En este artículo se describe una arquitectura de recuperación ante desastres útil para los clústeres de Azure Databricks y los pasos necesarios para lograr ese diseño.
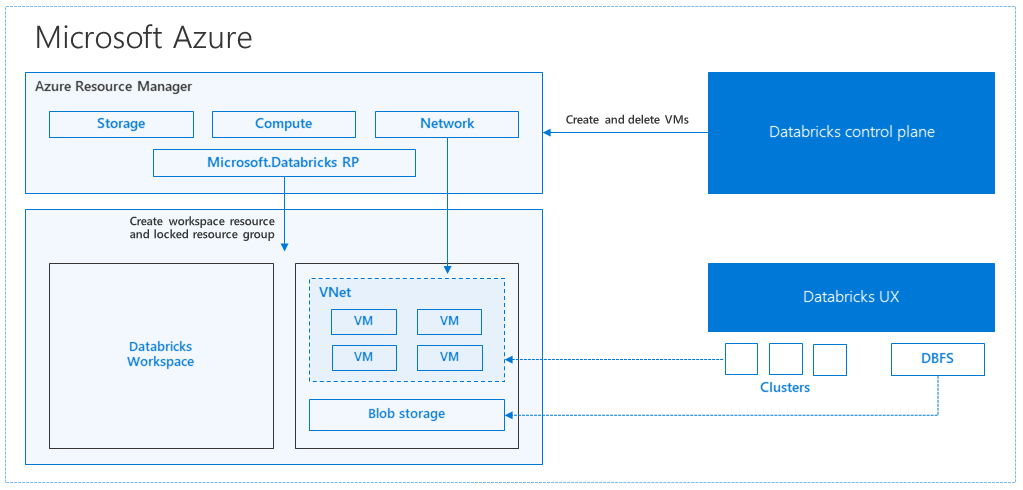
Al crear un área de trabajo de Azure Databricks desde Azure Portal, se implementa una aplicación administrada como un recurso de Azure en su suscripción, en la región de Azure seleccionada (por ejemplo, Oeste de EE. UU.). Esta aplicación se implementa en una instancia de Azure Virtual Network con un grupo de seguridad de red y una cuenta de Azure Storage, disponible en su suscripción. La red virtual proporciona seguridad a nivel de perímetro para el área de trabajo de Databricks y está protegida a través del grupo de seguridad de red. En el área de trabajo, puede crear clústeres de Databricks proporcionando el trabajo y tipo de máquina virtual de controlador y versión de Databricks Runtime. Los datos persistentes están disponibles en la cuenta de almacenamiento. Una vez creado el clúster, puede ejecutar trabajos a través de cuadernos, API REST o puntos de conexión ODBC/JDBC, adjuntándolos a un clúster concreto.
El plano de control de Databricks administra y supervisa el entorno de área de trabajo de Databricks. Cualquier operación de administración, como crear un clúster, se iniciará desde el plano de control. Todos los metadatos, como los trabajos programados, se almacenan en Azure Database y las copias de seguridad de la base de datos se replican geográficamente automáticamente para regiones emparejadas donde se implementa.
Una de las ventajas de esta arquitectura es que los usuarios pueden conectar Azure Databricks a cualquier recurso de almacenamiento en su cuenta. Una ventaja clave es que proceso (Azure Databricks) y almacenamiento se pueden escalar independientemente uno del otro.
En la descripción de la arquitectura anterior, hay una serie de componentes utilizados para una canalización de macrodatos con Azure Databricks: Azure Storage, Azure Database y otros orígenes de datos. Azure Databricks es el proceso para la canalización de macrodatos. Es efímero por naturaleza, lo que significa que mientras los datos siguen estando disponibles en Azure Storage, el proceso (clúster de Azure Databricks) se puede finalizar para que no tenga que pagar por proceso cuando no lo necesita. El proceso (Azure Databricks) y los orígenes de almacenamiento tienen que estar en la misma región para que los trabajos no sufran una latencia elevada.
Para crear su propia topología de recuperación ante desastres regional, siga estos requisitos:
Para prepararse para desastres regionales, debe mantener explícitamente otro conjunto de áreas de trabajo de Azure Databricks en una región secundaria. Consulte Recuperación ante desastres.
Nuestras herramientas recomendadas para la recuperación ante desastres son principalmente Terraform (para replicación infra) y Delta Deep Clone (para la replicación de datos).
Instalación de la CLI de Databricks
En los ejemplos de este artículo se usa la interfaz de la línea de comandos (CLI) de Databricks, que es un contenedor fácil de usar a través de la API de REST de Azure Databricks.
Antes de realizar cualquier paso de migración, instale la CLI de Databricks en su equipo local o máquina virtual. Para más información, consulte Instalación de la CLI de Databricks
Nota
Los scripts de Python proporcionados en este artículo funcionan con Python 2.7 y versiones posteriores.
Configuración de dos perfiles.
Siguiendo los pasos de _, configure dos perfiles: uno para el espacio de trabajo primario y otro para el secundario.
databricks configure --profile primary
databricks configure --profile secondary
Los bloques de código de este artículo cambian entre los perfiles en cada paso mediante el comando correspondiente del área de trabajo. Asegúrese de que los nombres de los perfiles creados se sustituyen en cada bloque de código.
EXPORT_PROFILE = "primary"
IMPORT_PROFILE = "secondary"
Puede cambiar manualmente en la línea de comandos si es necesario:
databricks workspace list --profile primary
databricks workspace list --profile secondary
Migración de usuarios de Microsoft Entra ID (anteriormente Azure Active Directory)
Agregue manualmente los mismos usuarios de Microsoft Entra ID (anteriormente Azure Active Directory) que existen en el área de trabajo principal al área de trabajo secundaria.
Migración de las carpetas de usuario y los blocs de notas
Use el siguiente código de Python para migrar los entornos de usuario de espacio aislado, que incluyen la estructura de carpetas anidadas y blocks de notas por usuario.
Nota
Las bibliotecas no se copian en este paso, ya que la API subyacente no es compatible con ellas.
Copie y guarde el siguiente script de Python en un archivo y ejecútelo en la línea de comandos. Por ejemplo, python scriptname.py.
import sys
import os
import subprocess
from subprocess import call, check_output
EXPORT_PROFILE = "primary"
IMPORT_PROFILE = "secondary"
user_list_out = check_output(["databricks", "workspace", "list", "/Users", "--profile", EXPORT_PROFILE])
user_list = (user_list_out.decode(encoding="utf-8")).splitlines()
print (user_list)
for user in user_list:
print (("Trying to migrate workspace for user ") + user)
subprocess.call(str("mkdir -p ") + str(user), shell = True)
export_exit_status = call("databricks workspace export_dir /Users/" + str(user) + " ./" + str(user) + " --profile " + EXPORT_PROFILE, shell = True)
if export_exit_status==0:
print ("Export Success")
import_exit_status = call("databricks workspace import_dir ./" + str(user) + " /Users/" + str(user) + " --profile " + IMPORT_PROFILE, shell=True)
if import_exit_status==0:
print ("Import Success")
else:
print ("Import Failure")
else:
print ("Export Failure")
print ("All done")
Migración de configuraciones de clúster
Una vez que se han migrado los blocs de notas, tiene la opción de migrar las configuraciones de clúster a la nueva área de trabajo. Es casi un paso totalmente automatizado mediante la CLI de Databricks, a menos que quiera realizar la migración selectiva de la configuración del clúster.
Nota
No hay ningún punto de conexión de configuración de creación de clúster, y este script intenta crear cada clúster de forma inmediata. Si no hay suficientes núcleos disponibles en su suscripción, se puede producir un error en la creación del clúster. El error se puede ignorar, siempre y cuando la configuración se haya transferido correctamente.
El siguiente script proporcionado imprime una asignación de los identificadores de clúster antiguos a los nuevos, que podrían usarse para la migración de trabajo más adelante (para los trabajos que están configurados para usar clústeres existentes).
Copie y guarde el siguiente script de Python en un archivo y ejecútelo en la línea de comandos. Por ejemplo, python scriptname.py.
import sys
import os
import subprocess
import json
from subprocess import call, check_output
EXPORT_PROFILE = "primary"
IMPORT_PROFILE = "secondary"
clusters_out = check_output(["databricks", "clusters", "list", "--profile", EXPORT_PROFILE])
clusters_info_list = str(clusters_out.decode(encoding="utf-8")).splitlines()
print("Printing Cluster info List")
print(clusters_info_list)
clusters_list = []
for cluster_info in clusters_info_list:
if cluster_info != '':
clusters_list.append(cluster_info.split(None, 1)[0])
cluster_req_elems = ["num_workers","autoscale","cluster_name","spark_version","spark_conf","node_type_id","driver_node_type_id","custom_tags","cluster_log_conf","spark_env_vars","autotermination_minutes","enable_elastic_disk"]
print("Printing Cluster element List")
print (cluster_req_elems)
print(str(len(clusters_list)) + " clusters found in the primary site" )
print ("---------------------------------------------------------")
cluster_old_new_mappings = {}
i = 0
for cluster in clusters_list:
i += 1
print("Checking cluster " + str(i) + "/" + str(len(clusters_list)) + " : " +str(cluster))
cluster_get_out_f = check_output(["databricks", "clusters", "get", "--cluster-id", str(cluster), "--profile", EXPORT_PROFILE])
cluster_get_out=str(cluster_get_out_f.decode(encoding="utf-8"))
print ("Got cluster config from old workspace")
print (cluster_get_out)
cluster_req_json = json.loads(cluster_get_out)
cluster_json_keys = cluster_req_json.keys()
if cluster_req_json['cluster_source'] == u'JOB' :
print ("Skipping this cluster as it is a Job cluster : " + cluster_req_json['cluster_id'] )
print ("---------------------------------------------------------")
continue
for key in cluster_json_keys:
if key not in cluster_req_elems:
print (cluster_req_json)
cluster_req_json.popitem(key, None)
strCurrentClusterFile = "tmp_cluster_info.json"
if os.path.exists(strCurrentClusterFile) :
os.remove(strCurrentClusterFile)
fClusterJSONtmp = open(strCurrentClusterFile,"w+")
fClusterJSONtmp.write(json.dumps(cluster_req_json))
fClusterJSONtmp.close()
cluster_create_out = check_output(["databricks", "clusters", "create", "--json-file", strCurrentClusterFile , "--profile", IMPORT_PROFILE])
cluster_create_out_json = json.loads(cluster_create_out)
cluster_old_new_mappings[cluster] = cluster_create_out_json['cluster_id']
print ("Cluster create request sent to secondary site workspace successfully")
print ("---------------------------------------------------------")
if os.path.exists(strCurrentClusterFile) :
os.remove(strCurrentClusterFile)
print ("Cluster mappings: " + json.dumps(cluster_old_new_mappings))
print ("All done")
print ("P.S. : Please note that all the new clusters in your secondary site are being started now!")
print (" If you won't use those new clusters at the moment, please don't forget terminating your new clusters to avoid charges")
Migración de la configuración de trabajos
Si ha migrado las configuraciones de clúster en el paso anterior, puede optar a migrar las configuraciones de trabajo a la nueva área de trabajo. Es un paso totalmente automatizado mediante la CLI de Databricks, a menos que quiera realizar la migración selectiva de la configuración de trabajos en lugar de hacerlo para todos los trabajos.
Nota
La configuración para un trabajo programado contiene también la información de "programación", por lo que de forma predeterminada empezará a trabajar según el tiempo configurado en cuanto se haya migrado. Por lo tanto, el bloque de código siguiente quita cualquier información de programación durante la migración (para evitar ejecuciones duplicadas en áreas de trabajo antiguas y nuevas). Configure las programaciones de esos trabajos una vez que esté listo para la migración.
La configuración del trabajo requiere una configuración para un clúster nuevo o uno ya existente. Si usa el clúster existente, el script o código a continuación intentará reemplazar el antiguo identificador del clúster con el nuevo.
Copie y guarde el siguiente script de Python en un archivo. Reemplace el valor de old_cluster_id y new_cluster_id con el resultado de migración de clúster realizada en el paso anterior. Ejecútelo en la línea de comandos, por ejemplo, python scriptname.py.
import sys
import os
import subprocess
import json
from subprocess import call, check_output
EXPORT_PROFILE = "primary"
IMPORT_PROFILE = "secondary"
cluster_old_new_mappings = {"0227-120427-tryst214": "0229-032632-paper88"}
try:
jobs_out = check_output(["databricks", "jobs", "list", "--profile", EXPORT_PROFILE])
jobs_info_list = jobs_out.splitlines()
except:
print("No jobs to migrate")
sys.exit(0)
jobs_list = []
for jobs_info in jobs_info_list:
jobs_list.append(jobs_info.split(None, 1)[0])
for job in jobs_list:
print("Trying to migrate " + str(job))
job_get_out = check_output(["databricks", "jobs", "get", "--job-id", job, "--profile", EXPORT_PROFILE])
print("Got job config from old workspace")
job_req_json = json.loads(job_get_out)
job_req_settings_json = job_req_json['settings']
job_req_settings_json.pop('schedule', None)
if 'existing_cluster_id' in job_req_settings_json:
if job_req_settings_json['existing_cluster_id'] in cluster_old_new_mappings:
job_req_settings_json['existing_cluster_id'] = cluster_old_new_mappings[job_req_settings_json['existing_cluster_id']]
else:
print("Mapping not available for old cluster id " + str(job_req_settings_json['existing_cluster_id']))
continue
call(["databricks", "jobs", "create", "--json", json.dumps(job_req_settings_json), "--profile", IMPORT_PROFILE])
print("Sent job create request to new workspace successfully")
print("All done")
Migración de bibliotecas
Actualmente no hay ninguna manera sencilla de migrar las bibliotecas de un área de trabajo a otra. Vuelva a instalar esas bibliotecas en la nueva área de trabajo manualmente. Puede automatizarlo mediante la CLI de Databricks para cargar bibliotecas personalizadas en el área de trabajo.
Migración de montajes de Azure Blob Storage y Azure Data Lake Storage
Vuelva a montar manualmente todos los puntos de montaje de Azure Blob Storage y Azure Data Lake Storage (Gen 2) mediante una solución basada en cuaderno. Los recursos de almacenamiento se habrían montado en el área de trabajo principal, y esto mismo tiene que repetirse en el área de trabajo secundario. No hay ninguna API externa para montajes.
Migración de los scripts de inicialización de clúster
Los scripts de inicialización de clúster se pueden migrar desde la antigua a la nueva área de trabajo mediante la CLI de Databricks. Primero copie los scripts necesarios en el escritorio local o máquina virtual. A continuación, copie esos scripts en la nueva área de trabajo en la misma ruta de acceso.
Nota
Si tiene scripts de inicialización almacenados en DBFS, mígrelos primero a una ubicación admitida. Consulte _.
// Primary to local
databricks fs cp dbfs:/Volumes/my_catalog/my_schema/my_volume/ ./old-ws-init-scripts --profile primary
// Local to Secondary workspace
databricks fs cp old-ws-init-scripts dbfs:/Volumes/my_catalog/my_schema/my_volume/ --profile secondary
Reconfiguración y reaplicación manual del control de acceso.
Si el área de trabajo principal existente está configurada para usar el nivel Premium o Enterprise (SKU), es probable que también esté usando el control de acceso.
Si usa el control de acceso, vuelva a aplicarlo manualmente a los recursos (cuadernos, clústeres, trabajos, tablas).
Si usa otros servicios de Azure, asegúrese de implementar los procedimientos recomendados de la recuperación ante desastres también para ellos. Por ejemplo, si elige usar una instancia de Hive Metastore externa, debe tener en cuenta la recuperación ante desastres de Azure SQL Database, Azure HDInsight o Azure Database for MySQL . Para obtener información general acerca de la recuperación ante desastres, consulte Error y recuperación ante desastres para aplicaciones de Azure.