Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Azure Databricks admite el origen de datos de archivo binario, que lee archivos binarios y convierte cada archivo en un único registro que contiene el contenido y los metadatos sin procesar del archivo. Normalmente se usa para cargar datos no estructurados, como imágenes, audio o archivos PDF para el procesamiento descendente o la inferencia de ML. Para leer archivos binarios, especifique el origen de datos format como binaryFile.
Prerequisites
Azure Databricks no requiere configuración adicional para usar archivos binarios.
Opciones
Use los métodos .option() y .options() de DataFrameReader para configurar el origen de datos de archivo binario. Para obtener una lista completa de las opciones admitidas, consulte Referencia de opciones de API de Spark.
Esquema de salida
El origen de datos de archivo binario genera un DataFrame con las columnas siguientes, además de las columnas de partición:
-
path (StringType): ruta de acceso del archivo. -
modificationTime (TimestampType): Hora de modificación del archivo. En algunas implementaciones de Hadoop FileSystem, este parámetro podría no estar disponible y el valor se establecería en un valor predeterminado. -
length (LongType): La longitud del archivo en bytes. -
content (BinaryType): Contenido del archivo.
Usage
En los ejemplos siguientes se muestra cómo cargar archivos binarios mediante la API DataFrame de Spark y SQL, filtrar por tipo de archivo, mostrar vistas previas de imágenes y guardar en una tabla Delta para mejorar el rendimiento de lectura.
Leer archivos binarios
Use la API DataFrame de Apache Spark para cargar archivos binarios en un dataframe para su transformación, visualización o procesamiento de bajada.
Python
df = spark.read.format("binaryFile").load("/Volumes/<catalog>/<schema>/<volume>/")
display(df)
Scala
val df = spark.read.format("binaryFile").load("/Volumes/<catalog>/<schema>/<volume>/")
df.show()
SQL
SELECT path, length, modificationTime FROM read_files(
'/Volumes/<catalog>/<schema>/<volume>/images/',
format => 'binaryFile'
)
Configuración de las opciones de lectura
Para cargar archivos con rutas de acceso que coincidan con un patrón global determinado mientras se mantiene el comportamiento de la detección de particiones, puede usar la opción pathGlobFilter. El código siguiente lee todos los archivos JPG del directorio de entrada con la detección de particiones:
Python
df = spark.read.format("binaryFile").option("pathGlobFilter", "*.jpg").load("/Volumes/<catalog>/<schema>/<volume>/images/")
Scala
val df = spark.read.format("binaryFile").option("pathGlobFilter", "*.jpg").load("/Volumes/<catalog>/<schema>/<volume>/images/")
SQL
SELECT * FROM read_files(
'/Volumes/<catalog>/<schema>/<volume>/images/',
format => 'binaryFile',
pathGlobFilter => '*.jpg'
)
Si quiere omitir la detección de particiones y buscar archivos de forma recursiva en el directorio de entrada, use la opción recursiveFileLookup. Esta opción busca en directorios anidados incluso si sus nombres no siguen un esquema de nombres de partición como date=2019-07-01.
El siguiente código lee todos los archivos JPG recursivamente desde el directorio de entrada e ignora el descubrimiento de particiones:
Python
df = (spark.read.format("binaryFile")
.option("pathGlobFilter", "*.jpg")
.option("recursiveFileLookup", "true")
.load("/Volumes/<catalog>/<schema>/<volume>/images/"))
Scala
val df = spark.read.format("binaryFile")
.option("pathGlobFilter", "*.jpg")
.option("recursiveFileLookup", "true")
.load("/Volumes/<catalog>/<schema>/<volume>/images/")
SQL
SELECT * FROM read_files(
'/Volumes/<catalog>/<schema>/<volume>/images/',
format => 'binaryFile',
pathGlobFilter => '*.jpg',
recursiveFileLookup => true
)
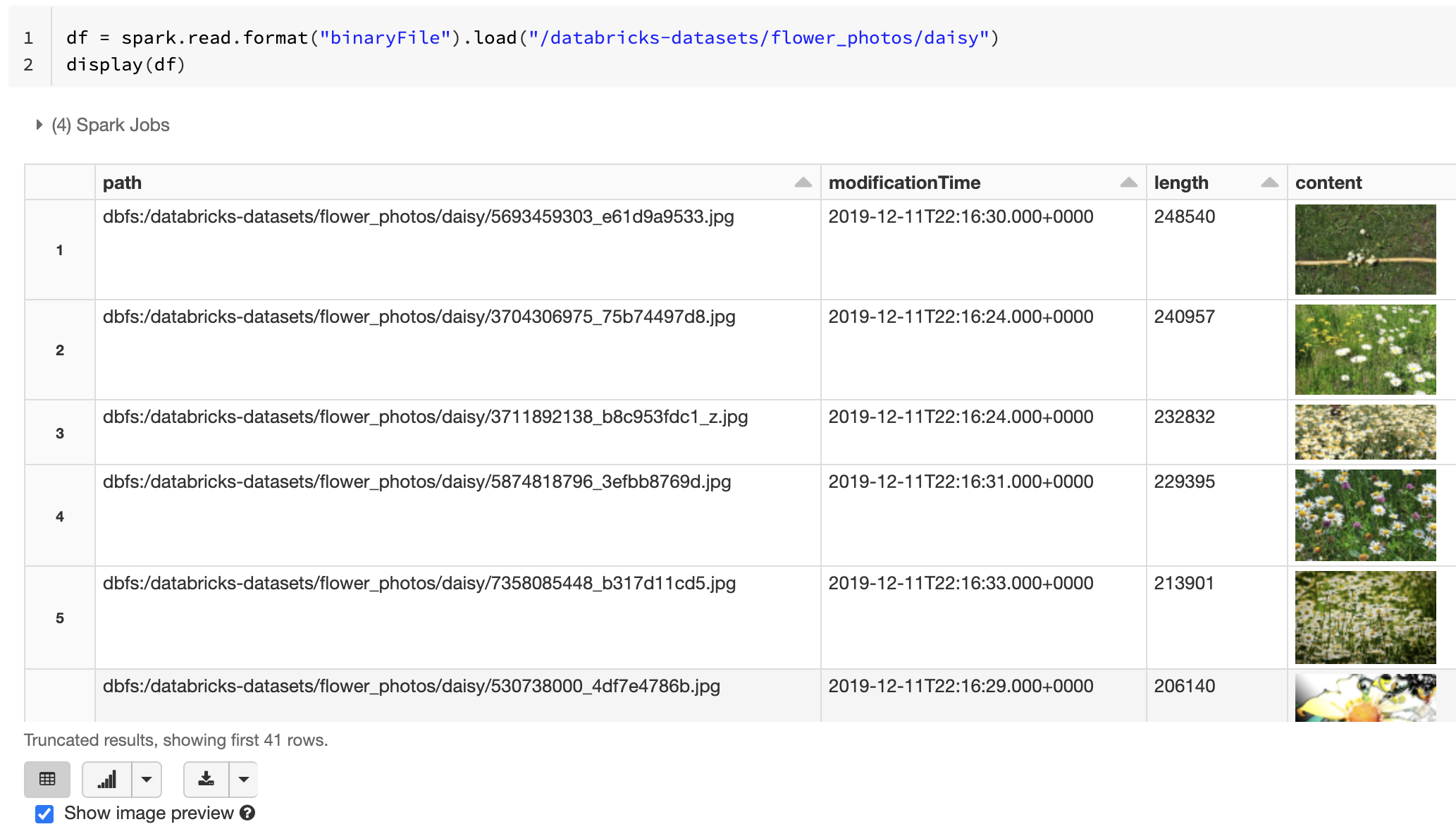
Cargar y mostrar imágenes
Databricks recomienda usar el origen de datos de archivo binario para cargar datos de imagen. La función de Databricks display admite la visualización de datos de imagen cargados mediante el origen de datos binario.
Si todos los archivos cargados tienen un nombre de archivo con una extensión de imagen, la vista previa de la imagen se habilita automáticamente:
Python
df = spark.read.format("binaryFile").load("/Volumes/<catalog>/<schema>/<volume>/images/")
display(df) # image thumbnails are rendered in the "content" column
Scala
val df = spark.read.format("binaryFile").load("/Volumes/<catalog>/<schema>/<volume>/images/")
df.show()
SQL
SELECT * FROM read_files(
'/Volumes/<catalog>/<schema>/<volume>/images/',
format => 'binaryFile'
)
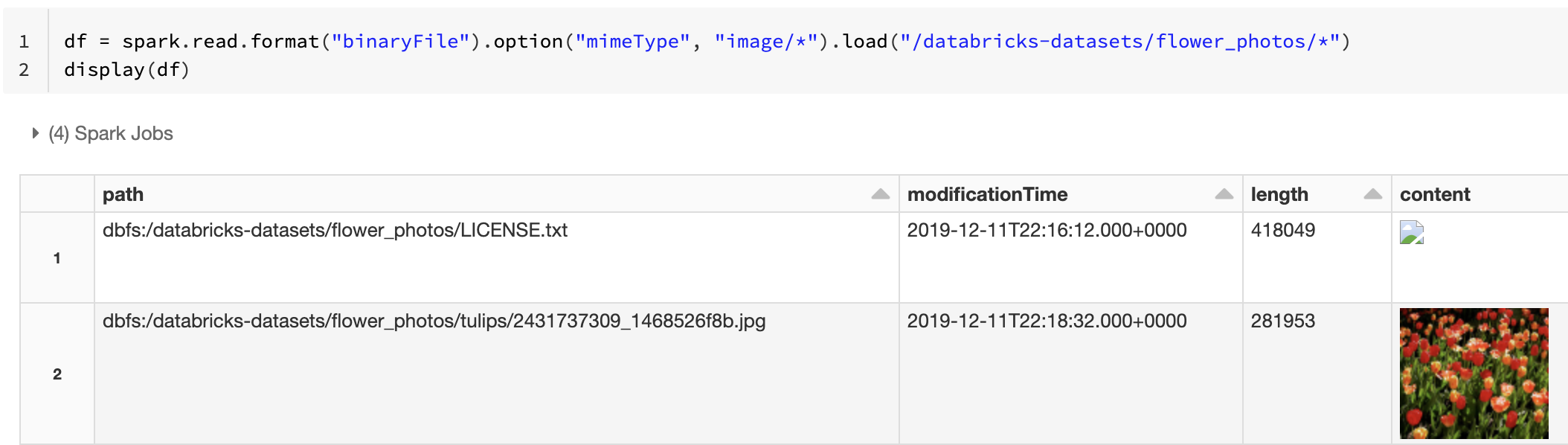
Como alternativa, puede forzar la funcionalidad de vista previa de la imagen mediante la opción mimeType con un valor de cadena "image/*" para anotar la columna binaria. Las imágenes se descodifican en función de su información de formato en el contenido binario. Los tipos de imagen admitidos son bmp, gif, jpeg, y png. Los archivos no admitidos aparecen como un icono con forma de imagen rota.
Python
df = spark.read.format("binaryFile").option("mimeType", "image/*").load("/Volumes/<catalog>/<schema>/<volume>/images/")
display(df)
Scala
val df = spark.read.format("binaryFile").option("mimeType", "image/*").load("/Volumes/<catalog>/<schema>/<volume>/images/")
df.show()
SQL
SELECT * FROM read_files(
'/Volumes/<catalog>/<schema>/<volume>/images/',
format => 'binaryFile',
mimeType => 'image/*'
)
Vea Solución de referencia para aplicaciones de imagen para conocer el flujo de trabajo recomendado para controlar datos de imagen.
Guardar en la tabla Delta
Para mejorar el rendimiento de lectura al volver a cargar datos, Azure Databricks recomienda guardar los datos cargados de archivos binarios en una tabla Delta.
Python
df.write.format("delta").saveAsTable("<catalog>.<schema>.<table>")
Scala
df.write.format("delta").saveAsTable("<catalog>.<schema>.<table>")
Recursos adicionales
- Leer archivos de imagen: si la carga de trabajo requiere campos de imagen estructurados como los datos de alto, ancho y canal en lugar de bytes sin procesar, el origen de datos de imagen proporciona un esquema descodificado.