Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Los mecanismos de replicación de Azure HDInsight se pueden integrar en una arquitectura de solución de alta disponibilidad. En este artículo, se usa un caso práctico ficticio para Contoso Retail para explicar posibles enfoques de recuperación ante desastres de alta disponibilidad, consideraciones sobre los costos y sus diseños correspondientes.
Las recomendaciones de recuperación ante desastres de alta disponibilidad pueden tener muchas permutaciones y combinaciones. Estas soluciones deben llegarse después de deliberar las ventajas y desventajas de cada opción. En este artículo solo se describe una posible solución.
Arquitectura del cliente
En la imagen siguiente se muestra la arquitectura principal de Contoso Retail. La arquitectura consta de una carga de trabajo de streaming, carga de trabajo por lotes, capa de servicio, capa de consumo, capa de almacenamiento y control de versiones.
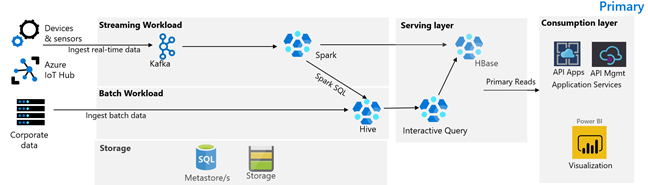
Flujo de trabajo de streaming
Los dispositivos y sensores generan datos en HDInsight Kafka, que constituye el marco de mensajería. Un consumidor de HDInsight Spark lee los tópicos de Kafka. Spark transforma los mensajes entrantes y los escribe en un clúster de HBase de HDInsight en la capa de servicio.
Carga de trabajo por lotes
Un clúster de Hadoop de HDInsight que ejecuta Hive y MapReduce ingiere datos de sistemas transaccionales locales. Los datos sin procesar transformados por Hive y MapReduce se almacenan en tablas de Hive en una partición lógica del lago de datos respaldado por Azure Data Lake Storage Gen2. Los datos almacenados en tablas de Hive también están disponibles para Spark SQL, que realiza transformaciones por lotes antes de almacenar los datos depurados en HBase para su uso.
Capa de servicio
Un clúster de HBase de HDInsight con Apache Phoenix se usa para servir datos a aplicaciones web y paneles de visualización. Un clúster de LLAP de HDInsight se usa para cumplir los requisitos de informes internos.
Capa de consumo
Una capa de Azure API Apps y API Management respalda una página web orientada al público. Power BI cumple los requisitos de informes internos.
Capa de almacenamiento
Azure Data Lake Storage Gen2 con particiones lógicas se usa como lago de datos empresarial. Azure SQL DB respalda los metastores de HDInsight.
Sistema de control de versiones
Un sistema de control de versiones integrado en Azure Pipelines y hospedado fuera de Azure.
Requisitos de continuidad empresarial del cliente
Es importante determinar la funcionalidad empresarial mínima que necesitará si se produce un desastre.
Requisitos de continuidad empresarial de Contoso Retail
- Debemos estar protegidos contra un error regional o un problema de mantenimiento del servicio regional.
- Mis clientes nunca deben ver un error 404. El contenido público siempre debe servirse. (RTO = 0)
- Durante la mayor parte del año, podemos mostrar contenido público con una obsolescencia de cinco horas. (RPO = 5 horas)
- Durante la temporada de vacaciones, nuestro contenido orientado al público siempre debe estar actualizado. (RPO = 0)
- Mis requisitos de informes internos no se consideran críticos para la continuidad empresarial.
- Optimice los costos de continuidad empresarial.
Solución propuesta
En la imagen siguiente se muestra la arquitectura de recuperación ante desastres de alta disponibilidad de Contoso Retail.
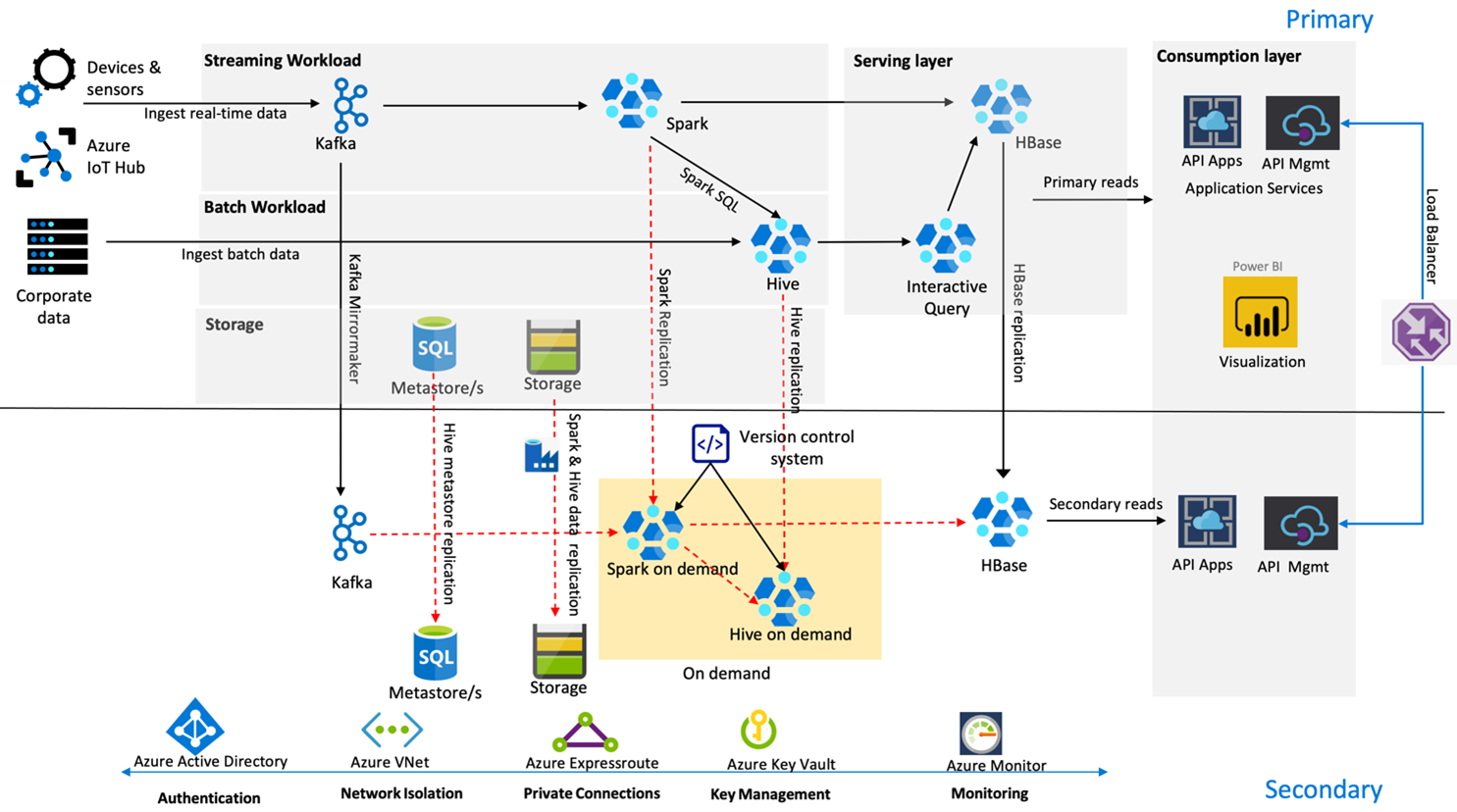
Kafka usa la replicación activa: pasiva para reflejar temas de Kafka desde la región primaria a la región secundaria. Una alternativa a la replicación de Kafka podría ser realizar la producción en Kafka en ambas regiones.
Hive y Spark usan modelos de replicación principal activa: secundaria a petición durante los tiempos normales. El proceso de replicación de Hive se ejecuta periódicamente y acompaña al metastore de Hive Azure SQL y a la replicación de la cuenta de almacenamiento de Hive. La cuenta de almacenamiento de Spark se replica periódicamente mediante ADF DistCP. La naturaleza transitoria de estos clústeres ayuda a optimizar los costos. Las replicaciones se programan cada cuatro horas para lograr un RPO que queda claramente por debajo del requisito de cinco horas.
La replicación de HBase usa el modelo Leader – Follower durante los tiempos normales para asegurarse de que los datos siempre se sirven independientemente de la región y el RPO sea muy bajo.
Si hay un error regional en la región primaria, la página web y el contenido del back-end se sirven desde la región secundaria durante cinco horas con cierto grado de obsolescencia. Si el panel de estado del servicio de Azure no indica un ETA de recuperación en la ventana de cinco horas, Contoso Retail creará la capa de transformación Hive y Spark en la región secundaria y, a continuación, apuntará todos los orígenes de datos ascendentes a la región secundaria. El hecho de convertir la región secundaria en grabable causaría un proceso de conmutación por recuperación que implicaría la replicación en la región primaria.
Durante una temporada de compras máxima, toda la canalización secundaria siempre está activa y en ejecución. Los productores de Kafka realizan su tarea en ambas regiones, y la replicación de HBase pasa del modelo líder-líder al modelo líder-seguidor para garantizar que el contenido de acceso público esté siempre actualizado.
No es necesario diseñar una solución de conmutación por error para la creación de informes internos, ya que no es algo crítico para la continuidad empresarial.
Pasos siguientes
Para más información sobre los elementos que se describen en este artículo, consulte: