Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
La ejecución de consultas adaptables (AQE) es la reoptimización de consultas que se produce durante el procesamiento de consultas.
La motivación para la optimización en tiempo de ejecución es que Azure Databricks tiene las estadísticas más precisas de fecha up-toal final de un intercambio aleatorio y de difusión (denominado fase de consulta en AQE). Como resultado, Azure Databricks puede optar por una mejor estrategia física, elegir un tamaño y un número óptimos de partición posteriores a la mezcla, o realizar optimizaciones que solían requerir sugerencias, por ejemplo, la gestión de uniones sesgadas.
Esto puede ser muy útil cuando la recopilación de estadísticas no está activada o cuando las estadísticas están obsoletas. También es útil en lugares donde las estadísticas derivadas estáticamente son inexactas, como en medio de una consulta complicada, o después de la aparición de la asimetría de datos.
Capacidades
AQE está habilitado de forma predeterminada. Tiene cuatro características principales:
- Cambia dinámicamente la combinación de combinación de ordenación en combinación hash de difusión.
- Combina dinámicamente las particiones (combinan particiones pequeñas en particiones de tamaño razonable) después del intercambio aleatorio. Las tareas muy pequeñas tienen un rendimiento de E/S peor y tienden a sufrir más de la sobrecarga de programación y la sobrecarga de configuración de tareas. La combinación de tareas pequeñas ahorra recursos y mejora el rendimiento del clúster.
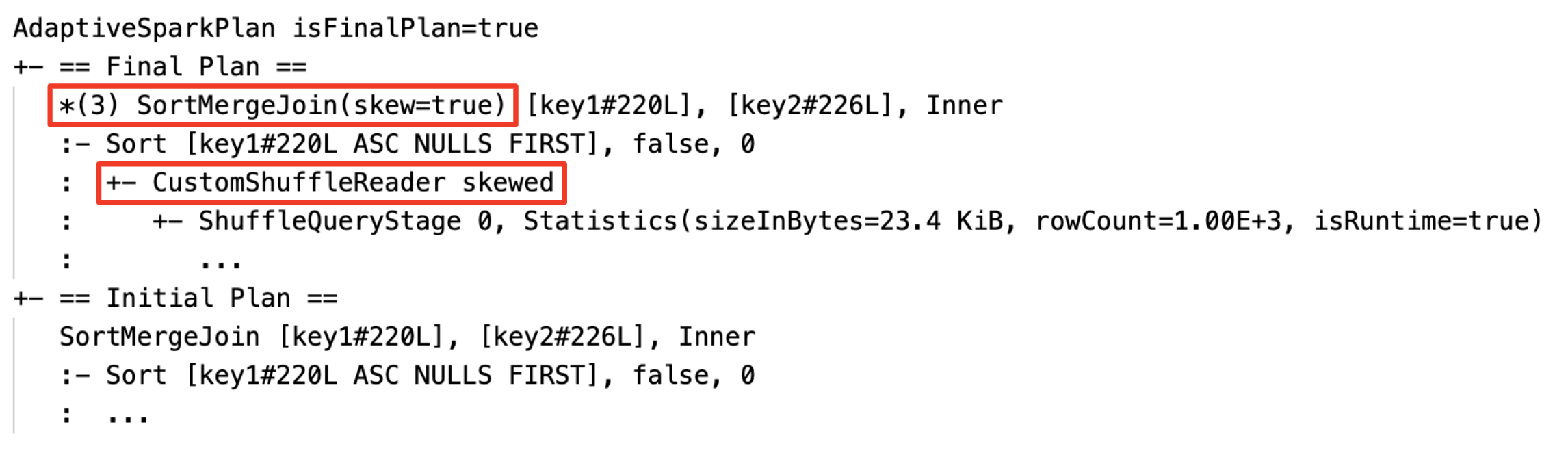
- Gestiona dinámicamente el sesgo en las uniones de combinación de ordenación y hash aleatorio dividiendo (y replicando si es necesario) las tareas sesgadas en tareas de tamaño aproximadamente uniforme.
- Detecta y propaga dinámicamente relaciones vacías.
Aplicación
AQE se aplica a todas las consultas que son:
- Sin transmisión
- Contiene al menos un intercambio (normalmente cuando hay una combinación, un agregado o una ventana), una subconsulta, o ambos.
No todas las consultas aplicadas por AQE se vuelven a optimizar necesariamente. La reoptimización puede dar lugar a un plan de consulta diferente al compilado estáticamente. Para determinar si AQE ha cambiado el plan de una consulta, consulte la sección siguiente, Planes de consulta.
Planes de consulta
En esta sección se describe cómo puede examinar los planes de consulta de diferentes maneras.
En esta sección:
Interfaz de usuario de Spark
AdaptiveSparkPlan nodo
Las consultas aplicadas a AQE contienen uno o varios AdaptiveSparkPlan nodos, normalmente como nodo raíz de cada consulta principal o subconsulta.
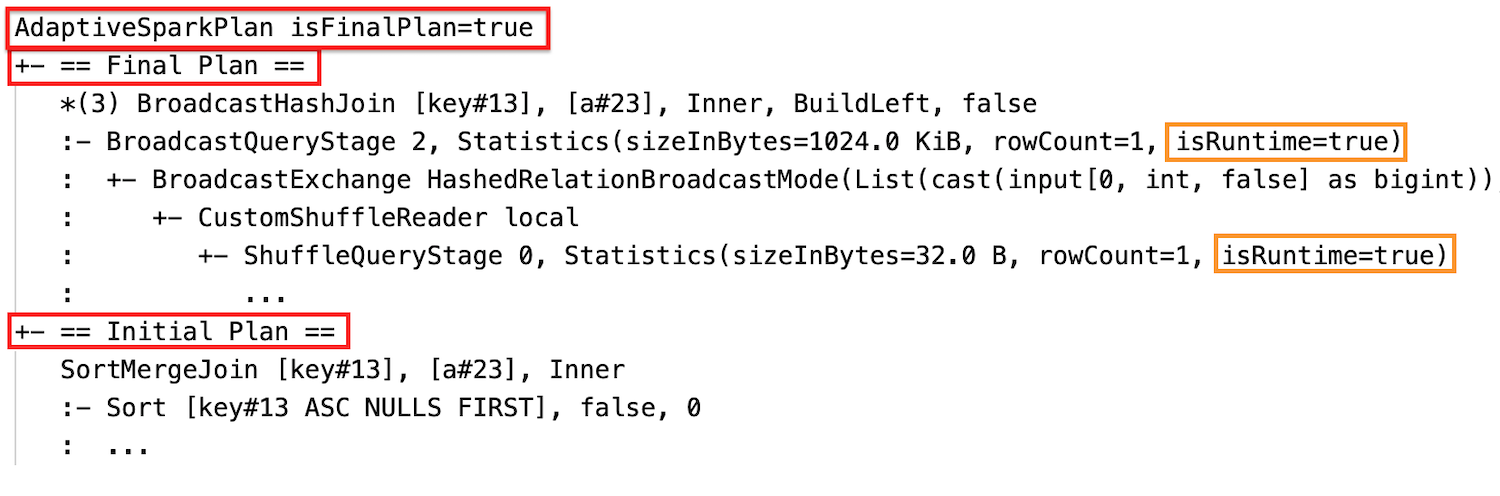
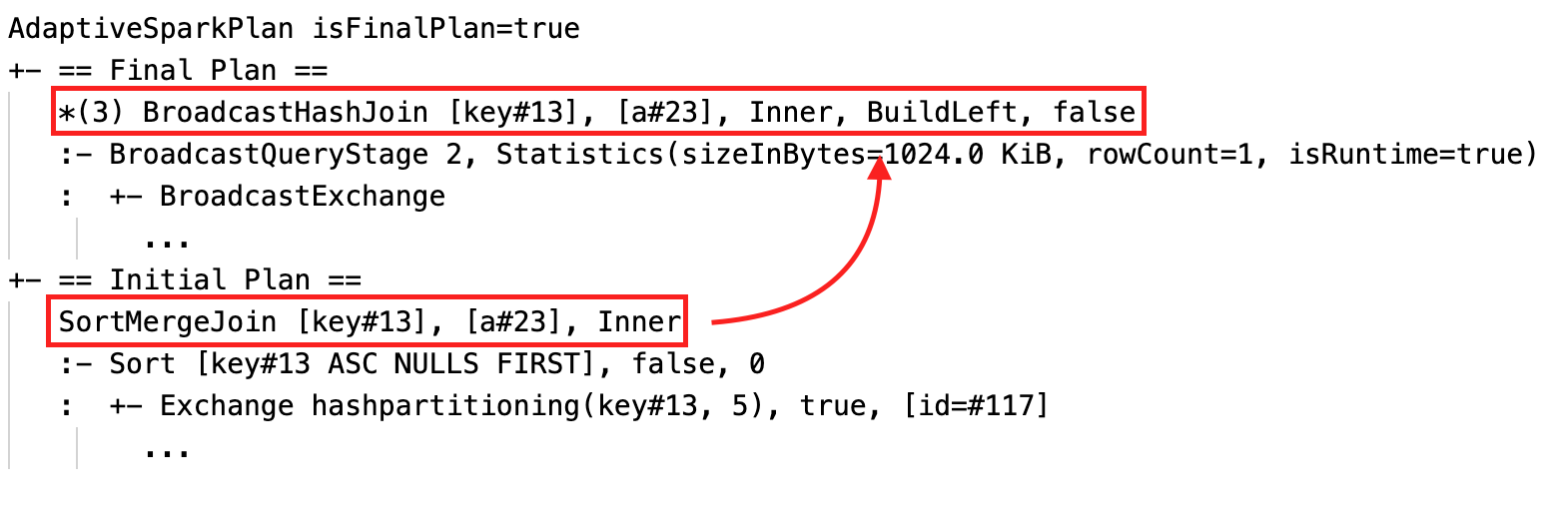
Antes de que se ejecute la consulta o cuando se esté ejecutando, la isFinalPlan marca del nodo correspondiente AdaptiveSparkPlan se muestra como false; una vez completada la ejecución de la consulta, la isFinalPlan marca cambia a . true.
Plan en evolución
El diagrama del plan de consulta evoluciona a medida que avanza la ejecución y refleja el plan más actual que se está ejecutando. Los nodos que ya se han ejecutado (en los que las métricas están disponibles) no cambiarán, pero aquellos que no lo han hecho pueden cambiar con el tiempo al ser reoptimizados.
A continuación se muestra un ejemplo de diagrama de plan de consulta:
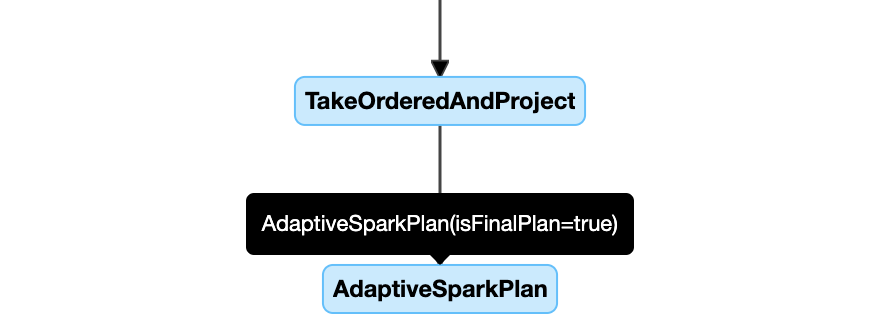
DataFrame.explain()
AdaptiveSparkPlan nodo
Las consultas aplicadas a AQE contienen uno o varios AdaptiveSparkPlan nodos, normalmente como nodo raíz de cada consulta principal o subconsulta. Antes de que se ejecute la consulta o cuando se ejecute, la isFinalPlan marca del nodo correspondiente AdaptiveSparkPlan se muestra como false; una vez completada la ejecución de la consulta, la isFinalPlan marca cambia a true.
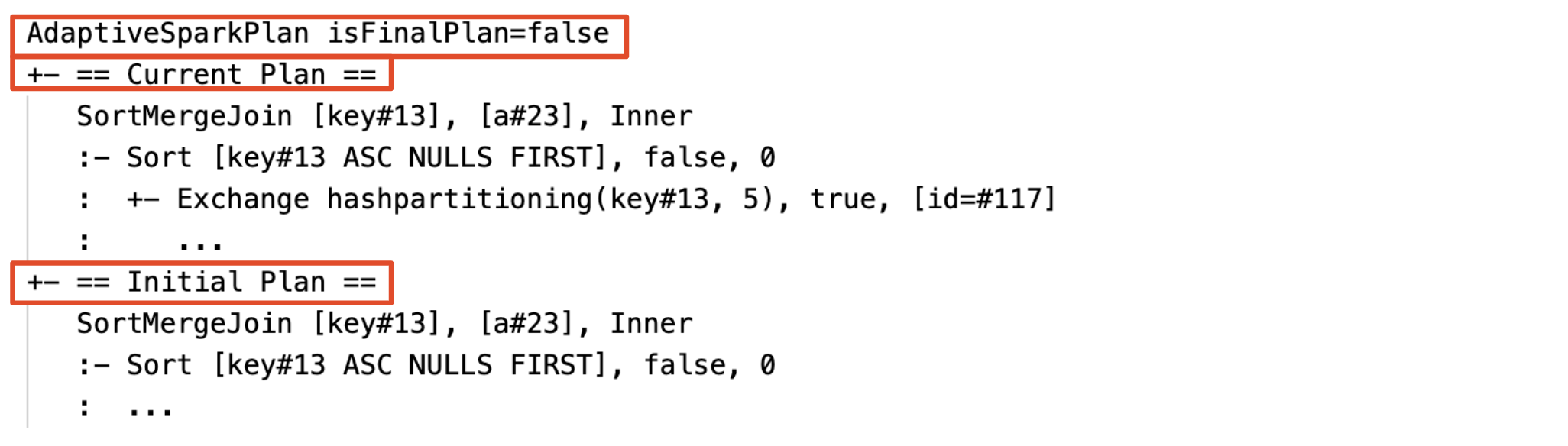
Plan actual e inicial
En cada AdaptiveSparkPlan nodo habrá el plan inicial (el plan antes de aplicar las optimizaciones de AQE) y el plan actual o final, en función de si la ejecución se ha completado. El plan actual evolucionará a medida que avanza la ejecución.
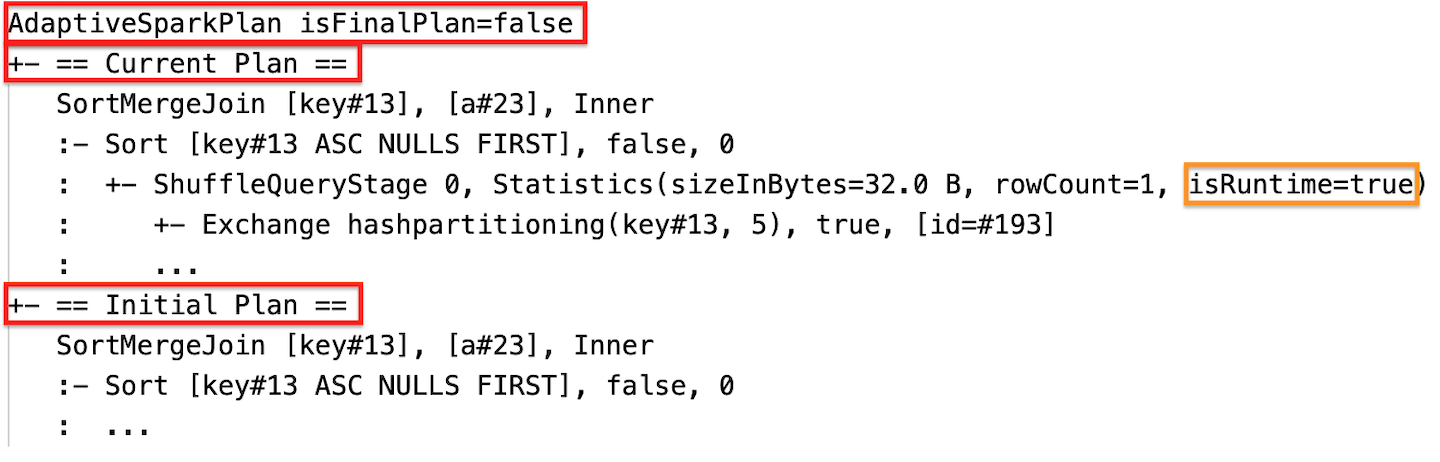
Estadísticas de tiempo de ejecución
Cada fase de orden aleatorio y de difusión contiene estadísticas de datos.
Antes de que se ejecute la etapa o durante su ejecución, las estadísticas son estimaciones en tiempo de compilación, y el indicador isRuntime es false, por ejemplo: Statistics(sizeInBytes=1024.0 KiB, rowCount=4, isRuntime=false);
Una vez completada la ejecución de la fase, las estadísticas son las recopiladas en tiempo de ejecución y la marca isRuntime se convertirá en true, por ejemplo: Statistics(sizeInBytes=658.1 KiB, rowCount=2.81E+4, isRuntime=true)
A continuación se muestra un DataFrame.explain ejemplo:
Antes de la ejecución
Durante la ejecución
Después de la ejecución
SQL EXPLAIN
AdaptiveSparkPlan nodo
Las consultas aplicadas a AQE contienen uno o varios nodos AdaptiveSparkPlan, normalmente como nodo raíz de cada consulta principal o subconsulta.
Ningún plan actual
Como SQL EXPLAIN no ejecuta la consulta, el plan actual es siempre el mismo que el plan inicial y no refleja lo que finalmente se ejecutaría con AQE.
A continuación se muestra un ejemplo de explicación de SQL:

Efectividad
El plan de consulta cambiará si una o varias optimizaciones de AQE surten efecto. El efecto de estas optimizaciones de AQE se demuestra por la diferencia entre los planes actuales y finales y el plan inicial y los nodos de plan específicos en los planes actuales y finales.
Cambiar dinámicamente el tipo de combinación de ordenación a combinación hash de difusión: diferentes nodos de combinación física entre el plan actual y el plan inicial.
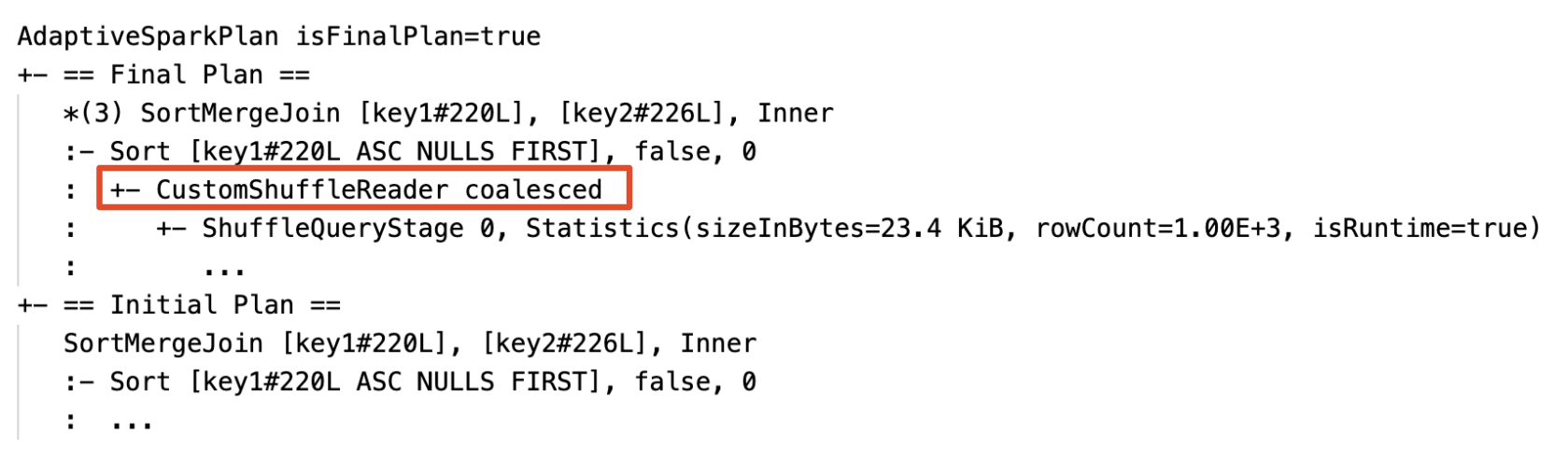
Particiones de fusión dinámica: nodo
CustomShuffleReadercon propiedadCoalesced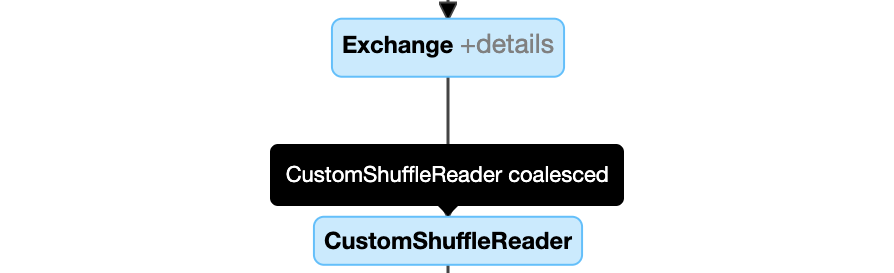
Controlar dinámicamente la combinación de asimetría: nodo
SortMergeJoincon el campoisSkewcomo true.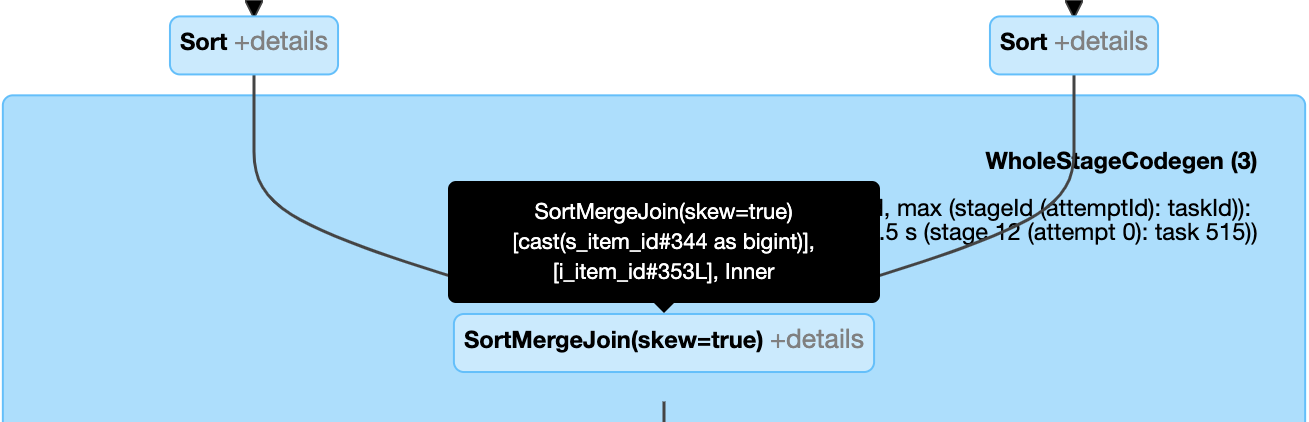
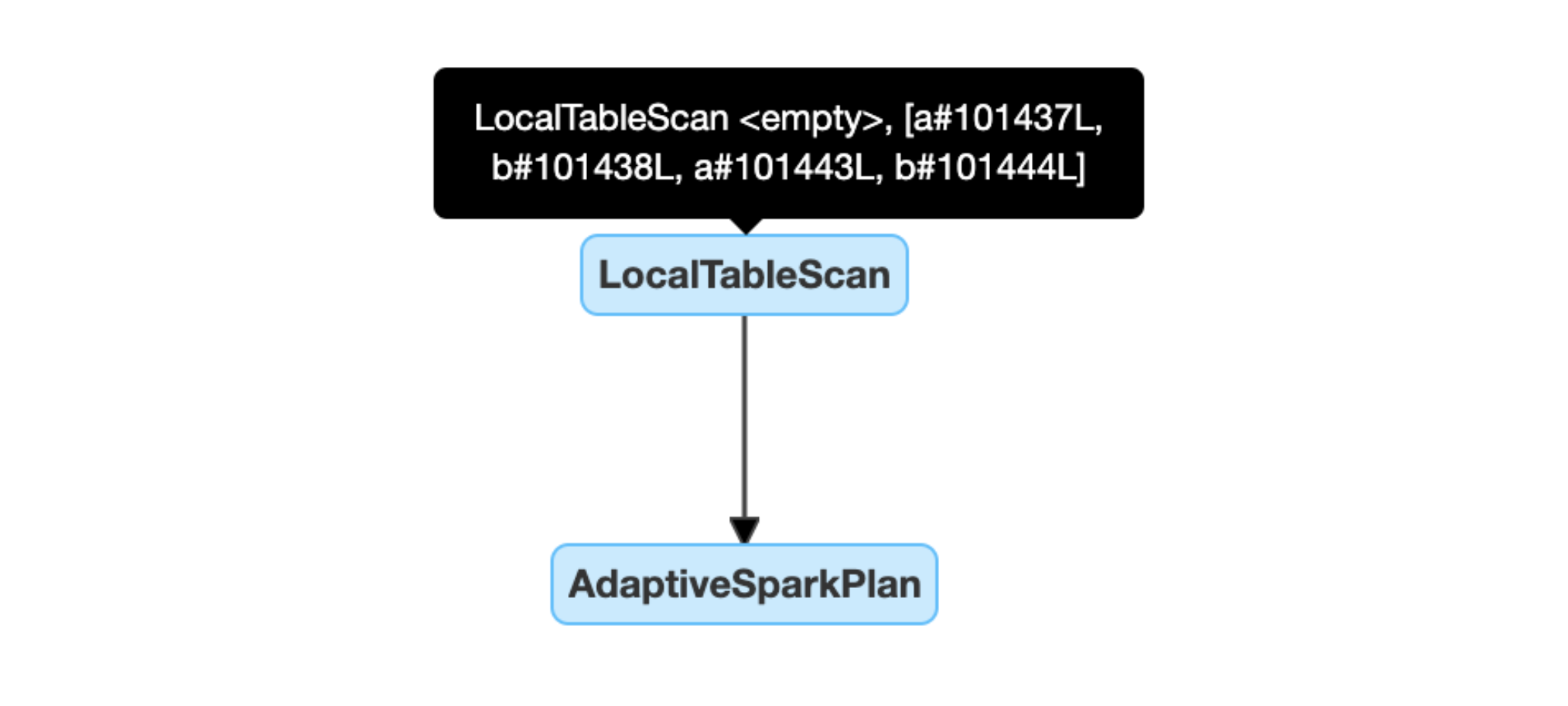
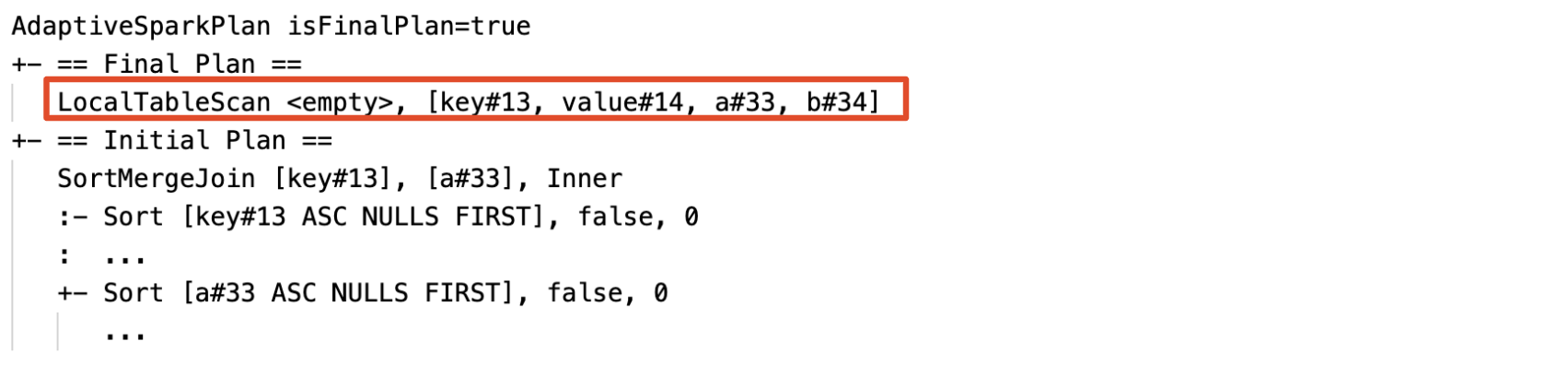
Detectar y propagar dinámicamente relaciones vacías: parte (o la totalidad) del plan es reemplazada por el nodo LocalTableScan con el campo de relación vacío.
Configuración
En esta sección:
- Habilitación y deshabilitación de la ejecución de consultas adaptables
- Habilitar mezcla autooptimizada
- Cambiar dinámicamente la unión de mezcla de ordenación a unión de hash de difusión
- Fusión dinámica de particiones
- Gestionar dinámicamente la unificación sesgada
- Detección y propagación dinámica de relaciones vacías
Habilitación y deshabilitación de la ejecución de consultas adaptables
| Propiedad |
|---|
|
spark.databricks.optimizer.adaptive.enabled Tipo: BooleanSi se va a habilitar o deshabilitar la ejecución de consultas adaptables. Valor predeterminado: true |
Habilitar mezcla aleatoria autooptimizada
| Propiedad |
|---|
|
spark.sql.shuffle.partitions Tipo: IntegerNúmero predeterminado de particiones que se van a usar al ordenar aleatoriamente datos para combinaciones o agregaciones. Si se establece el valor auto , se habilita el orden aleatorio optimizado automáticamente, que determina automáticamente este número en función del plan de consulta y del tamaño de los datos de entrada de la consulta.Nota: Para Structured Streaming, esta configuración no se puede cambiar entre reinicios de consulta desde la misma ubicación de punto de control. Valor predeterminado: 200 |
Cambiar dinámicamente la combinación de combinación de ordenación en combinación hash de difusión
| Propiedad |
|---|
|
spark.databricks.adaptive.autoBroadcastJoinThreshold Tipo: Byte StringUmbral para desencadenar la conmutación a la unión de difusión en tiempo de ejecución. Valor predeterminado: 30MB |
Fusión dinámica de particiones
| Propiedad |
|---|
|
spark.sql.adaptive.coalescePartitions.enabled Tipo: BooleanSi se debe habilitar o deshabilitar la fusión de particiones. Valor predeterminado: true |
|
spark.sql.adaptive.advisoryPartitionSizeInBytes Tipo: Byte StringTamaño de destino después de la coalescencia. Los tamaños de las particiones fusionados estarán cerca, pero no más grandes que este tamaño objetivo. Valor predeterminado: 64MB |
|
spark.sql.adaptive.coalescePartitions.minPartitionSize Tipo: Byte StringTamaño mínimo de las particiones después de la fusión. Los tamaños de partición fusionados no serán menores que este tamaño. Valor predeterminado: 1MB |
|
spark.sql.adaptive.coalescePartitions.minPartitionNum Tipo: IntegerNúmero mínimo de particiones después de la fusión. No se recomienda, ya que la configuración anula explícitamente spark.sql.adaptive.coalescePartitions.minPartitionSize.Valor predeterminado: 2x no. de núcleos de clúster |
Control dinámico de la combinación de asimetría
| Propiedad |
|---|
|
spark.sql.adaptive.skewJoin.enabled Tipo: BooleanSi se va a habilitar o deshabilitar el manejo de combinaciones sesgadas. Valor predeterminado: true |
|
spark.sql.adaptive.skewJoin.skewedPartitionFactor Tipo: IntegerFactor que cuando se multiplica por el tamaño de partición mediana contribuye a determinar si una partición está sesgada. Valor predeterminado: 5 |
|
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes Tipo: Byte StringUmbral que contribuye a determinar si una partición está sesgada. Valor predeterminado: 256MB |
Una partición se considera sesgada cuando ambos (partition size > skewedPartitionFactor * median partition size) y (partition size > skewedPartitionThresholdInBytes) son true.
Detección y propagación dinámica de relaciones vacías
| Propiedad |
|---|
|
spark.databricks.adaptive.emptyRelationPropagation.enabled Tipo: BooleanSi se va a habilitar o deshabilitar la propagación dinámica de relaciones vacías. Valor predeterminado: true |
Preguntas más frecuentes (FAQ)
En esta sección:
- ¿Por qué AQE no transmitió una pequeña tabla de combinación?
- ¿Debería seguir usando un indicador de estrategia de combinación de difusión cuando AQE está habilitado?
- ¿Cuál es la diferencia entre la sugerencia para combinación asimétrica y la optimización para combinación asimétrica de AQE? ¿Cuál debo usar?
- ¿Por qué AQE no ajustó mi ordenación de combinaciones automáticamente?
- ¿Por qué AQE no detectó mi asimetría de datos?
¿Por qué AQE no transmitió una pequeña tabla de unión?
Si el tamaño de la relación que se espera que se difunda está por debajo de este umbral, pero sigue sin difundirse:
- Compruebe el tipo de combinación. La difusión no se admite para ciertos tipos de combinación; por ejemplo, la relación izquierda de un
LEFT OUTER JOINno se puede transmitir. - También puede ocurrir que la relación contenga una gran cantidad de particiones vacías, en cuyo caso la mayoría de las tareas puede finalizar rápidamente con una combinación de ordenación o puede optimizarse potencialmente con un manejo de combinaciones sesgadas. AQE evita cambiar estas combinaciones de combinación de ordenación para difundir combinaciones hash si el porcentaje de particiones no vacías es inferior a
spark.sql.adaptive.nonEmptyPartitionRatioForBroadcastJoin.
¿Debo seguir usando una sugerencia de estrategia de combinación de difusión con AQE habilitado?
Sí. Una unión de difusión planeada estáticamente suele ser más eficaz que una planeada dinámicamente por AQE, ya que AQE podría no cambiar a la unión de difusión hasta después de realizar la reorganización para ambos lados de la unión, momento en el cual se obtienen los tamaños de relación reales. Por lo tanto, el uso de una sugerencia de difusión puede ser una buena opción si conoce bien la consulta. AQE respetará las sugerencias de consulta de la misma manera que la optimización estática, pero todavía puede aplicar optimizaciones dinámicas que no se ven afectadas por las sugerencias.
¿Cuál es la diferencia entre la sugerencia para combinación asimétrica y la optimización para combinación asimétrica de AQE? ¿Cuál debo usar?
Se recomienda confiar en el control de combinaciones de asimetría de AQE en lugar de usar la sugerencia de combinación de asimetría, ya que la combinación de asimetría de AQE es completamente automática y, en general, funciona mejor que el homólogo de sugerencia.
¿Por qué AQE no ajustó automáticamente mi orden de unión?
La reordenación de combinaciones dinámicas no forma parte de AQE.
¿Por qué AQE no detectó mi asimetría de datos?
Hay dos condiciones de tamaño que deben cumplirse para que AQE detecte una partición como una partición sesgada:
- El tamaño de la partición es mayor que (
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytesvalor predeterminado de 256 MB) - El tamaño de la partición es mayor que el tamaño medio de todas las particiones multiplicado por el factor de partición sesgada
spark.sql.adaptive.skewJoin.skewedPartitionFactor(valor predeterminado: 5)
Además, la compatibilidad con el control de sesgos está limitada para determinados tipos de combinación, por ejemplo, en LEFT OUTER JOIN, solo se puede optimizar la asimetría en el lado izquierdo.
Legado
El término "Ejecución adaptable" ha existido desde Spark 1.6, pero el nuevo AQE en Spark 3.0 es fundamentalmente diferente. En términos de funcionalidad, Spark 1.6 solo realiza la función de "agrupar dinámicamente particiones". En términos de arquitectura técnica, el nuevo AQE es un marco de planeamiento dinámico y replanado de consultas basadas en estadísticas en tiempo de ejecución, que admite una variedad de optimizaciones como las que hemos descrito en este artículo y se puede ampliar para habilitar más optimizaciones potenciales.