo para la acción inmediata
- Herramientas de soporte que gestionan registros de clientes enriquecidos a partir de datos de lakehouse.
Creación de una tabla sincronizada
Prerrequisitos
Necesitas:
- Un área de trabajo de Databricks con Lakebase habilitado.
- Un proyecto de Lakebase (consulte Creación de un proyecto).
- Una tabla del catálogo de Unity para sincronizar.
- Permisos para crear tablas sincronizadas. Necesita USE_SCHEMA y CREATE_TABLE en cualquier esquema que use.
Para los modos desencadenados o continuos, el flujo de datos de cambio debe estar habilitado en la tabla de origen.
ALTER TABLE your_catalog.your_schema.your_table
SET TBLPROPERTIES (delta.enableChangeDataFeed = true)
Para obtener información sobre la compatibilidad de tipos de datos y planeamiento de capacidad, consulte Tipos de datos y compatibilidad y planeamiento de la capacidad.
Interfaz de usuario
Vaya a Catálogo en la barra lateral del área de trabajo y seleccione la tabla catálogo de Unity que desea sincronizar.
Haga clic en Crear>tabla sincronizada desde la vista de detalles de la tabla.
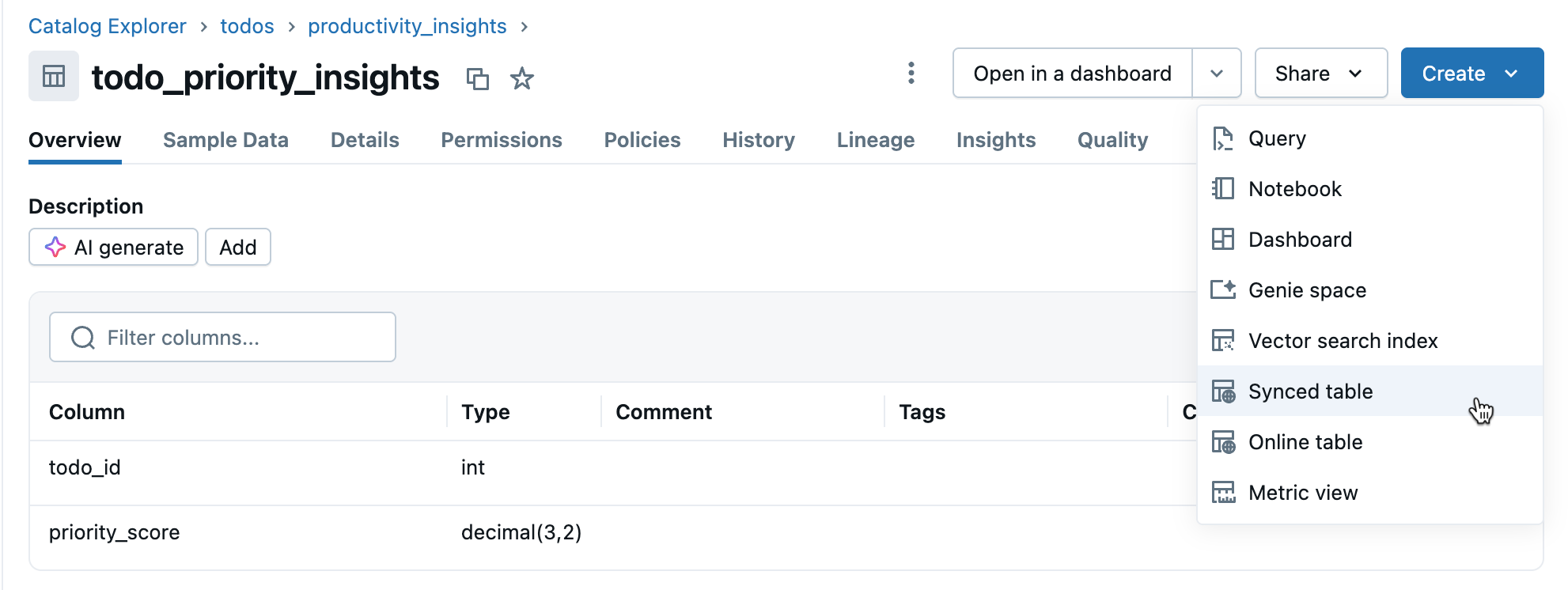
En el diálogo cuadro Crear tabla sincronizada:
Las listas de catálogos y esquemas solo incluyen esquemas de catálogo de Unity donde el usuario actual tiene USE_SCHEMA y privilegios de CREATE_TABLE . Si no ve un esquema esperado, confirme los permisos con el administrador del catálogo.
- Nombre de tabla: escriba un nombre para la tabla sincronizada (se crea en el mismo catálogo y esquema que la tabla de origen). Esto crea una tabla sincronizada de Catálogo de Unity y una tabla postgres que puede consultar.
- Tipo de base de datos: elija Lakebase Sin servidor (escalado automático).
- Modo de sincronización: elija Instantánea, Desencadenada o Continua según sus necesidades (consulte los modos de sincronización anteriores).
- Configure las selecciones de proyecto, rama y base de datos.
- Compruebe que la clave principal es correcta (normalmente se detecta automáticamente).
Si eligió el modo Desencadenado o continuo y aún no ha habilitado el flujo de datos modificados, verá una advertencia con el comando exacto que se va a ejecutar. Para obtener preguntas sobre compatibilidad de tipos de datos, consulte Tipos de datos y compatibilidad.
Haga clic en Crear para crear la tabla sincronizada.
Supervise la tabla sincronizada en El catálogo. En la pestaña Información general se muestra el estado de sincronización, la configuración, el estado de la canalización y la última marca de tiempo de sincronización. Use Sincronizar ahora para actualizar manualmente.
SDK de Python
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import (
SyncedTable,
SyncedTableSyncedTableSpec,
SyncedTableSyncedTableSpecSyncedTableSchedulingPolicy,
)
w = WorkspaceClient()
synced_table = w.postgres.create_synced_table(
synced_table=SyncedTable(spec=SyncedTableSyncedTableSpec(
source_table_full_name="main.sales.orders",
project="projects/my-project",
branch="projects/my-project/branches/production",
primary_key_columns=["order_id"],
scheduling_policy=SyncedTableSyncedTableSpecSyncedTableSchedulingPolicy.TRIGGERED,
postgres_database="mydb",
create_database_objects_if_missing=True,
)),
synced_table_id="my-catalog.sales.orders",
).wait()
print(f"Synced table created: {synced_table.name}")
synced_table_id usa el formato catalog.schema.table y se convierte en el nombre de la tabla sincronizada del catálogo de Unity y el nombre de la tabla postgres.
SDK de Java
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.*;
import java.util.List;
WorkspaceClient w = new WorkspaceClient();
SyncedTable syncedTable = w.postgres().createSyncedTable(
new CreateSyncedTableRequest()
.setSyncedTableId("my-catalog.sales.orders")
.setSyncedTable(new SyncedTable()
.setSpec(new SyncedTableSyncedTableSpec()
.setSourceTableFullName("main.sales.orders")
.setProject("projects/my-project")
.setBranch("projects/my-project/branches/production")
.setPrimaryKeyColumns(List.of("order_id"))
.setSchedulingPolicy(SyncedTableSyncedTableSpecSyncedTableSchedulingPolicy.TRIGGERED)
.setPostgresDatabase("mydb")
.setCreateDatabaseObjectsIfMissing(true))))
.waitForCompletion();
System.out.println("Synced table created: " + syncedTable.getName());
curl
curl -X POST "https://your-workspace.cloud.databricks.com/api/2.0/postgres/synced_tables?synced_table_id=my-catalog.sales.orders" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"spec": {
"source_table_full_name": "main.sales.orders",
"project": "projects/my-project",
"branch": "projects/my-project/branches/production",
"primary_key_columns": ["order_id"],
"scheduling_policy": "TRIGGERED",
"postgres_database": "mydb",
"create_database_objects_if_missing": true
}
}'
Esto devuelve una operación de larga duración. Sondee el campo devuelto name hasta done: true. Consulte Operaciones de ejecución prolongada. Para la configuración de la autenticación, consulte Autenticación.
Programar o desencadenar sincronizaciones posteriores
La instantánea inicial se ejecuta automáticamente cuando se crea. En el caso de los modos Instantánea y Activado, las sincronizaciones posteriores deben activarse explícitamente. El modo continuo es autoadministrado.
Tarea de canalización de sincronización de tabla de base de datos
La tarea de Database Table Sync pipeline en Lakeflow Jobs ejecuta la canalización de una tabla sincronizada como un paso del flujo de trabajo. Configure el trabajo con un desencadenador de actualización de tabla o una programación.
Desencadenador activado por actualizaciones en la tabla de origen
Activa el trabajo cuando se actualiza la tabla fuente de Unity Catalog. Con el modo activado, solo se aplican cambios nuevos de forma incremental, lo que proporciona una actualización casi en tiempo real sin el costo siempre activo del modo continuo.
- En la barra lateral, haga clic en Flujos de trabajo.
- Haga clic en Crear trabajo o abra un trabajo existente.
- En la pestaña Tareas , haga clic en + Agregar otro tipo de tarea.
- En Ingesta y transformación, seleccione el Proceso de Sincronización de tablas de base de datos.
- En el campo Canalización , seleccione la canalización asociada a la tabla sincronizada.
- En Programaciones y desencadenadores, haga clic en Agregar desencadenador.
- Seleccione Actualización de tabla como tipo de desencadenador.
- En Tablas, seleccione la tabla de catálogo de Unity de origen que se va a supervisar.
- Haz clic en Guardar.
Desencadenador según una programación
Ejecuta la sincronización con una cadencia fija. Adecuado para el modo de instantánea , donde una actualización completa nocturna o semanal suele ser el patrón más eficaz.
- Siga los pasos 1 a 5 anteriores para agregar una tarea de canalización de Database Table Sync a un trabajo.
- En Programaciones y desencadenadores, haga clic en Agregar desencadenador.
- Seleccione Scheduled (Programado ) como tipo de desencadenador.
- Establezca la programación cron y la zona horaria y, a continuación, haga clic en Guardar.
Desencadenar una ejecución de sincronización mediante programación
Desencadene una ejecución de sincronización mediante programación, por ejemplo, al final de un cuaderno o canalización ascendente:
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
# Get the pipeline ID from the synced table
table = w.postgres.get_synced_table("synced_tables/my-catalog.sales.orders")
pipeline_id = table.status.pipeline_id
# Trigger a sync run
w.pipelines.start_update(pipeline_id=pipeline_id)
Comprobación del estado de sincronización
Para comprobar el estado actual y la hora de la última sincronización de una tabla sincronizada:
Interfaz de usuario
En Catálogo, vaya a la tabla sincronizada y seleccione la pestaña Información general . Muestra el estado de sincronización actual, el estado de la canalización y la última marca de tiempo de sincronización.
SDK de Python
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
table = w.postgres.get_synced_table("synced_tables/my-catalog.sales.orders")
print(f"State: {table.status.detailed_state}")
print(f"Last sync: {table.status.last_sync_time}")
print(f"Message: {table.status.message}")
SDK de Java
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.SyncedTable;
WorkspaceClient w = new WorkspaceClient();
SyncedTable table = w.postgres().getSyncedTable("synced_tables/my-catalog.sales.orders");
System.out.println("State: " + table.getStatus().getDetailedState());
System.out.println("Last sync: " + table.getStatus().getLastSyncTime());
System.out.println("Message: " + table.getStatus().getMessage());
curl
curl "https://your-workspace.cloud.databricks.com/api/2.0/postgres/synced_tables/my-catalog.sales.orders" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}"
Tipos de datos y compatibilidad
Los tipos de datos del Catálogo de Unity se asignan a los tipos de Postgres al crear tablas sincronizadas. Los tipos complejos (ARRAY, MAP, STRUCT) se almacenan como JSONB en Postgres.
| Tipo de columna de origen | Tipo de columna Postgres |
|---|---|
| BIGINT | BIGINT |
| BINARIO | BYTEA |
| BOOLEAN | BOOLEAN |
| DATE | DATE |
| DECIMAL(p,s) | NUMÉRICO |
| DOUBLE | doble precisión |
| FLOTAR | REAL |
| INT | INTEGER |
| INTERVAL | INTERVAL |
| SMALLINT | SMALLINT |
| STRING | Mensaje de texto |
| TIMESTAMP | MARCA DE TIEMPO CON ZONA HORARIA |
| TIMESTAMP_NTZ | MARCA DE TIEMPO SIN ZONA HORARIA |
| TINYINT | SMALLINT |
| ARRAY<tipoDeElemento> | JSONB |
| MAP<keyType,valueType> | JSONB |
| ESTRUCTURA<fieldName:fieldType[, ...]> | JSONB |
Nota:
No se admiten los tipos GEOGRAPHY, GEOMETRY, VARIANT y OBJECT.
Gestionar caracteres no válidos
Se permiten determinados caracteres como bytes NULL (0x00) en columnas STRING del catálogo de Unity, ARRAY, MAP o STRUCT, pero no se admiten en columnas POSTGRES TEXT o JSONB. Esto puede provocar errores de sincronización con errores como:
ERROR: invalid byte sequence for encoding "UTF8": 0x00
ERROR: unsupported Unicode escape sequence DETAIL: \u0000 cannot be converted to text
Soluciones:
Limpiar campos de cadena: elimine caracteres no admitidos antes de la sincronización. Para bytes NULL en columnas STRING:
SELECT REPLACE(column_name, CAST(CHAR(0) AS STRING), '') AS cleaned_column FROM your_tableConvertir a BINARY: Para las columnas STRING en las que es necesario conservar bytes sin procesar, convierta al tipo BINARY.
Planeamiento de la capacidad
Al planear la implementación de tablas sincronizadas, tenga en cuenta estos requisitos de recursos:
- Uso de conexiones: cada tabla sincronizada usa hasta 16 conexiones a la base de datos de Lakebase, las cuales cuentan para el límite de conexiones de la instancia.
- Límites de tamaño: el límite total de tamaño de datos lógicos en todas las tablas sincronizadas es de 8 TB. Las tablas individuales no tienen límites, pero Databricks recomienda no superar los 1 TB para las tablas que requieren actualizaciones.
-
Requisitos de nomenclatura: los nombres de base de datos, esquema y tabla solo pueden contener caracteres alfanuméricos y caracteres de subrayado (
[A-Za-z0-9_]+). - Evolución del esquema: solo se admiten cambios de esquema aditivos (como agregar columnas) para modos desencadenados y continuos.
- Velocidad de actualización: Para Autoscaling de Lakebase, la canalización de sincronización admite escrituras continuas y desencadenadas en aproximadamente 150 filas por segundo por unidad de capacidad (CU) y escrituras instantáneas en hasta 2,000 filas por segundo por CU.
Operaciones permitidas en tablas sincronizadas en Postgres
Azure Databricks recomienda realizar solo las siguientes operaciones en Postgres para tablas sincronizadas para evitar sobrescrituras accidentales o incoherencias de datos:
- Consultas de solo lectura
- Creación de índices
- Quitar la tabla (para liberar espacio después de quitar la tabla sincronizada del catálogo de Unity)
Aunque es posible modificar tablas sincronizadas en Postgres de otras maneras, interfiere con la canalización de sincronización.
Eliminación de una tabla sincronizada
Para eliminar una tabla sincronizada, debe completar ambos pasos a continuación.
Paso 1: Quitar del catálogo de Unity
Esto detiene las actualizaciones de datos, pero deja la tabla postgres en su lugar.
Interfaz de usuario
En Catálogo, busque la tabla sincronizada, haga clic en el ![]() y seleccione Eliminar.
y seleccione Eliminar.
SDK de Python
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
w.postgres.delete_synced_table("synced_tables/my-catalog.sales.orders").wait()
SDK de Java
import com.databricks.sdk.WorkspaceClient;
WorkspaceClient w = new WorkspaceClient();
w.postgres().deleteSyncedTable("synced_tables/my-catalog.sales.orders").waitForCompletion();
curl
curl -X DELETE "https://your-workspace.cloud.databricks.com/api/2.0/postgres/synced_tables/my-catalog.sales.orders" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}"
Paso 2: Quitar de Postgres
Conéctese a la base de datos de Lakebase y quite la tabla para liberar espacio:
DROP TABLE your_database.your_schema.your_table;
Puede usar el editor de SQL o las herramientas externas para conectarse a Postgres.
Aprende más
| tarea | Descripción |
|---|---|
| Creación de un proyecto | Configuración de un proyecto de Lakebase |
| Conexión a la base de datos | Obtenga información sobre las opciones de conexión de Lakebase. |
| Registro de la base de datos en el catálogo de Unity | Hacer que los datos de Lakebase sean visibles en el Catálogo de Unity para una gobernanza unificada y consultas entre orígenes |
| Integración del catálogo de Unity | Descripción de la gobernanza y los permisos |
Otras opciones
Para sincronizar datos en sistemas que no son de Databricks, consulte Soluciones ETL inversas de Partner Connect como Census o Hightouch.