Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
HDInsight proporciona elasticidad con opciones para escalar y reducir verticalmente el número de nodos de trabajo de los clústeres. Esta elasticidad permite reducir un clúster una vez finalizada la jornada laboral o durante los fines de semana. También permite expandirlo durante períodos de máxima demanda empresarial.
Escale verticalmente el clúster antes del procesamiento por lotes periódico para que el clúster tenga los recursos adecuados. Una vez completado el procesamiento y reducido el uso, reduzca verticalmente el clúster de HDInsight a menos nodos de trabajo.
Es posible escalar un clúster manualmente con uno de los métodos siguientes. También puede usar opciones de escalabilidad automática para escalar y reducir verticalmente de forma automática como respuesta a determinadas métricas.
Nota
Solo son compatibles los clústeres con la versión 3.1.3 de HDInsight, o superior. Si no está seguro de la versión del clúster, puede comprobar la página de propiedades.
Utilidades para escalar clústeres
Microsoft proporciona las siguientes utilidades para escalar clústeres:
| Utilidad | Descripción |
|---|---|
| PowerShell Az |
Set-AzHDInsightClusterSize
-ClusterName CLUSTERNAME -TargetInstanceCount NEWSIZE
|
| CLI de Azure |
az hdinsight resize
--resource-group RESOURCEGROUP --name CLUSTERNAME --workernode-count NEWSIZE
|
| CLI de Azure clásica | azure hdinsight cluster resize CLUSTERNAME NEWSIZE |
| Azure Portal | Abra el panel del clúster de HDInsight, seleccione Tamaño de clúster en el menú izquierdo y, luego, en el panel Tamaño de clúster, escriba el número de nodos de trabajo y seleccione Guardar. |
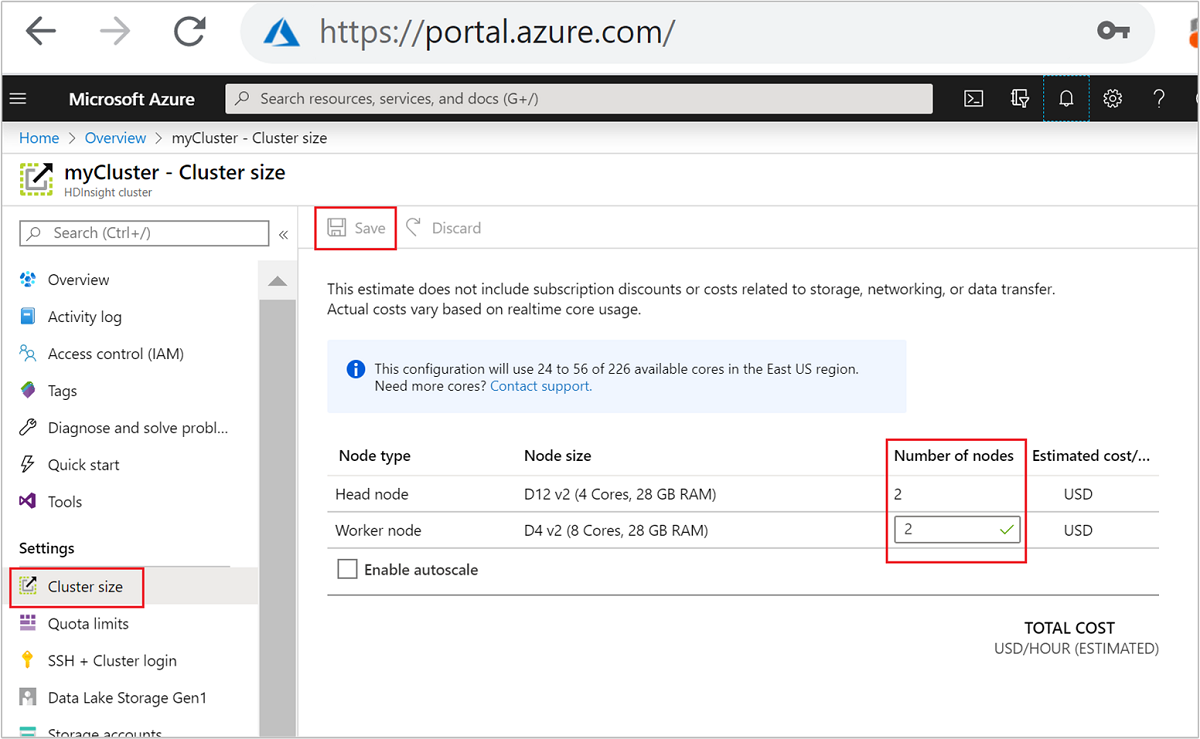
Con cualquiera de estos métodos, puede escalar o reducir verticalmente el clúster de HDInsight en cuestión de minutos.
Importante
- La CLI clásica de Azure está en desuso y solo debe usarse con el modelo de implementación clásico. Para las demás implementaciones, utilice la CLI de Azure.
- El módulo AzureRM de PowerShell está en desuso. Use el módulo Az siempre que sea posible.
Impacto de las operaciones de escalado
Al agregar nodos al clúster de HDInsight en ejecución (escalado vertical), los trabajos no se ven afectados. Los trabajos nuevos pueden enviarse de forma segura mientras el proceso de escalado está en ejecución. Si se produjese un error en la operación de escalado, este dejará el clúster en estado funcional.
Si se quitan nodos (reducción vertical), se producirá un error en los trabajos pendientes o en ejecución cuando finalice la operación de escalado. Dicho error se debe a que algunos de los servicios se reinician durante el proceso de escalado. El clúster podría quedarse atascado en el modo seguro durante una operación de escalado manual.
A continuación se muestra cómo el efecto de cambiar el número de nodos de datos varía para cada tipo de clúster compatible con HDInsight:
Apache Hadoop
Puede aumentar fácilmente la cantidad de nodos de trabajo en un clúster de Hadoop en ejecución sin que ello afecte a ningún trabajo. También se pueden enviar trabajos nuevos mientras la operación está en curso. Los errores de una operación de escalado se administran fácilmente. El clúster siempre se deja en un estado funcional.
Cuando se reduce verticalmente un clúster de Hadoop con menos nodos de datos, se reinician algunos servicios. Este comportamiento hace que todos los trabajos pendientes y en ejecución fallen al completarse la operación de escalado. Sin embargo, puede volver a enviar los trabajos una vez finalizada la operación.
HBase Apache
Puede agregar nodos fácilmente al clúster de HBase mientras se encuentra en ejecución, así como quitarlos. Los servidores regionales se equilibran automáticamente en unos pocos minutos tras completar la operación de escalado. Sin embargo, puede equilibrar manualmente los servidores regionales. Inicie sesión en el nodo principal del clúster y ejecute los siguientes comandos:
pushd %HBASE_HOME%\bin hbase shell balancerPara más información sobre el uso del shell de HBase, vea Introducción a un ejemplo de Apache HBase en HDInsight.
Nota:
No es responsable de la aplicación para los clústeres de Kafka.
LLAP de Apache Hive
Después de escalar a
Nnodos de trabajo, HDInsight define automáticamente las siguientes configuraciones y reinicia Hive.- Número máximo total de consultas simultáneas:
hive.server2.tez.sessions.per.default.queue = min(N, 32) - Número de nodos usados por LLAP de Hive:
num_llap_nodes = N - Número de nodos para ejecutar el demonio LLAP de Hive:
num_llap_nodes_for_llap_daemons = N
- Número máximo total de consultas simultáneas:
Reducción vertical segura de clústeres
Reducción vertical de clústeres con trabajos en ejecución
Para evitar que se produzcan errores en los trabajos en ejecución durante una operación de reducción vertical, puede intentar tres cosas:
- Espere hasta que finalicen los trabajos antes de realizar la reducción vertical del clúster.
- Finalice los trabajos manualmente.
- Vuelva a enviar los trabajos una vez haya concluido la operación de escalado.
Para ver una lista de los trabajos pendientes y en ejecución, puede usar la interfaz de usuario de Resource Manager de YARN; para ello, siga estos pasos:
En Azure Portal, seleccione su clúster. El clúster se abre en una nueva página del portal.
En la vista principal, vaya a Paneles de clúster>Inicio de Ambari. Escriba las credenciales del clúster.
En la interfaz de usuario de Ambari, seleccione YARN en la lista de servicios del menú de la izquierda.
En la página de YARN, seleccione Vínculos rápidos, mantenga el puntero sobre el nodo principal activo y, después, seleccione ResourceManager UI (UI de Resource Manager).
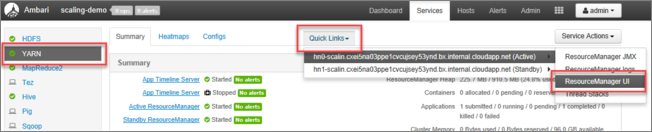
Puede acceder directamente a la UI de Resource Manager con https://<HDInsightClusterName>.azurehdinsight.net/yarnui/hn/cluster.
Verá una lista de trabajos, junto con su estado actual. En la captura de pantalla, hay un trabajo en ejecución:
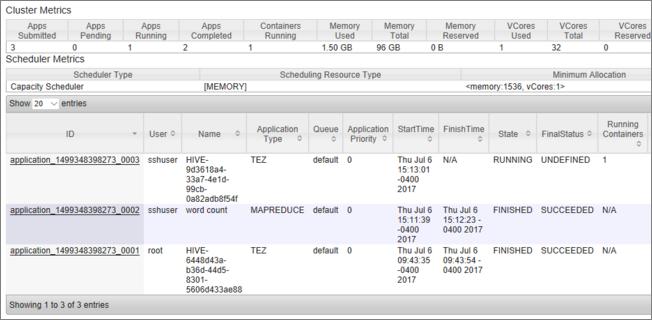
Para terminar manualmente esa aplicación en ejecución, ejecute el comando siguiente desde el shell de SSH:
yarn application -kill <application_id>
Por ejemplo:
yarn application -kill "application_1499348398273_0003"
Bloqueo en modo seguro
Al reducir verticalmente un clúster, HDInsight utiliza las interfaces de administración de Apache Ambari para retirar antes los nodos de trabajo adicionales. Los nodos replican sus bloques HDFS en otros nodos de trabajo en línea. Después, HDInsight reduce el nodo verticalmente de forma segura. HDFS entra en modo seguro durante la operación de escalado. Se supone que HDFS saldrá al finalizar el escalado. Sin embargo, en algunos casos, el HDFS se atasca en modo seguro durante una operación de escalado debido a la infra-replicación del bloque de archivos.
De forma predeterminada, HDFS se configura con el valor 1 en dfs.replication, que controla el número de copias de cada bloque de archivos que hay disponibles. Cada una de las copias de un bloque de archivos se almacena en un nodo diferente del clúster.
Cuando el número esperado de copias del bloque no está disponible, HDFS entra en modo seguro y Ambari genera alertas. HDFS puede entrar en modo seguro para una operación de escalado. El clúster puede quedarse bloqueado en el modo seguro si no se detecta el número necesario de nodos para la replicación.
Ejemplos de errores cuando el modo seguro está activado
org.apache.hadoop.hdfs.server.namenode.SafeModeException: Cannot create directory /tmp/hive/hive/819c215c-6d87-4311-97c8-4f0b9d2adcf0. Name node is in safe mode.
org.apache.http.conn.HttpHostConnectException: Connect to active-headnode-name.servername.internal.cloudapp.net:10001 [active-headnode-name.servername. internal.cloudapp.net/1.1.1.1] failed: Connection refused
Puede revisar los registros del nodo de nombre en la carpeta /var/log/hadoop/hdfs/, cerca del momento en que se escaló el clúster, para ver cuándo entró en modo seguro. Los archivos de registro se denominan Hadoop-hdfs-namenode-<active-headnode-name>.*.
La causa principal es que Hive depende de los archivos temporales de HDFS durante la ejecución de consultas. Cuando HDFS entra en modo seguro, Hive no puede ejecutar las consultas porque no puede escribir en HDFS. Los archivos temporales de HDFS se encuentran en la unidad local montada en las VM del nodo de trabajo individual. Los archivos se replican entre otros nodos de trabajo en tres réplicas, como mínimo.
Evitar que HDInsight se quede bloqueado en modo seguro
Hay varias maneras de evitar que HDInsight se quede en modo seguro:
- Detenga todos los trabajos de Hive antes de reducir verticalmente HDInsight. Como alternativa, programe el proceso de reducción vertical para evitar que entre en conflicto con los trabajos de Hive en ejecución.
- Limpie manualmente los archivos temporales del directorio
tmpde Hive en HDFS antes de la reducción vertical. - Solo reduzca verticalmente HDInsight a tres nodos de trabajo como mínimo. Evite reducir a un solo nodo de trabajo.
- Ejecute el comando para salir del modo seguro, si es necesario.
Estas opciones se describen en las secciones siguientes.
Detención de todos los trabajos de Hive
Detenga todos los trabajos de Hive antes de reducir verticalmente a un nodo de trabajo. Si la carga de trabajo está programada, ejecute la reducción vertical una vez que se complete el trabajo de Hive.
Detener los trabajos de Hive antes del escalado ayuda a minimizar el número de archivos temporales en la carpeta tmp (en caso de que haya).
Limpieza manual de los archivos temporales de Hive
Si Hive ha dejado archivos temporales, puede limpiarlos manualmente antes de la reducción vertical para evitar la activación del modo seguro.
Compruebe qué ubicación se usa para los archivos temporales de Hive, para lo que puede examinar la propiedad de la configuración
hive.exec.scratchdir. Este parámetro se establece en/etc/hive/conf/hive-site.xml:<property> <name>hive.exec.scratchdir</name> <value>hdfs://mycluster/tmp/hive</value> </property>Detenga los servicios de Hive y asegúrese de que se hayan completado todas las consultas y los trabajos.
Enumere el contenido del directorio temporal
hdfs://mycluster/tmp/hive/para ver si contiene archivos:hadoop fs -ls -R hdfs://mycluster/tmp/hive/hiveEste es un ejemplo de resultado cuando existen archivos:
sshuser@scalin:~$ hadoop fs -ls -R hdfs://mycluster/tmp/hive/hive drwx------ - hive hdfs 0 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c drwx------ - hive hdfs 0 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c/_tmp_space.db -rw-r--r-- 3 hive hdfs 27 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c/inuse.info -rw-r--r-- 3 hive hdfs 0 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c/inuse.lck drwx------ - hive hdfs 0 2017-07-06 20:30 hdfs://mycluster/tmp/hive/hive/c108f1c2-453e-400f-ac3e-e3a9b0d22699 -rw-r--r-- 3 hive hdfs 26 2017-07-06 20:30 hdfs://mycluster/tmp/hive/hive/c108f1c2-453e-400f-ac3e-e3a9b0d22699/inuse.infoSi sabe que Hive ya no necesita estos archivos, puede eliminarlos. Asegúrese de que Hive no tiene ninguna consulta en ejecución; para ello, consulte la página de la interfaz de usuario de Resource Manager en Yarn.
Línea de comandos de ejemplo para quitar archivos de HDFS:
hadoop fs -rm -r -skipTrash hdfs://mycluster/tmp/hive/
Escalado de HDInsight a tres, o más, nodos de trabajo
Si los clústeres se bloquean con frecuencia en el modo seguro al reducir verticalmente a menos de tres nodos de trabajo, conserve al menos tres nodos de trabajo.
Tener tres nodos de trabajo es más costoso que reducir verticalmente a uno solo. Sin embargo, esta acción impide que el clúster se quede bloqueado en modo seguro.
Reducción vertical de HDInsight a un nodo de trabajo
Incluso cuando el clúster se reduce verticalmente a un nodo, el nodo de trabajo 0 aún sobrevive. El nodo de trabajo 0 nunca se puede retirar.
Ejecución del comando para salir del modo seguro
La última opción es ejecutar el comando para salir del modo seguro. Si HDFS entró en modo seguro porque había poca replicación de archivos de Hive, ejecute el siguiente comando para salir del modo seguro:
hdfs dfsadmin -D 'fs.default.name=hdfs://mycluster/' -safemode leave
Reducción vertical de un clúster de Apache HBase
Los servidores regionales se equilibran automáticamente en pocos minutos tras completar una operación de escalado. Para equilibrar manualmente los servidores regionales, siga estos pasos:
Conéctate al clúster de HDInsight con SSH: Para más información, consulte Uso SSH con HDInsight.
Inicie el shell de HBase:
hbase shellUse el comando siguiente para equilibrar manualmente los servidores regionales:
balancer
Pasos siguientes
Para obtener información específica sobre cómo ampliar tu clúster de HDInsight, consulta: