Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Descubra cómo utilizar C# para crear una solución de MapReduce en HDInsight.
El streaming de Apache Hadoop permite ejecutar trabajos de MapReduce mediante un script o ejecutable. Aquí se emplea .NET para implementar el asignador y reductor en una solución de recuento de palabras.
.NET en HDInsight
Los clústeres de HDInsight usan Mono (https://mono-project.com) para ejecutar aplicaciones .NET. La versión 4.2.1 de Mono está incluida en la versión 3.6 de HDInsight. Para más información sobre la versión de Mono incluida con HDInsight, consulte Componentes de Apache Hadoop disponibles con las versiones de HDInsight.
Si desea conocer más detalles sobre la compatibilidad entre Mono y las versiones de .NET Framework, consulte la página en la que se trata la compatibilidad de Mono.
Funcionamiento del streaming de Hadoop
A continuación se expone el proceso básico que se emplea para realizar streaming en este documento:
- Hadoop transfiere datos al asignador (mapper.exe en este ejemplo) en STDIN.
- El asignador procesa los datos y envía pares clave-valor delimitados por tabulaciones a STDOUT.
- Hadoop lee los resultados, que, a continuación, se transfieren al reductor (reducer.exe en este ejemplo) en STDIN.
- El reductor lee los pares clave-valor delimitados por tabulaciones, procesa los datos y, después, envía el resultado en forma de pares clave-valor delimitados por tabulaciones en STDOUT.
- Hadoop lee los resultados, que, a continuación, se escriben en el directorio de salida.
Para más información, consulte Hadoop Streaming.
Prerrequisitos
Visual Studio.
Estar familiarizado con la escritura y la compilación del código C# orientado a .NET Framework 4.5.
Una forma de cargar archivos .exe en el clúster. En los pasos descritos en este documento se emplean las herramientas Data Lake para Visual Studio para cargar los archivos en el almacenamiento principal del clúster.
Si usa PowerShell, necesitará el Módulo Az.
Un clúster de Apache Hadoop en HDInsight. Consulte Introducción a HDInsight en Linux.
El esquema de URI para el almacenamiento principal de clústeres. Este esquema sería
wasb://para Azure Storage,abfs://para Azure Data Lake Storage Gen2 oadl://para Azure Data Lake Storage Gen1. Si la transferencia segura está habilitada para Azure Storage o Data Lake Storage Gen2, el URI seráwasbs://oabfss://, respectivamente.
Creación del asignador
En Visual Studio, cree una nueva aplicación de consola denominada mapper. Use el código siguiente para la aplicación:
using System;
using System.Text.RegularExpressions;
namespace mapper
{
class Program
{
static void Main(string[] args)
{
string line;
//Hadoop passes data to the mapper on STDIN
while((line = Console.ReadLine()) != null)
{
// We only want words, so strip out punctuation, numbers, etc.
var onlyText = Regex.Replace(line, @"\.|;|:|,|[0-9]|'", "");
// Split at whitespace.
var words = Regex.Matches(onlyText, @"[\w]+");
// Loop over the words
foreach(var word in words)
{
//Emit tab-delimited key/value pairs.
//In this case, a word and a count of 1.
Console.WriteLine("{0}\t1",word);
}
}
}
}
}
Después de crear la aplicación, compílela para generar el archivo /bin/Debug/mapper.exe en el directorio del proyecto.
Creación del reductor
En Visual Studio, cree una aplicación de consola de .NET Framework denominada reducer. Use el código siguiente para la aplicación:
using System;
using System.Collections.Generic;
namespace reducer
{
class Program
{
static void Main(string[] args)
{
//Dictionary for holding a count of words
Dictionary<string, int> words = new Dictionary<string, int>();
string line;
//Read from STDIN
while ((line = Console.ReadLine()) != null)
{
// Data from Hadoop is tab-delimited key/value pairs
var sArr = line.Split('\t');
// Get the word
string word = sArr[0];
// Get the count
int count = Convert.ToInt32(sArr[1]);
//Do we already have a count for the word?
if(words.ContainsKey(word))
{
//If so, increment the count
words[word] += count;
} else
{
//Add the key to the collection
words.Add(word, count);
}
}
//Finally, emit each word and count
foreach (var word in words)
{
//Emit tab-delimited key/value pairs.
//In this case, a word and a count of 1.
Console.WriteLine("{0}\t{1}", word.Key, word.Value);
}
}
}
}
Después de crear la aplicación, compílela para generar el archivo /bin/Debug/reducer.exe en el directorio del proyecto.
Carga en el almacenamiento
Luego, debe cargas las aplicaciones mapper y reducer en el almacenamiento de HDInsight.
En Visual Studio, seleccione Ver>Explorador de servidores.
Haga clic con el botón derecho en Azure, seleccione Conectar a la suscripción de Microsoft Azure... y complete el proceso de inicio de sesión.
Expanda el clúster de HDInsight en el que desee implementar esta aplicación. Aparecerá una entrada con el texto (Cuenta de almacenamiento predeterminada) en la lista.
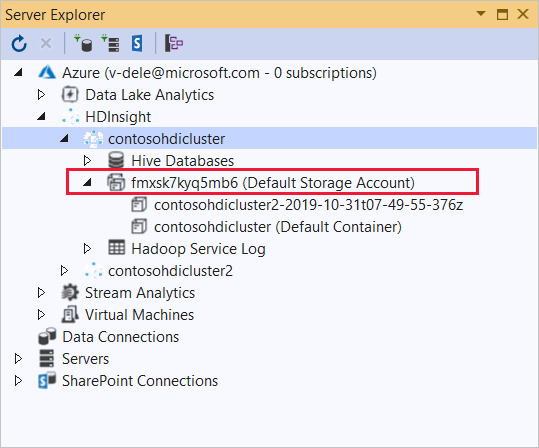
Si se puede expandir la entrada (Cuenta de almacenamiento predeterminada) , significa que está usando una cuenta de Azure Storage como almacenamiento predeterminado para el clúster. Para ver los archivos incluidos en el almacenamiento predeterminado del clúster, expanda la entrada y, luego, haga doble clic en (Contenedor predeterminado) .
Si la entrada (Cuenta de almacenamiento predeterminada) no se puede expandir, significa que está usando Azure Data Lake Storage como almacenamiento predeterminado para el clúster. Para ver los archivos incluidos en el almacenamiento predeterminado del clúster, haga doble clic en la entrada (Cuenta de almacenamiento predeterminada) .
Para cargar los archivos .exe, siga uno de estos métodos:
Si está usando una cuenta de Azure Storage, seleccione el icono Cargar blob.

En el cuadro de diálogo Cargar nuevo archivo, en Nombre de archivo, seleccione Examinar. En el cuadro de diálogo Cargar blob, vaya a la carpeta bin\debug del proyecto mapper y, luego, elija el archivo mapper.exe. Por último, seleccione Abrir y, a continuación, Aceptar para completar la carga.
Si usa Azure Data Lake Storage, haga clic con el botón derecho en un área vacía de la lista de archivos y, después, seleccione Cargar. Por último, seleccione el archivo mapper.exe y haga clic en Abrir.
Una vez que la carga del archivo mapper.exe haya finalizado, repita el proceso de carga con el archivo reducer.exe.
Ejecución de un trabajo: Con una sesión de SSH
En el procedimiento siguiente se describe cómo ejecutar un trabajo de MapReduce mediante una sesión de SSH:
Use el comando SSH para conectarse al clúster. Modifique el comando siguiente: reemplace CLUSTERNAME por el nombre del clúster y, luego, escriba el comando:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netUse uno de los siguientes comandos para iniciar el trabajo de MapReduce:
Si el almacenamiento predeterminado es Azure Storage:
yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-streaming.jar \ -files wasbs:///mapper.exe,wasbs:///reducer.exe \ -mapper mapper.exe \ -reducer reducer.exe \ -input /example/data/gutenberg/davinci.txt \ -output /example/wordcountoutSi el almacenamiento predeterminado es Data Lake Storage Gen1:
yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-streaming.jar \ -files adl:///mapper.exe,adl:///reducer.exe \ -mapper mapper.exe \ -reducer reducer.exe \ -input /example/data/gutenberg/davinci.txt \ -output /example/wordcountoutSi el almacenamiento predeterminado es Data Lake Storage Gen2:
yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-streaming.jar \ -files abfs:///mapper.exe,abfs:///reducer.exe \ -mapper mapper.exe \ -reducer reducer.exe \ -input /example/data/gutenberg/davinci.txt \ -output /example/wordcountout
En la lista siguiente se describe lo que representa cada parámetro y opción:
Parámetro Descripción hadoop-streaming.jar especifica el archivo .jar que contiene la funcionalidad de streaming de MapReduce. -files especifica los archivos mapper.exe y reducer.exe de este trabajo. La declaración del protocolo wasbs:///,adl:///oabfs:///delante de cada archivo es la ruta de acceso a la raíz del almacenamiento predeterminado del clúster.-mapper especifica el archivo que implementa el mapeador. -reducer especifica el archivo que implementa el reductor. -input especifica los datos de entrada. -output especifica el directorio de salida. Una vez completado el trabajo de MapReduce, use el siguiente comando para ver los resultados:
hdfs dfs -text /example/wordcountout/part-00000Este texto es un ejemplo de los datos que devuelve este comando:
you 1128 young 38 younger 1 youngest 1 your 338 yours 4 yourself 34 yourselves 3 youth 17
Ejecución de un trabajo: Usar PowerShell
Sírvase del siguiente script de PowerShell para ejecutar un trabajo de MapReduce y descargar los resultados.
# Login to your Azure subscription
$context = Get-AzContext
if ($context -eq $null)
{
Connect-AzAccount
}
$context
# Get HDInsight info
$clusterName = Read-Host -Prompt "Enter the HDInsight cluster name"
$creds=Get-Credential -Message "Enter the login for the cluster"
# Path for job output
$outputPath="/example/wordcountoutput"
# Progress indicator
$activity="C# MapReduce example"
Write-Progress -Activity $activity -Status "Getting cluster information..."
#Get HDInsight info so we can get the resource group, storage, etc.
$clusterInfo = Get-AzHDInsightCluster -ClusterName $clusterName
$resourceGroup = $clusterInfo.ResourceGroup
$storageActArr=$clusterInfo.DefaultStorageAccount.split('.')
$storageAccountName=$storageActArr[0]
$storageType=$storageActArr[1]
# Progress indicator
#Define the MapReduce job
# Note: using "/mapper.exe" and "/reducer.exe" looks in the root
# of default storage.
$jobDef=New-AzHDInsightStreamingMapReduceJobDefinition `
-Files "/mapper.exe","/reducer.exe" `
-Mapper "mapper.exe" `
-Reducer "reducer.exe" `
-InputPath "/example/data/gutenberg/davinci.txt" `
-OutputPath $outputPath
# Start the job
Write-Progress -Activity $activity -Status "Starting MapReduce job..."
$job=Start-AzHDInsightJob `
-ClusterName $clusterName `
-JobDefinition $jobDef `
-HttpCredential $creds
#Wait for the job to complete
Write-Progress -Activity $activity -Status "Waiting for the job to complete..."
Wait-AzHDInsightJob `
-ClusterName $clusterName `
-JobId $job.JobId `
-HttpCredential $creds
Write-Progress -Activity $activity -Completed
# Download the output
if($storageType -eq 'azuredatalakestore') {
# Azure Data Lake Store
# Fie path is the root of the HDInsight storage + $outputPath
$filePath=$clusterInfo.DefaultStorageRootPath + $outputPath + "/part-00000"
Export-AzDataLakeStoreItem `
-Account $storageAccountName `
-Path $filePath `
-Destination output.txt
} else {
# Az.Storage account
# Get the container
$container=$clusterInfo.DefaultStorageContainer
#NOTE: This assumes that the storage account is in the same resource
# group as HDInsight. If it is not, change the
# --ResourceGroupName parameter to the group that contains storage.
$storageAccountKey=(Get-AzStorageAccountKey `
-Name $storageAccountName `
-ResourceGroupName $resourceGroup)[0].Value
#Create a storage context
$context = New-AzStorageContext `
-StorageAccountName $storageAccountName `
-StorageAccountKey $storageAccountKey
# Download the file
Get-AzStorageBlobContent `
-Blob 'example/wordcountoutput/part-00000' `
-Container $container `
-Destination output.txt `
-Context $context
}
Este script le solicitará el nombre de la cuenta de inicio de sesión y la contraseña del clúster, junto con el nombre del clúster de HDInsight. Finalizado el trabajo, el resultado se descarga en un archivo denominado output.txt. A continuación, se muestra un ejemplo de los datos que contiene el archivo output.txt:
you 1128
young 38
younger 1
youngest 1
your 338
yours 4
yourself 34
yourselves 3
youth 17