Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Los administradores del área de trabajo y los usuarios con privilegios suficientes pueden configurar y administrar almacenes de SQL. En este artículo se describe cómo crear, editar y supervisar almacenes de SQL existentes.
También puede crear almacenes de SQL mediante la API de almacenes de SQL o Terraform.
Databricks recomienda usar almacenes de SQL sin servidor cuando estén disponibles.
Nota
La mayoría de los usuarios no pueden crear almacenes de SQL, pero pueden reiniciar cualquier almacenamiento de SQL al que puedan conectarse. Consulte Conectarse a un almacén SQL.
Requisitos
Los almacenes de SQL tienen los siguientes requisitos:
- Para crear un almacén de SQL, debe ser administrador del área de trabajo o un usuario con permisos de creación de clústeres sin restricciones.
- Antes de poder crear un almacén de SQL sin servidor en una región que admita la característica, es posible que se requieran algunos pasos. Consulte Configuración de almacenes sql sin servidor.
- En el caso de los almacenes de SQL clásicos o pro, la cuenta de Azure debe tener una cuota de vCPU adecuada. La cuota predeterminada de vCPU suele ser adecuada para crear un almacén de SQL sin servidor, pero es posible que no sea suficiente para escalar el almacén de SQL o para crear almacenes adicionales. Consulte Cuota de vCPU de Azure requerida para almacenes SQL clásicos y pro. Puede solicitar una cuota de vCPU adicional. Su cuenta de Azure puede tener limitaciones en la cantidad de cuota de vCPU que puede solicitar. Póngase en contacto con el equipo de la cuenta de Azure para obtener más información.
Creación de un almacén de SQL
Para crear un almacén de SQL mediante la interfaz de usuario web:
- Haga clic en Almacenes de SQL en la barra lateral.
- Haga clic en Crear almacenamiento de SQL.
- Escriba un nombre para el almacén.
- (Opcional) Configure las opciones de almacenamiento. Consulte Configuración de la configuración de un almacenamiento de SQL.
- (Opcional) Configure las opciones avanzadas. Consulte Opciones avanzadas.
- Haga clic en Crear.
- (Opcional) Configure el acceso a un almacenamiento de SQL. Consulte Administración de un almacenamiento de SQL.
El almacenamiento creado se inicia automáticamente.
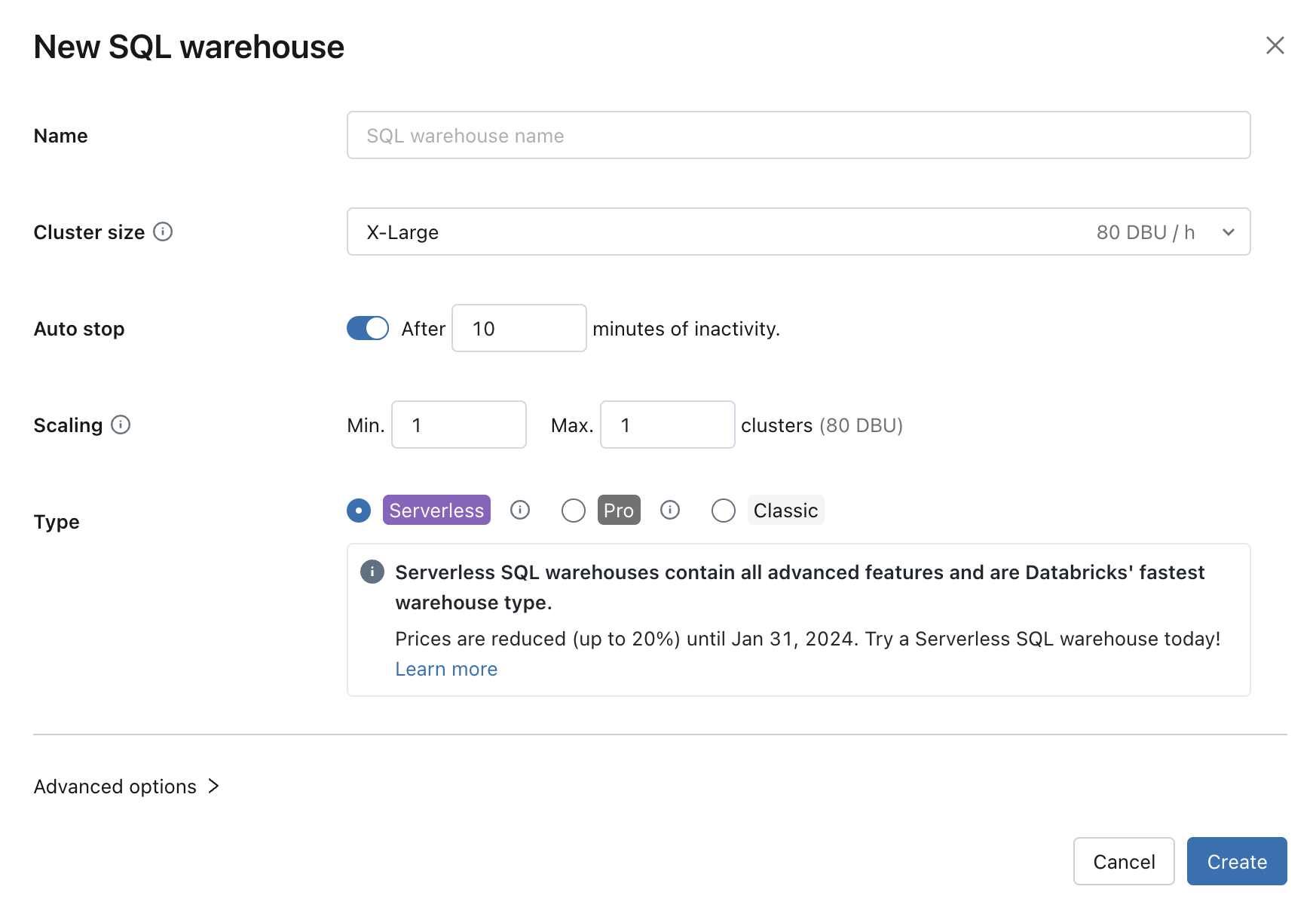
Configuración de un almacenamiento de SQL
Puede modificar la siguiente configuración al crear o editar un almacén de SQL:
El tamaño del clúster representa el tamaño del nodo controlador y el número de nodos de trabajo asociados al clúster. El valor predeterminado es X-Large. Para reducir la latencia de las consultas, aumente el tamaño.
La detención automática determina si el almacenamiento se detiene si está inactivo durante el número de minutos especificado. Los almacenes de SQL inactivos siguen acumulando cargos de DBU y de instancia en la nube hasta que se detienen.
- Almacenes de SQL pro y clásicos: el valor predeterminado es de 45 minutos, lo que se recomienda para uso típico. El mínimo es de 10 minutos.
- Almacenes de SQL sin servidor: el valor predeterminado es de 10 minutos, lo que se recomienda para uso típico. El mínimo es de 5 minutos cuando se usa la interfaz de usuario. Tenga en cuenta que puede crear un almacén de SQL sin servidor mediante la API de almacenes de SQL, en cuyo caso puede establecer el valor de detención automática en un mínimo de 1 minuto.
El escalado establece el número mínimo y máximo de clústeres que se usarán para una consulta. El valor predeterminado tiene un mínimo y un máximo de un clúster. Puede aumentar el número máximo de clústeres si desea controlar más usuarios simultáneos para una consulta determinada. Azure Databricks recomienda un clúster para cada 10 consultas simultáneas.
Para mantener un rendimiento óptimo, Azure Databricks recicla periódicamente los clústeres que se han ejecutado durante más de 24 horas. Durante el reciclaje, Azure Databricks abre un nuevo clúster y comienza a realizar la transición de nuevas consultas a él al retirar el clúster anterior. Las consultas existentes continúan ejecutándose en el clúster anterior hasta que se completen.
Durante este período de transición, puede ver temporalmente un recuento de clústeres que supere el máximo configurado. Por ejemplo, si el número máximo de clústeres está establecido en 1, es posible que vea 2 clústeres activos durante el reciclaje. Azure Databricks espera a que todas las consultas del clúster anterior finalicen antes de finalizarla. Si el clúster antiguo no se puede finalizar en un plazo de 4 horas debido a consultas de larga duración, Azure Databricks finaliza el clúster de forma forzada para completar el proceso de reciclaje.
El tipo determina los tipos de almacén. Si está habilitado "sin servidor" en su cuenta, este será el valor predeterminado. Consulte tipos de almacenamiento de SQL para obtener la lista.
Opciones avanzadas
Configure las siguientes opciones avanzadas expandiendo el área Opciones avanzadas cuando cree un nuevo almacén de SQL o edite un almacén de SQL existente. También puede configurar estas opciones mediante el uso de la API del almacén de SQL.
Etiquetas: las etiquetas le permiten supervisar el costo de los recursos en la nube utilizados por los usuarios y los grupos de la organización. Las etiquetas se especifican como pares clave-valor.
Unity Catalog: si Unity Catalog está habilitado en el área de trabajo, es el valor predeterminado para todos los almacenes nuevos del área de trabajo. Si el Unity Catalog no está habilitado en el área de trabajo, no verá esta opción. Consulte ¿Qué es Unity Catalog?.
Canal: use el canal de versión preliminar para probar la nueva funcionalidad, incluidas las consultas y los paneles, antes de que se convierta en el SQL estándar de Databricks.
Use las notas de la versión para obtener información sobre lo que se encuentra en la versión preliminar más reciente.
Importante
Databricks recomienda no usar una versión preliminar para cargas de trabajo de producción. Dado que solo los administradores del área de trabajo pueden ver las propiedades de un almacenamiento, incluido su canal, considere la posibilidad de indicar que un almacenamiento de SQL de Databricks usa una versión preliminar en el nombre de ese almacenamiento para evitar que los usuarios lo usen para cargas de trabajo de producción.
Establecimiento de un almacenamiento predeterminado de nivel de usuario
Puede establecer una instancia predeterminada de SQL Warehouse para usarla automáticamente al ejecutar consultas. Esta configuración invalida el almacenamiento predeterminado de nivel de área de trabajo, si existe uno. Ver Establecer una instancia predeterminada de SQL Warehouse para el área de trabajo.
Use el menú desplegable para establecer un nuevo valor predeterminado desde cualquier superficie de creación de SQL de Databricks, incluido el editor de SQL, paneles de IA/BI, Genie, Alertas y el Explorador de catálogos.
Para establecer un almacenamiento predeterminado de nivel de usuario:
Haga clic en el menú desplegable para seleccionar el cómputo de almacén SQL.
Haga clic en Personalizar el almacén predeterminado.

Elija alguna de las acciones siguientes:
- Valor predeterminado del área de trabajo: Mantenga esta configuración para usar el conjunto de almacenamiento predeterminado para el área de trabajo.
- Última selección: La selección predeterminada muestra el último almacén que seleccionaste como recurso de cómputo.
- Valor predeterminado personalizado: Elija una nueva instancia de SQL Warehouse como almacenamiento predeterminado. Esto invalida una configuración predeterminada de nivel de área de trabajo. Después de configurarlo, el almacén seleccionado se designa automáticamente como cómputo. Para invalidar manualmente esta configuración, elija otro almacén de SQL en el menú desplegable.
Administración de un almacén de SQL
Los administradores del área de trabajo y los usuarios con privilegios CAN MANAGE en un almacén SQL pueden completar las siguientes tareas en un almacén SQL existente:
Para detener un almacén en ejecución, haga clic en el icono de detención situado junto al almacén.
Para iniciar un almacén detenido, haga clic en el icono de inicio situado junto al almacén.
Para editar un almacén, haga clic en el icono de
 . A continuación, haga clic en Editar.
. A continuación, haga clic en Editar.Para agregar y editar permisos, haga clic en el icono del
y luego en Permisos.- Asignar Puede ver para permitir a los usuarios ver los almacenes de SQL, incluidos el historial de consultas y los perfiles de consulta. Estos usuarios no pueden ejecutar consultas en el almacenamiento.
- Asigne Puede usar a los usuarios que necesitan ejecutar consultas en el almacenamiento.
- Asigne Puede supervisar a usuarios avanzados para solucionar problemas y optimizar el rendimiento de las consultas. Puede supervisar el permiso permite a los usuarios ejecutar consultas y supervisar almacenes de SQL, incluidos el historial de consultas y los perfiles de consulta.
- Asigne Puede administrar a los usuarios responsables del dimensionamiento y los límites de gasto de almacenamiento de SQL.
- Es propietario se aplica automáticamente al creador de almacenamiento de SQL.
Para obtener información sobre los niveles de los permisos, consulte ACL del almacén de SQL.
Para actualizar una instancia de un almacenamiento de SQL a sin servidor, haga clic en el menú kebab
y, a continuación, haga clic en Actualizar a sin servidor.Para eliminar un almacén, haga clic en el icono de
. A continuación, haga clic en Eliminar.
Nota
Póngase en contacto con su representante de Databricks para restaurar almacenes eliminados en un plazo de 14 días.