Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Importante
- Foundry Local está disponible en versión preliminar. Las versiones preliminares públicas proporcionan acceso anticipado a las características que se encuentran en la implementación activa.
- Las características, los enfoques y los procesos pueden cambiar o tener funcionalidades limitadas, antes de la disponibilidad general (GA).
El SDK local de Foundry simplifica la administración de modelos de IA en entornos locales al proporcionar operaciones del plano de control independientes del código de inferencia del plano de datos. Esta referencia documenta implementaciones del SDK para Python, JavaScript, C# y Rust.
Referencia del SDK de Python
Prerrequisitos
- Instale Foundry Local y asegúrese de que el
foundrycomando está disponible enPATH. - Utilice Python 3.9 o posterior.
Installation
Instale el paquete de Python:
pip install foundry-local-sdk
Inicio rápido
Use este fragmento de código para comprobar que el SDK puede iniciar el servicio y llegar al catálogo local.
from foundry_local import FoundryLocalManager
manager = FoundryLocalManager()
manager.start_service()
catalog = manager.list_catalog_models()
print(f"Catalog models available: {len(catalog)}")
En este ejemplo se imprime un número distinto de cero cuando se ejecuta el servicio y el catálogo está disponible.
Referencias:
Clase FoundryLocalManager
La FoundryLocalManager clase proporciona métodos para administrar modelos, caché y el servicio local Foundry.
Inicialización
from foundry_local import FoundryLocalManager
# Initialize and optionally bootstrap with a model
manager = FoundryLocalManager(alias_or_model_id=None, bootstrap=True)
-
alias_or_model_id: (opcional) Nombre alternativo o ID de modelo para descargar y cargar al inicio. -
bootstrap: (valor predeterminado True) Si es True, inicia el servicio si no se ejecuta y carga el modelo si se proporciona.
Una nota sobre los alias
Muchos métodos descritos en esta referencia tienen un alias_or_model_id parámetro en la firma. Puede pasar al método un alias o un identificador de modelo como un valor. El uso de un alias hará lo siguiente:
- Seleccione el mejor modelo para el hardware disponible. Por ejemplo, si hay disponible una GPU de Nvidia CUDA, Foundry Local selecciona el modelo CUDA. Si hay disponible una NPU compatible, Foundry Local selecciona el modelo de NPU.
- Permite usar un nombre más corto sin necesidad de recordar el identificador del modelo.
Sugerencia
Se recomienda pasar al alias_or_model_id parámetro un alias porque al implementar la aplicación, Foundry Local adquiere el mejor modelo para el equipo del usuario final en tiempo de ejecución.
Nota:
Si tiene una NPU de Intel en Windows, asegúrese de que ha instalado el controlador NPU de Intel para obtener una aceleración de NPU óptima.
Administración de servicios
| Método | Signature | Description |
|---|---|---|
is_service_running() |
() -> bool |
Comprueba si el servicio Foundry Local se está ejecutando. |
start_service() |
() -> None |
Inicia el servicio Foundry Local. |
service_uri |
@property -> str |
Devuelve el URI del servicio. |
endpoint |
@property -> str |
Devuelve el punto de conexión de servicio. |
api_key |
@property -> str |
Devuelve la clave de API (de env o predeterminada). |
Administración de catálogos
| Método | Signature | Description |
|---|---|---|
list_catalog_models() |
() -> list[FoundryModelInfo] |
Enumera todos los modelos disponibles en el catálogo. |
refresh_catalog() |
() -> None |
Actualiza el catálogo de modelos. |
get_model_info() |
(alias_or_model_id: str, raise_on_not_found=False) -> FoundryModelInfo \| None |
Obtiene la información del modelo por alias o identificador. |
Administración de la memoria caché
| Método | Signature | Description |
|---|---|---|
get_cache_location() |
() -> str |
Devuelve la ruta de acceso del directorio de caché del modelo. |
list_cached_models() |
() -> list[FoundryModelInfo] |
Enumera los modelos descargados en la caché local. |
Administración de modelos
| Método | Signature | Description |
|---|---|---|
download_model() |
(alias_or_model_id: str, token: str = None, force: bool = False) -> FoundryModelInfo |
Descarga un modelo en la memoria caché local. |
load_model() |
(alias_or_model_id: str, ttl: int = 600) -> FoundryModelInfo |
Carga un modelo en el servidor de inferencia. |
unload_model() |
(alias_or_model_id: str, force: bool = False) -> None |
Descarga un modelo del servidor de inferencia. |
list_loaded_models() |
() -> list[FoundryModelInfo] |
Enumera todos los modelos cargados actualmente en el servicio. |
FoundryModelInfo
Los métodos list_catalog_models(), list_cached_models()y list_loaded_models() devuelven una lista de FoundryModelInfo objetos . Puede usar la información contenida en este objeto para refinar aún más la lista. O bien, obtenga la información de un modelo directamente llamando al get_model_info(alias_or_model_id) método .
Estos objetos contienen los siguientes campos:
| Campo | Tipo | Description |
|---|---|---|
alias |
str |
Alias del modelo. |
id |
str |
Identificador único del modelo. |
version |
str |
Versión del modelo. |
execution_provider |
str |
Acelerador (proveedor de ejecución) usado para ejecutar el modelo. |
device_type |
DeviceType |
Tipo de dispositivo del modelo: CPU, GPU, NPU. |
uri |
str |
URI del modelo. |
file_size_mb |
int |
Tamaño del modelo en disco en MB. |
supports_tool_calling |
bool |
Si el modelo admite llamadas a herramientas. |
prompt_template |
dict \| None |
Solicitud de plantilla para el modelo. |
provider |
str |
Proveedor del modelo (donde se publica el modelo). |
publisher |
str |
Publicador del modelo (quién publicó el modelo). |
license |
str |
Nombre de la licencia del modelo. |
task |
str |
Tarea del modelo. Uno de estos valores: chat-completions o automatic-speech-recognition. |
ep_override |
str \| None |
Invalide para el proveedor de ejecución, si es diferente del valor predeterminado del modelo. |
Proveedores de ejecución
Uno de los valores siguientes:
-
CPUExecutionProvider- Ejecución basada en CPU -
CUDAExecutionProvider- Ejecución de GPU de NVIDIA CUDA -
WebGpuExecutionProvider- Ejecución de WebGPU -
QNNExecutionProvider- Ejecución de red neuronal de Qualcomm (NPU) -
OpenVINOExecutionProvider- Ejecución de Intel OpenVINO -
NvTensorRTRTXExecutionProvider- Ejecución de NVIDIA TensorRT -
VitisAIExecutionProvider- Ejecución de la inteligencia artificial de Vitis de AMD
Ejemplo de uso
En el código siguiente se muestra cómo usar la FoundryLocalManager clase para administrar modelos e interactuar con el servicio local Foundry.
from foundry_local import FoundryLocalManager
# By using an alias, the most suitable model will be selected
# to your end-user's device.
alias = "qwen2.5-0.5b"
# Create a FoundryLocalManager instance. This will start the Foundry.
manager = FoundryLocalManager()
# List available models in the catalog
catalog = manager.list_catalog_models()
print(f"Available models in the catalog: {catalog}")
# Download and load a model
model_info = manager.download_model(alias)
model_info = manager.load_model(alias)
print(f"Model info: {model_info}")
# List models in cache
local_models = manager.list_cached_models()
print(f"Models in cache: {local_models}")
# List loaded models
loaded = manager.list_loaded_models()
print(f"Models running in the service: {loaded}")
# Unload a model
manager.unload_model(alias)
En este ejemplo se enumeran modelos, se descarga y carga un modelo, y luego se descarga.
Referencias:
Integración con el SDK de OpenAI
Instale el paquete OpenAI:
pip install openai
En el código siguiente se muestra cómo integrar con FoundryLocalManager el SDK de OpenAI para interactuar con un modelo local.
import openai
from foundry_local import FoundryLocalManager
# By using an alias, the most suitable model will be downloaded
# to your end-user's device.
alias = "qwen2.5-0.5b"
# Create a FoundryLocalManager instance. This will start the Foundry
# Local service if it is not already running and load the specified model.
manager = FoundryLocalManager(alias)
# The remaining code uses the OpenAI Python SDK to interact with the local model.
# Configure the client to use the local Foundry service
client = openai.OpenAI(
base_url=manager.endpoint,
api_key=manager.api_key # API key is not required for local usage
)
# Set the model to use and generate a streaming response
stream = client.chat.completions.create(
model=manager.get_model_info(alias).id,
messages=[{"role": "user", "content": "Why is the sky blue?"}],
stream=True
)
# Print the streaming response
for chunk in stream:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="", flush=True)
En este ejemplo se transmite una respuesta de finalización de chat del modelo local.
Referencias:
Referencia del SDK de JavaScript
Prerrequisitos
- Instale Foundry Local y asegúrese de que el
foundrycomando está disponible enPATH.
Installation
Instale el paquete desde npm:
npm install foundry-local-sdk
Inicio rápido
Use este fragmento de código para comprobar que el SDK puede iniciar el servicio y llegar al catálogo local.
import { FoundryLocalManager } from "foundry-local-sdk";
const manager = new FoundryLocalManager();
await manager.startService();
const catalogModels = await manager.listCatalogModels();
console.log(`Catalog models available: ${catalogModels.length}`);
En este ejemplo se imprime un número distinto de cero cuando se ejecuta el servicio y el catálogo está disponible.
Referencias:
Clase FoundryLocalManager
La FoundryLocalManager clase le permite administrar modelos, controlar la memoria caché e interactuar con el servicio local Foundry en entornos de explorador y Node.js.
Inicialización
import { FoundryLocalManager } from "foundry-local-sdk";
const foundryLocalManager = new FoundryLocalManager();
Opciones disponibles:
-
host: dirección URL base del servicio local Foundry -
fetch: (opcional) Implementación de captura personalizada para entornos como Node.js
Una nota sobre los alias
Muchos métodos descritos en esta referencia tienen un aliasOrModelId parámetro en la firma. Puede pasar al método un alias o un identificador de modelo como un valor. El uso de un alias hará lo siguiente:
- Seleccione el mejor modelo para el hardware disponible. Por ejemplo, si hay disponible una GPU de Nvidia CUDA, Foundry Local selecciona el modelo CUDA. Si hay disponible una NPU compatible, Foundry Local selecciona el modelo de NPU.
- Permite usar un nombre más corto sin necesidad de recordar el identificador del modelo.
Sugerencia
Se recomienda pasar al aliasOrModelId parámetro un alias porque al implementar la aplicación, Foundry Local adquiere el mejor modelo para el equipo del usuario final en tiempo de ejecución.
Nota:
Si tiene una NPU de Intel en Windows, asegúrese de que ha instalado el controlador NPU de Intel para obtener una aceleración de NPU óptima.
Administración de servicios
| Método | Signature | Description |
|---|---|---|
init() |
(aliasOrModelId?: string) => Promise<FoundryModelInfo \| void> |
Inicializa el SDK y, opcionalmente, carga un modelo. |
isServiceRunning() |
() => Promise<boolean> |
Comprueba si el servicio Foundry Local se está ejecutando. |
startService() |
() => Promise<void> |
Inicia el servicio Foundry Local. |
serviceUrl |
string |
Dirección URL base del servicio local Foundry. |
endpoint |
string |
Punto de conexión de API (serviceUrl + /v1). |
apiKey |
string |
La clave de API (ninguna). |
Administración de catálogos
| Método | Signature | Description |
|---|---|---|
listCatalogModels() |
() => Promise<FoundryModelInfo[]> |
Enumera todos los modelos disponibles en el catálogo. |
refreshCatalog() |
() => Promise<void> |
Actualiza el catálogo de modelos. |
getModelInfo() |
(aliasOrModelId: string, throwOnNotFound = false) => Promise<FoundryModelInfo \| null> |
Obtiene la información del modelo por alias o identificador. |
Administración de la memoria caché
| Método | Signature | Description |
|---|---|---|
getCacheLocation() |
() => Promise<string> |
Devuelve la ruta de acceso del directorio de caché del modelo. |
listCachedModels() |
() => Promise<FoundryModelInfo[]> |
Enumera los modelos descargados en la caché local. |
Administración de modelos
| Método | Signature | Description |
|---|---|---|
downloadModel() |
(aliasOrModelId: string, token?: string, force = false, onProgress?) => Promise<FoundryModelInfo> |
Descarga un modelo en la memoria caché local. |
loadModel() |
(aliasOrModelId: string, ttl = 600) => Promise<FoundryModelInfo> |
Carga un modelo en el servidor de inferencia. |
unloadModel() |
(aliasOrModelId: string, force = false) => Promise<void> |
Descarga un modelo del servidor de inferencia. |
listLoadedModels() |
() => Promise<FoundryModelInfo[]> |
Enumera todos los modelos cargados actualmente en el servicio. |
Ejemplo de uso
En el código siguiente se muestra cómo usar la FoundryLocalManager clase para administrar modelos e interactuar con el servicio local Foundry.
import { FoundryLocalManager } from "foundry-local-sdk";
// By using an alias, the most suitable model will be downloaded
// to your end-user's device.
// TIP: You can find a list of available models by running the
// following command in your terminal: `foundry model list`.
const alias = "qwen2.5-0.5b";
const manager = new FoundryLocalManager();
// Initialize the SDK and optionally load a model
const modelInfo = await manager.init(alias);
console.log("Model Info:", modelInfo);
// Check if the service is running
const isRunning = await manager.isServiceRunning();
console.log(`Service running: ${isRunning}`);
// List available models in the catalog
const catalog = await manager.listCatalogModels();
// Download and load a model
await manager.downloadModel(alias);
await manager.loadModel(alias);
// List models in cache
const localModels = await manager.listCachedModels();
// List loaded models
const loaded = await manager.listLoadedModels();
// Unload a model
await manager.unloadModel(alias);
En este ejemplo se descarga y carga un modelo y, a continuación, se enumeran los modelos almacenados en caché y cargados.
Referencias:
Integración con el cliente de OpenAI
Instale el paquete OpenAI:
npm install openai
El siguiente código demuestra cómo integrar el FoundryLocalManager con el cliente de OpenAI para interactuar con un modelo local.
import { OpenAI } from "openai";
import { FoundryLocalManager } from "foundry-local-sdk";
// By using an alias, the most suitable model will be downloaded
// to your end-user's device.
// TIP: You can find a list of available models by running the
// following command in your terminal: `foundry model list`.
const alias = "qwen2.5-0.5b";
// Create a FoundryLocalManager instance. This will start the Foundry
// Local service if it is not already running.
const foundryLocalManager = new FoundryLocalManager();
// Initialize the manager with a model. This will download the model
// if it is not already present on the user's device.
const modelInfo = await foundryLocalManager.init(alias);
console.log("Model Info:", modelInfo);
const openai = new OpenAI({
baseURL: foundryLocalManager.endpoint,
apiKey: foundryLocalManager.apiKey,
});
async function streamCompletion() {
const stream = await openai.chat.completions.create({
model: modelInfo.id,
messages: [{ role: "user", content: "What is the golden ratio?" }],
stream: true,
});
for await (const chunk of stream) {
if (chunk.choices[0]?.delta?.content) {
process.stdout.write(chunk.choices[0].delta.content);
}
}
}
streamCompletion();
En este ejemplo se transmite una respuesta de finalización de chat del modelo local.
Referencias:
Uso del explorador
El SDK incluye una versión compatible con el explorador donde debe especificar manualmente la dirección URL del host:
import { FoundryLocalManager } from "foundry-local-sdk/browser";
// Specify the service URL
// Run the Foundry Local service using the CLI: `foundry service start`
// and use the URL from the CLI output
const host = "HOST";
const manager = new FoundryLocalManager({ host });
// Note: The `init`, `isServiceRunning`, and `startService` methods
// are not available in the browser version
Nota:
La versión del explorador no admite los initmétodos , isServiceRunningy startService . Debe asegurarse de que el servicio local Foundry se está ejecutando antes de usar el SDK en un entorno de navegador. Puede iniciar el servicio mediante la CLI local de Foundry: foundry service start. Puede obtener la dirección URL del servicio desde la salida de la CLI.
Ejemplo de uso
import { FoundryLocalManager } from "foundry-local-sdk/browser";
// Specify the service URL
// Run the Foundry Local service using the CLI: `foundry service start`
// and use the URL from the CLI output
const host = "HOST";
const manager = new FoundryLocalManager({ host });
const alias = "qwen2.5-0.5b";
// Get all available models
const catalog = await manager.listCatalogModels();
console.log("Available models in catalog:", catalog);
// Download and load a specific model
await manager.downloadModel(alias);
await manager.loadModel(alias);
// View models in your local cache
const localModels = await manager.listCachedModels();
console.log("Cached models:", localModels);
// Check which models are currently loaded
const loaded = await manager.listLoadedModels();
console.log("Loaded models in inference service:", loaded);
// Unload a model when finished
await manager.unloadModel(alias);
Referencias:
Referencia del SDK de C#
Guía de configuración del proyecto
Hay dos paquetes NuGet para el SDK local de Foundry( WinML y un paquete multiplataforma) que tienen la misma superficie de API, pero están optimizadas para distintas plataformas:
-
Windows: usa el
Microsoft.AI.Foundry.Local.WinMLpaquete específico de las aplicaciones de Windows, que usa el marco de Windows Machine Learning (WinML). -
Multiplataforma: usa el
Microsoft.AI.Foundry.Localpaquete que se puede usar para aplicaciones multiplataforma (Windows, Linux, macOS).
En función de la plataforma de destino, siga estas instrucciones para crear una nueva aplicación de C# y agregar las dependencias necesarias:
Use Foundry Local en el proyecto de C# siguiendo estas instrucciones específicas de Windows o multiplataforma (macOS/Linux/Windows):
- Cree un nuevo proyecto de C# y vaya a él:
dotnet new console -n app-name cd app-name - Abra y edite el
app-name.csprojarchivo en:<Project Sdk="Microsoft.NET.Sdk"> <PropertyGroup> <OutputType>Exe</OutputType> <TargetFramework>net9.0-windows10.0.26100</TargetFramework> <RootNamespace>app-name</RootNamespace> <ImplicitUsings>enable</ImplicitUsings> <Nullable>enable</Nullable> <WindowsAppSDKSelfContained>false</WindowsAppSDKSelfContained> <WindowsPackageType>None</WindowsPackageType> <EnableCoreMrtTooling>false</EnableCoreMrtTooling> </PropertyGroup> <ItemGroup> <PackageReference Include="Microsoft.AI.Foundry.Local.WinML" Version="0.8.2.1" /> <PackageReference Include="Microsoft.Extensions.Logging" Version="9.0.10" /> <PackageReference Include="OpenAI" Version="2.5.0" /> </ItemGroup> </Project> - Cree un
nuget.configarchivo en la raíz del proyecto con el siguiente contenido para que los paquetes se restauren correctamente:<?xml version="1.0" encoding="utf-8"?> <configuration> <packageSources> <clear /> <add key="nuget.org" value="https://api.nuget.org/v3/index.json" /> <add key="ORT" value="https://aiinfra.pkgs.visualstudio.com/PublicPackages/_packaging/ORT/nuget/v3/index.json" /> </packageSources> <packageSourceMapping> <packageSource key="nuget.org"> <package pattern="*" /> </packageSource> <packageSource key="ORT"> <package pattern="*Foundry*" /> </packageSource> </packageSourceMapping> </configuration>
Inicio rápido
Use este fragmento de código para comprobar que el SDK puede inicializar y acceder al catálogo de modelos local.
using Microsoft.AI.Foundry.Local;
using Microsoft.Extensions.Logging;
using System.Linq;
var config = new Configuration
{
AppName = "app-name",
LogLevel = Microsoft.AI.Foundry.Local.LogLevel.Information,
};
using var loggerFactory = LoggerFactory.Create(builder =>
{
builder.SetMinimumLevel(Microsoft.Extensions.Logging.LogLevel.Information);
});
var logger = loggerFactory.CreateLogger<Program>();
await FoundryLocalManager.CreateAsync(config, logger);
var manager = FoundryLocalManager.Instance;
var catalog = await manager.GetCatalogAsync();
var models = await catalog.ListModelsAsync();
Console.WriteLine($"Models available: {models.Count()}");
En este ejemplo se imprime el número de modelos disponibles para tu hardware.
Referencias:
Rediseño
Para mejorar la capacidad de enviar aplicaciones mediante inteligencia artificial en el dispositivo, hay cambios sustanciales en la arquitectura del SDK de C# en la versión 0.8.0 y versiones posteriores. En esta sección, se describen los cambios clave que le ayudarán a migrar las aplicaciones a la versión más reciente del SDK.
Nota:
En la versión 0.8.0 del SDK y versiones posteriores, hay cambios importantes en la API de versiones anteriores.
En el diagrama siguiente se muestra cómo la arquitectura anterior , para versiones anteriores a 0.8.0 , se basaba en gran medida en el uso de un servidor web REST para administrar modelos e inferencias como finalizaciones de chat:

El SDK usaría una llamada de procedimiento remota (RPC) para buscar el ejecutable de la CLI local de Foundry en la máquina, iniciar el servidor web y, a continuación, comunicarse con él a través de HTTP. Esta arquitectura tenía varias limitaciones, entre las que se incluyen:
- Complejidad en la administración del ciclo de vida del servidor web.
- Implementación complicada: los usuarios finales necesitaban tener instalada la CLI local de Foundry en sus máquinas y la aplicación.
- La administración de versiones de la CLI y el SDK podrían provocar problemas de compatibilidad.
Para solucionar estos problemas, la arquitectura rediseñada en la versión 0.8.0 y versiones posteriores usa un enfoque más simplificado. La nueva arquitectura es la siguiente:

En esta nueva arquitectura:
- La aplicación es independiente. No requiere que la CLI local de Foundry se instale por separado en la máquina del usuario final, lo que facilita la implementación de aplicaciones.
- El servidor web REST es opcional. Todavía puede usar el servidor web si desea integrar con otras herramientas que se comunican a través de HTTP. Lea Uso de finalizaciones de chat a través del servidor REST con Foundry Local para obtener más información sobre cómo usar esta característica.
- El SDK tiene compatibilidad nativa con finalizaciones de chat y transcripciones de audio, lo que le permite crear aplicaciones de inteligencia artificial conversacional con menos dependencias. Lea Use Foundry Local native chat completions API (Uso de la API de finalizaciones de chat nativo local de Foundry ) para obtener más información sobre cómo usar esta característica.
- En dispositivos Windows, puedes utilizar una compilación de Windows ML que gestiona la aceleración de hardware para modelos en el dispositivo mediante la integración del entorno de ejecución y los controladores adecuados.
Cambios de API
La versión 0.8.0 y versiones posteriores proporcionan una API más orientada a objetos y que se pueden componer. El punto de entrada principal sigue siendo la FoundryLocalManager clase , pero en lugar de ser un conjunto plano de métodos que funcionan a través de llamadas estáticas a una API HTTP sin estado, el SDK ahora expone métodos en la FoundryLocalManager instancia que mantienen el estado sobre el servicio y los modelos.
| Primitivo | Versiones < 0.8.0 | Versiones >= 0.8.0 |
|---|---|---|
| Configuración | N/A | config = Configuration(...) |
| Obtener administrador | mgr = FoundryLocalManager(); |
await FoundryLocalManager.CreateAsync(config, logger);var mgr = FoundryLocalManager.Instance; |
| Obtener catálogo | N/A | catalog = await mgr.GetCatalogAsync(); |
| Enumerar modelos | mgr.ListCatalogModelsAsync(); |
catalog.ListModelsAsync(); |
| Obtener modelo | mgr.GetModelInfoAsync("aliasOrModelId"); |
catalog.GetModelAsync(alias: "alias"); |
| Obtener variante | N/A | model.SelectedVariant; |
| Establecer variante | N/A | model.SelectVariant(); |
| Descarga de un modelo | mgr.DownloadModelAsync("aliasOrModelId"); |
model.DownloadAsync() |
| Carga de un modelo | mgr.LoadModelAsync("aliasOrModelId"); |
model.LoadAsync() |
| Descargar un modelo | mgr.UnloadModelAsync("aliasOrModelId"); |
model.UnloadAsync() |
| Enumerar modelos cargados | mgr.ListLoadedModelsAsync(); |
catalog.GetLoadedModelsAsync(); |
| Obtener la ruta del modelo | N/A | model.GetPathAsync() |
| Iniciar servicio | mgr.StartServiceAsync(); |
mgr.StartWebServerAsync(); |
| Detener servicio | mgr.StopServiceAsync(); |
mgr.StopWebServerAsync(); |
| Ubicación de caché | mgr.GetCacheLocationAsync(); |
config.ModelCacheDir |
| Enumerar modelos almacenados en caché | mgr.ListCachedModelsAsync(); |
catalog.GetCachedModelsAsync(); |
La API permite que Foundry Local sea más configurable a través del servidor web, el registro, la ubicación de caché y la selección de variantes del modelo. Por ejemplo, la Configuration clase permite configurar el nombre de la aplicación, el nivel de registro, las direcciones URL del servidor web y los directorios para los datos de la aplicación, la caché del modelo y los registros:
var config = new Configuration
{
AppName = "app-name",
LogLevel = Microsoft.AI.Foundry.Local.LogLevel.Information,
Web = new Configuration.WebService
{
Urls = "http://127.0.0.1:55588"
},
AppDataDir = "./foundry_local_data",
ModelCacheDir = "{AppDataDir}/model_cache",
LogsDir = "{AppDataDir}/logs"
};
Referencias:
En la versión anterior del SDK de C# local de Foundry, no se pudieron configurar estas opciones directamente a través del SDK, lo que limitaba la capacidad de personalizar el comportamiento del servicio.
Reducir el tamaño del paquete de aplicación
El SDK local de Foundry incorpora el paquete NuGet como dependencia. El Microsoft.ML.OnnxRuntime.Foundry paquete proporciona el paquete de tiempo de ejecución para la inferencia, que es el conjunto de bibliotecas necesarias para ejecutar de forma eficaz la inferencia en dispositivos de hardware de proveedores específicos. El conjunto de tiempo de ejecución de inferencia incluye los siguientes componentes:
-
Biblioteca en tiempo de ejecución de ONNX: el motor de inferencia principal (
onnxruntime.dll). -
Biblioteca del proveedor de ejecución en tiempo de ejecución (EP) de ONNX. En el entorno de ejecución de ONNX, un servicio de fondo específico del hardware que optimiza y ejecuta partes de un modelo de aprendizaje automático y un acelerador de hardware. Por ejemplo:
- CUDA EP:
onnxruntime_providers_cuda.dll - QNN EP:
onnxruntime_providers_qnn.dll
- CUDA EP:
-
Bibliotecas independientes del proveedor de hardware (IHV). Por ejemplo:
- WebGPU: dependencias de DirectX (
dxcompiler.dll,dxil.dll) - QNN: dependencias de Qualcomm QNN (
QnnSystem.dll, etc.)
- WebGPU: dependencias de DirectX (
En la tabla siguiente se resumen las bibliotecas EP e IHV que se incluyen con la aplicación y qué winML descargará o instalará en tiempo de ejecución:
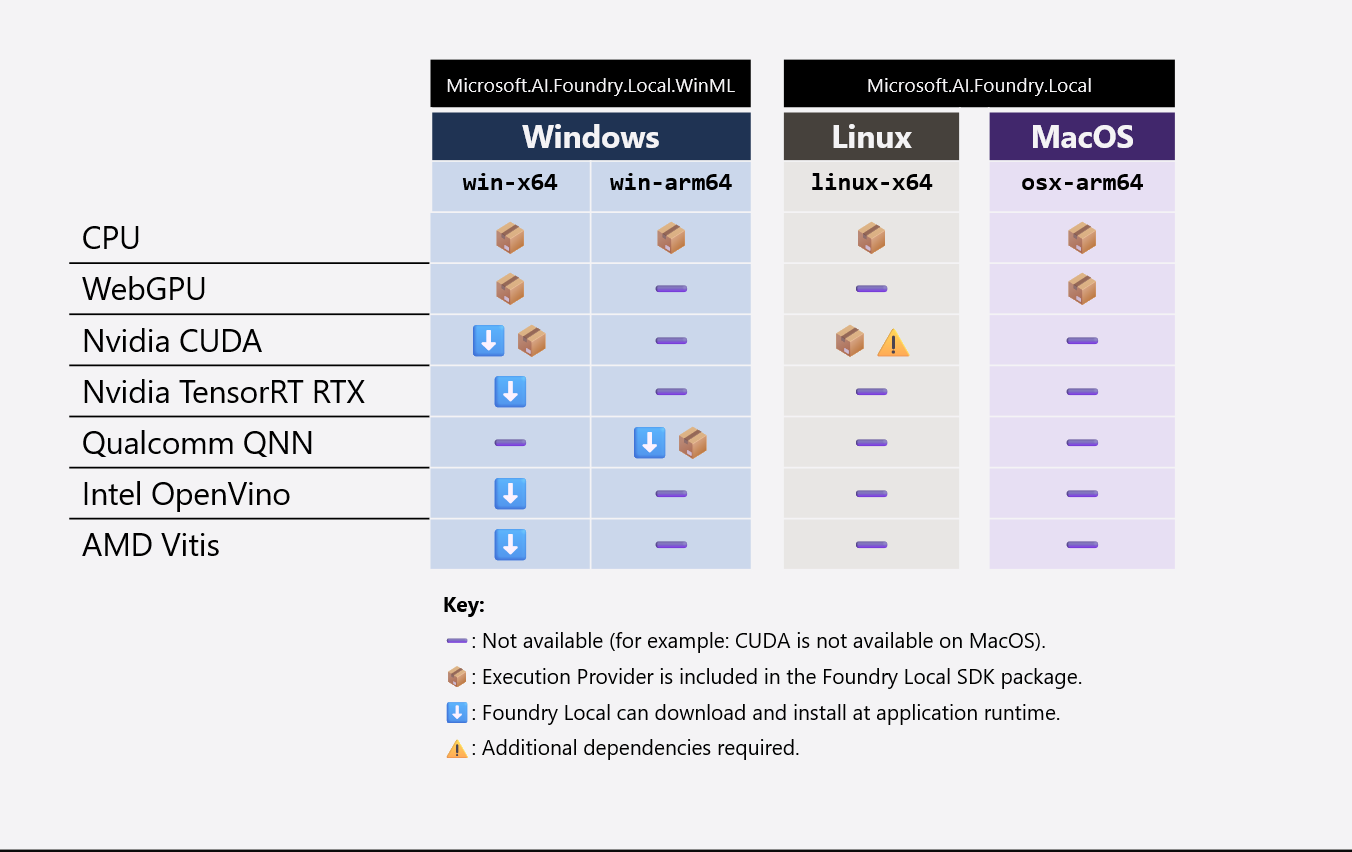
En todas las plataformas y arquitecturas, se requiere el EP de CPU. Las bibliotecas WEBGPU EP e IHV tienen un tamaño pequeño (por ejemplo, WebGPU solo agrega ~7 MB al paquete de aplicación) y son necesarias en Windows y macOS. Sin embargo, los EP de CUDA y QNN tienen un tamaño grande (por ejemplo, CUDA agrega ~1 GB al paquete de aplicación), por lo que se recomienda excluir estos EP del paquete de aplicación. WinML descargará o instalará CUDA y QNN en tiempo de ejecución si el usuario final tiene hardware compatible.
Nota:
Estamos trabajando para quitar los EP de CUDA y QNN del paquete Microsoft.ML.OnnxRuntime.Foundry en futuras versiones para que no necesite incluir un archivo ExcludeExtraLibs.props para quitarlos del paquete de aplicación.
Para reducir el tamaño del paquete de aplicación, puede crear un ExcludeExtraLibs.props archivo en el directorio del proyecto con el siguiente contenido, que excluye las bibliotecas CUDA y QNN EP e IHV al publicar la aplicación:
<Project>
<!-- we want to ensure we're using the onnxruntime libraries from Foundry Local Core so
we delete the WindowsAppSdk versions once they're unzipped. -->
<Target Name="ExcludeOnnxRuntimeLibs" AfterTargets="ExtractMicrosoftWindowsAppSDKMsixFiles">
<Delete Files="$(MicrosoftWindowsAppSDKMsixContent)\onnxruntime.dll"/>
<Delete Files="$(MicrosoftWindowsAppSDKMsixContent)\onnxruntime_providers_shared.dll"/>
<Message Importance="Normal" Text="Deleted onnxruntime libraries from $(MicrosoftWindowsAppSDKMsixContent)." />
</Target>
<!-- Remove CUDA EP and IHV libraries on Windows x64 -->
<Target Name="ExcludeCudaLibs" Condition="'$(RuntimeIdentifier)'=='win-x64'" AfterTargets="ResolvePackageAssets">
<ItemGroup>
<!-- match onnxruntime*cuda.* (we're matching %(Filename) which excludes the extension) -->
<NativeCopyLocalItems Remove="@(NativeCopyLocalItems)"
Condition="$([System.Text.RegularExpressions.Regex]::IsMatch('%(Filename)',
'^onnxruntime.*cuda.*', RegexOptions.IgnoreCase))" />
</ItemGroup>
<Message Importance="Normal" Text="Excluded onnxruntime CUDA libraries from package." />
</Target>
<!-- Remove QNN EP and IHV libraries on Windows arm64 -->
<Target Name="ExcludeQnnLibs" Condition="'$(RuntimeIdentifier)'=='win-arm64'" AfterTargets="ResolvePackageAssets">
<ItemGroup>
<NativeCopyLocalItems Remove="@(NativeCopyLocalItems)"
Condition="$([System.Text.RegularExpressions.Regex]::IsMatch('%(Filename)%(Extension)',
'^QNN.*\.dll', RegexOptions.IgnoreCase))" />
<NativeCopyLocalItems Remove="@(NativeCopyLocalItems)"
Condition="$([System.Text.RegularExpressions.Regex]::IsMatch('%(Filename)',
'^libQNNhtp.*', RegexOptions.IgnoreCase))" />
<NativeCopyLocalItems Remove="@(NativeCopyLocalItems)"
Condition="'%(FileName)%(Extension)' == 'onnxruntime_providers_qnn.dll'" />
</ItemGroup>
<Message Importance="Normal" Text="Excluded onnxruntime QNN libraries from package." />
</Target>
<!-- need to manually copy on linux-x64 due to the nuget packages not having the correct props file setup -->
<ItemGroup Condition="'$(RuntimeIdentifier)' == 'linux-x64'">
<!-- 'Update' as the Core package will add these dependencies, but we want to be explicit about the version -->
<PackageReference Update="Microsoft.ML.OnnxRuntime.Gpu" />
<PackageReference Update="Microsoft.ML.OnnxRuntimeGenAI.Cuda" />
<OrtNativeLibs Include="$(NuGetPackageRoot)microsoft.ml.onnxruntime.gpu.linux/$(OnnxRuntimeVersion)/runtimes/$(RuntimeIdentifier)/native/*" />
<OrtGenAINativeLibs Include="$(NuGetPackageRoot)microsoft.ml.onnxruntimegenai.cuda/$(OnnxRuntimeGenAIVersion)/runtimes/$(RuntimeIdentifier)/native/*" />
</ItemGroup>
<Target Name="CopyOrtNativeLibs" AfterTargets="Build" Condition=" '$(RuntimeIdentifier)' == 'linux-x64'">
<Copy SourceFiles="@(OrtNativeLibs)" DestinationFolder="$(OutputPath)"></Copy>
<Copy SourceFiles="@(OrtGenAINativeLibs)" DestinationFolder="$(OutputPath)"></Copy>
</Target>
</Project>
En el archivo de proyecto (.csproj), agregue la siguiente línea para importar el ExcludeExtraLibs.props archivo:
<!-- other project file content -->
<Import Project="ExcludeExtraLibs.props" />
Windows: dependencias de CUDA
CUDA EP se integra en tu aplicación Linux a través de Microsoft.ML.OnnxRuntime.Foundry, pero no se incluyen las bibliotecas de IHV. Si quiere permitir que los usuarios finales con dispositivos habilitados para CUDA se beneficien del rendimiento superior, debe agregar las siguientes bibliotecas de IHV de CUDA a la aplicación:
- CUBLAS v12.8.4 (descarga de NVIDIA Developer)
- cublas64_12.dll
- cublasLt64_12.dll
- CUDA RT v12.8.90 (descarga de NVIDIA Developer)
- cudart64_12.dll
- CUDNN V9.8.0 (descarga de NVIDIA Developer)
- cudnn_graph64_9.dll
- cudnn_ops64_9.dll
- cudnn64_9.dll
- CUDA FFT v11.3.3.83 (descarga de NVIDIA Developer)
- cufft64_11.dll
Advertencia
Agregar las bibliotecas CUDA EP e IHV a la aplicación aumentan el tamaño del paquete de aplicación en 1 GB.
Muestras
- Para ver aplicaciones de ejemplo que muestran cómo usar el SDK de C# local de Foundry, consulte el repositorio de GitHub de ejemplos del SDK de C# local de Foundry.
Referencia de API
- Para obtener más información sobre el SDK de C# local de Foundry, consulte Referencia de la API del SDK de C# local de Foundry.
Referencia del SDK de Rust
El SDK de Rust para Foundry Local proporciona una manera de administrar modelos, controlar la memoria caché e interactuar con el servicio local foundry.
Prerrequisitos
- Instale Foundry Local y asegúrese de que el
foundrycomando está disponible enPATH. - Utilice Rust 1.70.0 o posterior.
Installation
Para usar el SDK de Foundry Local Rust, agregue lo siguiente a Cargo.toml:
[dependencies]
foundry-local = "0.1.0"
Como alternativa, puede agregar la caja local de Foundry mediante cargo:
cargo add foundry-local
Inicio rápido
Use este fragmento de código para comprobar que el SDK puede iniciar el servicio y leer el catálogo local.
use anyhow::Result;
use foundry_local::FoundryLocalManager;
#[tokio::main]
async fn main() -> Result<()> {
let mut manager = FoundryLocalManager::builder().bootstrap(true).build().await?;
let models = manager.list_catalog_models().await?;
println!("Catalog models available: {}", models.len());
Ok(())
}
En este ejemplo se imprime un número distinto de cero cuando se ejecuta el servicio y el catálogo está disponible.
Referencias:
FoundryLocalManager
Administrador para las operaciones del SDK local de Foundry.
Campos
-
service_uri: Option<String>— URI del servicio Foundry. -
client: Option<HttpClient>: cliente HTTP para solicitudes de API. -
catalog_list: Option<Vec<FoundryModelInfo>>: lista almacenada en caché de modelos de catálogo. -
catalog_dict: Option<HashMap<String, FoundryModelInfo>>: diccionario almacenado en caché de modelos de catálogo. -
timeout: Option<u64>: tiempo de espera del cliente HTTP opcional.
Methods
pub fn builder() -> FoundryLocalManagerBuilder
Crear un nuevo constructor paraFoundryLocalManager.pub fn service_uri(&self) -> Result<&str>
Obtenga el URI del servicio.
Devuelve: URI del servicio Foundry.fn client(&self) -> Result<&HttpClient>
Obtenga la instancia de cliente HTTP.
Devuelve: cliente HTTP.pub fn endpoint(&self) -> Result<String>
Obtenga el punto de conexión del servicio.
Devuelve: dirección URL del punto de conexión.pub fn api_key(&self) -> String
Obtenga la clave de API para la autenticación.
Devuelve: clave de API.pub fn is_service_running(&mut self) -> bool
Compruebe si el servicio se está ejecutando y establezca el URI del servicio si se encuentra.
Devuelve:truesi se ejecuta,falsede lo contrario.pub fn start_service(&mut self) -> Result<()>
Inicie el servicio local Foundry.pub async fn list_catalog_models(&mut self) -> Result<&Vec<FoundryModelInfo>>
Obtenga una lista de los modelos disponibles en el catálogo.pub fn refresh_catalog(&mut self)
Actualice la memoria caché del catálogo.pub async fn get_model_info(&mut self, alias_or_model_id: &str, raise_on_not_found: bool) -> Result<FoundryModelInfo>
Obtener información del modelo por alias o identificador.
Argumentos:-
alias_or_model_id: alias o id. de modelo. -
raise_on_not_found: si es true, error si no se encuentra.
-
pub async fn get_cache_location(&self) -> Result<String>
Obtiene la ubicación de la memoria caché como una cadena.pub async fn list_cached_models(&mut self) -> Result<Vec<FoundryModelInfo>>
Enumerar modelos almacenados en caché.pub async fn download_model(&mut self, alias_or_model_id: &str, token: Option<&str>, force: bool) -> Result<FoundryModelInfo>
Descargue un modelo.
Argumentos:-
alias_or_model_id: alias o id. de modelo. -
token: token de autenticación opcional. -
force: forzar la nueva descarga si ya está almacenado en caché.
-
pub async fn load_model(&mut self, alias_or_model_id: &str, ttl: Option<i32>) -> Result<FoundryModelInfo>
Cargue un modelo para la inferencia.
Argumentos:-
alias_or_model_id: alias o id. de modelo. -
ttl: Tiempo de vida opcional en segundos.
-
pub async fn unload_model(&mut self, alias_or_model_id: &str, force: bool) -> Result<()>
Descargue un modelo.
Argumentos:-
alias_or_model_id: alias o id. de modelo. -
force: forzar la descarga incluso si está en uso.
-
pub async fn list_loaded_models(&mut self) -> Result<Vec<FoundryModelInfo>>
Enumerar modelos cargados.
FoundryLocalManagerBuilder
Generador para crear una FoundryLocalManager instancia.
Campos
-
alias_or_model_id: Option<String>: alias o identificador de modelo para descargar y cargar. -
bootstrap: bool: indica si se debe iniciar el servicio si no se está ejecutando. -
timeout_secs: Option<u64>: tiempo de espera del cliente HTTP en segundos.
Methods
pub fn new() -> Self
Cree una nueva instancia del constructor.pub fn alias_or_model_id(mut self, alias_or_model_id: impl Into<String>) -> Self
Establezca el alias o el identificador de modelo para descargar y cargar.pub fn bootstrap(mut self, bootstrap: bool) -> Self
Establezca si se va a iniciar el servicio si no se está ejecutando.pub fn timeout_secs(mut self, timeout_secs: u64) -> Self
Establezca el tiempo de espera del cliente HTTP en segundos.pub async fn build(self) -> Result<FoundryLocalManager>
Cree la instanciaFoundryLocalManager.
FoundryModelInfo
Representa información sobre un modelo.
Campos
-
alias: String: alias del modelo. -
id: String: identificador del modelo. -
—
version: StringLa versión del modelo. -
runtime: ExecutionProvider— El proveedor de ejecución (CPU, CUDA, etc.). -
uri: String: el URI del modelo. -
file_size_mb: i32— Tamaño del archivo de modelo en MB. -
prompt_template: serde_json::Value: solicitud de plantilla para el modelo. -
provider: String: nombre del proveedor. -
publisher: String: nombre del publicador. -
license: String— Tipo de licencia. -
task: String— Tarea Modelo (por ejemplo, generación de texto).
Methods
from_list_response(response: &FoundryListResponseModel) -> Self
Crea un objetoFoundryModelInfoa partir de una respuesta de catálogo.to_download_body(&self) -> serde_json::Value
Convierte la información del modelo en un cuerpo JSON para las solicitudes de descarga.
ExecutionProvider
Enumeración para proveedores de ejecución admitidos.
CPUWebGPUCUDAQNN
Methods
get_alias(&self) -> String
Devuelve un alias de cadena para el proveedor de ejecución.
ModelRuntime
Describe el entorno en tiempo de ejecución de un modelo.
device_type: DeviceTypeexecution_provider: ExecutionProvider