Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Azure DevOps Services | Azure DevOps Server | Azure DevOps Server 2022
Puede organizar la canalización en trabajos. Cada canalización tiene un trabajo por lo menos. Un trabajo es una serie de pasos que se ejecutan secuencialmente como una unidad. En otras palabras, un trabajo es la unidad de trabajo más pequeña que se puede programar para ejecutarse.
Para obtener información sobre los conceptos y componentes clave que componen una canalización, consulte Conceptos clave para los nuevos usuarios de Azure Pipelines.
Azure Pipelines no admite la prioridad de tareas de las canalizaciones YAML. Para controlar cuándo se ejecutan los trabajos, puede especificar condiciones y dependencias.
Definición de un único trabajo
En el caso más sencillo, una canalización tiene un único trabajo. En ese caso, no es necesario usar explícitamente la palabra clave job a menos que use una plantilla. Puede especificar directamente los pasos en el archivo YAML.
Este archivo YAML tiene un trabajo que se ejecuta en un agente hospedado por Microsoft y genera Hello world.
pool:
vmImage: 'ubuntu-latest'
steps:
- bash: echo "Hello world"
Es posible que desee especificar más propiedades en ese trabajo. En ese caso, puede usar la palabra clave job.
jobs:
- job: myJob
timeoutInMinutes: 10
pool:
vmImage: 'ubuntu-latest'
steps:
- bash: echo "Hello world"
La canalización puede tener varios trabajos. En ese caso, use la palabra clave jobs.
jobs:
- job: A
steps:
- bash: echo "A"
- job: B
steps:
- bash: echo "B"
Su pipeline puede tener múltiples etapas, cada una con múltiples trabajos. En ese caso, use la palabra clave stages.
stages:
- stage: A
jobs:
- job: A1
- job: A2
- stage: B
jobs:
- job: B1
- job: B2
La sintaxis completa para especificar un trabajo es:
- job: string # name of the job, A-Z, a-z, 0-9, and underscore
displayName: string # friendly name to display in the UI
dependsOn: string | [ string ]
condition: string
strategy:
parallel: # parallel strategy
matrix: # matrix strategy
maxParallel: number # maximum number simultaneous matrix legs to run
# note: `parallel` and `matrix` are mutually exclusive
# you may specify one or the other; including both is an error
# `maxParallel` is only valid with `matrix`
continueOnError: boolean # 'true' if future jobs should run even if this job fails; defaults to 'false'
pool: pool # agent pool
workspace:
clean: outputs | resources | all # what to clean up before the job runs
container: containerReference # container to run this job inside
timeoutInMinutes: number # how long to run the job before automatically cancelling
cancelTimeoutInMinutes: number # how much time to give 'run always even if cancelled tasks' before killing them
variables: { string: string } | [ variable | variableReference ]
steps: [ script | bash | pwsh | powershell | checkout | task | templateReference ]
services: { string: string | container } # container resources to run as a service container
La sintaxis completa para especificar un trabajo es:
- job: string # name of the job, A-Z, a-z, 0-9, and underscore
displayName: string # friendly name to display in the UI
dependsOn: string | [ string ]
condition: string
strategy:
parallel: # parallel strategy
matrix: # matrix strategy
maxParallel: number # maximum number simultaneous matrix legs to run
# note: `parallel` and `matrix` are mutually exclusive
# you may specify one or the other; including both is an error
# `maxParallel` is only valid with `matrix`
continueOnError: boolean # 'true' if future jobs should run even if this job fails; defaults to 'false'
pool: pool # agent pool
workspace:
clean: outputs | resources | all # what to clean up before the job runs
container: containerReference # container to run this job inside
timeoutInMinutes: number # how long to run the job before automatically cancelling
cancelTimeoutInMinutes: number # how much time to give 'run always even if cancelled tasks' before killing them
variables: { string: string } | [ variable | variableReference ]
steps: [ script | bash | pwsh | powershell | checkout | task | templateReference ]
services: { string: string | container } # container resources to run as a service container
uses: # Any resources (repos or pools) required by this job that are not already referenced
repositories: [ string ] # Repository references to Azure Git repositories
pools: [ string ] # Pool names, typically when using a matrix strategy for the job
Si la intención principal del trabajo es implementar la aplicación (en lugar de compilar o probar la aplicación), puede usar un tipo especial de trabajo denominado trabajo de implementación.
La sintaxis de un trabajo de implementación es:
- deployment: string # instead of job keyword, use deployment keyword
pool:
name: string
demands: string | [ string ]
environment: string
strategy:
runOnce:
deploy:
steps:
- script: echo Hi!
Aunque puede agregar pasos para las tareas de implementación en job, se recomienda usar en su lugar un trabajo de implementación. Un trabajo de implementación tiene algunas ventajas. Por ejemplo, puede implementar en un entorno, lo que incluye ventajas como poder ver el historial de lo que ha implementado.

Tipos de trabajos
Los trabajos pueden ser de diferentes tipos, dependiendo de dónde se ejecuten.
- Los trabajos del grupo de agentes se ejecutan en un agente de un grupo de agentes.
- Los trabajos de servidor se ejecutan en el Azure DevOps Server.
- Los trabajos de contenedor se ejecutan en un contenedor de un agente de un grupo de agentes. Para obtener más información sobre cómo elegir contenedores, consulte Definir trabajos de contenedor.
Trabajos de grupo de agentes
Los trabajos del grupo de agentes son los más comunes. Estos trabajos se ejecutan en un agente de un grupo de agentes. Puede especificar el grupo en el que ejecutar el trabajo, y también puede especificar demandas para especificar qué capacidades debe tener un agente para ejecutar su trabajo. Los agentes pueden estar alojados en Microsoft o ser autoalojados. Para obtener más información, consulte agentes de canalizaciones de Azure.
- Cuando se usan agentes hospedados por Microsoft, cada trabajo de una canalización obtiene un agente nuevo.
- Al utilizar agentes autohospedados, puede usar demandas para especificar qué capacidades debe tener un agente para ejecutar su trabajo. Puede obtener el mismo agente para trabajos consecutivos, en función de si hay más de un agente en el grupo de agentes que coincida con las demandas de la canalización. Si solo hay un agente en el grupo que coincida con las demandas de la canalización, la canalización esperará hasta que este agente esté disponible.
Nota:
Las demandas y funcionalidades están diseñadas para su uso con agentes autohospedados para que los trabajos puedan coincidir con un agente que cumpla los requisitos del trabajo. Al usar agentes hospedados por Microsoft, seleccione una imagen para el agente que coincida con los requisitos del trabajo. Aunque es posible agregar funcionalidades a un agente hospedado por Microsoft, no es necesario usar funcionalidades con agentes hospedados por Microsoft.
pool:
name: myPrivateAgents # your job runs on an agent in this pool
demands: agent.os -equals Windows_NT # the agent must have this capability to run the job
steps:
- script: echo hello world
O varias demandas:
pool:
name: myPrivateAgents
demands:
- agent.os -equals Darwin
- anotherCapability -equals somethingElse
steps:
- script: echo hello world
Más información sobre funcionalidades de agente.
Trabajos de servidor
El servidor organiza y ejecuta tareas en un trabajo de servidor. Un trabajo de servidor no requiere un agente ni ningún equipo de destino. Actualmente solo se admiten algunas tareas en un trabajo de servidor. El tiempo máximo de un trabajo de servidor es de 30 días.
Tareas admitidas de trabajos sin agente
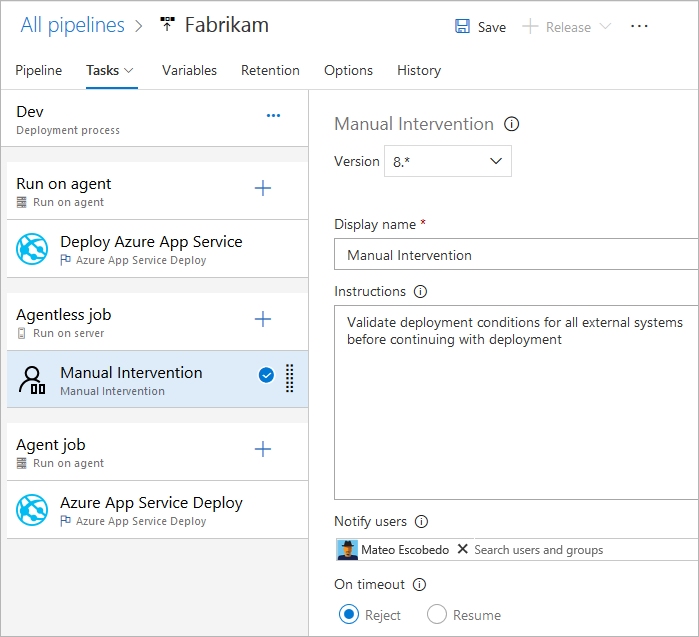
Actualmente, solo se admiten las siguientes tareas listas para usar para trabajos sin agente:
- Retrasar tarea
- Invocar tarea de Azure Functions
- Invocar tarea de API de REST
- Tarea de validación manual
- Publicar en tarea de Azure Service Bus
- Consultar la tarea de alertas de Azure Monitor
- Tarea de elementos de trabajo de la consulta
Dado que las tareas son extensibles, puede agregar más tareas sin agente mediante extensiones. El tiempo de espera predeterminado para los trabajos sin agente es de 60 minutos.
La sintaxis completa para especificar un trabajo de servidor es:
jobs:
- job: string
timeoutInMinutes: number
cancelTimeoutInMinutes: number
strategy:
maxParallel: number
matrix: { string: { string: string } }
pool: server # note: the value 'server' is a reserved keyword which indicates this is an agentless job
También puede usar la sintaxis simplificada:
jobs:
- job: string
pool: server # note: the value 'server' is a reserved keyword which indicates this is an agentless job
Dependencias
Al definir varios trabajos en una sola fase, puede especificar dependencias entre ellos. Las canalizaciones deben contener al menos un trabajo sin dependencias. De forma predeterminada, los trabajos de canalización de YAML de Azure DevOps se ejecutarán en paralelo a menos que se establezca el valor dependsOn.
Nota:
Cada agente solo puede ejecutar un trabajo a la vez. Para ejecutar varios trabajos en paralelo, debe configurar varios agentes. También necesita suficientes trabajos paralelos.
La sintaxis para definir varios trabajos y sus dependencias es:
jobs:
- job: string
dependsOn: string
condition: string
Trabajos de ejemplo que se compilan secuencialmente:
jobs:
- job: Debug
steps:
- script: echo hello from the Debug build
- job: Release
dependsOn: Debug
steps:
- script: echo hello from the Release build
Trabajos de ejemplo que se compilan en paralelo (sin dependencias):
jobs:
- job: Windows
pool:
vmImage: 'windows-latest'
steps:
- script: echo hello from Windows
- job: macOS
pool:
vmImage: 'macOS-latest'
steps:
- script: echo hello from macOS
- job: Linux
pool:
vmImage: 'ubuntu-latest'
steps:
- script: echo hello from Linux
Ejemplo de distribución ramificada:
jobs:
- job: InitialJob
steps:
- script: echo hello from initial job
- job: SubsequentA
dependsOn: InitialJob
steps:
- script: echo hello from subsequent A
- job: SubsequentB
dependsOn: InitialJob
steps:
- script: echo hello from subsequent B
Ejemplo de absorción:
jobs:
- job: InitialA
steps:
- script: echo hello from initial A
- job: InitialB
steps:
- script: echo hello from initial B
- job: Subsequent
dependsOn:
- InitialA
- InitialB
steps:
- script: echo hello from subsequent
Condiciones
Puede especificar las condiciones con las que se ejecutará cada trabajo. De forma predeterminada, un trabajo se ejecuta si no depende de ningún otro trabajo, o si todos los trabajos de los que depende se completan correctamente. Puede personalizar este comportamiento forzando la ejecución de un trabajo aunque se produzca un error en un trabajo anterior o especificando una condición personalizada.
Ejemplo para ejecutar un trabajo en función del estado de ejecución de un trabajo anterior:
jobs:
- job: A
steps:
- script: exit 1
- job: B
dependsOn: A
condition: failed()
steps:
- script: echo this will run when A fails
- job: C
dependsOn:
- A
- B
condition: succeeded('B')
steps:
- script: echo this will run when B runs and succeeds
Ejemplo de uso de una condición personalizada:
jobs:
- job: A
steps:
- script: echo hello
- job: B
dependsOn: A
condition: and(succeeded(), eq(variables['build.sourceBranch'], 'refs/heads/main'))
steps:
- script: echo this only runs for master
Puede especificar que un trabajo se ejecute en función del valor de una variable de salida establecida en un trabajo anterior. En este caso, solo puede usar variables establecidas en trabajos dependientes directamente:
jobs:
- job: A
steps:
- script: "echo '##vso[task.setvariable variable=skipsubsequent;isOutput=true]false'"
name: printvar
- job: B
condition: and(succeeded(), ne(dependencies.A.outputs['printvar.skipsubsequent'], 'true'))
dependsOn: A
steps:
- script: echo hello from B
Tiempos de espera
Para evitar el uso de recursos cuando el trabajo no responde o espera demasiado tiempo, puede establecer un límite durante cuánto tiempo se puede ejecutar el trabajo. Use la configuración de tiempo de espera del trabajo para especificar el límite en minutos para ejecutar el trabajo. Establecer el valor en cero significa que el trabajo se puede ejecutar:
- Para siempre en agentes autohospedados
- Durante 360 minutos (6 horas) en agentes hospedados por Microsoft con un proyecto público y un repositorio público
- Durante 60 minutos en agentes hospedados por Microsoft con un proyecto privado o un repositorio privado (a menos que se pague capacidad adicional)
El período de tiempo de espera comienza cuando el trabajo comienza a ejecutarse. No incluye el tiempo en que la tarea está en cola o está esperando un agente.
timeoutInMinutes permite establecer un límite para el tiempo de ejecución del trabajo. Cuando no se especifica, el valor predeterminado es de 60 minutos. Cuando se especifica 0, se usa el límite máximo.
cancelTimeoutInMinutes permite establecer un límite para la hora de cancelación del trabajo cuando se establece la tarea de implementación para seguir ejecutándose si se ha producido un error en una tarea anterior. Cuando no se especifica, el valor predeterminado es de 5 minutos. El valor debe estar comprendido entre 1 y 35790 minutos.
Nota:
Establecer timeoutInMinutes o cancelTimeoutInMinutes superior a la longitud máxima del trabajo del agente hospedado por Microsoft no tiene ningún efecto en las canalizaciones del agente hospedado, ya que esos trabajos expirarán en función de los límites del agente hospedado. Para obtener más información, consulte la sección Tiempos de espera anteriores.
jobs:
- job: Test
timeoutInMinutes: 10 # how long to run the job before automatically cancelling
cancelTimeoutInMinutes: 2 # how much time to give 'run always even if cancelled tasks' before stopping them
Los tiempos de espera tienen el siguiente nivel de prioridad.
- En los agentes hospedados por Microsoft, la duración de los trabajos está limitada en función del tipo de proyecto y de si se ejecutan mediante un trabajo paralelo de pago. Cuando transcurre el intervalo de tiempo de espera del trabajo hospedado por Microsoft, se finaliza el trabajo. En los agentes hospedados por Microsoft, los trabajos no se pueden ejecutar durante más de este intervalo, independientemente de los tiempos de espera de nivel de trabajo especificados en el trabajo.
- El tiempo de espera configurado en el nivel de trabajo especifica la duración máxima del trabajo que se va a ejecutar. Cuando transcurre el intervalo de tiempo de espera del nivel de trabajo, se finaliza el trabajo. Cuando el trabajo se ejecuta en un agente hospedado por Microsoft, establecer el tiempo de espera en un nivel de trabajo mayor que el tiempo de espera predeterminado de nivel de trabajo hospedado por Microsoft no tiene ningún efecto.
- También puede establecer el tiempo de espera de cada tarea individualmente; consulte las opciones de control de tareas. Si el intervalo de tiempo de espera del nivel de trabajo transcurre antes de que se complete la tarea, se finaliza el trabajo en ejecución, incluso si la tarea está configurada con un intervalo de tiempo de espera más largo.
Configuración de varios trabajos
Desde un trabajo único que cree, puede ejecutar varios trabajos en varios agentes en paralelo. Estos son algunos ejemplos:
Compilaciones de varias configuraciones: puede crear varias configuraciones en paralelo. Por ejemplo, podría compilar una aplicación de Visual C++ para las configuraciones
debugyreleaseen ambas plataformasx86yx64. Para obtener más información, consulte Compilación de Visual Studio: varias configuraciones para varias plataformas.Implementaciones de varias configuraciones: puede ejecutar varias implementaciones en paralelo, por ejemplo, en diferentes regiones geográficas.
Pruebas de configuración múltiple: puede ejecutar varias configuraciones en paralelo.
La multiconfiguración siempre genera al menos un trabajo, incluso si una variable de multiconfiguración está vacía.
La estrategia matrix permite que un trabajo se envíe varias veces, con conjuntos de variables diferentes. La etiqueta maxParallel restringe la cantidad de paralelismo. El siguiente trabajo se enviará tres veces con los valores de Ubicación y Explorador establecidos como se especifica. Sin embargo, solo se ejecutarán dos trabajos al mismo tiempo.
jobs:
- job: Test
strategy:
maxParallel: 2
matrix:
US_IE:
Location: US
Browser: IE
US_Chrome:
Location: US
Browser: Chrome
Europe_Chrome:
Location: Europe
Browser: Chrome
Nota:
Los nombres de configuración de matriz (como US_IE arriba) solo deben contener letras alfabéticas latinas básicas (A-Z, a-z), números y caracteres de subrayado (_).
Deben empezar con una letra.
Además, deben tener como máximo 100 caracteres.
También es posible usar variables de salida para generar una matriz. Este método puede ser útil si necesita generar la matriz utilizando un script.
matrix aceptará una expresión en tiempo de ejecución que contiene un objeto JSON con cadena.
Ese objeto JSON, cuando se expande, debe coincidir con la sintaxis de matriz.
En el ejemplo siguiente, codificamos de forma rígida la cadena JSON, pero puede generarla con un lenguaje de scripting o un programa de línea de comandos.
jobs:
- job: generator
steps:
- bash: echo "##vso[task.setVariable variable=legs;isOutput=true]{'a':{'myvar':'A'}, 'b':{'myvar':'B'}}"
name: mtrx
# This expands to the matrix
# a:
# myvar: A
# b:
# myvar: B
- job: runner
dependsOn: generator
strategy:
matrix: $[ dependencies.generator.outputs['mtrx.legs'] ]
steps:
- script: echo $(myvar) # echos A or B depending on which leg is running
Segmentación
Un trabajo de agente se puede usar para ejecutar un conjunto de pruebas en paralelo. Por ejemplo, puede ejecutar un amplio conjunto de 1000 pruebas en un solo agente. O bien, puede usar dos agentes y ejecutar 500 pruebas en cada uno en paralelo.
Para aplicar la segmentación, las tareas del trabajo deben ser lo suficientemente inteligentes como para comprender el segmento al que pertenecen.
La tarea de prueba de Visual Studio es una de estas tareas que admite la segmentación de pruebas. Si ha instalado varios agentes, puede especificar cómo se ejecutará la tarea de prueba de Visual Studio en paralelo en estos agentes.
La estrategia parallel permite que un trabajo se duplique muchas veces.
Las variables System.JobPositionInPhase y System.TotalJobsInPhase se agregan a cada trabajo. A continuación, las variables se pueden usar dentro de los scripts para dividir el trabajo entre los trabajos.
Consulte Ejecución en paralelo y varias ejecuciones mediante trabajos de agente.
El siguiente trabajo se enviará cinco veces con el correcto establecimiento de los valores de System.JobPositionInPhase y System.TotalJobsInPhase.
jobs:
- job: Test
strategy:
parallel: 5
Variables de trabajo
Si usa YAML, se pueden especificar variables en el trabajo. Las variables se pueden pasar a las entradas de tarea mediante la sintaxis de macro $(variableName) o se puede acceder a ellas dentro de un script mediante la variable de fase.
Este es un ejemplo de definición de variables en un trabajo y su uso en tareas.
variables:
mySimpleVar: simple var value
"my.dotted.var": dotted var value
"my var with spaces": var with spaces value
steps:
- script: echo Input macro = $(mySimpleVar). Env var = %MYSIMPLEVAR%
condition: eq(variables['agent.os'], 'Windows_NT')
- script: echo Input macro = $(mySimpleVar). Env var = $MYSIMPLEVAR
condition: in(variables['agent.os'], 'Darwin', 'Linux')
- bash: echo Input macro = $(my.dotted.var). Env var = $MY_DOTTED_VAR
- powershell: Write-Host "Input macro = $(my var with spaces). Env var = $env:MY_VAR_WITH_SPACES"
Para obtener información sobre el uso de una condición, consulte Especificar condiciones.
Área de trabajo
Cuando se ejecuta un trabajo de grupo de agentes, se crea un área de trabajo en el agente. El área de trabajo es un directorio en el que descarga el origen, ejecuta los pasos y genera salidas. Se puede hacer referencia al directorio del área de trabajo en el trabajo mediante la variable Pipeline.Workspace. En este caso, se crean varios subdirectorios:
-
Build.SourcesDirectoryes donde las tareas descargan el código fuente de la aplicación. -
Build.ArtifactStagingDirectoryes donde las tareas descargan artefactos necesarios para la canalización o cargan artefactos antes de que se publiquen. -
Build.BinariesDirectoryes donde las tareas escriben sus salidas. -
Common.TestResultsDirectoryes donde las tareas cargan sus resultados de prueba.
Los $(Build.ArtifactStagingDirectory) y $(Common.TestResultsDirectory) siempre se eliminan y se recrean antes de cada compilación.
Al ejecutar una canalización en un agente autohospedado, de forma predeterminada, ninguno de los subdirectorios distintos de $(Build.ArtifactStagingDirectory) y $(Common.TestResultsDirectory) se limpia entre dos ejecuciones consecutivas. Como resultado, se pueden realizar compilaciones y despliegues incrementales, si se implementan tareas para hacer uso de ellos. Puede invalidar este comportamiento mediante la configuración workspace del trabajo.
Importante
Las opciones de limpieza del área de trabajo solo son aplicables a los agentes autohospedados. Los trabajos se ejecutan siempre en un nuevo agente con agentes hospedados en Microsoft.
- job: myJob
workspace:
clean: outputs | resources | all # what to clean up before the job runs
Al especificar una de las opciones clean, se interpretan de la siguiente manera:
-
outputs: elimineBuild.BinariesDirectoryantes de ejecutar un nuevo trabajo. -
resources: elimineBuild.SourcesDirectoryantes de ejecutar un nuevo trabajo. -
all: elimine todo el directorioPipeline.Workspaceantes de ejecutar un nuevo trabajo.
jobs:
- deployment: MyDeploy
pool:
vmImage: 'ubuntu-latest'
workspace:
clean: all
environment: staging
Nota:
Según las capacidades del agente y las demandas de canalización, cada trabajo se puede enrutar a un agente diferente en el grupo autohospedado. Como resultado, puede obtener un nuevo agente para ejecuciones de canalización posteriores (o fases o trabajos en la misma canalización), por lo que no limpiar no es una garantía de que las ejecuciones, trabajos o fases posteriores puedan acceder a las salidas de ejecuciones, trabajos o fases anteriores. Puede configurar las capacidades de los agentes y las demandas de pipeline para especificar qué agentes se utilizan para ejecutar un trabajo de pipeline. Pero a menos que haya un único agente en el grupo que satisfaga las demandas, no hay garantía de que los trabajos posteriores utilicen el mismo agente que los anteriores. Para obtener más información, consulte Especificar peticiones.
Además de limpiar el área de trabajo, también puede configurar la limpieza mediante la configuración Limpiar en la interfaz de usuario de configuración de la canalización. Cuando la opción Limpiar es true, que también es su valor predeterminado, equivale a especificar clean: true para cada paso de restauración de la canalización. Al especificar clean: true, ejecute git clean -ffdx seguido de git reset --hard HEAD antes de hacer fetch en Git. Para configurar la opción Limpiar:
Edite la canalización, elija ... y seleccione Desencadenadores.
Seleccione YAML, Obtener orígenes y configure la opción de Limpiar deseada. El valor predeterminado es true.
Descarga del artefacto
Este archivo YAML de ejemplo publica el artefacto Website y, a continuación, descarga el artefacto en $(Pipeline.Workspace). El trabajo de implementación solo se ejecuta si el trabajo de compilación se realiza correctamente.
# test and upload my code as an artifact named Website
jobs:
- job: Build
pool:
vmImage: 'ubuntu-latest'
steps:
- script: npm test
- task: PublishPipelineArtifact@1
inputs:
artifactName: Website
targetPath: '$(System.DefaultWorkingDirectory)'
# download the artifact and deploy it only if the build job succeeded
- job: Deploy
pool:
vmImage: 'ubuntu-latest'
steps:
- checkout: none #skip checking out the default repository resource
- task: DownloadPipelineArtifact@2
displayName: 'Download Pipeline Artifact'
inputs:
artifactName: Website
targetPath: '$(Pipeline.Workspace)'
dependsOn: Build
condition: succeeded()
Para obtener información sobre el uso de dependsOn y condition, consulte Especificar condiciones.
Acceso al token de OAuth
Puede permitir que los scripts que se ejecutan en un trabajo accedan al token de seguridad OAuth de Azure Pipelines actual. El token se puede usar para autenticarse en la API de REST de Azure Pipelines.
El token de OAuth siempre está disponible para las canalizaciones de YAML.
Debe asignarse explícitamente a la tarea o paso mediante env.
Este es un ejemplo:
steps:
- powershell: |
$url = "$($env:SYSTEM_TEAMFOUNDATIONCOLLECTIONURI)$env:SYSTEM_TEAMPROJECTID/_apis/build/definitions/$($env:SYSTEM_DEFINITIONID)?api-version=4.1-preview"
Write-Host "URL: $url"
$pipeline = Invoke-RestMethod -Uri $url -Headers @{
Authorization = "Bearer $env:SYSTEM_ACCESSTOKEN"
}
Write-Host "Pipeline = $($pipeline | ConvertTo-Json -Depth 100)"
env:
SYSTEM_ACCESSTOKEN: $(system.accesstoken)