Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Las carpetas de Git de Databricks se pueden usar en los flujos de CI/CD. Al configurar carpetas de Git de Databricks en el área de trabajo, puede usar el control de código fuente para trabajar en repositorios de Git e integrarlas en los flujos de trabajo de ingeniería de datos. Para obtener información general más completa sobre CI/CD con Azure Databricks, consulte CI/CD en Azure Databricks.
Flujos de uso
La mayor parte del trabajo en el desarrollo de la automatización para carpetas Git está en la configuración inicial para sus carpetas y en la comprensión de la API REST de Azure Databricks Repos que utiliza para automatizar las operaciones Git desde los trabajos de Azure Databricks. Antes de empezar a crear tu automatización y configurar carpetas, revisa los repositorios remotos de Git que incorporarás en tus flujos de automatización y selecciona los adecuados para las diferentes etapas de tu automatización, incluyendo desarrollo, integración, entorno de pruebas y producción.
- Flujo de administración: para flujos de producción, un administrador del área de trabajo de Azure Databricks configura carpetas de nivel superior en el área de trabajo para hospedar las carpetas git de producción. El administrador clona un repositorio de Git y una rama al crearlos, y podría dar a estas carpetas nombres significativos, como "Producción", "Prueba" o "Ensayo", que corresponden al propósito de los repositorios de Git remotos en los flujos de desarrollo. Para obtener más información, consulte Carpeta Git de producción.
- Flujo de usuarios: Un usuario puede crear una carpeta Git bajo
/Workspace/Users/<email>/basada en un repositorio Git remoto. Un usuario crea una rama local específica del usuario para el trabajo que el usuario confirmará en ella y enviará al repositorio remoto. Para obtener información sobre cómo colaborar en carpetas de Git específicas del usuario, consulte Colaboración con carpetas de Git. - Flujo de fusión: Los usuarios pueden crear pull requests (PR) después de insertar desde una carpeta Git. Cuando el PR se fusiona, la automatización puede extraer los cambios en las carpetas Git de producción utilizando la API Azure Databricks Repos.
Colaboración mediante carpetas de Git
Puede colaborar fácilmente con otros usuarios mediante carpetas de Git, extraer actualizaciones e insertar cambios directamente desde la interfaz de usuario de Azure Databricks. Por ejemplo, use una característica o una rama de desarrollo para agregar los cambios realizados en varias ramas.
En el flujo siguiente se describe cómo colaborar mediante una rama de características:
- Clona tu repositorio de Git existente hacia el área de trabajo de Databricks.
- Use la interfaz de usuario de carpetas de Git para crear una rama de características desde la rama principal. Puede crear y usar varias ramas de características para realizar su trabajo.
- Realice las modificaciones en los cuadernos de Azure Databricks y en otros archivos del repositorio.
- Confirme e inserte los cambios en el repositorio de Git remoto.
- Ahora, los colaboradores pueden clonar el repositorio de Git en su propia carpeta de usuario.
- Al trabajar en una nueva rama, un compañero de trabajo realiza cambios en los cuadernos y otros archivos de la carpeta Git.
- El colaborador confirma e inserta sus cambios en el repositorio de Git remoto.
- Cuando tú u otros colaboradores estén listos para fusionar el código, crea un PR en el sitio web del proveedor de Git. Revise el código con el equipo antes de combinar los cambios en la rama de implementación.
Nota:
Databricks recomienda que cada desarrollador trabaje en su propia rama. Para información sobre cómo resolver conflictos de combinación, consulte Resolución de conflictos de combinación.
Elija un enfoque de CI/CD
Databricks recomienda usar Conjuntos de recursos de Databricks para empaquetar e implementar los flujos de trabajo de CI/CD. Si prefiere implementar solo código controlado por código fuente en el área de trabajo, puede configurar una carpeta git de producción. Para obtener información general más completa sobre CI/CD con Azure Databricks, consulte CI/CD en Azure Databricks.
Sugerencia
Defina recursos como trabajos y canalizaciones en archivos de origen mediante agrupaciones y, a continuación, cree, implemente y administre agrupaciones en carpetas git del área de trabajo. Consulte Colaboración en agrupaciones en el área de trabajo.
Carpeta Git de producción
Las carpetas git de producción tienen un propósito diferente al de las carpetas de Git de nivel de usuario que se encuentran en la carpeta de usuario de /Workspace/Users/. Las carpetas Git de nivel de usuario actúan como comprobadores locales, donde los usuarios desarrollan y envían cambios de código. Por el contrario, los administradores de Databricks crean carpetas git de producción fuera de las carpetas de usuario y contienen ramas de implementación de producción. Las carpetas Git de producción contienen la fuente para los flujos de trabajo automatizados y solo deben actualizarse mediante programación cuando las solicitudes de extracción (PR) se fusionan en las ramas de implementación. En el caso de las carpetas de Git de producción, limite el acceso de usuario a solo ejecución y permita que solo los administradores y las entidades de servicio de Azure Databricks editen.
Para crear una carpeta de producción de Git:
Elija un repositorio de Git y una rama para la implementación.
Obtenga un principal de servicio y configure una credencial de Git para que el principal de servicio acceda a este repositorio de Git.
Cree una carpeta Azure Databricks Git para el repositorio Git y la rama en una subcarpeta en
Workspacededicada a un proyecto, equipo y etapa de desarrollo.Seleccione Compartir después de seleccionar la carpeta o Compartir (permisos) haciendo clic con el botón derecho en la carpeta en el árbol Área de trabajo . Configure la carpeta Git con los permisos siguientes:
- Establecer Can Run para cualquier usuario del proyecto
- Establezca Can Run para cualquier cuenta principal del servicio de Azure Databricks que ejecutará la automatización para ello.
- Si es adecuado para el proyecto, establezca Can View for all users in the workspace (Ver para todos los usuarios del área de trabajo) para fomentar la detección y el uso compartido.
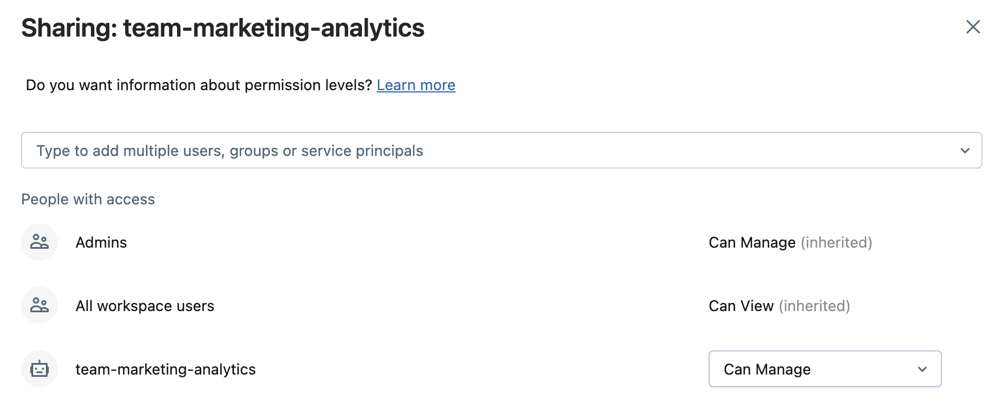
Selecciona Agregar.
Configure actualizaciones automatizadas en carpetas de Git de Databricks. Puede usar la automatización para mantener una carpeta git de producción sincronizada con la rama remota realizando una de las siguientes acciones:
- Utilice herramientas externas de CI/CD como GitHub Actions para extraer los últimos commits a una carpeta Git de producción cuando una pull request se fusiona en la rama de implementación. Para ver un ejemplo de Acciones de Github, consulte Ejecución de un flujo de trabajo de CI/CD que actualiza una carpeta git de producción.
- Si no puede acceder a herramientas externas de CI/CD, cree un trabajo programado para actualizar una carpeta Git en el área de trabajo con la rama remota. Programe un cuaderno sencillo con el código siguiente para ejecutarse periódicamente:
from databricks.sdk import WorkspaceClient w = WorkspaceClient() w.repos.update(w.workspace.get_status(path=”<git-folder-workspace-full-path>”).object_id, branch=”<branch-name>”)
Para más información sobre la automatización con la API de repositorios de Azure Databricks, consulte la documentación de la API REST de Databricks para Repositorios.