Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo se describen las visualizaciones heredadas de Azure Databricks. Consulte Visualizaciones en cuadernos de Databricks y el editor de SQL para conocer las capacidades actuales de visualización al crear visualizaciones en el editor de SQL o en un cuaderno. Para obtener información sobre cómo trabajar con visualizaciones en paneles de IA/BI, consulte Tipos de visualización de paneles de AI/BI.
Azure Databricks también admite de forma nativa bibliotecas de visualización en Python y R, y permite instalar y usar bibliotecas de terceros.
Crear una visualización heredada
Para crear una visualización heredada a partir de una celda de resultados, haga clic en + y seleccione Legacy Visualization.
Las visualizaciones heredadas admiten un amplio conjunto de tipos de trazado:
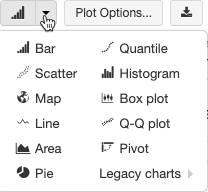
Elija y configure un tipo de gráfico heredado
Para elegir un gráfico de barras, haga clic en el icono del gráfico de barras  :
:
Para elegir otro tipo de trazado, haga clic en ![]() a la derecha del gráfico de barras y elija el tipo de trazado.
a la derecha del gráfico de barras y elija el tipo de trazado.
Barra de herramientas del gráfico heredado
Tanto los gráficos de líneas como los de barras tienen una barra de herramientas integrada que admite un amplio conjunto de interacciones del lado cliente.
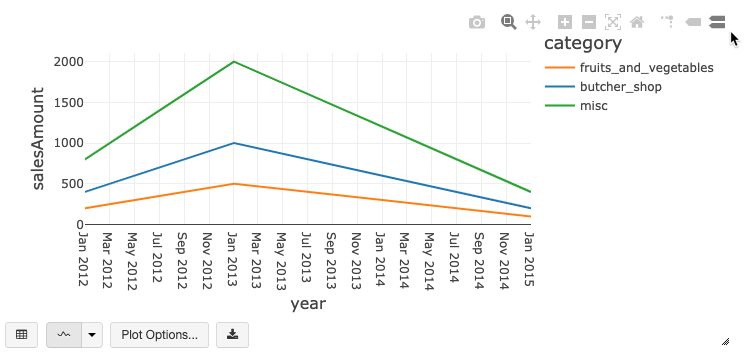
Para configurar un gráfico, haga clic en Opciones de trazado...
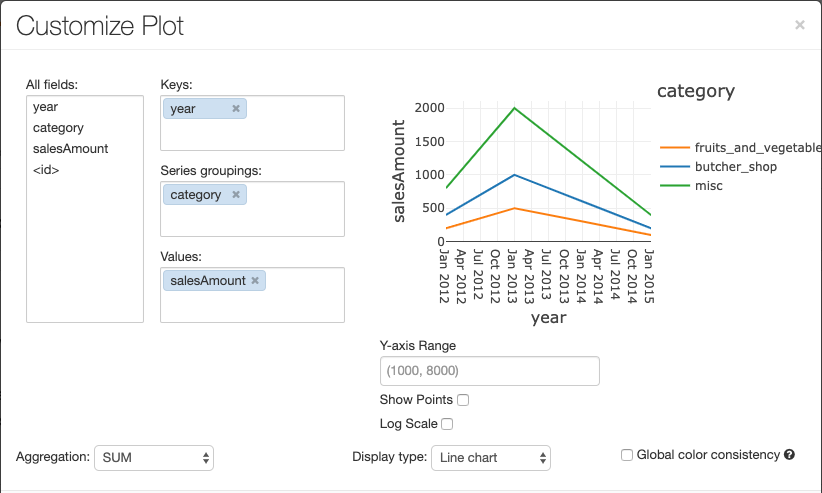
El gráfico de líneas tiene varias opciones personalizadas: establecer un rango del eje Y, mostrar y ocultar puntos, y mostrar el eje Y con una escala de registro.
Para obtener información sobre los tipos de gráfico heredados, consulte:
Coherencia de colores entre gráficos
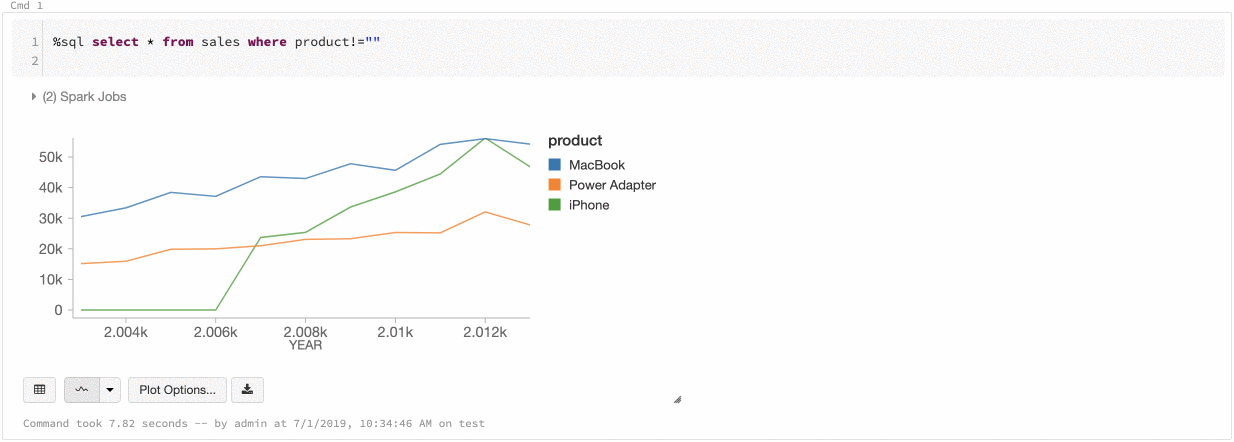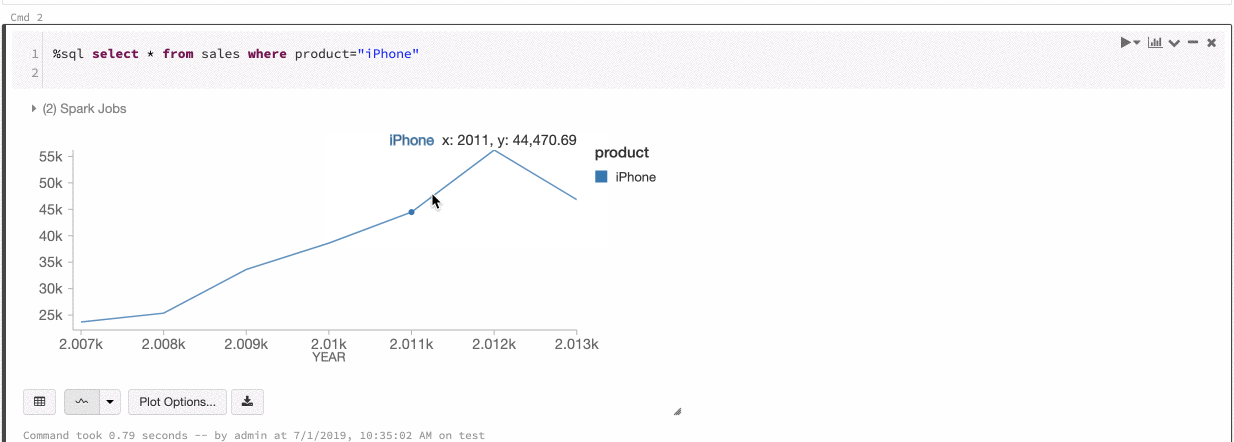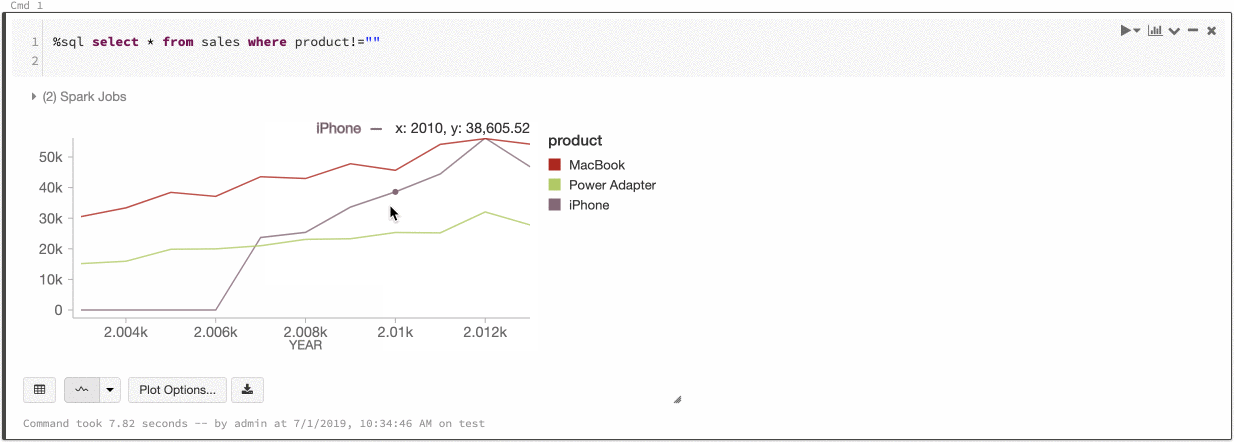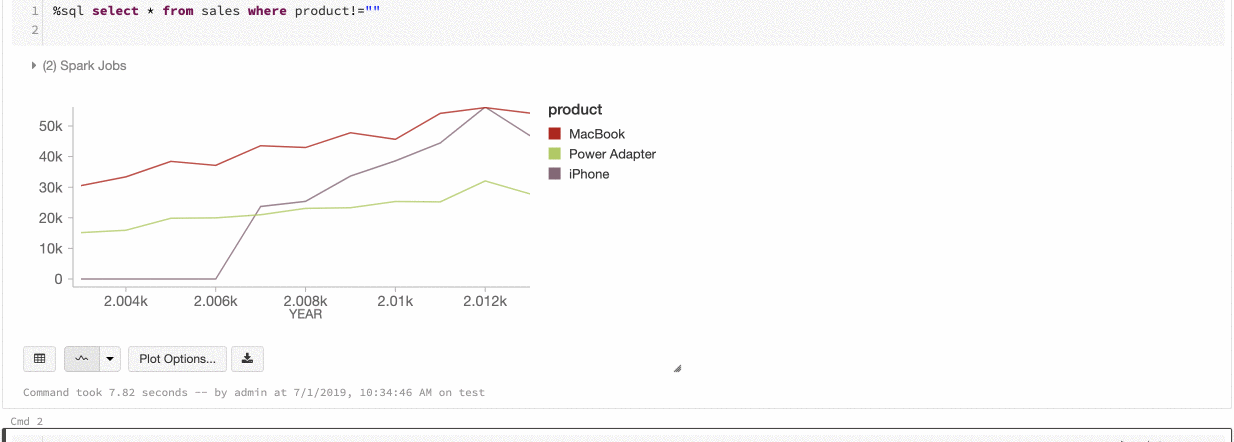
Azure Databricks es compatible con dos tipos de consistencia de color en los gráficos heredados: conjunto de series y global.
La consistencia de color de tipo conjunto de una serie asigna el mismo color al mismo valor si existen series con los mismos valores pero ordenados de forma distinta (por ejemplo, A = ["Apple", "Orange", "Banana"] y B = ["Orange", "Banana", "Apple"]). Los valores se ordenan antes de trazarse, de modo que ambas leyendas se ordenan de la misma manera (["Apple", "Banana", "Orange"]) y los mismos valores reciben los mismos colores. Sin embargo, si tiene una serie C = ["Orange", "Banana"], no sería coherente en color con el conjunto A porque el conjunto no es igual. El algoritmo de ordenación asignaría el primer color a "Banana" en el conjunto C, pero en el conjunto A le asignaría el segundo color. Si quiere que estas series tengan colores uniformes, puede especificar que los gráficos tengan una uniformidad de color global.
En la coherencia de color global, todos los valores siempre se asignan al mismo color, independientemente de los valores que tenga la serie. Para habilitar esta opción en todos los gráficos, active la casilla Global color consistency (Coherencia de color global).
Nota:
Para lograr esta coherencia, Azure Databricks aplica un algoritmo hash directamente de los valores a los colores. Para evitar colisiones (donde dos valores se asignan al mismo color exacto), el hash se aplica a un conjunto grande de colores. Como efecto secundario, no es posible garantizar colores con una apariencia agradable o fáciles de distinguir. Cuando hay muchos colores, existe la posibilidad de que algunos tengan una apariencia muy similar.
Visualizaciones de Machine Learning
Además de los tipos de gráfico estándar, las visualizaciones heredadas admiten los siguientes parámetros y resultados del entrenamiento del aprendizaje automático:
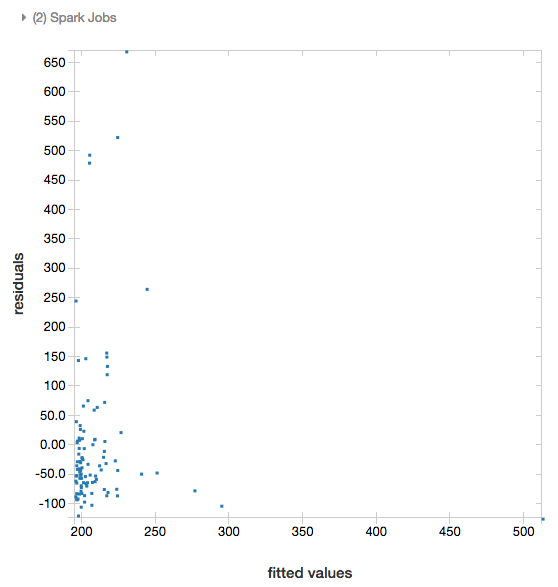
Valores residuales
En el caso de las regresiones lineales y logísticas, puede representar gráficamente una gráfica de valores ajustados frente a residuales. Para obtener este trazado, proporcione el modelo y el dataframe.
En el ejemplo siguiente se ejecuta una regresión lineal en la población de la ciudad en relación con los datos del precio de venta de las casas y, a continuación, se muestran los valores residuales frente a los datos predichos.
# Load data
pop_df = spark.read.csv("/databricks-datasets/samples/population-vs-price/data_geo.csv", header="true", inferSchema="true")
# Drop rows with missing values and rename the feature and label columns, replacing spaces with _
from pyspark.sql.functions import col
pop_df = pop_df.dropna() # drop rows with missing values
exprs = [col(column).alias(column.replace(' ', '_')) for column in pop_df.columns]
# Register a UDF to convert the feature (2014_Population_estimate) column vector to a VectorUDT type and apply it to the column.
from pyspark.ml.linalg import Vectors, VectorUDT
spark.udf.register("oneElementVec", lambda d: Vectors.dense([d]), returnType=VectorUDT())
tdata = pop_df.select(*exprs).selectExpr("oneElementVec(2014_Population_estimate) as features", "2015_median_sales_price as label")
# Run a linear regression
from pyspark.ml.regression import LinearRegression
lr = LinearRegression()
modelA = lr.fit(tdata, {lr.regParam:0.0})
# Plot residuals versus fitted data
display(modelA, tdata)
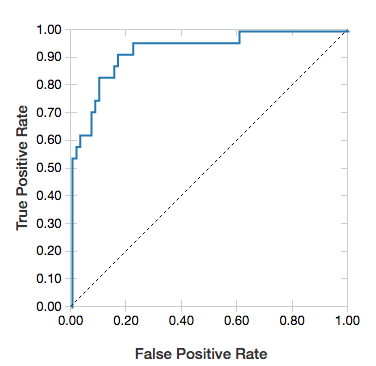
Curvas ROC
En el caso de las regresiones logísticas, puede representar una curva ROC. Para obtener este trazado, se suministra el modelo; es decir, los datos preparados previamente que se introducen en el método fit y el parámetro "ROC".
En el siguiente ejemplo se desarrolla un clasificador que predice si un individuo percibe ≥ 50 000 o > 50 000 al año a partir de varios atributos del individuo. El conjunto de datos Adult se deriva de datos de un censo y consta de información sobre 48 842 personas y sus ingresos anuales.
El código de ejemplo de esta sección utiliza la codificación one-hot.
# This code uses one-hot encoding to convert all categorical variables into binary vectors.
schema = """`age` DOUBLE,
`workclass` STRING,
`fnlwgt` DOUBLE,
`education` STRING,
`education_num` DOUBLE,
`marital_status` STRING,
`occupation` STRING,
`relationship` STRING,
`race` STRING,
`sex` STRING,
`capital_gain` DOUBLE,
`capital_loss` DOUBLE,
`hours_per_week` DOUBLE,
`native_country` STRING,
`income` STRING"""
dataset = spark.read.csv("/databricks-datasets/adult/adult.data", schema=schema)
from pyspark.ml import Pipeline
from pyspark.ml.feature import OneHotEncoder, StringIndexer, VectorAssembler
categoricalColumns = ["workclass", "education", "marital_status", "occupation", "relationship", "race", "sex", "native_country"]
stages = [] # stages in the Pipeline
for categoricalCol in categoricalColumns:
# Category indexing with StringIndexer
stringIndexer = StringIndexer(inputCol=categoricalCol, outputCol=categoricalCol + "Index")
# Use OneHotEncoder to convert categorical variables into binary SparseVectors
encoder = OneHotEncoder(inputCols=[stringIndexer.getOutputCol()], outputCols=[categoricalCol + "classVec"])
# Add stages. These are not run here, but will run all at once later on.
stages += [stringIndexer, encoder]
# Convert label into label indices using the StringIndexer
label_stringIdx = StringIndexer(inputCol="income", outputCol="label")
stages += [label_stringIdx]
# Transform all features into a vector using VectorAssembler
numericCols = ["age", "fnlwgt", "education_num", "capital_gain", "capital_loss", "hours_per_week"]
assemblerInputs = [c + "classVec" for c in categoricalColumns] + numericCols
assembler = VectorAssembler(inputCols=assemblerInputs, outputCol="features")
stages += [assembler]
# Run the stages as a Pipeline. This puts the data through all of the feature transformations in a single call.
partialPipeline = Pipeline().setStages(stages)
pipelineModel = partialPipeline.fit(dataset)
preppedDataDF = pipelineModel.transform(dataset)
# Fit logistic regression model
from pyspark.ml.classification import LogisticRegression
lrModel = LogisticRegression().fit(preppedDataDF)
# ROC for data
display(lrModel, preppedDataDF, "ROC")
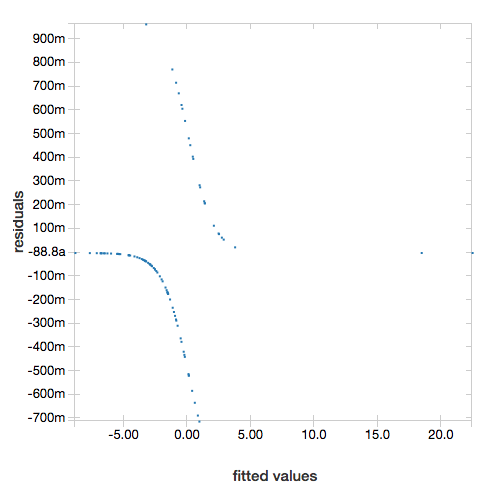
Para mostrar los valores residuales, omita el parámetro "ROC":
display(lrModel, preppedDataDF)
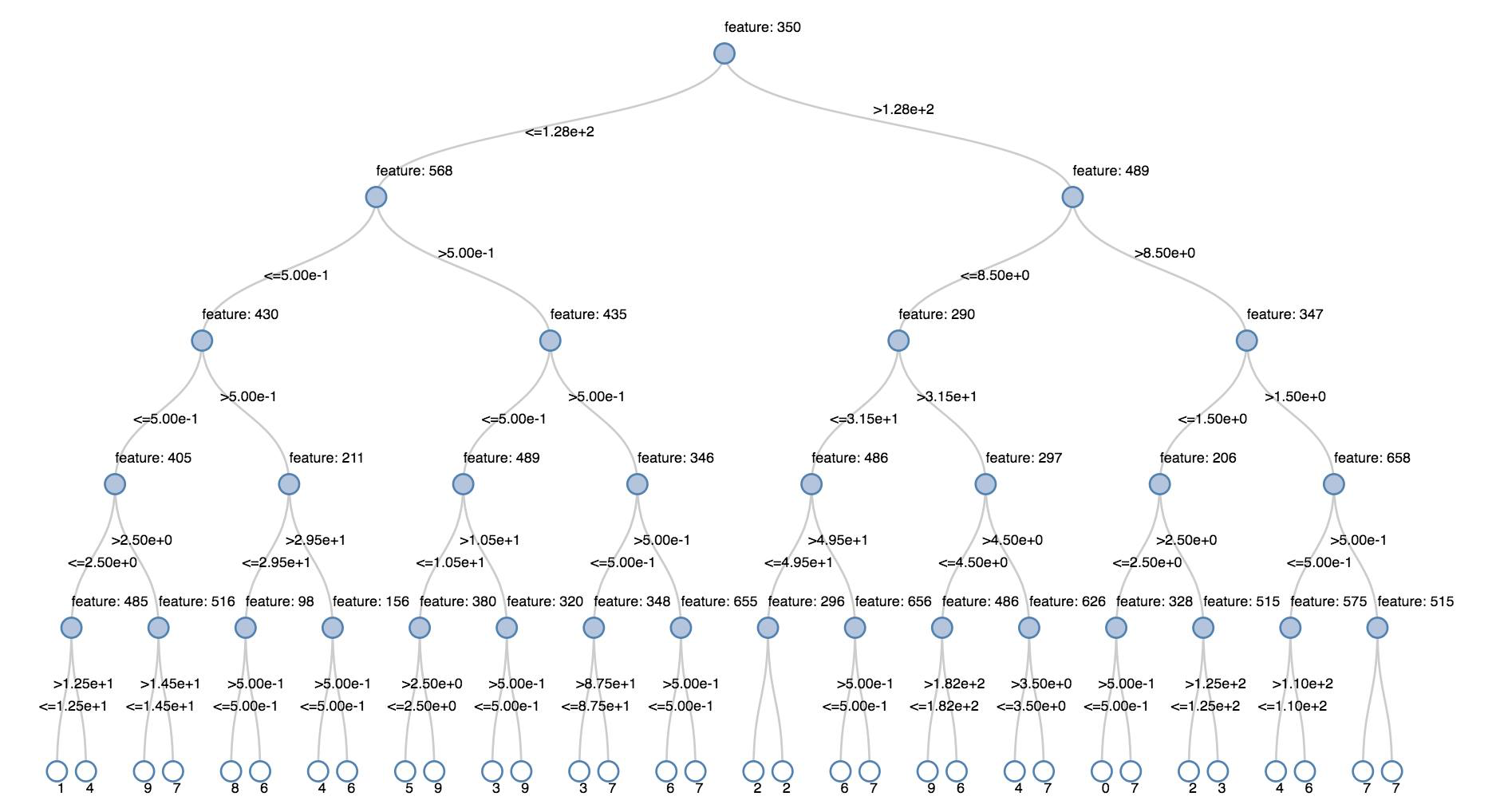
Árboles de decisión
Las visualizaciones heredadas admiten la representación de un árbol de decisión.
Para obtener esta visualización, debe proporcionar el modelo de árbol de decisión.
En los siguientes ejemplos se entrena un árbol para reconocer dígitos (0 a 9) del conjunto de datos de MNIST a partir de imágenes de dígitos escritos a mano y, a continuación, se muestra el árbol.
Pitón
trainingDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-train.txt").cache()
testDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-test.txt").cache()
from pyspark.ml.classification import DecisionTreeClassifier
from pyspark.ml.feature import StringIndexer
from pyspark.ml import Pipeline
indexer = StringIndexer().setInputCol("label").setOutputCol("indexedLabel")
dtc = DecisionTreeClassifier().setLabelCol("indexedLabel")
# Chain indexer + dtc together into a single ML Pipeline.
pipeline = Pipeline().setStages([indexer, dtc])
model = pipeline.fit(trainingDF)
display(model.stages[-1])
Scala
val trainingDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-train.txt").cache
val testDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-test.txt").cache
import org.apache.spark.ml.classification.{DecisionTreeClassifier, DecisionTreeClassificationModel}
import org.apache.spark.ml.feature.StringIndexer
import org.apache.spark.ml.Pipeline
val indexer = new StringIndexer().setInputCol("label").setOutputCol("indexedLabel")
val dtc = new DecisionTreeClassifier().setLabelCol("indexedLabel")
val pipeline = new Pipeline().setStages(Array(indexer, dtc))
val model = pipeline.fit(trainingDF)
val tree = model.stages.last.asInstanceOf[DecisionTreeClassificationModel]
display(tree)
DataFrames de Streaming estructurado
Para visualizar el resultado de una consulta de streaming en tiempo real, puede usar display para mostrar un dataframe de Structured Streaming en Scala y Python.
Pitón
streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count())
Scala
val streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count())
display admite los siguientes parámetros opcionales:
-
streamName: el nombre de la consulta de streaming. -
trigger(Scala) yprocessingTime(Python): define la frecuencia con que se ejecuta la consulta de streaming. Si no se especifica, el sistema comprueba la disponibilidad de los datos nuevos en cuanto se haya completado el procesamiento anterior. Para reducir el costo de producción, Databricks recomienda establecer siempre un intervalo de desencadenador. El intervalo de desencadenador predeterminado es 500 ms. -
checkpointLocation: la ubicación en la que el sistema escribe toda la información del punto de comprobación. Si no se especifica, el sistema genera automáticamente una ubicación temporal para el punto de comprobación en DBFS. Para que la transmisión continúe con el procesamiento de datos en el lugar en que lo dejó, es preciso proporcionar una ubicación del punto de control. Databricks recomienda que en producción siempre se especifique la opcióncheckpointLocation.
Pitón
streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count(), processingTime = "5 seconds", checkpointLocation = "dbfs:/<checkpoint-path>")
Scala
import org.apache.spark.sql.streaming.Trigger
val streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count(), trigger = Trigger.ProcessingTime("5 seconds"), checkpointLocation = "dbfs:/<checkpoint-path>")
Para más información sobre estos parámetros, consulte el apartado en el que se indica cómo iniciar consultas de streaming.
Función displayHTML
Los cuadernos de los lenguajes de programación de Azure Databricks (Python, Scala y R) admiten gráficos HTML mediante la función displayHTML; esta función se puede usar en cualquier código HTML, CSS o JavaScript. Esta función admite gráficos interactivos mediante bibliotecas de JavaScript como D3.
Para ver ejemplos de uso de displayHTML, consulte:
Nota:
El