Guía de solución de problemas para la migración de cargas de trabajo de Hive desde HDInsight 3.6 a HDInsight 4.0
En este artículo se proporcionan respuestas a algunos de los problemas más comunes a los que se enfrentan los clientes al migrar cargas de trabajo de Hive de HDInsight 3.6 a HDInsight 4.0.
Reduzca la latencia al ejecutar DESCRIBE TABLE_NAME.
Solución:
Aumente el número máximo de objetos (tablas o particiones) que se pueden recuperar del metastore en un lote. Establézcalo en un número grande (el valor predeterminado es 300) hasta que se alcancen los niveles de latencia satisfactorios. Cuanto mayor sea el número, menos recorridos de ida y vuelta se necesitan en el servidor de metastore de Hive, si bien también puede provocar un mayor requisito de memoria en el lado cliente.
hive.metastore.batch.retrieve.max=2000Reinicio de Hive y todos los servicios obsoletos.
No se puede consultar el archivo de texto Gzipped si skip.header.line.count y skip.footer.line.count están configurados para la tabla.
El problema se ha corregido en Interactive Query 4.0, pero aún persiste en Interactive Query 3.1.0.
Solución:
- Cree una tabla sin usar
"skip.header.line.count"="1"y"skip.footer.line.count"="1", luego cree una vista de la tabla original que excluya la fila del encabezado/pie en la consulta.
No se pueden usar caracteres Unicode.
Solución:
Conéctese a la base de datos del metastore de Hive del clúster.
Realice la copia de seguridad de las tablas
TBLSyTABLE_PARAMScon el comando siguiente:select * into tbls_bak from tbls; select * into table_params_bak from table_params;Cambie manualmente los tipos de columna afectados a
nvarchar(max).alter table TABLE_PARAMS alter column PARAM_VALUE nvarchar(max); alter table TBLS alter column VIEW_EXPANDED_TEXT nvarchar(max) null; alter table TBLS alter column VIEW_ORIGINAL_TEXT nvarchar(max) null;
Create table as select (CTAS) crea una nueva tabla con el mismo UUID.
Hive 3.1 (HDInsight 4.0) ofrece una UDF integrada para generar UUID únicos. El método UUID() de Hive genera identificadores únicos incluso con CTAS. Se puede usar como se indica a continuación.
create table rhive as
select uuid() as UUID
from uuid_test
El formato de salida del trabajo de Hive difiere de HDInsight 3.6.
Se debe a la diferencia de WebHCat(Templeton) entre HDInsight 3.6 y HDInsight 4.0.
API REST de Hive: agregue
arg=--showHeader=false -d arg=--outputformat=tsv2 -dSDK de .NET: inicialice argumentos de
HiveJobSubmissionParameters.List<string> args = new List<string> { { "--showHeader=false" }, { "--outputformat=tsv2" } }; var parameters = new HiveJobSubmissionParameters { Query = "SELECT clientid,market from hivesampletable LIMIT 10", Defines = defines, Arguments = args };
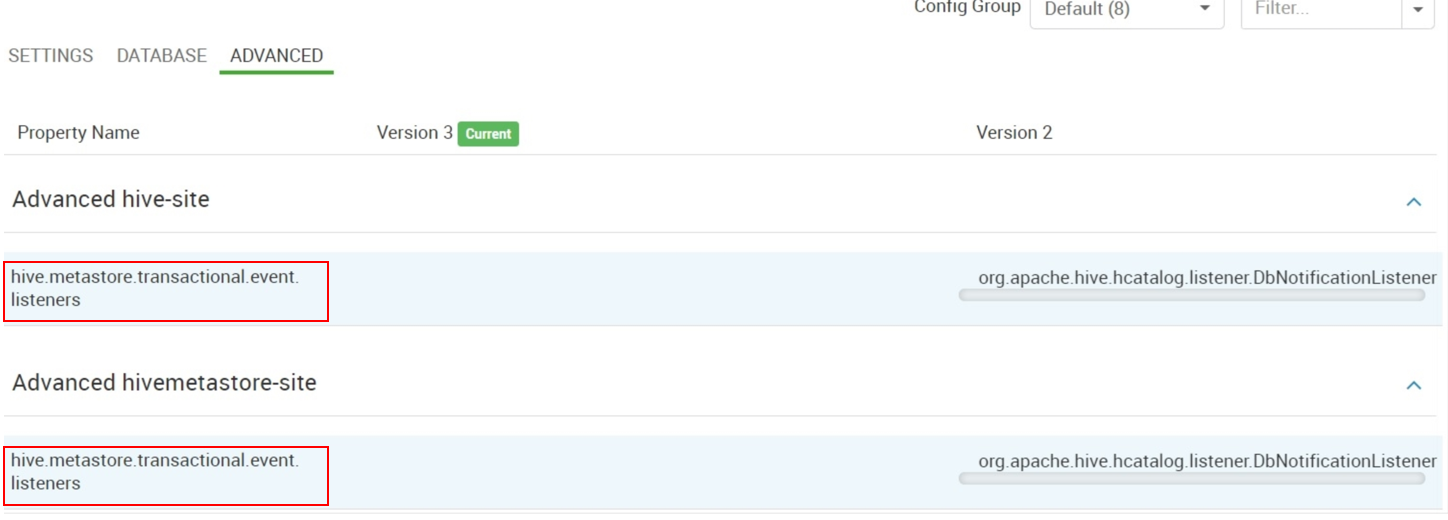
Reducción de la latencia de creación de tablas internas de Hive
En el sitio de Hive avanzado y el sitio de Hivemetastore avanzado, elimine el valor
org.apache.hive.hcatalog.listener.DbNotificationListenerdehive.metastore.transactional.event.listeners.Si
hive.metastore.event.listenerstiene un valor, quítelo.DbNotificationListener solo es necesario si usa comandos REPL y, si no es así, es seguro quitarlo.
Cambio de la ubicación predeterminada de la tabla de Hive
Este es un cambio de comportamiento por diseño en HDInsight 4.0 (Hive 3.1). Este cambio está motivado por el control de permisos de archivo.
Para crear tablas externas en una ubicación personalizada, especifique la ubicación en la instrucción create table.
Deshabilitación de ACID en HDInsight 4.0
Se recomienda habilitar ACID en HDInsight 4.0. La mayoría de las mejoras recientes (tanto funcionales como de rendimiento) en Hive están disponibles solo para las tablas ACID.
Pasos para deshabilitar ACID en HDInsight 4.0:
Cambie las siguientes configuraciones de Hive en Ambari:
hive.strict.managed.tables=false hive.support.concurrency=false; hive.txn.manager=org.apache.hadoop.hive.ql.lockmgr.DummyTxnManager; hive.enforce.bucketing=false; hive.compactor.initiator.on=false; hive.compactor.worker.threads=0; hive.create.as.insert.only=false; metastore.create.as.acid=false;
Nota
Si hive.strict.managed.tables está establecido en el <valor predeterminado> de true, se producirá el siguiente error al crear una tabla administrada y no transaccional:
java.lang.Exception: java.sql.SQLException: Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. Unable to alter table. Table <Table name> failed strict managed table checks due to the following reason: Table is marked as a managed table but is not transactional.
- Reinicie el servicio de Hive.
Importante
Microsoft recomienda no compartir los mismos datos o almacenamiento con las tablas administradas por Hive de HDInsight 3.6 y HDInsight 4.0. Es un escenario no admitido.
Normalmente, las configuraciones anteriores deben establecerse incluso antes de crear tablas de Hive en el clúster de HDInsight 4.0. No debemos deshabilitar ACID una vez creadas las tablas administradas. Podría provocar la pérdida de datos o resultados incoherentes. Por lo tanto, se recomienda establecerlo una vez al crear un clúster y no cambiarlo más adelante.
La deshabilitación de ACID después de crear tablas es arriesgado; sin embargo, en caso de que quiera hacerlo, siga estos pasos para evitar posibles pérdidas de datos o incoherencias:
- Cree una tabla externa con el mismo esquema y copie los datos de la tabla administrada original mediante el comando CTAS
create external table e_t1 select * from m_t1. - Quite la tabla administrada mediante
drop table m_t1. - Deshabilite ACID mediante las configuraciones sugeridas.
- Cree m_t1 y copie los datos de la tabla externa mediante el comando CTAS
create table m_t1 select * from e_t1. - Quite la tabla externa mediante
drop table e_t1.
- Cree una tabla externa con el mismo esquema y copie los datos de la tabla administrada original mediante el comando CTAS
Asegúrese de que todas las tablas administradas se convierten en tablas externas y se descartan antes de deshabilitar ACID. Además, compare el esquema y los datos después de cada paso para evitar cualquier discrepancia.
Creación de una tabla externa de Hive con permiso 755
Este problema se puede resolver mediante cualquiera de las dos opciones siguientes:
Establezca manualmente el permiso de carpeta en 757 o 777 para permitir que el usuario de Hive escriba en el directorio.
Cambie el "Administrador de autorización de Hive" de
org.apache.hadoop.hive.ql.security.authorization.StorageBasedAuthorizationProvideraorg.apache.hadoop.hive.ql.security.authorization.MetaStoreAuthzAPIAuthorizerEmbedOnly.
MetaStoreAuthzAPIAuthorizerEmbedOnly deshabilita eficazmente las comprobaciones de seguridad porque el metastore de Hive no está insertado en HDInsight 4.0. Sin embargo, esto puede traer otros posibles problemas. Tenga cuidado al usar esta opción.
Errores de permisos en el trabajo de Hive después de actualizar a HDInsight 4.0
En HDInsight 4.0, todas las formas de clúster con componentes de Hive se configuran con un nuevo proveedor de autorización: .
org.apache.hadoop.hive.ql.security.authorization.StorageBasedAuthorizationProviderSe deben asignar permisos de archivo HDFS al usuario de Hive para el archivo al que se accede. El mensaje de error proporciona los detalles necesarios para resolver el problema.
También puede cambiar al proveedor
MetaStoreAuthzAPIAuthorizerEmbedOnlyque se usa en clústeres de Hive de HDInsight 3.6.org.apache.hadoop.hive.ql.security.authorization.MetaStoreAuthzAPIAuthorizerEmbedOnly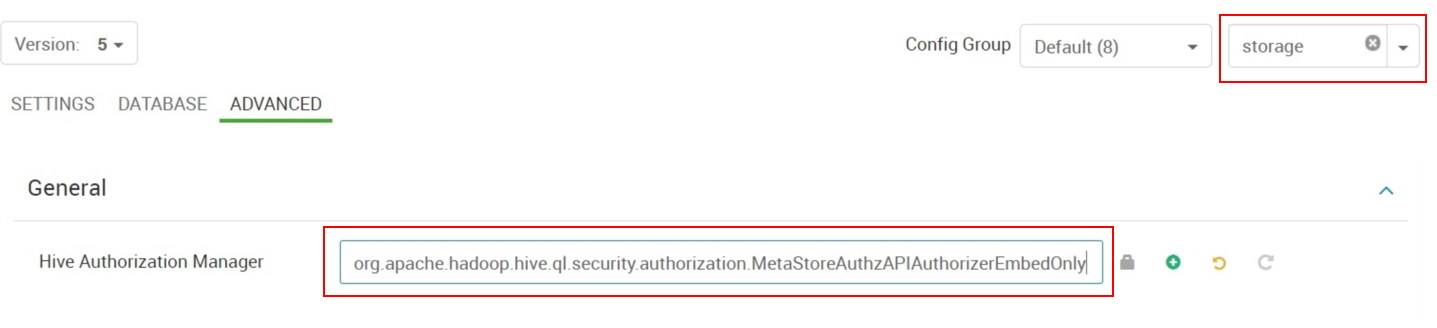
No se puede consultar la tabla con OpenCSVSerde
La lectura de datos de la tabla de formato csv puede producir una excepción como la siguiente:
MetaException(message:java.lang.UnsupportedOperationException: Storage schema reading not supported)
Solución:
Agregar la configuración
metastore.storage.schema.reader.impl=org.apache.hadoop.hive.metastore.SerDeStorageSchemaReaderenCustom hive-sitemediante la interfaz de usuario de AmbariReiniciar todos los servicios de Hive obsoletos
Pasos siguientes
Si su problema no aparece o es incapaz de resolverlo, visite uno de nuestros canales para obtener ayuda adicional:
Obtenga respuestas de expertos de Azure mediante el soporte técnico de la comunidad de Azure.
Póngase en contacto con @AzureSupport, la cuenta oficial de Microsoft Azure para mejorar la experiencia del cliente. Esta cuenta pone en contacto a la comunidad de Azure con los recursos adecuados: respuestas, soporte técnico y expertos.
Si necesita más ayuda, puede enviar una solicitud de soporte técnico desde Azure Portal. Seleccione Soporte técnico en la barra de menús o abra la central Ayuda + soporte técnico. Para obtener información más detallada, revise Creación de una solicitud de soporte técnico de Azure. La suscripción a Microsoft Azure incluye acceso al soporte técnico para facturación y administración de suscripciones. El soporte técnico se proporciona a través de uno de los planes de soporte técnico de Azure.
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de