Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
El almacenamiento de alto rendimiento de Azure DocumentDB usa SSD Premium v2 para ofrecer una latencia baja coherente y IOPS predecibles para cargas de trabajo intensivas de E/S. Esta funcionalidad le permite lograr el escalado de rendimiento en función de las configuraciones de proceso y almacenamiento, maximizando el rendimiento y la eficacia por núcleo virtual.
Orientación
El rendimiento máximo de almacenamiento para el clúster de Azure DocumentDB depende de la combinación del nivel de proceso y el tamaño de almacenamiento que seleccione. Cada combinación determina los límites efectivos de IOPS y rendimiento. Empiece por elegir el tamaño de almacenamiento que necesita y, a continuación, seleccione un nivel de proceso que proporcione las operaciones de entrada y salida necesarias por segundo (IOPS) y el rendimiento de la carga de trabajo. Si no está seguro acerca de los requisitos de rendimiento:
Comience con el nivel de proceso que desbloquea completamente el rendimiento de almacenamiento para el tamaño seleccionado.
Ejecutar pruebas comparativas de cargas de trabajo.
Reduzca gradualmente la capacidad de cómputo hasta que encuentre la categoría más pequeña que ofrezca el rendimiento deseado.
Límites de IOPS y rendimiento
En esta sección se enumeran los límites de IOPS y rendimiento de cada nivel de Azure DocumentDB:
Para más información sobre los niveles, consulte Los niveles de proceso y almacenamiento.
2 Núcleos virtuales (M30)
| Almacenamiento (GiB) | 32 | 64 | 128 | 256 | 512 | 1024 | 2048 | 4096 | 8192 | 16384 | 32768 | 65536 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IOPS máx. | 3750 | 3750 | 3750 | 3750 | 3750 | 3750 | 3750 | 3750 | 3750 | 3750 | 3750 | 3750 |
| Rendimiento máximo (MB/s) | 85 | 85 | 85 | 85 | 85 | 85 | 85 | 85 | 85 | 85 | 85 | 85 |
4 Núcleos virtuales (M40)
| Almacenamiento (GiB) | 32 | 64 | 128 | 256 | 512 | 1024 | 2048 | 4096 | 8192 | 16384 | 32768 | 65536 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IOPS máx. | 6\.400 | 6\.400 | 6\.400 | 6\.400 | 6\.400 | 6\.400 | 6\.400 | 6\.400 | 6\.400 | 6\.400 | 6\.400 | 6\.400 |
| Rendimiento máximo (MB/s) | 145 | 145 | 145 | 145 | 145 | 145 | 145 | 145 | 145 | 145 | 145 | 145 |
8 Núcleos virtuales (M50)
| Almacenamiento (GiB) | 32 | 64 | 128 | 256 | 512 | 1024 | 2048 | 4096 | 8192 | 16384 | 32768 | 65536 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IOPS máx. | 12.800 | 12.800 | 12.800 | 12.800 | 12.800 | 12.800 | 12.800 | 12.800 | 12.800 | 12.800 | 12.800 | 12.800 |
| Rendimiento máximo (MB/s) | 290 | 290 | 290 | 290 | 290 | 290 | 290 | 290 | 290 | 290 | 290 | 290 |
16 Núcleos virtuales (M60)
| Almacenamiento (GiB) | 32 | 64 | 128 | 256 | 512 | 1024 | 2048 | 4096 | 8192 | 16384 | 32768 | 65536 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IOPS máx. | 16 000 | 25.600 | 25.600 | 25.600 | 25.600 | 25.600 | 25.600 | 25.600 | 25.600 | 25.600 | 25.600 | 25.600 |
| Rendimiento máximo (MB/s) | 600 | 600 | 600 | 600 | 600 | 600 | 600 | 600 | 600 | 600 | 600 | 600 |
32 Núcleos virtuales (M80)
| Almacenamiento (GiB) | 32 | 64 | 128 | 256 | 512 | 1024 | 2048 | 4096 | 8192 | 16384 | 32768 | 65536 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IOPS máx. | 16 000 | 32 000 | 51 200 | 51 200 | 51 200 | 51 200 | 51 200 | 51 200 | 51 200 | 51 200 | 51 200 | 51 200 |
| Rendimiento máximo (MB/s) | 865 | 865 | 865 | 865 | 865 | 865 | 865 | 865 | 865 | 865 | 865 | 865 |
64 Núcleos virtuales (M200)
| Almacenamiento (GiB) | 32 | 64 | 128 | 256 | 512 | 1024 | 2048 | 4096 | 8192 | 16384 | 32768 | 65536 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IOPS máx. | 16 000 | 32 000 | 64 000 | 80 000 | 80 000 | 80 000 | 80 000 | 80 000 | 80 000 | 80 000 | 80 000 | 80 000 |
| Rendimiento máximo (MB/s) | 1,200 | 1,200 | 1,200 | 1,200 | 1,200 | 1,200 | 1,200 | 1,200 | 1,200 | 1,200 | 1,200 | 1,200 |
Prerrequisitos
Una suscripción de Azure
- Si no tiene ninguna suscripción a Azure, cree una cuenta gratuita
Un clúster de Azure DocumentDB existente
- Si no tiene un clúster, cree un nuevo clúster.
Use el entorno de Bash en Azure Cloud Shell. Para más información, consulte Introducción a Azure Cloud Shell.

Si prefieres ejecutar comandos de referencia CLI localmente, instala la CLI de Azure. Si estás utilizando Windows o macOS, considera ejecutar Azure CLI en un contenedor Docker. Para obtener más información, consulte Cómo ejecutar el Azure CLI en un contenedor de Docker.
Si estás utilizando una instalación local, inicia sesión en Azure CLI utilizando el comando az login. Siga los pasos que se muestran en el terminal para completar el proceso de autenticación. Para ver otras opciones de inicio de sesión, consulte Autenticación en Azure mediante la CLI de Azure.
En caso de que se le solicite, instale las extensiones de la CLI de Azure la primera vez que la use. Para obtener más información sobre las extensiones, consulte Uso y administración de extensiones con la CLI de Azure.
Ejecute az version para ver la versión y las bibliotecas dependientes que están instaladas. Para actualizar a la versión más reciente, ejecute az upgrade.
- Terraform 1.2.0 o posterior.
Creación de un clúster con almacenamiento de alto rendimiento
Configurar un clúster utilizando el almacenamiento SSD Premium v2 (alto rendimiento) como parte del proceso de creación del clúster.
Inicie sesión en Azure Portal (https://portal.azure.com).
En el menú de Azure Portal o en la página principal, seleccione Crear un recurso.
En la página Nuevo , busque y seleccione Azure DocumentDB.
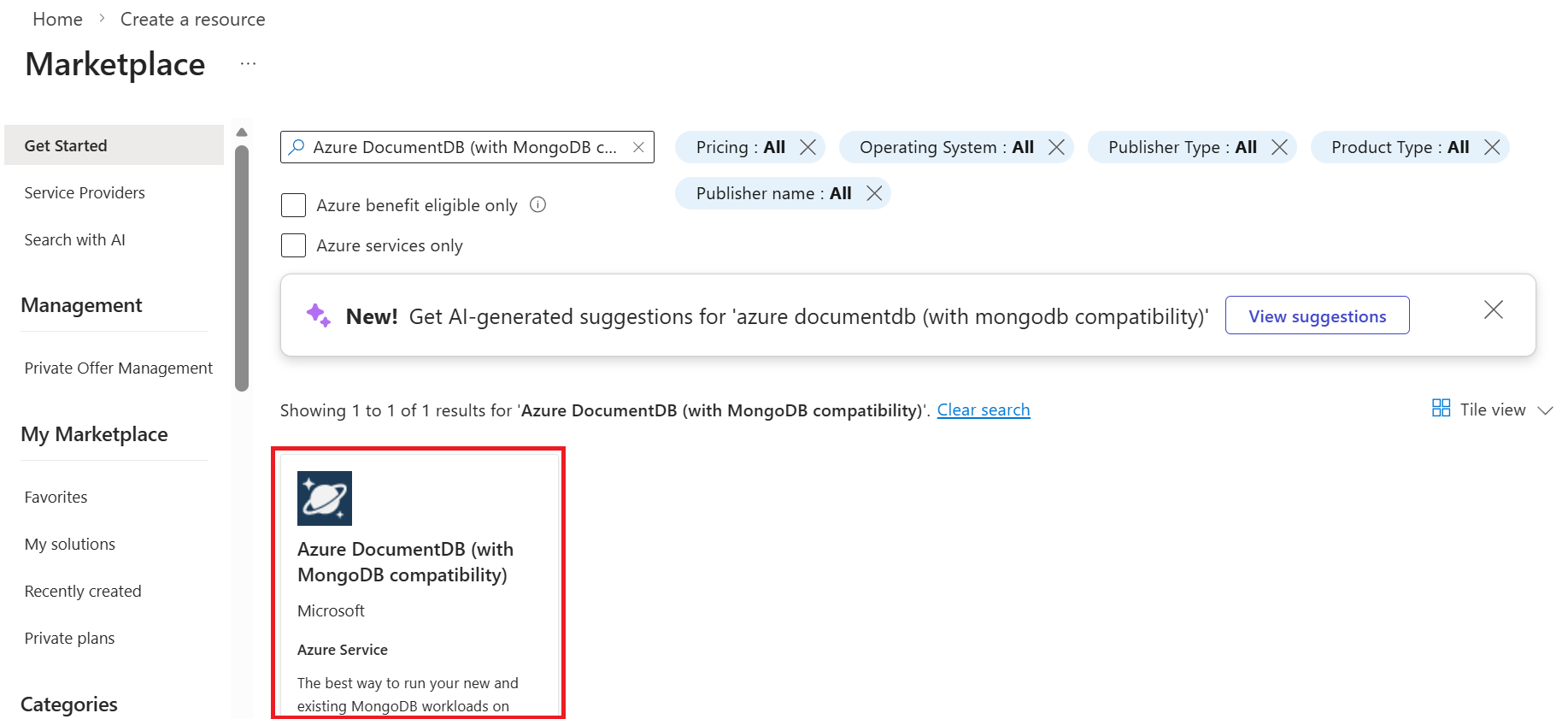
En la página Crear clúster de Azure DocumentDB y, en la sección Aspectos básicos , seleccione la opción Configurar en la sección Nivel de clúster.
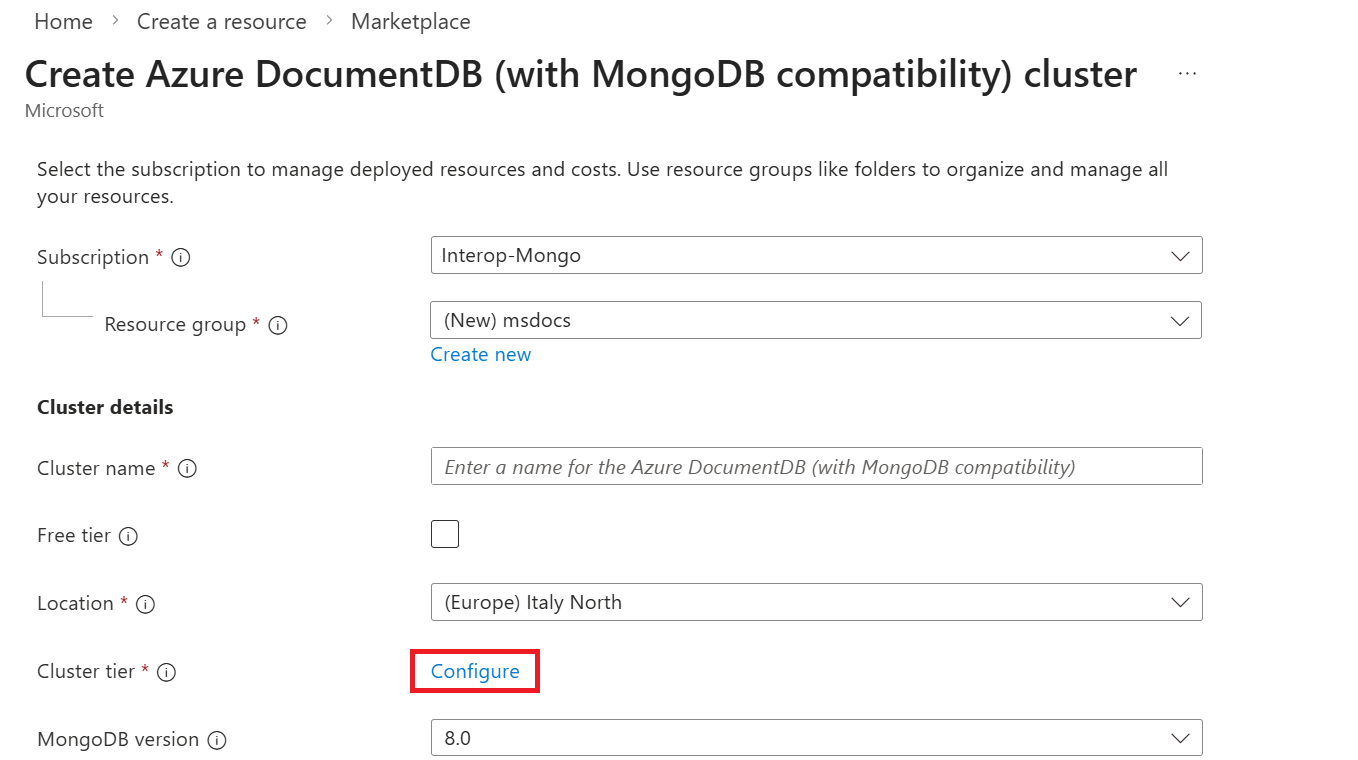
En la página Configurar , elija el nivel de clúster y el tamaño de almacenamiento según sea necesario. Seleccione el tipo de almacenamiento como SSD Premium v2 (versión preliminar) para habilitar el almacenamiento de alto rendimiento y, después, seleccione Guardar para aplicar los cambios.
Rellene los detalles restantes y seleccione Revisar y crear.
Revise la configuración que proporcione y, a continuación, seleccione Crear. La operación de creación del clúster tarda unos minutos. Espere a que se complete la implementación de recursos.
Por último, seleccione Ir al recurso para ir al clúster de Azure DocumentDB en el portal.
Abrir un nuevo terminal.
Inicie sesión en la CLI de Azure.
Cree un nuevo archivo de Bicep para definir tu rol. Asigne al archivo el nombre main.bicep.
Agregue esta plantilla al contenido del archivo. Reemplace los marcadores de posición
<cluster-name>,<location>,<username>y<password>por los valores adecuados.resource cluster 'Microsoft.DocumentDB/mongoClusters@2025-08-01-preview' = { name: '<cluster-name>' location: '<location>' properties: { administrator: { userName: '<username>' password: '<password>' } serverVersion: '8.0' storage: { sizeGb: 32 type: 'PremiumSSDv2' } compute: { tier: 'M30' } sharding: { shardCount: 1 } highAvailability: { targetMode: 'Disabled' } } }Implemente la plantilla de Bicep usando
az deployment group create. Especifique el nombre de la plantilla de Bicep y reemplace el<resource-group>marcador de posición por el nombre del grupo de recursos de Azure de destino.az deployment group create \ --resource-group "<resource-group>" \ --template-file main.bicepEspere a que la implementación se complete. Revise la salida de la implementación.
Abrir un nuevo terminal.
Inicie sesión en la CLI de Azure.
Compruebe la suscripción de Azure de destino.
az account showDefina el clúster en un nuevo archivo de Terraform. Asigne al archivo el nombre cluster.
tf.Agregue esta configuración de recursos al contenido del archivo. Reemplace los marcadores de posición
<cluster-name>,<resource-group>y<location>con los valores adecuados.variable "admin_username" { type = string description = "Administrator username for the cluster." sensitive = true } variable "admin_password" { type = string description = "Administrator password for the cluster." sensitive = true } terraform { required_providers { azurerm = { source = "hashicorp/azurerm" version = "~> 4.0" } } } provider "azurerm" { features {} } data "azurerm_resource_group" "existing" { name = "<resource-group>" } resource "azurerm_mongo_cluster" "cluster" { name = "<cluster-name>" resource_group_name = data.azurerm_resource_group.existing.name location = "<location>" administrator_username = var.admin_username administrator_password = var.admin_password shard_count = "1" compute_tier = "M30" high_availability_mode = "Disabled" storage_size_in_gb = "32" storage_type = "PremiumSSDv2" version = "8.0" }Sugerencia
Para obtener más información sobre las opciones que usan el recurso, consulte
azurerm_mongo_clusterazurermdocumentación del proveedor en Terraform Registry.Inicialice la implementación de Terraform.
terraform init --upgradeCree un plan de ejecución y guárdelo en un archivo denominado cluster.tfplan. Proporcione valores cuando se le pidan las
admin_usernamevariables yadmin_password.ARM_SUBSCRIPTION_ID=$(az account show --query id --output tsv) terraform plan --out "cluster.tfplan"Nota:
Este comando establece temporalmente la
ARM_SUBSCRIPTION_IDvariable de entorno. Esta configuración es necesaria para el proveedor deazurermcomenzando con la versión 4.0. Para obtener más información, consulte Id. de suscripción enazurerm.Aplique el plan de ejecución para implementar el clúster en Azure.
ARM_SUBSCRIPTION_ID=$(az account show --query id --output tsv) terraform apply "cluster.tfplan"Espere a que la implementación se complete. Revise la salida de la implementación.
Abrir un nuevo terminal.
Inicie sesión en la CLI de Azure.
Cree un nuevo archivo JSON denominado cluster.json.
Agregue este documento al contenido del archivo. Reemplace los marcadores de posición
<location>,<username>y<password>con los valores adecuados.{ "location": "<location>", "properties": { "administrator": { "userName": "<username>", "password": "<password>" }, "serverVersion": "8.0", "storage": { "sizeGb": 32, "type": "PremiumSSDv2" }, "compute": { "tier": "M30" }, "sharding": { "shardCount": 1 }, "highAvailability": { "targetMode": "Disabled" } } }Use el comando de la
az restCLI de Azure para crear un clúster con la configuración especificada en el archivo JSON. Especifique el nombre del archivo JSON como elbodyde la solicitud y reemplace los siguientes marcadores de posición:Description <subscription-id>Identificador único de la suscripción de Azure de destino <resource-group>Nombre del grupo de recursos de Azure de destino <cluster-name>Nombre único del nuevo clúster de Azure DocumentDB az rest \ --method "GET" \ --url "https://management.azure.com/subscriptions/<subscription-id>/resourceGroups/<resource-group>/providers/Microsoft.DocumentDB/mongoClusters/<cluster-name>/users?api-version=2025-08-01-preview" \ --body @cluster.jsonSugerencia
Use
az account showpara obtener el identificador único de la suscripción de Azure de destino.Espere a que la implementación se complete. Revise la salida de la implementación.
Limitaciones del almacenamiento de alto rendimiento
Estas son las limitaciones de la característica de almacenamiento de alto rendimiento:
No se admite la alta disponibilidad (AD)
No se admiten clústeres de réplica
No se admiten claves administradas por el cliente (CMK)
Azure Portal representa el tamaño de almacenamiento, pero no representa IOPS o rendimiento efectivos.
El almacenamiento de alto rendimiento está disponible en un subconjunto limitado de regiones de Azure
Consideraciones para el almacenamiento de alto rendimiento
Tenga en cuenta estos aspectos al usar el almacenamiento de alto rendimiento en el clúster de Azure DocumentDB:
- El almacenamiento de alto rendimiento puede obtener el máximo rendimiento de la combinación de proceso y almacenamiento seleccionada para el precio fijo por 1 GiB de almacenamiento /mes. Para más información, consulte Precios de Azure DocumentDB.