Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
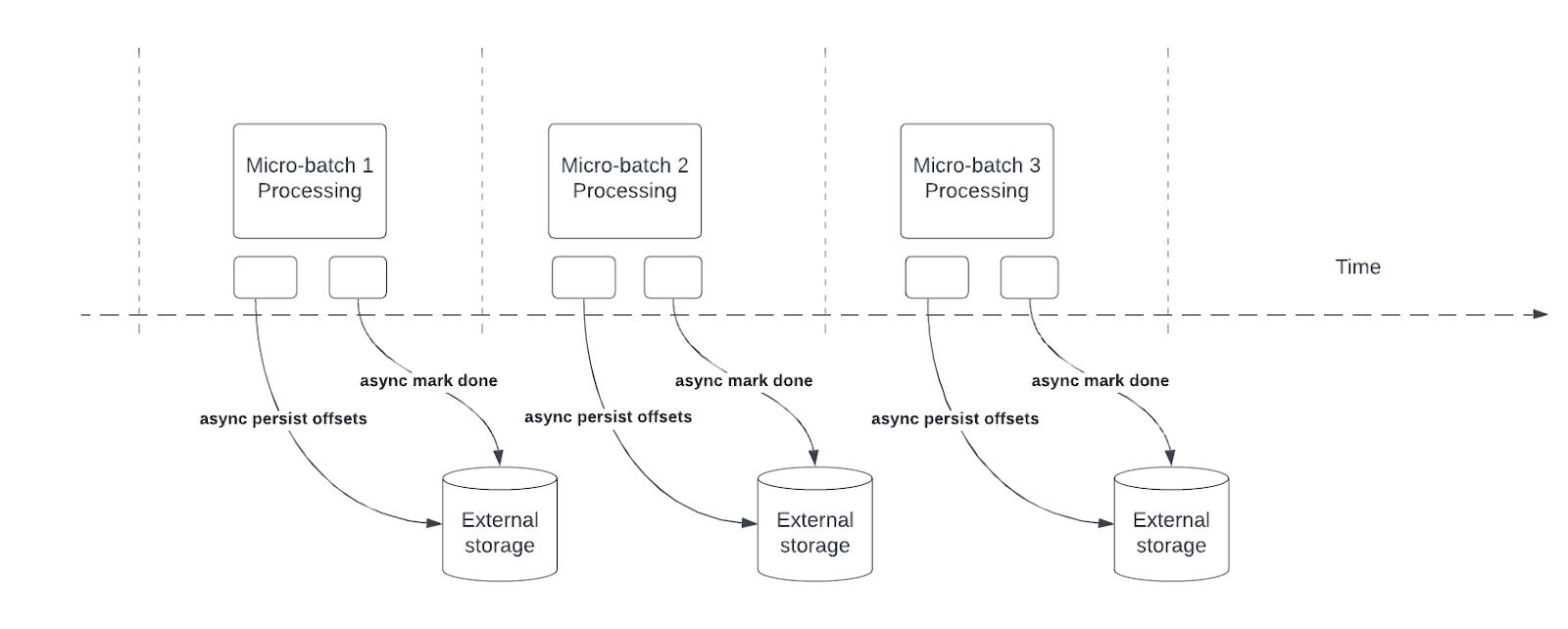
El seguimiento de progreso asincrónico reduce la latencia de las canalizaciones de Structured Streaming al permitir que las consultas actualicen de forma asincrónica el progreso del punto de control y procesen los datos de cada microproceso.
Durante el procesamiento de consultas, Structured Streaming conserva y administra los desplazamientos para medir el progreso de la consulta en offsetLog y commitLog en cada microlote. Sin el seguimiento de progreso asincrónico, las operaciones de gestión de compensaciones afectan directamente a la latencia de procesamiento de datos porque el procesamiento de datos no puede continuar hasta que se completen.
Nota
El seguimiento de progreso asincrónico no es compatible con desencadenadores Trigger.once o Trigger.availableNow. Si se habilita, las consultas de Structured Streaming con Trigger.once o Trigger.availableNow fallan.
Opciones de configuración
| Opción | Predeterminado | Descripción |
|---|---|---|
asyncProgressTrackingEnabled |
false |
Si se va a habilitar el seguimiento de progreso asincrónico. |
asyncProgressTrackingCheckpointIntervalMs |
1000 |
Intervalo en milisegundos entre escrituras para desplazamientos y confirmaciones de finalización. |
Habilitación del seguimiento de progreso asincrónico
Para habilitar el seguimiento de progreso asincrónico, establezca asyncProgressTrackingEnabled en true:
Python
stream = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "in")
.load()
)
query = (stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.start()
)
Scala
val stream = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "in")
.load()
val query = stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.start()
Mejora el caudal modificando la frecuencia de los puntos de control
La frecuencia de punto de comprobación predeterminada de 1000 milisegundos tiene un buen rendimiento para la mayoría de las consultas. Cuando las operaciones de gestión de compensación se producen más rápido de lo que el seguimiento del progreso asincrónico puede procesarlas, se acumula un retraso en las operaciones de gestión de compensación. Para evitar que el trabajo pendiente crezca aún más, el seguimiento de progreso asincrónico puede bloquear o ralentizar el procesamiento de datos, lo que podría reducir las ventajas de latencia esperadas.
En este escenario, Databricks recomienda aumentar el intervalo de punto de comprobación:
Python
query = (stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.option("asyncProgressTrackingCheckpointIntervalMs", "5000")
.start()
)
Scala
val query = stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.option("asyncProgressTrackingCheckpointIntervalMs", "5000")
.start()
Nota
El tiempo de recuperación de errores aumenta con el tiempo de intervalo de punto de comprobación. En caso de fallo, una canalización debe procesar nuevamente todos los datos desde el punto de control exitoso anterior. Antes de realizar este cambio en la producción, tenga en cuenta el equilibrio entre una menor latencia durante el procesamiento normal en comparación con el tiempo de recuperación en caso de error.
Desactivar el seguimiento de progreso asincrónico
Cuando se habilita el seguimiento de progreso asincrónico, el flujo de datos no garantiza el progreso del punto de control para cada lote. Debe controlar el progreso antes de poder desactivar esta característica.
Para desactivarlo, siga estos pasos:
Procese al menos dos microlotes con
asyncProgressTrackingEnabledestablecido entrueyasyncProgressTrackingCheckpointIntervalMsestablecido en0:Python
query = (stream.writeStream .format("kafka") .option("topic", "out") .option("checkpointLocation", "/tmp/checkpoint") .option("asyncProgressTrackingEnabled", "true") .option("asyncProgressTrackingCheckpointIntervalMs", "0") .start() )Scala
val query = stream.writeStream .format("kafka") .option("topic", "out") .option("checkpointLocation", "/tmp/checkpoint") .option("asyncProgressTrackingEnabled", "true") .option("asyncProgressTrackingCheckpointIntervalMs", "0") .start()Detenga la consulta:
Python
query.stop()Scala
query.stop()Desactive el seguimiento de progreso asincrónico y reinicie la consulta:
Python
query = (stream.writeStream .format("kafka") .option("topic", "out") .option("checkpointLocation", "/tmp/checkpoint") .option("asyncProgressTrackingEnabled", "false") .start() )Scala
val query = stream.writeStream .format("kafka") .option("topic", "out") .option("checkpointLocation", "/tmp/checkpoint") .option("asyncProgressTrackingEnabled", "false") .start()
Si desactiva el seguimiento de progreso asincrónico sin seguir los pasos anteriores, es posible que encuentre el siguiente error:
java.lang.IllegalStateException: batch x doesn't exist
En los registros del controlador, es posible que vea el siguiente error:
The offset log for batch x doesn't exist, which is required to restart the query from the latest batch x from the offset log. Please ensure there are two subsequent offset logs available for the latest batch via manually deleting the offset file(s). Please also ensure the latest batch for commit log is equal or one batch earlier than the latest batch for offset log.
Limitaciones
- En el caso de los receptores de Kafka, el seguimiento asincrónico del progreso solo es compatible con canalizaciones sin estado.
- El seguimiento de progreso asincrónico no garantiza el procesamiento de un extremo a otro exactamente una vez porque los intervalos de desplazamiento de un lote pueden cambiar en caso de error. Algunos sumideros, como Kafka, nunca ofrecen garantías de exactamente una vez.