Canalizaciones de datos de CI/CD de Azure
Azure DevOps Services
En este artículo se explican las canalizaciones de datos de integración continua y entrega continua (CI/CD) de Azure y su importancia para la ciencia de datos.
Puede usar canalizaciones de datos para:
- Ingerir datos de varios orígenes de datos.
- Procese y transforme los datos.
- Guarde los datos procesados en una ubicación de almacenamiento provisional para que otros los consuman.
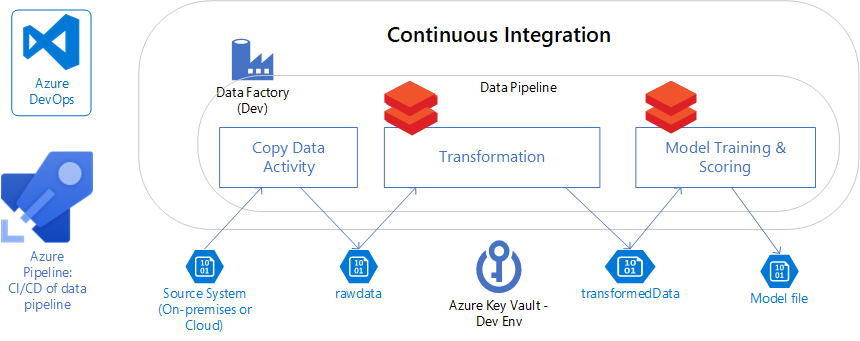
Las canalizaciones de datos empresariales pueden evolucionar en escenarios más complicados con varios sistemas de origen y varias aplicaciones de nivel inferior compatibles.
Las canalizaciones de datos proporcionan:
- Coherencia, mediante la transformación de datos en un formato coherente para que los usuarios consuman.
- Reducción de errores, mediante el uso de canalizaciones de datos automatizadas para eliminar errores humanos al manipular datos.
- Eficiencia, al reducir el tiempo invertido en la transformación del procesamiento de datos.
Las canalizaciones de datos permiten a los profesionales de datos centrarse en sus principales funciones de trabajo, obtener información de los datos y ayudar a las empresas a tomar mejores decisiones.
Integración continua y entrega continua (CI/CD)
La integración continua y la entrega continua (CI/CD) es un enfoque de desarrollo de software en el que todos los desarrolladores trabajan juntos en un repositorio de código compartido de código. A medida que los desarrolladores realizan cambios, los procesos automatizados detectan problemas de código. El resultado del uso de CI/CD es un ciclo de vida de desarrollo más rápido con tasas de error más bajas.
Canalizaciones de datos de CI/CD en ciencia de datos
La creación de modelos de aprendizaje automático es similar al desarrollo de software tradicional en que los científicos de datos escriben código para entrenar y puntuar modelos de aprendizaje automático. Pero, a diferencia del software tradicional basado en código, los modelos de aprendizaje automático de ciencia de datos se basan en código, como algoritmos e hiperparámetros, y en los datos usados para entrenar los modelos. La mayoría de los científicos de datos dicen que dedican el 80 % de su tiempo a realizar la preparación, la limpieza y la ingeniería de características.
Para garantizar la calidad de los modelos de aprendizaje automático, también se usan técnicas como las pruebas A/B para comparar y mantener el rendimiento del modelo. Las pruebas A/B suelen usar un modelo de control y uno o varios modelos de tratamiento.
Es posible que varios modelos de aprendizaje automático se usen simultáneamente, agregando otra capa de complejidad para la CI/CD de los modelos de aprendizaje automático. Una canalización de datos de CI/CD es fundamental para que el equipo de ciencia de datos ofrezca modelos de aprendizaje automático de calidad a la empresa de forma oportuna.
Pasos siguientes
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de