Uso de Apache Hive como una herramienta de extracción, transformación y carga de datos (ETL)
Normalmente, deberá limpiar y transformar los datos entrantes antes de cargarlos en un destino adecuado para el análisis. Las operaciones de extracción, transformación y carga de datos (ETL) se utilizan para preparar los datos y cargarlos en un destino de datos. Apache Hive en HDInsight puede leer los datos no estructurados, procesarlos según sea necesario y, a continuación, cargarlos en un almacén de datos relacionales para los sistemas de ayuda a la toma de decisiones. En este enfoque, los datos se extraen del origen. A continuación, se almacenan en un almacenamiento adaptable, como Azure Storage Blobs o Azure Data Lake Storage. Después, los datos se transforman mediante una secuencia de consultas de Hive. Después, se almacenan dentro de Hive en la preparación para la carga masiva en el almacén de datos de destino.
Introducción del modelo y del caso de uso
En la siguiente ilustración se muestra una introducción del caso de uso y el modelo de automatización de ETL. Los datos de entrada se transforman para generar el resultado adecuado. Durante esa transformación, los datos cambian de forma, tipo e incluso de lenguaje. Los procesos ETL pueden convertir las unidades del sistema imperial al métrico, cambiar las zonas horarias y mejorar la precisión a fin de alinearse correctamente con los datos existentes en el destino. Los procesos ETL también pueden combinar los nuevos datos con los datos existentes para mantener los informes actualizados o para proporcionar más información sobre los datos existentes. A continuación, las aplicaciones, como los servicios y las herramientas de informes, pueden consumir estos datos en el formato deseado.
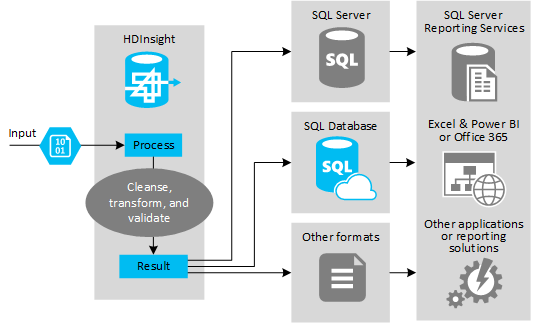
Hadoop se usa normalmente en procesos ETL que importan un gran número de archivos de texto (por ejemplo, CSV). O bien un número de archivos de texto menor, pero que cambian con frecuencia, o ambos. Hive es una herramienta excelente que se usa para preparar los datos antes de cargarlos en su destino. Permite crear un esquema del archivo CSV y usar un lenguaje similar a SQL para generar programas de MapReduce que interactúan con los datos.
Los pasos típicos para usar Hive para realizar ETL son los siguientes:
Cargue los datos en Azure Data Lake Store o Azure Blob Storage.
Cree una base de datos de Repositorio de metadatos (con Azure SQL Database) para que la use Hive en el almacenamiento de los esquemas.
Cree un clúster de HDInsight y conecte el almacén de datos.
Defina el esquema para que se aplique en tiempo de lectura en los datos del almacén de datos:
DROP TABLE IF EXISTS hvac; --create the hvac table on comma-separated sensor data stored in Azure Storage blobs CREATE EXTERNAL TABLE hvac(`date` STRING, time STRING, targettemp BIGINT, actualtemp BIGINT, system BIGINT, systemage BIGINT, buildingid BIGINT) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE LOCATION 'wasbs://{container}@{storageaccount}.blob.core.windows.net/HdiSamples/SensorSampleData/hvac/';Transforme los datos y cárguelos en el destino. Hay varias maneras de usar Hive durante la transformación y la carga:
- Consulte y prepare los datos con Hive y guárdelos como CSV en Azure Data Lake Storage o Azure Blob Storage. A continuación, use una herramienta como SQL Server Integration Services (SSIS) para adquirir esos archivos CSV y cargar los datos en una base de datos relacional de destino, como SQL Server.
- Consulte los datos directamente desde Excel o C# utilizando el controlador ODBC de Hive.
- Use Apache Sqoop para leer los archivos CSV planos preparados y cárguelos en la base de datos relacional de destino.
Orígenes de datos
Los orígenes de datos normalmente son datos externos que pueden asociarse a los datos existentes en el almacén de datos, por ejemplo:
- Datos de medios sociales, archivos de registro, sensores y aplicaciones que generan archivos de datos.
- Conjuntos de datos obtenidos de proveedores de datos, como estadísticas de tiempo o cifras de ventas de un proveedor.
- Datos de streaming capturados, filtrados y procesados a través de una herramienta o marco de trabajo adecuados.
Destinos de salida
Puede usar Hive para enviar los datos a destinos diferentes como son:
- Una base de datos relacional, como SQL Server o Azure SQL Database.
- Un almacenamiento de datos, como Azure Synapse Analytics.
- Excel.
- Almacenamiento de tabla y blob de Azure.
- Aplicaciones o servicios que requieren el procesamiento de los datos en formatos específicos o como archivos que contengan tipos específicos de la estructura de información.
- Almacén de documentos JSON como Azure Cosmos DB.
Consideraciones
El modelo ETL se utiliza normalmente cuando quiere:
* Cargar datos de flujo o grandes volúmenes de datos estructurados o semiestructurados desde orígenes externos en una base de datos o un sistema de información existentes.
* Limpiar, transformar y validar los datos antes de cargarlos, quizás usando más de una transformación con el clúster.
* Generar informes y visualizaciones que se actualicen periódicamente. Por ejemplo, si el informe tarda demasiado tiempo en generarse durante el día, puede programarlo para que se ejecute durante la noche. Para ejecutar automáticamente una consulta de Hive, puede usar Azure Logic Apps y PowerShell.
Si el destino de los datos no es una base de datos, puede generar un archivo con el formato adecuado dentro de la consulta, por ejemplo, un CSV. Luego, este archivo se puede importar a Excel o Power BI.
Si necesita ejecutar varias operaciones en los datos como parte del proceso ETL, tenga en cuenta cómo los administra. Con las operaciones controladas por un programa externo, en lugar de como un flujo de trabajo dentro de la solución, decida si algunas operaciones se pueden ejecutar en paralelo. Y para detectar cuándo se completa cada trabajo. Usar un mecanismo de flujo de trabajo como Oozie en Hadoop puede ser más sencillo que intentar crear una secuencia de operaciones mediante scripts externos o programas personalizados.
Pasos siguientes
- ETL at scale (ETL a escala)
Operationalize a data pipeline