Fase de Spark lenta con poca E/S
Si tiene una fase lenta con pocas E/S, esto podría deberse a lo siguiente:
- Lectura de una gran cantidad de archivos pequeños
- Escritura de una gran cantidad de archivos pequeños
- UDF lentas
- Combinación cartesiana
- Combinación exponencial
Casi todos estos problemas se pueden identificar mediante el DAG de SQL.
Abrir el DAG de SQL
Para abrir el DAG de SQL, desplácese hasta la parte superior de la página del trabajo y haga clic en Consulta SQL asociada:
Ahora debería ver el DAG. Si no es así, desplácese alrededor un poco y debería verlo:
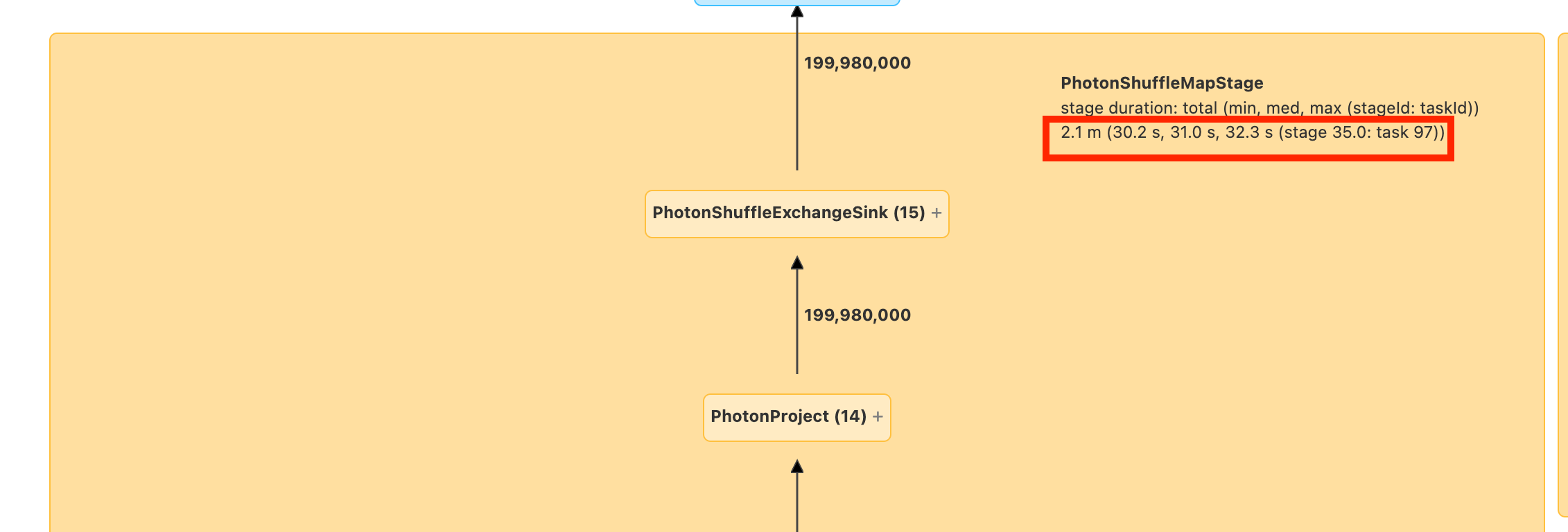
Antes de continuar, familiarícese con el DAG y donde se pasa el tiempo. Algunos nodos del DAG tienen información de tiempo útil y otros no. Por ejemplo, este bloque tardó 2,1 minutos e incluso proporciona el id. de fase:
Debe abrir este nodo para ver que tardó 1,4 minutos:
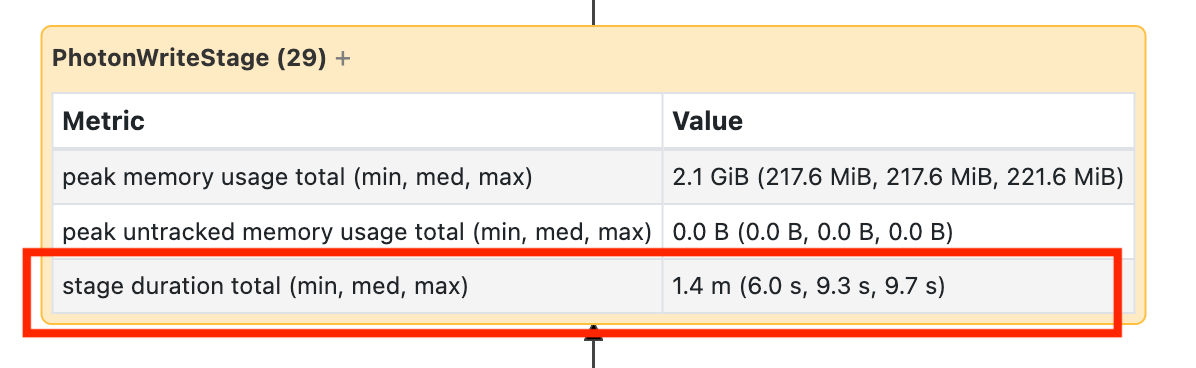
Estos tiempos son acumulativos, por lo que es el tiempo total que se pasó en todas las tareas, no la hora del reloj. Pero sigue siendo muy útil ya que se correlacionan con el tiempo del reloj y el costo.
Resulta útil familiarizarse en qué lugares en el DAG se está pasando el tiempo.
Lectura de una gran cantidad de archivos pequeños
Si ve que uno de los operadores de análisis tarda mucho tiempo, ábralo y busque el número de archivos leídos:
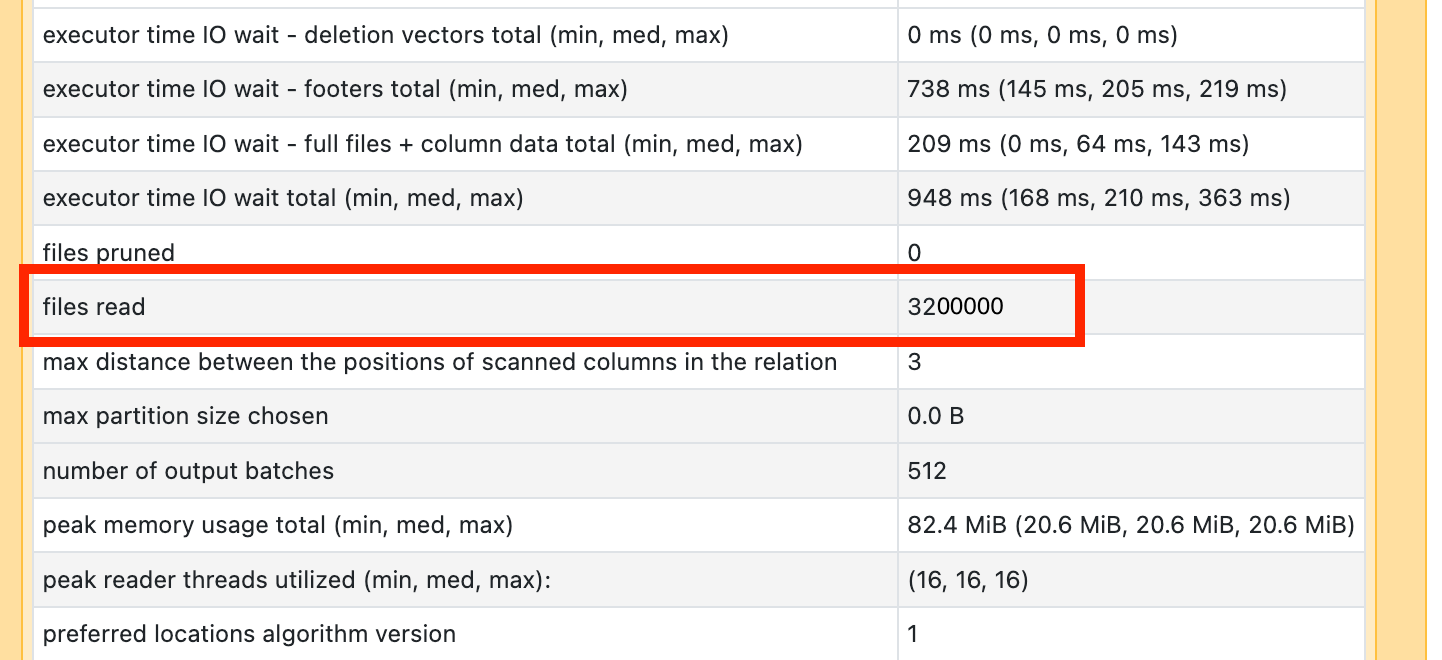
Si está leyendo decenas de miles de archivos o más, es posible que tenga un problema de archivo pequeño. El tamaño de los archivos no debe ser inferior a 8 MB. El problema de archivo pequeño suele deberse a la creación de particiones en demasiadas columnas o en una columna de cardinalidad alta.
Si tiene suerte, es posible que solo tenga que ejecutar OPTIMIZE. De todos modos, debe reconsiderar el diseño de archivo.
Escritura de una gran cantidad de archivos pequeños
Si ve que la escritura tarda mucho tiempo, ábrala y busque el número de archivos y la cantidad de datos que se han escrito:
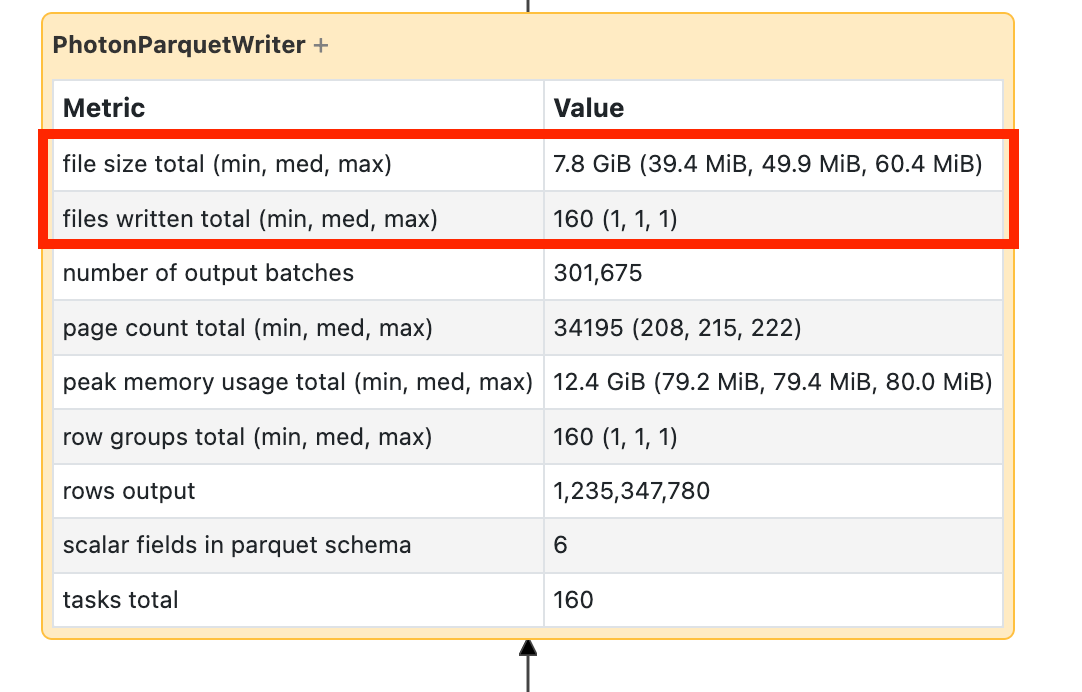
Si está escribiendo decenas de miles de archivos o más, es posible que tenga un problema de archivo pequeño. El tamaño de los archivos no debe ser inferior a 8 MB. El problema de archivo pequeño suele deberse a la creación de particiones en demasiadas columnas o en una columna de cardinalidad alta. Debe reconsiderar el diseño del archivo o activar las escrituras optimizadas.
UDF lentas
Si sabe que tiene UDFo ve algo parecido a esto en el DAG, podría estar experimentando UDF lentas:
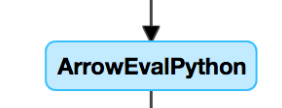
Si cree que tiene este problema, pruebe desactivar la UDF en el código mediante comentarios para ver cómo afecta a la velocidad de la canalización. Si la UDF es realmente donde se pasa el tiempo, lo mejor es volver a escribir la UDF mediante funciones nativas. Si no es posible, tenga en cuenta el número de tareas de la fase que ejecuta la UDF. Si es menor que el número de núcleos del clúster, repartition() el dataframe antes de usar la UDF:
(df
.repartition(num_cores)
.withColumn('new_col', udf(...))
)
Las UDF también pueden experimentar problemas de memoria. Tenga en cuenta que cada tarea puede tener que cargar todos los datos de su partición en la memoria. Si estos datos son demasiado grandes, las tareas pueden volverse muy lentas e inestables. La repartición también puede resolver este problema haciendo que cada tarea sea más pequeña.
Combinación cartesiana
Si ve una combinación cartesiana o de bucle anidado en el DAG, tenga en cuanta que estas combinaciones son muy costosas. Asegúrese de que es lo que ha previsto y analice si hay otra alternativa.
Combinación exponencial o explode
Si ve que algunas filas entran en un nodo y muchas más salen, es posible que experimente una combinación exponencial o explode():

Obtenga más información sobre las combinaciones exponenciales en la Guía de optimización de Databricks.