Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Con el fin de proporcionarle niveles óptimos de disponibilidad para los componentes de análisis, HDInsight se desarrolló con una arquitectura única que garantiza la alta disponibilidad (HA) de los servicios críticos. Microsoft desarrolló algunos componentes de esta arquitectura para proporcionar conmutación automática por error. Otros son componentes de Apache estándar que se implementan para la compatibilidad con servicios específicos. En este artículo se explica la arquitectura del modelo de servicio de alta disponibilidad en HDInsight, el modo en que HDInsight admite la conmutación por error de los servicios de alta disponibilidad y los procedimientos recomendados para recuperarse de otras interrupciones del servicio.
Nota
Este artículo contiene referencias al término esclavo, un término que Microsoft ya no usa. Cuando se elimine el término del software, se eliminará también de este artículo.
Infraestructura de alta disponibilidad
HDInsight proporciona una infraestructura personalizada para garantizar que los cuatro servicios principales sean de alta disponibilidad con funcionalidades de conmutación automática por error:
- Servidor Apache Ambari
- Servidor de Escala de tiempo de la aplicación para Apache YARN
- Servidor de Historial de trabajos para MapReduce de Hadoop
- Apache Livy
Esta infraestructura consta de muchos servicios y componentes de software, algunos de los cuales están diseñados por Microsoft. Los siguientes componentes son exclusivos de la plataforma HDInsight:
- Controlador de conmutación por error subordinado
- Controlador de conmutación por error maestro
- Servicio de alta disponibilidad subordinado
- Servicio de alta disponibilidad maestro
También hay otros servicios de alta disponibilidad, que son compatibles con los componentes de confiabilidad de Apache de código abierto. Estos componentes también están presentes en los clústeres de HDInsight:
- Hadoop File System (HDFS) NameNode
- YARN ResourceManager
- HBase Master
En las secciones siguientes se proporciona más información sobre cómo funcionan juntos estos servicios.
Servicios de alta disponibilidad de HDInsight
Microsoft ofrece compatibilidad con los cuatro servicios de Apache de la tabla siguiente en los clústeres de HDInsight. Para distinguirlos de los servicios de alta disponibilidad que admiten los componentes de Apache, se denominan servicios de alta disponibilidad de HDInsight.
| Servicio | Nodos de clúster | Tipos de clúster | Propósito |
|---|---|---|---|
| Servidor Apache Ambari | Nodo principal activo | All | Supervisa y administra el clúster. |
| Servidor de Escala de tiempo de la aplicación para Apache YARN | Nodo principal activo | Todos excepto Kafka | Mantiene información de depuración sobre los trabajos de YARN que se ejecutan en el clúster. |
| Servidor de Historial de trabajos para MapReduce de Hadoop | Nodo principal activo | Todos excepto Kafka | Mantiene datos de depuración de los trabajos de MapReduce. |
| Apache Livy | Nodo principal activo | Spark | Permite una interacción sencilla con un clúster de Spark a través de una interfaz REST. |
Nota:
Actualmente, los clústeres de Enterprise Security Package (ESP) de HDInsight solo proporcionan la alta disponibilidad del servidor de Ambari. El servidor de escala de tiempo de la aplicación, el servidor del historial de trabajos y Livy se ejecutan solo en headnode0 y no conmutan por error a headnode1 cuando se produce la conmutación por error de Ambari. La base de datos de escala de tiempo de la aplicación también se encuentra en headnode0 y no en SQL Server para Ambari.
Architecture
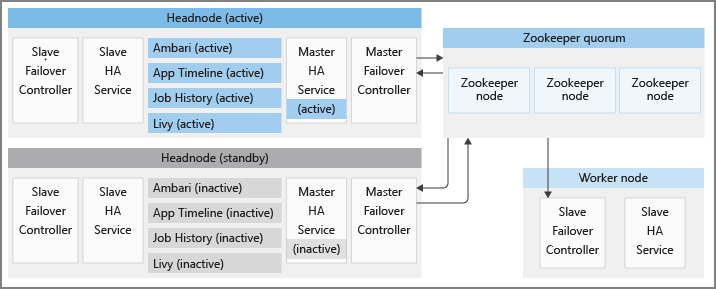
Cada clúster de HDInsight tiene dos nodos principales en los modos activo y en espera, respectivamente. Los servicios de alta disponibilidad de HDInsight solo se ejecutan en nodos principales. Estos servicios se deben ejecutar siempre en el nodo principal activo y detenerse y ponerse en modo de mantenimiento en el nodo principal en espera.
Para mantener los estados correctos de los servicios de alta disponibilidad y proporcionar una conmutación por error rápida, HDInsight emplea Apache ZooKeeper, que es un servicio de coordinación para aplicaciones distribuidas empleado para realizar la elección del nodo principal activo. HDInsight también aprovisiona algunos procesos de Java en segundo plano, que coordinan el procedimiento de conmutación por error de los servicios de alta disponibilidad de HDInsight. Estos servicios son: el controlador de conmutación por error maestro, el Controlador de conmutación por error subordinado, master-ha-service y slave-ha-service.
Apache ZooKeeper
Apache ZooKeeper es un servicio de coordinación de alto rendimiento para aplicaciones distribuidas. En producción, ZooKeeper normalmente se ejecuta en modo replicado, donde un grupo replicado de servidor ZooKeeper forma un cuórum. Cada clúster de HDInsight tiene tres nodos de ZooKeeper que permiten que tres servidores ZooKeeper formen un cuórum. HDInsight tiene dos cuórums de ZooKeeper que se ejecutan en paralelo con respecto al otro. Un cuórum decide el nodo principal activo de un clúster en el que se deben ejecutar los servicios de alta disponibilidad de HDInsight. Otro cuórum se usa para coordinar los servicios de alta disponibilidad proporcionados por Apache, tal como se detalla en secciones posteriores.
Controlador de conmutación por error subordinado
El Controlador de conmutación por error subordinado se ejecuta en todos los nodos de un clúster de HDInsight. Este controlador es responsable de iniciar el agente de Ambari y el servicio slave-ha-service en cada nodo. Periódicamente, consulta el primer cuórum ZooKeeper para conocer el nodo principal activo. Cuando los nodos principales activo y en espera cambian, el Controlador de conmutación por error subordinado realiza los pasos siguientes:
- Actualiza el archivo de configuración del host.
- Reinicia el agente Ambari.
slave-ha-service es responsable de detener los servicios de alta disponibilidad de HDInsight (excepto el servidor Ambari) en el nodo principal en espera.
Controlador de conmutación por error maestro
Un controlador de conmutación por error maestro se ejecuta en ambos nodos principales. Ambos controladores de conmutación por error maestros se comunican con el primer cuórum de ZooKeeper para designar el nodo principal en el que se van a ejecutar como nodo principal activo.
Por ejemplo, si el controlador de conmutación por error maestro del nodo principal 0 gana la elección, tienen lugar los siguientes cambios:
- El nodo principal 0 se activa.
- El controlador de conmutación por error maestro inicia el servidor Ambari y el servicio master-ha-service en el nodo principal 0.
- El otro controlador de conmutación por error maestro detiene el servidor Ambari y el servicio master-ha-service en el nodo principal 1.
El componente master-ha-service solo se ejecuta en el nodo principal activo, detiene los servicios de alta disponibilidad de HDInsight (excepto el servidor Ambari) en el nodo principal en espera y los inicia en el nodo principal activo.
Proceso de conmutación por error
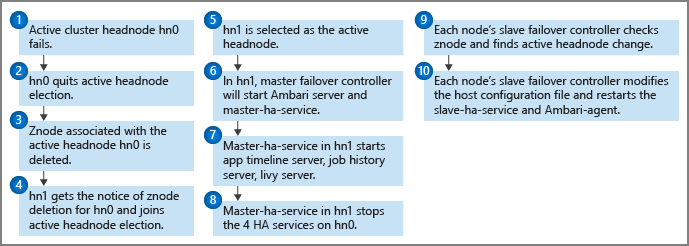
En cada nodo principal se ejecuta un monitor de estado junto con el controlador de conmutación por error maestro para enviar notificaciones de latido al cuórum de Zookeeper. En este escenario, el nodo principal se considera un servicio de alta disponibilidad. El monitor de estado comprueba si cada servicio de alta disponibilidad está en buen estado y si está listo para unirse a la elección del liderazgo. En caso afirmativo, este nodo principal compite en la elección. Si no, sale de la elección hasta que vuelva a estar listo.
Si el nodo principal en espera alcanza el liderazgo y se vuelve activo (por ejemplo, en el caso de que se produzca un error con el nodo activo anterior), su controlador de conmutación por error maestro inicia en él todos los servicios de alta disponibilidad de HDInsight. El controlador de conmutación por error maestro también detiene estos servicios en el otro nodo principal.
En el caso de errores del servicio de alta disponibilidad de HDInsight, por ejemplo, que un servicio esté inactivo o en mal estado, el controlador de conmutación por error maestro debe reiniciar o detener los servicios de forma automática según el estado del nodo principal. Los usuarios no deben iniciar manualmente los servicios de alta disponibilidad de HDInsight en ambos nodos principales. En su lugar, permita la conmutación por error automática o manual para la recuperación del servicio.
Intervención manual involuntaria
Los servicios de alta disponibilidad de HDInsight solo deben ejecutarse en el nodo principal activo y se reiniciarán automáticamente cuando sea necesario. Dado que los servicios de alta disponibilidad no tienen su propio monitor de estado de forma individual, la conmutación por error no se puede desencadenar en el nivel del servicio individual. La conmutación por error se garantiza en el nivel de nodo y no en el nivel de servicio.
Algunos problemas conocidos
Cuando se inicia manualmente un servicio de alta disponibilidad en el nodo principal en espera, no se detendrá hasta que se produzca la siguiente conmutación por error. Cuando los servicios de alta disponibilidad se ejecutan en ambos nodos principales, algunos posibles problemas son: No se puede acceder a la interfaz de usuario de Ambari, Ambari produce errores y los trabajos de YARN, Spark y Oozie podrían bloquearse.
Cuando se detiene un servicio de alta disponibilidad en el nodo principal activo, no se reiniciará hasta que se produzca la siguiente conmutación por error o se reinicie el controlador de conmutación por error maestro o el servicio master-ha-service. Cuando uno o varios servicios de alta disponibilidad se detienen en el nodo principal activo, especialmente cuando se detiene el servidor Ambari, no se puede acceder a la interfaz de usuario de Ambari; otros posibles problemas son errores en los trabajos de YARN, Spark y Oozie.
Servicios de alta disponibilidad de Apache
Apache proporciona alta disponibilidad para HDFS NameNode, YARN ResourceManager y HBase Master, que también están disponibles en clústeres de HDInsight. A diferencia de los servicios de alta disponibilidad de HDInsight, se admiten en clústeres ESP. Los servicios de la alta disponibilidad de Apache se comunican con el segundo cuórum de ZooKeeper (descrito en la sección anterior) para elegir los estados activo o en espera y realizar la conmutación automática por error. En las secciones siguientes se detalla cómo funcionan estos servicios.
Hadoop Distributed File System (HDFS) NameNode
Los clústeres de HDInsight basados en Apache Hadoop 2.0 o superior proporcionan alta disponibilidad de NameNode. Hay dos instancias de NameNode que se ejecutan en los nodos principales, que están configuradas para la conmutación automática por error. Estas instancias usan ZKFailoverController para comunicarse con Zookeeper y elegir el estado activo o en espera. ZKFailoverController se ejecuta en ambos nodos principales y funciona de la misma manera que el controlador de conmutación por error maestro.
El segundo cuórum de Zookeeper es independiente del primero, por lo que es posible que la instancia de NameNode activa no se ejecute en el nodo principal activo. Cuando la instancia de NameNode activa está inactiva o en mal estado, la instancia de NameNode en espera gana la elección y pasa a estar activa.
YARN ResourceManager
Los clústeres de HDInsight basados en Apache Hadoop 2.4 o superior admiten la alta disponibilidad de YARN ResourceManager. Hay dos instancias de ResourceManager, rm1 y rm2, que se ejecutan en los nodos principales 0 y 1, respectivamente. Al igual que NameNode, YARN ResourceManager también está configurado para la conmutación automática por error. Otra instancia de ResourceManager se elige automáticamente como activa cuando la instancia actual de ResourceManager está inactiva o no responde.
YARN ResourceManager usa su elemento ActiveStandbyElector insertado como detector de errores y elector del líder. A diferencia de HDFS NameNode, YARN ResourceManager no necesita un demonio de ZKFC independiente. La instancia de ResourceManager activa escribe sus estados en Apache Zookeeper.
La alta disponibilidad de YARN ResourceManager es independiente de NameNode y de otros servicios de alta disponibilidad de HDInsight. Es posible que la instancia de ResourceManager activa no se ejecute en el nodo principal activo ni en el nodo principal en el que se ejecuta la instancia de NameNode activa. Para más información sobre la alta disponibilidad de YARN ResourceManager, consulte Alta disponibilidad de ResourceManager.
HBase Master
Los clústeres de HBase de HDInsight admiten alta disponibilidad de HBase Master. A diferencia de otros servicios de alta disponibilidad, que se ejecutan en nodos principales, HBase Master se ejecuta en los tres nodos de Zookeeper, donde uno de ellos es el maestro activo y los otros dos están en espera. Al igual que NameNode, HBase Master se coordina con Apache Zookeeper para la elección del líder y realiza la conmutación automática por error cuando el maestro activo actual tiene problemas. Solo hay una instancia de HBase Master activa en cualquier momento.