Administración de registros de un clúster de HDInsight
Un clúster de HDInsight produce varios archivos de registro. Por ejemplo, Apache Hadoop y los servicios relacionados, como Apache Spark, producen registros detallados de ejecución de trabajo. La administración de archivos de registro forma parte del mantenimiento de un clúster de HDInsight en buen estado. También puede haber requisitos legales para el archivado de registros. Debido al número y tamaño de los archivos de registro, la optimización del almacenamiento de registro y el archivado sirven de ayuda con la administración de costos de servicio.
La administración de registros de clúster de HDInsight incluye la retención de información sobre todos los aspectos del entorno del clúster. Esta información incluye todos los registros asociados del servicio de Azure, la configuración del clúster, la información de ejecución de trabajo, los estados de error y otros datos, según sea necesario.
A continuación, se indican los pasos habituales de administración de registros de HDInsight:
- Paso 1: Determinar las directivas de retención de registros
- Paso 2: Administrar los registros de configuración de las versiones del servicio de clúster
- Paso 3: Administrar los archivos de registro de ejecución de trabajo del clúster
- Paso 4: Prever los costos y tamaños de almacenamiento del volumen de registros
- Paso 5: Determinar las directivas y procesos del archivo de registro
Paso 1: Determinar las directivas de retención de registros
El primer paso para crear una estrategia de administración de registros de clúster de HDInsight consiste en recopilar información acerca de escenarios empresariales y los requisitos de almacenamiento del historial de ejecución de trabajos.
Detalles del clúster
Los siguientes detalles del clúster son útiles para ayudar a recopilar información en su estrategia de administración de registros. Recopile dicha información a partir de todos los clústeres de HDInsight que ha creado en una cuenta de Azure determinada.
- Nombre del clúster
- Región del clúster y zona de disponibilidad de Azure
- Estado del clúster, incluidos los detalles del último cambio de estado
- Tipo y número de instancias de HDInsight especificados para los nodos maestro, principal y de tarea
Puede obtener la mayor parte de esta información de nivel superior mediante Azure Portal. Como alternativa, puede utilizar la CLI de Azure para obtener información acerca de los clústeres de HDInsight:
az hdinsight list --resource-group <ResourceGroup>
az hdinsight show --resource-group <ResourceGroup> --name <ClusterName>
También puede usar PowerShell para ver esta información. Para más información, consulte Administración de clústeres de Apache Hadoop en HDInsight mediante Azure PowerShell.
Comprender las cargas de trabajo que se ejecutan en los clústeres
Es importante entender los tipos de cargas de trabajo que se ejecutan en los clústeres de HDInsight para diseñar estrategias adecuadas de registro para cada tipo.
- ¿Las cargas de trabajo son experimentales (por ejemplo, de desarrollo o de prueba) o de calidad de producción?
- ¿Con qué frecuencia se ejecutan normalmente las cargas de trabajo de calidad de producción?
- ¿Alguna de las cargas de trabajo realiza un uso intensivo de recursos o es de larga ejecución?
- ¿Alguna de las cargas de trabajo usa un conjunto complejo de servicios de Hadoop para el que se producen varios tipos de registros?
- ¿Alguna de las cargas de trabajo tiene asociados requisitos legales de linaje de ejecución?
Procedimientos y patrones de retención de registros de ejemplo
Considere la posibilidad de mantener el seguimiento del linaje de los datos mediante la adición de un identificador a cada entrada de registro o a través de otras técnicas. Esto le permite realizar el seguimiento del origen inicial de los datos y la operación, así como seguir los datos a través de cada fase para comprender su coherencia y validez.
Tenga en cuenta cómo puede recopilar registros del clúster, o de varios clústeres, e intercálelos para fines tales como la auditoría, la supervisión, el planeamiento y las alertas. Puede usar una solución personalizada para tener acceso a los archivos de registro, y descargarlos, de forma regular, y combinarlos y analizarlos para proporcionar una pantalla de panel. También puede agregar otras funcionalidades para las alertas de seguridad o detección de errores. Puede compilar estas utilidades mediante PowerShell, los SDK de HDInsight o el código que tiene acceso al modelo de implementación clásica de Azure.
Considere si una solución o un servicio de supervisión sería una ventaja útil. Microsoft System Center proporciona un paquete de administración de HDInsight. También puede usar herramientas de terceros, como Apache Chukwa y Ganglia, para recopilar y centralizar los registros. Muchas compañías ofrecen servicios para supervisar soluciones de macrodatos basadas en Hadoop, por ejemplo:
Centerity, Compuware APM, Sematext SPM y Zettaset Orchestrator.
Paso 2: Administración de versiones de servicio del clúster y visualización de registros
Un clúster típico de HDInsight utiliza varios servicios y paquetes de software de código abierto (por ejemplo, Apache HBase, Apache Spark, etc.). Para algunas cargas de trabajo, como bioinformática, es posible que deba conservar el historial de registro de configuración del servicio, además de los registros de ejecución de trabajo.
Ver las opciones de configuración del clúster con la UI de Ambari
Apache Ambari simplifica la administración, la configuración y la supervisión de un clúster de HDInsight al proporcionar una API de REST y una interfaz de usuario web. Ambari se incluye en los clústeres de HDInsight basados en Linux. Seleccione Panel de clúster en la página de HDInsight de Azure Portal para abrir la página del vínculo Paneles de clúster. A continuación, seleccione el panel de clúster de HDInsight para abrir la UI de Ambari. Se le solicitarán las credenciales de inicio de sesión del clúster.
Para abrir una lista de vistas de servicio, seleccione el panel de vistas de Ambari en la página de Azure Portal para HDInsight. Esta lista varía en función de qué bibliotecas haya instalado. Por ejemplo, puede ver YARN Queue Manager, Hive View y Tez View. Seleccione cualquier vínculo de servicio para ver información sobre la configuración y el servicio. La página de pila y la versión de la UI de Ambari proporciona información sobre la configuración de los servicios de clúster y el historial de versiones del servicio. Para navegar a esta sección de la UI de Ambari, seleccione el menú Administración y, a continuación, Stacks and Versions (Pilas y versiones). Seleccione la pestaña Versiones para ver la información de la versión del servicio.
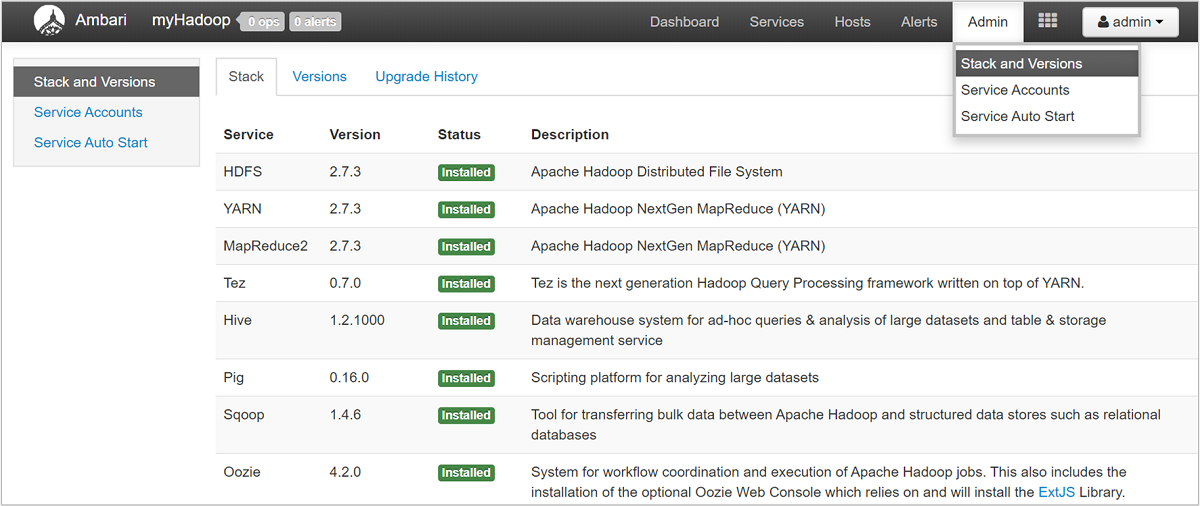
Con la UI de Ambari, puede descargar la configuración de cualquier servicio (o de todos) que se ejecute en un host determinado (o nodo) del clúster. Seleccione el menú Hosts y, a continuación, el vínculo para el host de interés. En la página de dicho host, seleccione el botón Acciones del host y, a continuación, Descargar configuraciones de cliente.
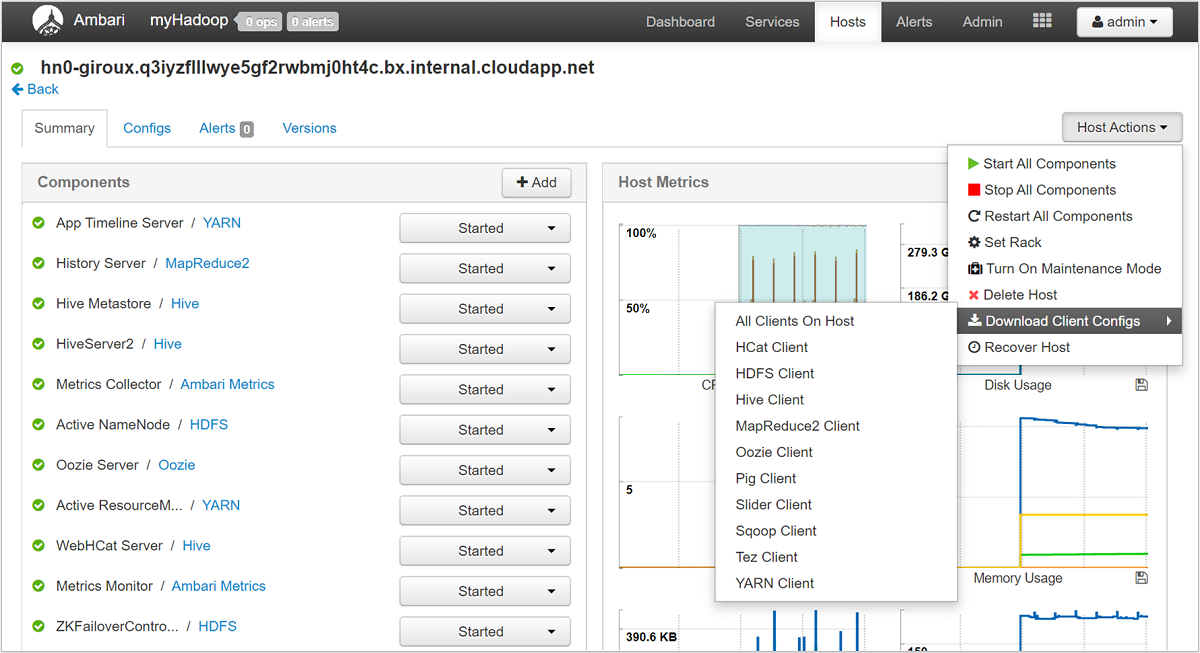
Ver los registros de acciones de script
Las acciones de script de HDInsight ejecutan scripts en un clúster, ya sea manualmente o cuando se especifique. Por ejemplo, las acciones de script pueden utilizarse para instalar otro software en el clúster o para modificar las opciones de configuración de los valores predeterminados. Los registros de acciones de script pueden proporcionar información sobre los errores que se produjeron durante la instalación del clúster, así como sobre los cambios de las opciones de configuración que podrían afectar a la disponibilidad y al rendimiento del clúster. Para ver el estado de una acción de script, seleccione el botón Operaciones en la UI de Ambari o acceda a los registros del estado de la cuenta de almacenamiento predeterminada. Los registros de almacenamiento están disponibles en /STORAGE_ACCOUNT_NAME/DEFAULT_CONTAINER_NAME/custom-scriptaction-logs/CLUSTER_NAME/DATE.
Visualización de los registros de estado de alertas de Ambari
Apache Ambari escribe cambios de estado de alerta en ambari-alerts.log. La ruta de acceso completa es /var/log/ambari-server/ambari-alerts.log. Para permitir la depuración del registro, cambie una propiedad en /etc/ambari-server/conf/log4j.properties. Luego, cambie la entrada que aparece en # Log alert state changes de:
log4j.logger.alerts=INFO,alerts
to
log4j.logger.alerts=DEBUG,alerts
Paso 3: Administrar los archivos de registro de ejecución de trabajo del clúster
El paso siguiente es revisar los archivos de registro de ejecución de trabajo de los distintos servicios. Estos servicios podrían incluir Apache HBase, Apache Spark y muchos más. Un clúster de Hadoop genera un gran número de registros detallados, por lo que determinar qué registros son útiles (y cuáles no) puede llevar mucho tiempo. Comprender el sistema de registro es importante para la administración dirigida de archivos de registro. La imagen siguiente es un archivo de registro de ejemplo.

Acceso a los archivos de registro de Hadoop
HDInsight almacena los archivos de registro en el sistema de archivos del clúster y en Azure Storage. Para examinar los archivos de registro del clúster, puede abrir una conexión SSH para el clúster y examinar el sistema de archivos, o bien usar el portal de estado de Hadoop YARN en el servidor remoto del nodo principal. Puede examinar los archivos de registro en Azure Storage mediante cualquiera de las herramientas que pueden acceder a los datos de Azure Storage y descargarlos. Algunos ejemplos son AZCopy, CloudXplorer y el Explorador de servidores de Visual Studio. También puede usar las bibliotecas de cliente de Azure Storage y PowerShell, o bien los SDK de Azure .NET, para tener acceso a los datos de Azure Blob Storage.
Hadoop ejecuta la labor de los trabajos como intentos de tareas en varios nodos del clúster. HDInsight puede iniciar intentos de tareas especulativas, lo que finaliza cualquier otro intento de tarea que no se complete primero. Esto genera una actividad significativa que se registra en el controlador, en stderr y en los archivos de registro de Syslog sobre la marcha. Además, varios intentos de tareas se ejecutan simultáneamente, pero un archivo de registro solo puede mostrar los resultados de forma lineal.
Registros de HDInsight escritos en Azure Blob Storage
Los clústeres de HDInsight se configuran para escribir registros de tareas en una cuenta de Azure Blob Storage para cualquier trabajo que se envíe mediante los cmdlets de Azure PowerShell o las API de envío de trabajos de .NET. Si envía los trabajos a través de SSH para el clúster, la información de registro de ejecución se almacena en las tablas de Azure según se describe en la sección anterior.
Además de los archivos de registro básico generados por HDInsight, los servicios instalados, como YARN, también generan archivos de registro de ejecución de trabajo. El número y tipo de archivos de registro depende de los servicios instalados. Algunos servicios habituales son Apache HBase, Apache Spark, etc. Investigue los archivos de ejecución de registro de trabajo para que cada servicio entienda los archivos de registro generales disponibles en el clúster. Cada servicio tiene sus propios y únicos métodos de registro y ubicaciones para almacenar archivos de registro. A modo de ejemplo, los detalles para acceder a los archivos de registro de servicio más comunes (de YARN) se examinan en la sección siguiente.
Registros de HDInsight generados por YARN
YARN agrega los registros en todos los contenedores de un nodo de trabajo y los almacena como un archivo de registros agregados por cada nodo de trabajo. Dicho registro se almacena en el sistema de archivos de forma predeterminada una vez finalizada una aplicación. Su aplicación puede usar cientos o miles de contenedores, pero los registros para todos los contenedores que se ejecutan en un único nodo de trabajo se agregarán siempre a un único archivo. Solo hay un registro por nodo de trabajo usado por la aplicación. La agregación de registros está habilitada de forma predeterminada en los clústeres de HDInsight de la versión 3.0 y superior. Los registros agregados se encuentran en el almacenamiento predeterminado del clúster.
/app-logs/<user>/logs/<applicationId>
Los registros agregados no son legibles directamente, ya que se escriben en TFile, un formato binario indexado por contenedor. Use los registros de ResourceManager de YARN o las herramientas de la CLI para ver estos registros como texto sin formato para aplicaciones o contenedores de interés.
Herramientas de la CLI de YARN
Para poder usar las herramientas de la CLI de YARN, tiene que conectarse primero al clúster de HDInsight mediante SSH. Especifique la información de <applicationId>, <user-who-started-the-application>, <containerId> y <worker-node-address> al ejecutar estos comandos. Puede ver los registros como texto sin formato con uno de los siguientes comandos:
yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application>
yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application> -containerId <containerId> -nodeAddress <worker-node-address>
Interfaz de usuario de Resource Manager de YARN
La interfaz de usuario de YARN Resource Manager se ejecuta en el nodo principal del clúster y puede tener acceso a ella mediante la UI web de Ambari. Para ver los registros de YARN, use los siguientes pasos:
- En un explorador web, vaya a
https://CLUSTERNAME.azurehdinsight.net. Reemplace CLUSTERNAME por el nombre del clúster de HDInsight. - En la lista de servicios de la izquierda de la página, seleccione YARN.
- En la lista desplegable Vínculos rápidos, seleccione uno de los nodos principales del clúster y, a continuación, Registros de ResourceManager. Aparece una lista de vínculos a los registros de YARN.
Paso 4: Prever los costos y tamaños de almacenamiento del volumen de registros
Tras completar los pasos anteriores, comprenderá los tipos y volúmenes de los archivos de registro que generan los clústeres de HDInsight.
A continuación, analice el volumen de datos de registro en ubicaciones clave de almacenamiento de registro durante un período de tiempo. Por ejemplo, puede analizar el volumen y el crecimiento durante períodos de 30, 60 o 90 días. Registre esta información en una hoja de cálculo o use otras herramientas, como Visual Studio, el Explorador de Azure Storage o Power Query para Excel. ```
Ahora tiene información suficiente para crear una estrategia de administración de registros para los registros clave. Utilice la hoja de cálculo (o la herramienta que prefiera) para pronosticar el crecimiento del tamaño del registro y los costos de servicio de Azure de almacenamiento de registros en el futuro. También debe tener en cuenta los requisitos de retención de registros para el conjunto de registros que está examinando. Ahora, puede volver a prever los futuros costos de almacenamiento de registros después de determinar qué archivos de registro pueden eliminarse (si los hubiera) y qué registros se deberían conservar y archivar en una instancia de Azure Storage más económica.
Paso 5: Determinar las directivas y procesos del archivo de registro
Después de determinar qué archivos de registro se pueden eliminar, puede ajustar los parámetros de registro en muchos servicios de Hadoop para eliminar automáticamente los archivos de registro tras un período de tiempo específico.
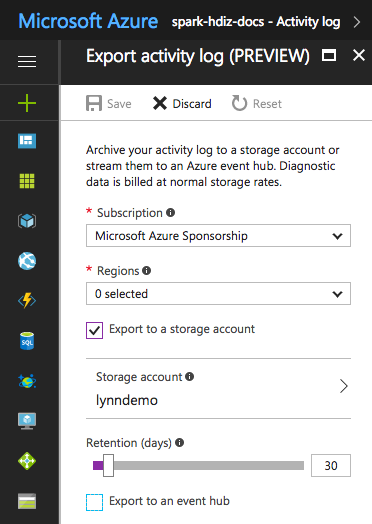
Para determinados archivos de registro, puede usar un enfoque de archivado de archivos de registro más económico. Para los registros de actividad de Azure Resource Manager, puede analizar este enfoque con Azure Portal. Configure el archivado de los registros de Resource Manager mediante la selección del vínculo Registro de actividad en Azure Portal para la instancia de HDInsight. En la parte superior de la página de búsqueda de Registro de actividad, seleccione el elemento de menú Exportar para abrir el panel Exportar registro de actividad. Rellene la suscripción, la región, si desea exportar a una cuenta de almacenamiento y durante cuántos días se deben conservar los registros. En este mismo panel, también puede indicar si desea exportar a un centro de eventos.
Como alternativa, puede crear scripts de archivado de registros con PowerShell.
Acceso a las métricas de Azure Storage
Azure Storage puede configurarse para registrar operaciones de almacenamiento y acceso. Puede usar estos registros detallados para la supervisión y planeamiento de capacidades, así como para las solicitudes de auditoría de almacenamiento. La información registrada incluye detalles de latencia, lo que le permite supervisar y ajustar el rendimiento de las soluciones. Puede usar el SDK de .NET para Hadoop para examinar los archivos de registro generados para la instancia de Azure Storage que contiene los datos de un clúster de HDInsight.
Control del tamaño y del número de índices de copia de seguridad de los archivos de registro antiguos
Para controlar el tamaño y el número de archivos de registro que se conservan, establezca las siguientes propiedades de RollingFileAppender:
maxFileSizees el tamaño crítico del archivo, en el cual se revierte el archivo. El valor predeterminado es de 10 MB.maxBackupIndexespecifica el número de archivos de copia de seguridad que se van a crear; el valor predeterminado es 1.
Otras técnicas de administración de registros
Para evitar quedarse sin espacio en disco, puede usar algunas herramientas del sistema operativo, como logrotate, para administrar el control de los archivos de registro. Puede configurar logrotate para que se ejecute a diario, y comprima los archivos de registro y quite los antiguos. El enfoque depende de los requisitos, como cuánto tiempo mantener los archivos de registro en los nodos locales.
También puede comprobar si el registro de depuración está habilitado para uno o varios servicios, lo que aumenta en gran medida el tamaño del registro de salida.
Para recopilar los registros de todos los nodos en una ubicación central, puede crear un flujo de datos, como la introducción de todas las entradas de registro en Solr.