Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Apache Phoenix es una base de datos relacional de código abierto y masivamente paralela que se basa en Apache HBase. Phoenix proporciona consultas de tipo SQL a través de HBase. Phoenix usa controladores JDBC para permitir a los usuarios crear, eliminar y modificar índices, vistas, secuencias y tablas SQL, así como realizar operaciones de upsert en filas de forma individual o masiva. Phoenix utiliza la compilación nativa de NoSQL (en lugar de usar MapReduce para compilar consultas) para crear aplicaciones de baja latencia a partir de HBase. Phoenix agrega coprocesadores para admitir la ejecución de código proporcionado por clientes en el espacio de direcciones del servidor, ejecutando el código colocado con los datos. Esto minimiza la transferencia de datos de cliente/servidor. Para trabajar con datos mediante Phoenix en HDInsight, primero debe crear tablas y, después, cargar datos en ellas.
Carga de datos masiva con Apache Phoenix
Hay varias maneras de obtener datos en HBase, incluido el uso de API de cliente, un trabajo MapReduce con TableOutputFormat, o la introducción de datos manualmente con el shell de HBase. Phoenix proporciona dos métodos para cargar datos CSV en tablas de Phoenix: una herramienta de carga de cliente denominada psql y una herramienta de carga masiva basada en MapReduce.
La herramienta psql tiene un subproceso único y es perfecta para cargar megabytes o gigabytes de datos. Todos los archivos CSV que se carguen deben tener la extensión de archivo "csv". También puede especificar archivos de script SQL en la línea de comandos psql con la extensión de archivo "SQL".
La carga masiva con MapReduce se usa para volúmenes de datos mucho más grandes, normalmente en escenarios de producción, ya que usa varios subprocesos.
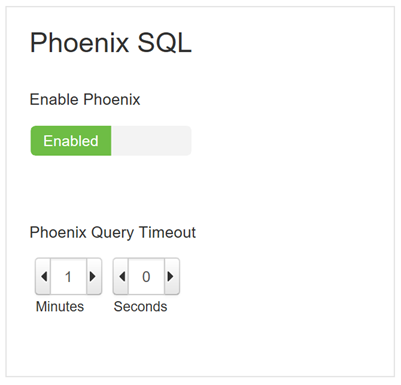
Antes de iniciar la carga de datos, compruebe que Phoenix está habilitado y que la configuración de tiempo de espera de consulta es la prevista. Acceda al panel de Apache Ambari del clúster de HDInsight, seleccione HBase y, después, la pestaña Configuración. Desplácese hacia abajo para comprobar que Apache Phoenix está establecido en enabled tal como se muestra:
Usar psql para cargar tablas de forma masiva
Cree un archivo llamado
createCustomersTable.sqly copie el código siguiente en el archivo. Guarde y cierre el archivo.CREATE TABLE Customers ( ID varchar NOT NULL PRIMARY KEY, Name varchar, Income decimal, Age INTEGER, Country varchar);Cree un archivo llamado
listCustomers.sqly copie el código siguiente en el archivo. Guarde y cierre el archivo.SELECT * from Customers;Cree un archivo llamado
customers.csvy copie el código siguiente en el archivo. Guarde y cierre el archivo.1,Samantha,260000.0,18,US 2,Sam,10000.5,56,US 3,Anton,550150.0,42,NorwayCree un archivo llamado
customers2.csvy copie el código siguiente en el archivo. Guarde y cierre el archivo.4,Nicolle,180000.0,22,US 5,Kate,210000.5,24,Canada 6,Ben,45000.0,32,PolandAbra un símbolo del sistema y cambie el directorio a la ubicación de los archivos recién creados. Reemplace CLUSTERNAME, a continuación, por el nombre real del clúster de HBase. A continuación, ejecute el código para cargar los archivos en el nodo principal del clúster:
scp customers.csv customers2.csv createCustomersTable.sql listCustomers.sql sshuser@CLUSTERNAME-ssh.azurehdinsight.net:/tmpUse el comando SSH para conectarse al clúster. Modifique el comando siguiente: reemplace CLUSTERNAME por el nombre del clúster y, luego, escriba el comando:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netDesde la sesión de SSH, cambie el directorio a la ubicación de la herramienta psql. Ejecute el siguiente comando:
cd /usr/hdp/current/phoenix-client/binCargue los datos de forma masiva. El código siguiente creará la tabla Customers y, a continuación, cargará los datos.
python psql.py /tmp/createCustomersTable.sql /tmp/customers.csvUna vez finalizada la operación
psql, debería ver un mensaje similar al siguiente:csv columns from database. CSV Upsert complete. 3 rows upserted Time: 0.081 sec(s)Puede seguir usando
psqlpara ver el contenido de la tabla Customers. Ejecute el código siguiente:python psql.py /tmp/listCustomers.sqlComo alternativa, puede usar el shell de HBase o Apache Zeppelin para consultar los datos.
Cargue los datos adicionales. Ahora que la tabla ya existe, el comando especifica la tabla. Ejecute el siguiente comando:
python psql.py -t CUSTOMERS /tmp/customers2.csv
Usar MapReduce para cargar tablas de forma masiva
Para las cargas de mayor rendimiento distribuidas en el clúster, use la herramienta de carga de MapReduce. En primer lugar, este cargador convierte todos los datos en HFiles y, después, proporciona los archivos HFiles creados a HBase.
En esta sección se continúa con la sesión de SSH y los objetos creados anteriormente. Cree la tabla Customers y el archivo customers.csv, según sea necesario, siguiendo los pasos descritos anteriormente. Si es necesario, vuelva a establecer la conexión SSH.
Trunque el contenido de la tabla Customers. Ejecute los siguientes comandos en la sesión de SSH abierta:
hbase shell truncate 'CUSTOMERS' exitCopie el archivo
customers.csvdel nodo principal a Azure Storage.hdfs dfs -put /tmp/customers.csv wasbs:///tmp/customers.csvCambie al directorio de ejecución para el comando de carga masiva de MapReduce:
cd /usr/hdp/current/phoenix-clientInicie el cargador de CSV MapReduce con el comando
hadoopcon el archivo JAR del cliente de Phoenix:HADOOP_CLASSPATH=/usr/hdp/current/hbase-client/lib/hbase-protocol.jar:/etc/hbase/conf hadoop jar phoenix-client.jar org.apache.phoenix.mapreduce.CsvBulkLoadTool --table Customers --input /tmp/customers.csvUna vez completada la carga, debería ver un mensaje similar al siguiente:
19/12/18 18:30:57 INFO client.ConnectionManager$HConnectionImplementation: Closing master protocol: MasterService 19/12/18 18:30:57 INFO client.ConnectionManager$HConnectionImplementation: Closing zookeeper sessionid=0x26f15dcceff02c3 19/12/18 18:30:57 INFO zookeeper.ZooKeeper: Session: 0x26f15dcceff02c3 closed 19/12/18 18:30:57 INFO zookeeper.ClientCnxn: EventThread shut down 19/12/18 18:30:57 INFO mapreduce.AbstractBulkLoadTool: Incremental load complete for table=CUSTOMERS 19/12/18 18:30:57 INFO mapreduce.AbstractBulkLoadTool: Removing output directory /tmp/50254426-aba6-400e-88eb-8086d3dddb6Para usar MapReduce con Azure Data Lake Storage, busque el directorio raíz de Data Lake Storage, que es el valor
hbase.rootdirdehbase-site.xml. En el siguiente comando, el directorio raíz de Data Lake Storage esadl://hdinsightconf1.azuredatalakestore.net:443/hbase1. En este comando, especifique las carpetas de entrada y salida de Data Lake Storage como parámetros:cd /usr/hdp/current/phoenix-client $HADOOP_CLASSPATH=$(hbase mapredcp):/etc/hbase/conf hadoop jar /usr/hdp/2.4.2.0-258/phoenix/phoenix-4.4.0.2.4.2.0-258-client.jar org.apache.phoenix.mapreduce.CsvBulkLoadTool --table Customers --input adl://hdinsightconf1.azuredatalakestore.net:443/hbase1/data/hbase/temp/input/customers.csv –zookeeper ZookeeperQuorum:2181:/hbase-unsecure --output adl://hdinsightconf1.azuredatalakestore.net:443/hbase1/data/hbase/output1Para consultar y ver los datos, puede usar psql, como se describió anteriormente. También puede usar el shell de HBase o Apache Zeppelin.
Recomendaciones
Use el mismo medio de almacenamiento, Azure Storage (WASB) o Azure Data Lake Storage (ADL), para las carpetas de entrada y salida. Para transferir datos de Azure Storage a Data Lake Storage, puede usar el comando
distcp:hadoop distcp wasb://@.blob.core.windows.net/example/data/gutenberg adl://.azuredatalakestore.net:443/myfolderUse nodos de trabajo de tamaño grande. Los procesos de asignación de la copia masiva de MapReduce generan grandes cantidades de resultados temporales que llenan el espacio disponible que no es DFS. Para una gran cantidad de carga masiva, use más nodos de trabajo y más grandes. El número de nodos de trabajo que asigne al clúster afecta directamente a la velocidad de procesamiento.
Divida los archivos de entrada en fragmentos de aproximadamente 10 GB. La carga masiva es una operación de almacenamiento intensivo, por lo que dividir los archivos de entrada en varios fragmentos mejora el rendimiento.
Evite puntos de acceso del servidor de región. Si la clave de fila aumenta de forma uniforme, las escrituras secuenciales de HBase pueden inducir puntos de acceso del servidor de región. Cifrar con sal la clave de fila reduce las escrituras secuenciales. Phoenix proporciona una manera de cifrar de forma transparente la clave de fila con un byte cifrado con sal para una determinada tabla, tal como se indica a continuación.
Pasos siguientes
- Bulk Data Loading with Apache Phoenix (Carga de datos masiva con Apache Phoenix)
- Usar Apache Phoenix con clústeres de Apache HBase basados en Linux en HDInsight
- Salted Tables (Tablas cifradas)
- Apache Phoenix Grammar (Gramática de Apache Phoenix)