Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En esta página se describe cómo usar tablas Delta como orígenes y receptores para Spark Structured Streaming con readStream y writeStream. Delta Lake resuelve problemas comunes de rendimiento y confiabilidad para los archivos y sistemas de streaming. Entre las ventajas se encuentran las siguientes:
- Combina archivos pequeños producidos por la ingesta de baja latencia y mejoran el rendimiento.
- Mantenga el procesamiento "exactamente una vez" con más de una secuencia (o trabajos por lotes simultáneos).
- Descubra de forma eficaz nuevos archivos cuando se utilizan como fuente de transmisión.
Para obtener información sobre cómo cargar datos mediante tablas de streaming en Databricks SQL, consulte Uso de tablas de streaming en Databricks SQL.
Para obtener combinaciones estáticas de flujos con Delta Lake, consulte Combinaciones de stream-static.
Uso de tablas Delta como receptor
Puede escribir datos en una tabla Delta mediante Structured Streaming. El registro de transacciones de Delta Lake garantiza el procesamiento exactamente una vez, incluso cuando hay otras secuencias o consultas por lotes que se ejecutan simultáneamente en la tabla.
Al escribir en una tabla Delta usando un receptor de Structured Streaming, puede ver confirmaciones vacías con epochId = -1. Estos son los esperados y suelen producirse:
- En el primer lote de cada ejecución de la consulta de streaming (esto sucede cada lote para
Trigger.AvailableNow). - Cuando se cambia un esquema (por ejemplo, agregar una columna).
Estas confirmaciones vacías son intencionadas y no indican un error. No afectan a la exactitud ni al rendimiento de la consulta de ninguna manera significativa.
Note
La función VACUUMde Delta Lake quita todos los archivos no administrados por Delta Lake, pero omite los directorios que comienzan por _. Puede almacenar de forma segura puntos de control junto con otros datos y metadatos de una tabla Delta mediante una estructura de directorios como <table-name>/_checkpoints.
Supervisión del trabajo pendiente con métricas
Use las métricas siguientes para supervisar el trabajo pendiente de un proceso de consulta de streaming:
-
numBytesOutstanding: número de bytes que todavía se van a procesar en el trabajo pendiente. -
numFilesOutstanding: número de archivos que todavía están pendientes de procesar. -
numNewListedFiles: número de archivos de Delta Lake enumerados para calcular el trabajo pendiente de este lote. -
backlogEndOffset: la versión de la tabla Delta utilizada para calcular el trabajo pendiente.
En un cuaderno, visualice estas métricas en la pestaña Datos sin procesar en el tablero de progreso de consultas de streaming.
{
"sources": [
{
"description": "DeltaSource[file:/path/to/source]",
"metrics": {
"numBytesOutstanding": "3456",
"numFilesOutstanding": "8"
}
}
]
}
Modo de adición
De forma predeterminada, los flujos se ejecutan en modo de anexión y solo agregan nuevos registros a la tabla.
Utilice el método toTable al transmitir datos a tablas.
Python
(events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
)
Scala
events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
Modo completo
Utilice Structured Streaming con el modo completo para sustituir la tabla completa después de cada lote. Por ejemplo, puede actualizar continuamente una tabla de resumen agregada de eventos por cliente:
Python
(spark.readStream
.table("events")
.groupBy("customerId")
.count()
.writeStream
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.toTable("events_by_customer")
)
Scala
spark.readStream
.table("events")
.groupBy("customerId")
.count()
.writeStream
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.toTable("events_by_customer")
En el caso de las aplicaciones sin requisitos estrictos de latencia, puede ahorrar recursos informáticos y costos con desencadenadores de un solo uso, como AvailableNow. Por ejemplo, use este desencadenador para actualizar las tablas de agregación de resumen en una programación determinada, procesando solo los datos nuevos que han llegado desde la última actualización. Consulte AvailableNow: Procesamiento por lotes incremental.
Control de los cambios en las tablas delta de origen
Structured Streaming lee de forma incremental las tablas Delta. Cuando una consulta de streaming lee de una tabla Delta, los nuevos registros se procesan de manera idempotente a medida que las nuevas versiones de la tabla se confirman en la tabla de origen. Structured Streaming solo acepta entradas de anexión y produce una excepción si se producen modificaciones en la tabla Delta de origen. Por ejemplo, si una UPDATE, DELETE, MERGE INTO o OVERWRITE modifica una tabla Delta de origen que lee una consulta de streaming, la secuencia falla con un error.
Hay cuatro enfoques típicos para controlar los cambios ascendentes en las tablas delta de origen, en función del caso de uso. A continuación se proporciona una tabla de referencia y detalles sobre cada uno de ellos:
| Enfoque | Ventajas | Desventajas |
|---|---|---|
skipChangeCommits |
Simple, no requiere que escriba lógica compleja. Resulta útil para el procesamiento solo de adiciones en el que los cambios de origen se manejan por separado o para manejar temporalmente un registro incorrecto. | No propaga los cambios y solo procesa anexos. |
| Actualización completa | Además, simple, no requiere que escriba lógica compleja. Resulta útil para conjuntos de datos pequeños con cambios ascendentes poco frecuentes. | Caro para grandes conjuntos de datos. Requiere procesar nuevamente todas las tablas posteriores. |
| Cambio de fuente de distribución de datos | Procesar todos los tipos de cambio (inserciones, actualizaciones y eliminaciones). Databricks recomienda, siempre que sea posible, transmitir desde la fuente CDC de una tabla Delta en lugar de directamente desde la tabla. | Requiere que escriba lógica más compleja para controlar cada tipo de cambio. |
| Vistas materializadas | Alternativa sencilla a Structured Streaming que tiene propagación automática de cambios. | Mayor latencia. Solo está disponible en Las Canalizaciones Declarativas de Lakeflow Spark y Databricks SQL. |
Omitir confirmaciones de cambios ascendentes con skipChangeCommits
Establezca skipChangeCommits esta opción para pasar por alto las transacciones que eliminan o modifican los registros existentes, y para procesar solo los anexos. Esto resulta útil cuando no es necesario propagar los cambios a los datos existentes a través de la secuencia o cuando se prefiere una lógica independiente para controlar esos cambios. Puede activar y desactivar skipChangeCommits si necesita omitir temporalmente cambios puntuales.
Databricks recomienda usar skipChangeCommits para la mayoría de las cargas de trabajo que no usan fuentes de distribución de datos modificados.
Python
(spark.readStream
.option("skipChangeCommits", "true")
.table("source_table")
)
Scala
spark.readStream
.option("skipChangeCommits", "true")
.table("source_table")
Important
Si el esquema de una tabla Delta cambia después de que se inicie una lectura de streaming en la tabla, se produce un error en la consulta. Para la mayoría de los cambios de esquema, puede reiniciar la secuencia para resolver el error de coincidencia del esquema y continuar con el procesamiento.
En Databricks Runtime 12.2 LTS y versiones inferiores, no puede transmitir desde una tabla Delta con la asignación de columnas habilitada que haya experimentado una evolución del esquema no aditivo, como un cambio de nombre o una eliminación de columnas. Para obtener más detalles, consulte Asignación y streaming de columnas.
Note
En Databricks Runtime 12.2 LTS y versiones posteriores, skipChangeCommits reemplaza a ignoreChanges. En Databricks Runtime 11.3 LTS y versiones anteriores, ignoreChanges es la única opción admitida. Consulte Opción heredada: ignoreChanges para obtener más información.
Opción heredada: ignoreDeletes
ignoreDeletes es una opción heredada que solo gestiona las transacciones que eliminan datos en los límites de partición (es decir, elimina completamente las particiones). Si necesita controlar eliminaciones, actualizaciones u otras modificaciones que no son de partición, use skipChangeCommits en su lugar.
Python
(spark.readStream
.option("ignoreDeletes", "true")
.table("user_events")
)
Scala
spark.readStream
.option("ignoreDeletes", "true")
.table("user_events")
Opción heredada: ignoreChanges
ignoreChanges está disponible en Databricks Runtime 11.3 LTS y versiones posteriores. En Databricks Runtime 12.2 LTS y versiones posteriores, se reemplaza por skipChangeCommits.
Con ignoreChanges habilitado, los archivos de datos reescritos de la tabla de origen se vuelven a emitir después de una operación de modificación de datos como UPDATE, MERGE INTO, DELETE (dentro de las particiones) o OVERWRITE. Las filas sin cambios a menudo se emiten junto con las nuevas filas, por lo que los consumidores descendentes deben poder gestionar los duplicados. Las eliminaciones no se propagan hacia aguas abajo.
ignoreChanges tiene prioridad sobre ignoreDeletes.
En cambio, skipChangeCommits ignora completamente las operaciones de cambio de archivos. Los archivos de datos reescritos en la tabla de origen debido a operaciones de modificación de datos como UPDATE, MERGE INTO, DELETEy OVERWRITE se omiten por completo. Para reflejar los cambios en las tablas de origen de flujos, debe implementar una lógica independiente para propagar estos cambios.
Databricks recomienda usar skipChangeCommits para todas las cargas de trabajo nuevas. Para migrar una carga de trabajo de ignoreChanges a skipChangeCommits, refactorice la lógica de streaming.
Actualización completa de las tablas posteriores
Si los cambios ascendentes son poco frecuentes y los datos son lo suficientemente pequeños como para volver a procesar, puede eliminar el punto de control de streaming y la tabla de salida y, a continuación, reiniciar la secuencia desde el principio. Esto hace que el flujo vuelva a procesar todos los datos de la tabla de origen. Tenga en cuenta que este enfoque también requiere reprocesar todas las tablas posteriores que dependen de la salida de este flujo.
Este enfoque es más adecuado para conjuntos de datos o cargas de trabajo más pequeños en los que los cambios ascendentes son poco frecuentes y el costo de una actualización completa es aceptable.
Uso de la transmisión de datos de cambio
En el caso de las cargas de trabajo que procesan todos los tipos de cambios (inserciones, actualizaciones y eliminaciones), use la fuente de distribución de datos de cambios de Delta Lake. El flujo de datos de cambios registra los cambios a nivel de fila en una tabla Delta, permitiéndole transmitir esos cambios y escribir lógica para manejar cada tipo de cambio en las tablas posteriores. Este es el enfoque más sólido porque el código controla explícitamente cada tipo de evento de cambio. Consulte Uso del feed de datos de cambios de Delta Lake en Azure Databricks.
Si usa canalizaciones declarativas de Spark de Lakeflow, consulte Las API AUTO CDC: Simplificar la captura de datos de cambios con canalizaciones.
Important
En Databricks Runtime 12.2 LTS y versiones anteriores, no se puede transmitir desde el flujo de cambios de datos de una tabla Delta con mapeo de columnas habilitado que ha sufrido una evolución de esquema no aditivo, como renombrar o eliminar columnas. Consulte Mapeo y transmisión de columnas.
Uso de vistas materializadas
Las vistas materializadas controlan automáticamente los cambios ascendentes mediante la recomputación de los resultados cuando cambian los datos de origen. Si no necesita la menor latencia posible y desea evitar la administración de la complejidad del streaming, una vista materializada puede simplificar la arquitectura. Las vistas materializadas están disponibles en las Canalizaciones Declarativas de Lakeflow Spark y en Databricks SQL. Consulte Vistas materializadas.
Example
Por ejemplo, suponga que tiene una tabla user_events con columnas date, user_email y action que está particionada por date. Se extraen datos de la tabla user_events y es necesario eliminar datos de la misma debido al RGPD.
skipChangeCommits permite eliminar datos en varias particiones (en este ejemplo, filtrar por user_email). Utilice la sintaxis siguiente:
spark.readStream
.option("skipChangeCommits", "true")
.table("user_events")
Si actualiza un user_email con la instrucción UPDATE, se reescribe el archivo que contiene user_email en cuestión. Use skipChangeCommits para omitir los archivos de datos modificados.
Databricks recomienda utilizar skipChangeCommits en lugar de ignoreDeletes a menos que esté seguro de que las eliminaciones siempre son eliminaciones completas de particiones.
Utilice foreachBatch para escrituras de tabla idempotentes
Note
Databricks recomienda configurar una escritura de streaming independiente para cada receptor que quiera actualizar en lugar de usar foreachBatch. Escribe en múltiples destinos en foreachBatch reduce la paralelización y aumenta la latencia general porque las escrituras en varias tablas se serializan en foreachBatch.
Las tablas Delta son compatibles con las siguientes opciones de DataFrameWriter para hacer que las escrituras en varias tablas dentro de foreachBatch sean idempotentes:
-
txnAppId: cadena única que puede pasarse en cada escritura de DataFrame. Por ejemplo, puede usar el identificador de StreamingQuery comotxnAppId.txnAppIdpuede ser cualquier cadena única generada por el usuario y no tiene que estar relacionada con el identificador de secuencia. -
txnVersion: número que aumenta de forma monótona y que actúa como versión de transacción.
Delta Lake usa txnAppId y txnVersion para identificar e ignorar las escrituras duplicadas. Por ejemplo, después de que un error interrumpa una escritura por lotes, puede volver a ejecutar el lote con el mismo txnAppId y txnVersion para identificar e ignorar correctamente los duplicados. Consulte Uso de foreachBatch para escribir en receptores de datos arbitrarios.
Warning
Si elimina el punto de control de streaming y vuelve a iniciar la consulta con un nuevo punto de control, debe proporcionar un txnAppId diferente. Los nuevos puntos de control comienzan con un identificador de lote de 0. Delta Lake usa el identificador de lote y txnAppId como una clave única y omite los lotes con valores ya vistos.
En el ejemplo de código siguiente se muestra este patrón:
Python
app_id = ... # A unique string that is used as an application ID.
def writeToDeltaLakeTableIdempotent(batch_df, batch_id):
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 1
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 2
streamingDF.writeStream.foreachBatch(writeToDeltaLakeTableIdempotent).start()
Scala
val appId = ... // A unique string that is used as an application ID.
streamingDF.writeStream.foreachBatch { (batchDF: DataFrame, batchId: Long) =>
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 1
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 2
}
Inserción o actualización desde consultas de streaming mediante foreachBatch
Puede usar merge y foreachBatch para escribir upserts complejos desde una consulta de streaming en una tabla Delta. Consulte Uso de foreachBatch para escribir en receptores de datos arbitrarios.
Este enfoque tiene muchas aplicaciones:
- Mejore el rendimiento de escritura usando el modo de salida
update, mientras que el modo de salidacompleterequiere volver a escribir toda la tabla de resultados para cada microbatch. - Aplique continuamente un flujo de cambios a una tabla Delta mediante una consulta de combinación para escribir datos modificados en
foreachBatch. Consulte también Datos de variación lenta (SCD) y captura de datos de cambios (CDC) con Delta Lake. - Controlar la desduplicación durante el procesamiento de flujos. Puede utilizar una consulta de combinación de solo inserción en
foreachBatchpara escribir datos continuamente en una tabla Delta con desduplicación automática. Consulte Desduplicación de datos al escribir en tablas Delta.
Note
Compruebe que la instrucción
mergedentro deforeachBatches idempotente. De lo contrario, los reinicios de la consulta de streaming pueden aplicar la operación en el mismo lote de datos varias veces. Consulte UsoforeachBatchpara escrituras de tabla idempotentes.Cuando
mergese usa enforeachBatch, la métrica de velocidad de datos de entrada puede devolver un múltiplo de la velocidad real que se generan los datos en el origen.mergelee los datos de entrada varias veces, lo que multiplica las métricas. Para evitar la multiplicación de métricas, almacene en caché el DataFrame por lotes antesmergey, a continuación, desalmacénelo despuésmerge.La velocidad de datos de entrada está disponible a través de
StreamingQueryProgressy en el gráfico de velocidad de streaming del notebook. Consulte Consultas de monitoreo de transmisión estructurada en Azure Databricks.
Por ejemplo, puede usar instrucciones MERGE SQL dentro de foreachBatch:
Scala
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
// Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
// Use the view name to apply MERGE
// NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
microBatchOutputDF.sparkSession.sql(s"""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
# Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
# Use the view name to apply MERGE
# NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
# In Databricks Runtime 10.5 and below, you must use the following:
# microBatchOutputDF._jdf.sparkSession().sql("""
microBatchOutputDF.sparkSession.sql("""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
También puede usar las API de Delta Lake para transmitir upserts:
Scala
import io.delta.tables.*
val deltaTable = DeltaTable.forName(spark, "table_name")
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
deltaTable.as("t")
.merge(
microBatchOutputDF.as("s"),
"s.key = t.key")
.whenMatched().updateAll()
.whenNotMatched().insertAll()
.execute()
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
from delta.tables import *
deltaTable = DeltaTable.forName(spark, "table_name")
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
(deltaTable.alias("t").merge(
microBatchOutputDF.alias("s"),
"s.key = t.key")
.whenMatchedUpdateAll()
.whenNotMatchedInsertAll()
.execute()
)
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
Establecimiento de la versión inicial de la tabla para procesar los cambios
De forma predeterminada, las secuencias comienzan con la versión más reciente de la tabla Delta disponible. Esto incluye una instantánea completa de la tabla en ese momento y todos los cambios futuros. Databricks recomienda usar la versión predeterminada de la tabla inicial para la mayoría de las cargas de trabajo.
Opcionalmente, puede usar las siguientes opciones para especificar el punto inicial del origen de streaming de Delta Lake sin procesar toda la tabla.
startingVersion: la versión de la tabla Delta desde la que empezar a leer. La secuencia lee todos los cambios de tabla confirmados en o después de la versión especificada. Si la versión especificada no está disponible, la secuencia no se puede iniciar.Para encontrar las versiones de confirmación disponibles, ejecute
DESCRIBE HISTORYy revise elversion. Para devolver solo los cambios más recientes, especifiquelatest. Para obtener información sobre las versiones de tabla Delta, consulte Trabajar con historial de tablas.startingTimestamp: marca de tiempo desde la que empezar a leer. La secuencia captura todos los cambios de tabla confirmados en o después del sello temporal especificado. Si la marca de tiempo proporcionada precede a todas las confirmaciones de tabla, la lectura de streaming comienza con la marca de tiempo más antigua disponible. Establezca cualquiera de las siguientes opciones:- Una cadena de marca de tiempo. Por ejemplo,
"2019-01-01T00:00:00.000Z". - Una cadena de fecha. Por ejemplo,
"2019-01-01".
- Una cadena de marca de tiempo. Por ejemplo,
No se pueden establecer tanto startingVersion como startingTimestamp al mismo tiempo. Esta configuración solo se aplica a las nuevas consultas de streaming. Si se ha iniciado una consulta de streaming y el progreso se ha registrado en su punto de control, esta configuración se omite.
Important
Aunque puede iniciar el origen de streaming desde una versión o marca de tiempo especificadas, el esquema del origen de streaming siempre es el esquema más reciente de la tabla Delta. Debe asegurarse de que no hay ningún cambio de esquema incompatible en la tabla Delta después de la versión o marca de tiempo especificada. De lo contrario, el origen de streaming podría devolver resultados incorrectos al leer los datos con un esquema incorrecto.
Example
Por ejemplo, supongamos que tiene una tabla user_events. Si desea leer los cambios desde la versión 5, use:
spark.readStream
.option("startingVersion", "5")
.table("user_events")
Si desea leer los cambios desde el 18 de octubre de 2018, use:
spark.readStream
.option("startingTimestamp", "2018-10-18")
.table("user_events")
Procesar instantánea inicial sin eliminar datos
Esta característica está disponible en Databricks Runtime 11.3 LTS y versiones posteriores.
En una consulta de transmisión con estado con una marca temporal definida, el procesamiento de archivos por tiempo de modificación puede procesar registros en el orden incorrecto. Esto puede hacer que la marca de agua marque incorrectamente los registros como eventos tardíos y los descarte. Esto solo puede ocurrir cuando la instantánea delta inicial se procesa en el orden predeterminado.
En el caso de las secuencias con una tabla de origen Delta, la consulta procesa primero todos los datos presentes en la tabla y crea una versión denominada instantánea inicial. De forma predeterminada, los archivos de datos de la tabla Delta se procesan en función del archivo que se modificó por última vez. Sin embargo, la hora de la última modificación no representa necesariamente el orden de la hora de los eventos en el registro.
Para evitar caídas de datos durante el procesamiento inicial de instantáneas, habilite la withEventTimeOrder opción .
withEventTimeOrder divide el intervalo de tiempo de evento de los datos de instantánea iniciales en cubos de tiempo. Cada microproceso procesa un cubo filtrando los datos dentro del intervalo de tiempo. Las opciones maxFilesPerTrigger y maxBytesPerTrigger siguen siendo aplicables para controlar el tamaño del microlote, pero solo aproximadamente debido al método de procesamiento.
En el diagrama siguiente se muestra este proceso:
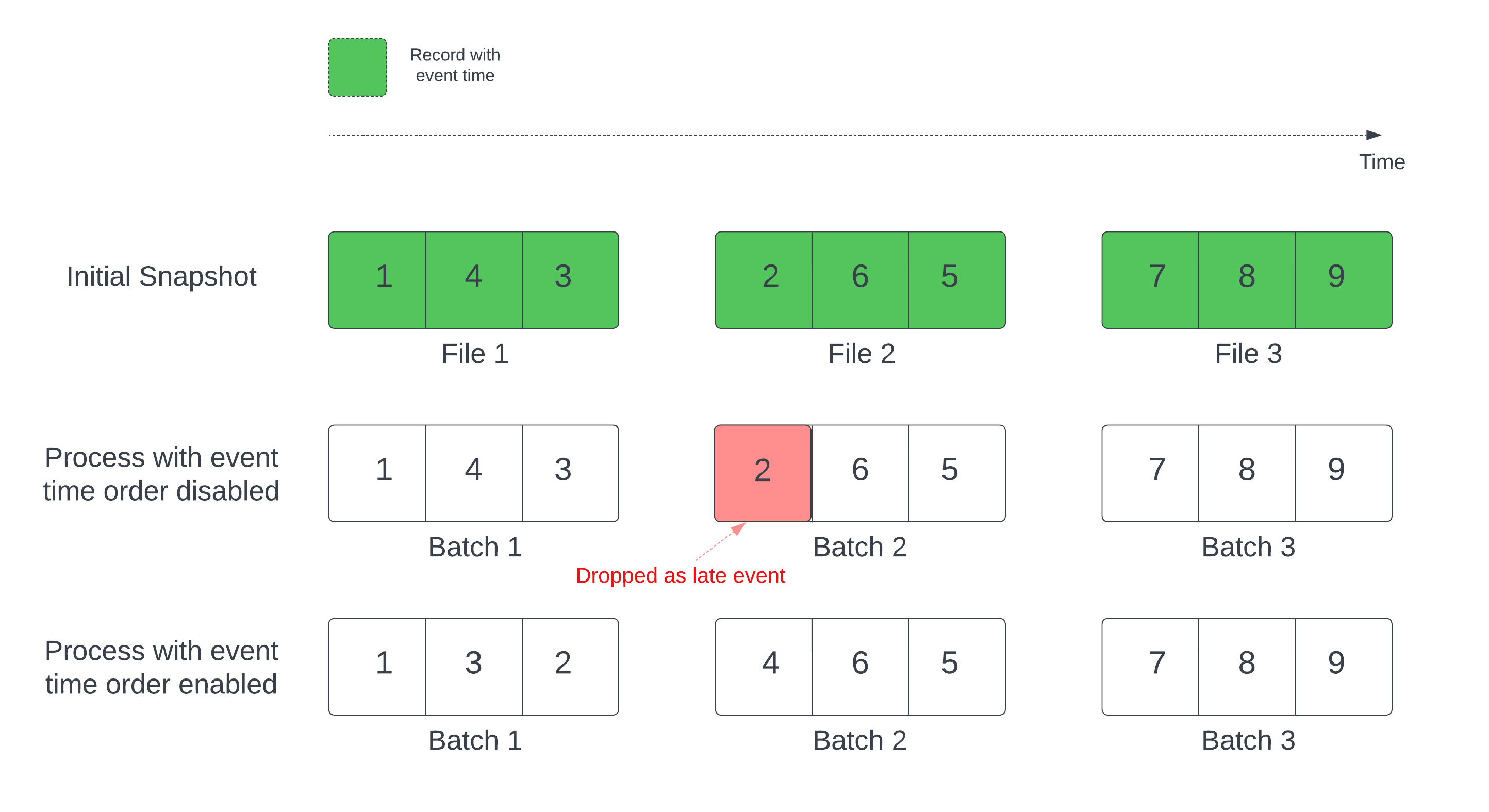
Limitaciones
- No se puede cambiar
withEventTimeOrdersi la consulta de secuencia se ha iniciado y la instantánea inicial se está procesando activamente. Para reiniciar conwithEventTimeOrdercambiado, debe eliminar el punto de control. - Si
withEventTimeOrderestá habilitado, no puede degradar una secuencia a una versión de Databricks Runtime que no admita esta característica hasta que finalice el procesamiento inicial de instantáneas. Para cambiar a una versión anterior, espere a que finalice la instantánea inicial o elimine el punto de control y reinicie la consulta. - Esta característica no se admite en los escenarios siguientes:
- La columna de hora del evento es una columna generada y hay transformaciones no de proyección entre el origen de Delta y la marca de agua.
- Hay una marca de agua que tiene más de un origen de Delta en la consulta de streaming.
Rendimiento
Si withEventTimeOrder está habilitado, el rendimiento del procesamiento de instantáneas inicial podría ser más lento. Cada microproceso examina la instantánea inicial para filtrar los datos dentro del intervalo de tiempo de evento correspondiente. Para mejorar el rendimiento del filtrado:
- Use una columna de origen Delta como tiempo del evento para que se pueda aplicar la omisión de datos. Consulte Omisión de datos.
- Particione la tabla según la columna de hora del evento.
Use la interfaz de usuario de Spark para ver cuántos archivos Delta se examinan para un microproceso específico.
Example
Supongamos que tiene una tabla user_events con una columna event_time. La consulta de streaming es una consulta de agregación. Si quiere asegurarse de que no se anulen datos durante el procesamiento de la instantánea inicial, puede usar:
spark.readStream
.option("withEventTimeOrder", "true")
.table("user_events")
.withWatermark("event_time", "10 seconds")
Puede establecer withEventTimeOrder con una configuración de Spark en el clúster para aplicarla a todas las consultas de streaming: spark.databricks.delta.withEventTimeOrder.enabled true.
Limitar la velocidad de entrada para mejorar el rendimiento del procesamiento
De forma predeterminada, Structured Streaming procesa tantos archivos como sea posible en cada microproceso. Para limitar la cantidad de datos procesados por lote y administrar el uso de memoria, estabilizar la latencia o reducir los costos de almacenamiento en la nube, use las siguientes opciones:
-
maxFilesPerTrigger: el número de archivos nuevos a considerar en cada microlote. El valor predeterminado es 1000. -
maxBytesPerTrigger: la cantidad de datos que se procesan en cada microlote. Esta opción establece un "máximo flexible", lo que significa que un lote procesa aproximadamente esta cantidad de datos y podría exceder el límite para permitir que la consulta de streaming progrese en los casos en los que la unidad de entrada más pequeña sea mayor que este límite. Esto no se establece de forma predeterminada.
Si usa tanto maxBytesPerTrigger como maxFilesPerTrigger, el micro-lote procesa los datos hasta que se alcanza el límite de maxFilesPerTrigger o maxBytesPerTrigger.
Note
De forma predeterminada, si logRetentionDuration limpia las transacciones en la tabla de origen y la consulta de streaming intenta procesar esas versiones, la consulta no puede evitar la pérdida de datos. Puede establecer la opción failOnDataLoss en false para omitir los datos perdidos y continuar el procesamiento. Vea Configuración de la retención de datos para las consultas de historial temporal.
Control del costo del almacenamiento en la nube
Las consultas de streaming tienen varios modos de desencadenador disponibles que permiten equilibrar el costo y la latencia, incluidos processingTime, availableNowy realTime. Consulte Control del costo del almacenamiento en la nube.