Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Las soluciones de macrodatos en tiempo real actúan sobre los datos que se mueven. Normalmente, estos datos son más valiosos en su momento de llegada. Si el flujo de datos entrante pasa a ser mayor de lo que pueda controlarse en ese momento, es posible que tenga que limitar los recursos. Como alternativa, un clúster de HDInsight puede escalarse para hacer frente a la solución de streaming agregando nodos a petición.
En una aplicación de streaming, uno o varios orígenes de datos generan eventos (a veces, millones por segundo) que deben ser ingeridos rápidamente sin quitar ninguna información útil. Los eventos de entrada se tratan con el almacenamiento en búfer de los flujos de datos, también denominado puesta en cola de eventos, por un servicio como Apache Kafka o Event Hubs. Después de recopilar los eventos, puede analizar los datos mediante un sistema de análisis en tiempo real en el nivel de procesamiento de flujos de datos. Los datos procesados se pueden almacenar en sistemas de almacenamiento a largo plazo, como Azure Data Lake Storage y se muestran en tiempo real en un panel de business intelligence, como Power BI, Tableau o una página web personalizada.
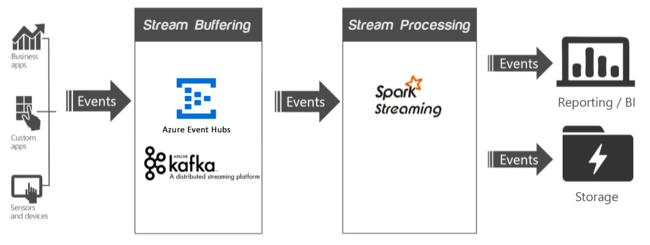
Apache Kafka
Apache Kafka proporciona un servicio de cola de mensajes de baja latencia y alto rendimiento y ahora forma parte del conjunto de aplicaciones de Apache de software de código abierto (OSS). Kafka usa un modelo de mensajería de publicación y suscripción y almacena flujos de datos con particiones de forma segura en un clúster distribuido replicado. Kafka se escala linealmente a medida que el rendimiento aumenta.
Para más información, consulte Introducción a Apache Kafka en HDInsight.
Spark Streaming
Spark Streaming es una extensión para Spark que permite reutilizar el mismo código que se usa para el procesamiento por lotes. Puede combinar consultas por lotes e interactivas en la misma aplicación. A diferencia de Spark, Streaming proporciona una semántica de procesamiento de estado exactamente una vez. Cuando se usa en combinación con la API de Kafka Direct, que garantiza que todos los datos de Kafka se reciben en Spark Streaming exactamente una vez, es posible lograr garantías de extremo a otro exactamente una vez. Uno de los puntos fuertes de Spark Streaming es sus funcionalidades tolerantes a errores, recuperando rápidamente los nodos con errores cuando se usan varios nodos dentro del clúster.
Para más información, consulte ¿Qué es Apache Spark Streaming?.
Escalado de un clúster
Aunque puede especificar el número de nodos del clúster durante la creación, es posible que desee aumentar o reducir el clúster para que coincida con la carga de trabajo. Todos los clústeres de HDInsight le permiten cambiar el número de nodos del clúster. Los clústeres de Spark se pueden quitar sin que se pierdan datos, ya que todos los datos están almacenados en Azure Storage o en Data Lake Storage.
Las tecnologías de desacoplamiento tienen sus ventajas. Por ejemplo, Kafka es una tecnología de almacenamiento en búfer de eventos, por lo que se realizan muchas operaciones de E/S y no se necesita mucha capacidad de procesamiento. En comparación, los procesadores de flujo, como Spark Streaming, consumen un uso computacionalmente intensivo, lo que requiere máquinas virtuales más eficaces. Al tener estas tecnologías desacopladas en distintos clústeres, puede escalarlas de forma independiente, a la vez que se usan mejor las máquinas virtuales.
Escalado de la capa de almacenamiento en búfer de flujos
Ambas tecnologías de almacenamiento en búfer de flujos de datos, Event Hubs y Kafka, usan particiones y los consumidores leen dichas particiones. El escalado del rendimiento de entrada requiere escalar verticalmente el número de particiones y agregar particiones proporciona un aumento del paralelismo. En Event Hubs, el número de particiones no se puede cambiar después de la implementación, de modo que es importante empezar teniendo la escala de destino en cuenta. Con Kafka, es posible agregar particiones, incluso mientras Kafka procesa los datos. Kafka proporciona una herramienta para volver a asignar las particiones, kafka-reassign-partitions.sh. HDInsight proporciona una herramienta de reajuste de las réplicas de particiones, rebalance_rackaware.py. Esta herramienta de reequilibrio llama a la herramienta kafka-reassign-partitions.sh de forma que cada réplica se encuentra en un dominio de error independiente y un dominio de actualización, lo que hace que el bastidor de Kafka sea consciente y aumente la tolerancia a errores.
Escalado de la capa de procesamiento de flujos
Apache Spark Streaming permite agregar nodos de trabajo a sus clústeres, incluso durante el procesamiento de los datos.
Apache Spark utiliza tres parámetros clave para configurar su entorno, según los requisitos de la aplicación: spark.executor.instances, spark.executor.cores y spark.executor.memory. Un ejecutor es un proceso que se inicia para una aplicación Spark. Se ejecuta en el nodo de trabajo y es responsable de realizar las tareas de la aplicación. El número predeterminado de ejecutores y los tamaños de los ejecutores para cada clúster se calculan basándose en el número de nodos trabajadores y el tamaño del nodo trabajador. Estos números se almacenan en el archivo spark-defaults.conf en cada nodo principal del clúster.
Estos tres parámetros se pueden configurar en el nivel de clúster para todas las aplicaciones que se ejecutan en el clúster y se pueden especificar también para cada aplicación individual. Para más información, consulte Administración de recursos para clústeres de Apache Spark.