Inicio rápido: Uso de Apache Zeppelin para ejecutar consultas de Apache Hive en Azure HDInsight
Con este inicio rápido aprenderá a usar Apache Zeppelin para ejecutar consultas de Apache Hive en Azure HDInsight. Los clústeres de HDInsight Interactive Query incluyen cuadernos de Apache Zeppelin con los que puede ejecutar consultas de Hive interactivas.
Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
Requisitos previos
Un clúster de HDInsight Interactive Query. Consulte Creación de un clúster para crear un clúster de HDInsight. Asegúrese de elegir el tipo de clúster Interactive Query.
Creación de una nota de Apache Zeppelin
Reemplace
CLUSTERNAMEpor el nombre del clúster en la siguiente dirección URLhttps://CLUSTERNAME.azurehdinsight.net/zeppelin. Después, escriba la dirección URL en un explorador web.Escriba el nombre de usuario y la contraseña de inicio de sesión del clúster. En la página de Zeppelin, puede crear una nota o abrir notas existentes. HiveSample contiene algunos ejemplos de consultas de Hive.
Seleccione Create new note (Crear una nota).
En el cuadro de diálogo Create new note (Crear una nota), escriba o seleccione los valores siguientes:
- Nombre de la nota: escriba un nombre para la nota.
- Intérprete predeterminado: seleccione JDBC en la lista desplegable.
Seleccione Create Note (Crear nota).
Escriba la siguiente consulta de Hive en la sección de código y, después, presione Mayús + Entrar:
%jdbc(hive) show tables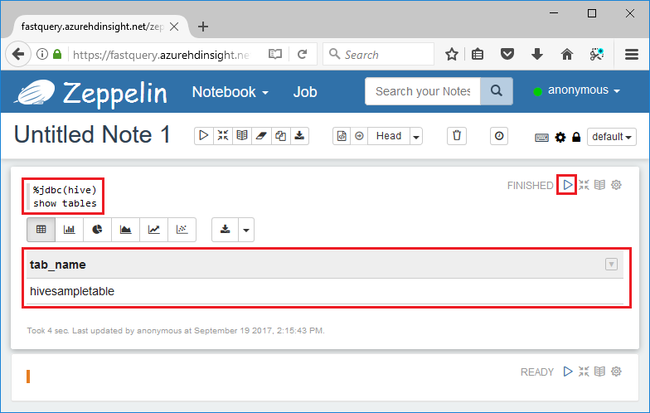
La instrucción %jdbc(hive) en la primera línea indica al bloc de notas que debe usar el intérprete JDBC de Hive.
La consulta devolverá una tabla de Hive denominada hivesampletable.
Aquí se muestran dos consultas adicionales de Hive que se pueden ejecutar en hivesampletable.
%jdbc(hive) select * from hivesampletable limit 10 %jdbc(hive) select ${group_name}, count(*) as total_count from hivesampletable group by ${group_name=market,market|deviceplatform|devicemake} limit ${total_count=10}Comparado con Hive tradicional, los resultados de la consulta se devuelven mucho más rápido.
Ejemplos adicionales
Cree una tabla. Ejecute el código siguiente en el cuaderno de Zeppelin Notebook:
%jdbc(hive) CREATE EXTERNAL TABLE log4jLogs ( t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE;Cargue los datos en la tabla nueva. Ejecute el código siguiente en el cuaderno de Zeppelin Notebook:
%jdbc(hive) LOAD DATA INPATH 'wasbs:///example/data/sample.log' INTO TABLE log4jLogs;Inserte un solo registro. Ejecute el código siguiente en el cuaderno de Zeppelin Notebook:
%jdbc(hive) INSERT INTO TABLE log4jLogs2 VALUES ('A', 'B', 'C', 'D', 'E', 'F', 'G');
Consulte el manual del lenguaje Hive para obtener más ejemplos de sintaxis.
Limpieza de recursos
Después de completar el inicio rápido, puede ser conveniente eliminar el clúster. Con HDInsight, los datos se almacenan en Azure Storage, por lo que puede eliminar un clúster de forma segura cuando no se esté usando. Los clústeres de HDInsight se cobran aunque no se estén usando. Como en muchas ocasiones los cargos por el clúster son mucho más elevados que los cargos por el almacenamiento, desde el punto de vista económico tiene sentido eliminar clústeres cuando no se usen.
Para eliminar un clúster, consulte Eliminación de un clúster de HDInsight con el explorador, PowerShell o la CLI de Azure.
Pasos siguientes
Con este artículo aprenderá a usar Apache Zeppelin para ejecutar consultas de Apache Hive en Azure HDInsight. Para más información sobre las consultas de Hive, el siguiente artículo le mostrará cómo ejecutar consultas con Visual Studio.