Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Azure Storage es una solución de almacenamiento sólida y de uso general, que se integra sin problemas con HDInsight. HDInsight puede usar un contenedor de blobs en Azure Storage como el sistema de archivos predeterminado para el clúster. Mediante una interfaz HDFS, el conjunto completo de componentes de HDInsight puede operar directamente en datos estructurados o no estructurados almacenados como blobs.
Se recomienda usar contenedores de almacenamiento independientes para el almacenamiento de clúster predeterminado y los datos empresariales. La separación es para aislar los registros de HDInsight y los archivos temporales de sus propios datos empresariales. También se recomienda eliminar el contenedor de blobs predeterminado, que contiene los registros de la aplicación y del sistema, después de cada uso para reducir los costes de almacenamiento. Asegúrese de recuperar los registros antes de eliminar el contenedor.
Si decide proteger la cuenta de almacenamiento con las restricciones de firewalls y redes virtuales en redes seleccionadas, asegúrese de habilitar la excepción Permitir servicios de Microsoft de confianza... . La excepción es para que HDInsight pueda obtener acceso a su cuenta de almacenamiento.
Arquitectura de almacenamiento de HDInsight
El diagrama siguiente proporciona una panorámica de la arquitectura de HDInsight de Azure Storage:
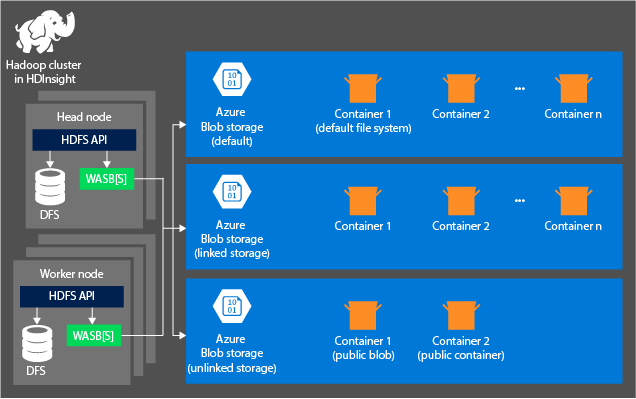
HDInsight brinda acceso al sistema de archivos distribuidos que se adjunta localmente a los nodos de ejecución. Se puede acceder a este sistema de archivos usando el URI completo, por ejemplo:
hdfs://<namenodehost>/<path>
A través de HDInsight, también puede tener acceso a datos en Azure Storage. La sintaxis es la siguiente:
wasb://<containername>@<accountname>.blob.core.windows.net/<path>
Para las cuentas que tienen un espacio de nombres jerárquico (Azure Data Lake Storage Gen2), la sintaxis es la siguiente:
abfs://<containername>@<accountname>.dfs.core.windows.net/<file.path>/
A la hora de usar una cuenta de Azure Storage con clústeres de HDInsight, es necesario considerar lo siguiente:
Contenedores de las cuentas de almacenamiento que se conectan a un clúster: dado que el nombre y la clave de la cuenta se asocian al clúster durante la creación, tiene acceso total a los blobs de dichos contenedores.
Contenedores públicos o blobs públicos de las cuentas de almacenamiento que no se conectan a un clúster: tiene permiso de solo lectura de los blobs de los contenedores.
Nota:
Los contenedores públicos le permiten obtener una lista de todos los blobs disponibles del contenedor en cuestión y obtener sus metadatos. Los blobs públicos le permiten acceder a los blobs solo si conoce la URL exacta. Para más información, consulte Administración del acceso de lectura anónimo a contenedores y blobs.
Contenedores privados de las cuentas de almacenamiento que no se conectan a un clúster: no puede tener acceso a los blobs de los contenedores a menos que defina la cuenta de almacenamiento al enviar los trabajos de WebHCat.
Las cuentas de almacenamiento definidas en el proceso de creación y sus claves se almacenan en %HADOOP_HOME%/conf/core-site.xml en los nodos de clúster. De manera predeterminada, HDInsight usa las cuentas de almacenamiento definidas en el archivo core-site.xml. Puede modificar esta configuración mediante Apache Ambari. Para más información sobre la configuración de la cuenta de almacenamiento que se puede modificar o colocar en el archivo core-site.xml, consulte estos artículos:
- Soporte técnico de Azure para Hadoop: Azure Blob Storage
- Soporte técnico de Azure para Hadoop: ABFS: Azure Data Lake Storage Gen2
Varios trabajos de WebHCat, incluido Apache Hive. Y MapReduce, streaming de Apache Hadoop y Apache Pig llevan una descripción de cuentas de almacenamiento y metadatos. (Actualmente este aspecto funciona para Pig con cuentas de almacenamiento, pero no para metadatos). Para obtener más información, consulte Uso de un clúster de HDInsight con cuentas de almacenamiento y tiendas de metadatos alternativas.
Los blobs se pueden usar para datos estructurados y no estructurados. Los contenedores de blobs almacenan los datos como pares de clave-valor y no tienen jerarquía de directorios. No obstante, el nombre de clave puede incluir un carácter de barra diagonal ( / ) para que parezca que el archivo está almacenado dentro de una estructura de directorios. Por ejemplo, la clave de un blob puede ser input/log1.txt. No existe un directorio input, pero debido a la barra diagonal en el nombre de clave, la clave se parece a una ruta de acceso de archivo.
Ventajas de Azure Storage
Los clústeres de proceso y los recursos de almacenamiento que no están colocados tienen costos de rendimiento implícitos. Estos costos se mitigan gracias a la manera en que los clústeres de cálculo se crean cerca de los recursos de la cuenta de almacenamiento dentro de la región de Azure. En esta región, los nodos de proceso pueden acceder eficazmente a los datos a través de la red de alta velocidad dentro de Azure Storage.
Al almacenar los datos en Azure Storage en lugar de HDFS, disfruta de varias ventajas:
Uso compartido y reutilización de datos: los datos de HDFS se ubican dentro del clúster de proceso. Solamente las aplicaciones que tengan acceso al clúster de cálculo podrán usar los datos usando las API HDFS. En contraste, se puede acceder a los datos de Azure Storage mediante las API de HDFS o las API REST de Blob Storage. Debido a esta disposición, se puede usar un conjunto mayor de aplicaciones (incluyendo otros clústeres de HDInsight) y herramientas para producir y consumir los datos.
Archivado de datos: Cuando los datos se almacenan en Azure Storage, los clústeres de HDInsight usados para el cálculo se eliminen de forma segura sin perder datos del usuario.
Costo de almacenamiento de datos: El almacenamiento de datos en DFS a largo plazo es más caro que el almacenamiento de datos en Azure Storage. Esto se debe a que el costo de un clúster de proceso es mayor que el costo de Azure Storage. Además, como no hay que volver a cargar los datos para cada generación de clúster de proceso, también se ahorra en costos de carga de datos.
Escalabilidad horizontal elástica: aunque HDFS proporciona un sistema de archivos escalable en horizontal, la escala se determina en función del número de nodos que cree para su clúster. Cambiar la escala puede ser un proceso más complicado que las funcionalidades de escalado elástico que se obtienen automáticamente en Azure Storage.
Replicación geográfica: Su almacenamiento de Azure Storage se puede replicar geográficamente. Aunque la replicación geográfica aporta recuperación geográfica y redundancia de datos, una conmutación por error en la ubicación replicada geográficamente afecta gravemente al rendimiento y puede incurrir en costes adicionales. Por lo tanto, elija la replicación geográfica con prudencia y únicamente si merece la pena pagar el costo adicional por el valor de los datos.
Determinados trabajos y paquetes de MapReduce podrían crear resultados intermedios que realmente no desea almacenar en Azure Storage. En tal caso, puede optar por almacenar los datos en el HDFS local. HDInsight usa DFS para varios de estos resultados intermedios en los trabajos de Hive y otros procesos.
Nota:
La mayoría de los comandos HDFS (por ejemplo, ls, copyFromLocal y mkdir) siguen funcionando según lo previsto. Únicamente los comandos específicos de la implementación nativa de HDFS (a la que nos referiremos como DFS), como fschk y dfsadmin, muestran comportamientos diferentes en Azure Storage.