Corrección de un error de memoria insuficiente de Apache Hive en Azure HDInsight
Obtenga información acerca de cómo corregir un error de memoria insuficiente de Apache Hive cuando procese tablas de gran tamaño mediante la configuración de memoria de Hive.
Ejecución de una consulta de Apache Hive en tablas de gran tamaño
Un cliente ejecutó una consulta de Hive:
SELECT
COUNT (T1.COLUMN1) as DisplayColumn1,
…
…
….
FROM
TABLE1 T1,
TABLE2 T2,
TABLE3 T3,
TABLE5 T4,
TABLE6 T5,
TABLE7 T6
where (T1.KEY1 = T2.KEY1….
…
…
Algunos matices de esta consulta:
- T1 es un alias para una tabla de gran tamaño, TABLE1, que cuenta con numerosos tipos de columna de CADENA.
- Otras tablas no son tan grandes, pero tienen un gran número de columnas.
- Todas las tablas se unen entre sí, en algunos casos con varias columnas en TABLE1, etc.
La consulta de Hive tardó 26 minutos en completarse en un clúster de HDInsigh A3 de 24 nodos. El cliente ha observado los siguientes mensajes de advertencia:
Warning: Map Join MAPJOIN[428][bigTable=?] in task 'Stage-21:MAPRED' is a cross product
Warning: Shuffle Join JOIN[8][tables = [t1933775, t1932766]] in Stage 'Stage-4:MAPRED' is a cross product
Mediante el motor de ejecución de Apache Tez. La misma consulta se ejecutó durante 15 minutos y se produjo el error siguiente:
Status: Failed
Vertex failed, vertexName=Map 5, vertexId=vertex_1443634917922_0008_1_05, diagnostics=[Task failed, taskId=task_1443634917922_0008_1_05_000006, diagnostics=[TaskAttempt 0 failed, info=[Error: Failure while running task:java.lang.RuntimeException: java.lang.OutOfMemoryError: Java heap space
at
org.apache.hadoop.hive.ql.exec.tez.TezProcessor.initializeAndRunProcessor(TezProcessor.java:172)
at org.apache.hadoop.hive.ql.exec.tez.TezProcessor.run(TezProcessor.java:138)
at
org.apache.tez.runtime.LogicalIOProcessorRuntimeTask.run(LogicalIOProcessorRuntimeTask.java:324)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable$1.run(TezTaskRunner.java:176)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable$1.run(TezTaskRunner.java:168)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable.call(TezTaskRunner.java:168)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable.call(TezTaskRunner.java:163)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Caused by: java.lang.OutOfMemoryError: Java heap space
El error se sigue produciendo cuando se usa una máquina virtual más grande (por ejemplo, D12).
Depuración del error de memoria insuficiente
Nuestros equipos de soporte técnico e ingeniería localizaron uno de los problemas que hicieron que el error de memoria insuficiente fuera un problema conocido descrito en Apache JIRA:
"Si hive.auto.convert.join.noconditionaltask = true comprobamos noconditionaltask.size y si la suma de los tamaños de las tablas de la combinación de asignaciones es inferior a noconditionaltask.size el plan generaría una combinación de asignaciones. El problema con esto es que el cálculo no tiene en cuenta la sobrecarga que introducen las diferentes implementaciones de HashTable como resulta si la suma de los tamaños de entrada es menor que el tamaño de noconditionaltask por consultas con un pequeño margen que alcanzan a OOM."
La propiedad hive.auto.convert.join.noconditionaltask del archivo hive-site.xml se estableció en true:
<property>
<name>hive.auto.convert.join.noconditionaltask</name>
<value>true</value>
<description>
Whether Hive enables the optimization about converting common join into mapjoin based on the input file size.
If this parameter is on, and the sum of size for n-1 of the tables/partitions for a n-way join is smaller than the
specified size, the join is directly converted to a mapjoin (there is no conditional task).
</description>
</property>
Es probable que la combinación de la asignación provocara el error de memoria insuficiente en el montón de Java. Como se explica en la entrada de blog Configuración de memoria de Hadoop Yarn en HDInsight, cuando se usa el motor de ejecución de Tez, el espacio de montón utilizado pertenece en realidad al contenedor de Tez. Consulte la siguiente imagen, que describe la memoria del contenedor de Tez.
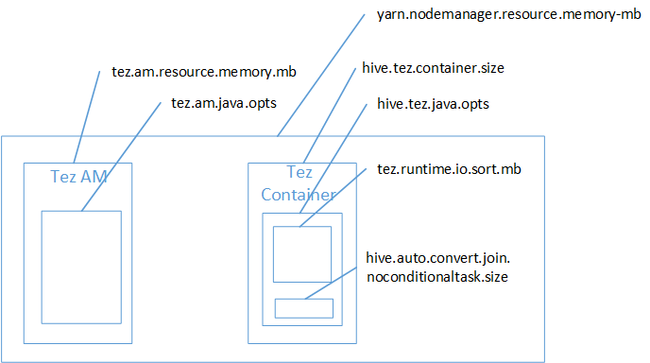
Como sugiere la entrada de blog, los dos valores de configuración de memoria siguientes definen la memoria del contenedor del montón: hive.tez.container.size y hive.tez.java.opts. En nuestra experiencia, la excepción de memoria insuficiente no significa que el tamaño del contenedor sea demasiado pequeño. Significa que el tamaño del montón de Java (hive.tez.java.opts) es demasiado pequeño. Por tanto, siempre que vea memoria insuficiente, puede intentar aumentar hive.tez.java.opts. Si es necesario, es posible que deba aumentar hive.tez.container.size. El valor de java.opts debe ser aproximadamente el 80 % de container.size.
Nota
El valor de hive.tez.java.opts siempre debe ser menor que hive.tez.container.size.
Como una máquina D12 tiene 28 GB de memoria, se optó por usar un tamaño de contenedor de 10 GB (10 240 MB) y asignar el 80 % a java.opts:
SET hive.tez.container.size=10240
SET hive.tez.java.opts=-Xmx8192m
Con estos nuevos valores, la consulta se ejecutó correctamente en menos de 10 minutos.
Pasos siguientes
Recibir un error de memoria insuficiente no significa necesariamente que el tamaño del contenedor sea demasiado pequeño. En su lugar, debe configurar las opciones de memoria para que aumente el tamaño del montón y sea de al menos el 80% del tamaño de memoria del contenedor. Para optimizar las consultas de Hive, consulte Optimizar consultas de Apache Hive para Apache Hadoop en HDInsight.