Uso del Kit de herramientas de Azure para IntelliJ para depurar de forma remota aplicaciones de Apache Spark en HDInsight mediante VPN
Se recomienda depurar las aplicaciones de Apache Spark de forma remota mediante SSH. Para obtener instrucciones, consulte Depuración de aplicaciones de Apache Spark de forma remota en un clúster de HDInsight con el kit de herramientas de Azure para IntelliJ mediante SSH.
En este artículo se proporcionan instrucciones paso a paso para usar las herramientas de HDInsight del Kit de herramientas de Azure para IntelliJ para enviar un trabajo de Spark en un clúster de HDInsight Spark y luego depurarlo de forma remota desde el equipo de escritorio. Para llevar a cabo estas tareas, debe realizar los siguientes pasos generales:
- Cree una red virtual de Azure de sitio a sitio o de punto a sitio. Para los pasos descritos en este documento, se da por supuesto que usa una red de sitio a sitio.
- Cree un clúster de Spark en HDInsight que forme parte de la red virtual de sitio a sitio.
- Compruebe la conectividad entre el nodo principal del clúster y el equipo de escritorio.
- Cree una aplicación Scala en IntelliJ IDEA y luego configúrela para la depuración remota.
- Ejecución y depuración de la aplicación.
Prerrequisitos
- Una suscripción de Azure. Para más información, vea Obtener una evaluación gratuita de Azure.
- Un clúster de Apache Spark en HDInsight. Para obtener instrucciones, vea Creación de clústeres Apache Spark en HDInsight de Azure.
- Kit de desarrollo de Oracle Java. Puede instalarlo desde el sitio web de Oracle.
- IntelliJ IDEA. En este artículo se usa la versión 2017.1. Puede instalarlo desde el sitio web de JetBrains.
- Herramientas de HDInsight del kit de herramientas de Azure para IntelliJ. Las herramientas de HDInsight para IntelliJ están disponibles como parte del Kit de herramientas de Azure para IntelliJ. Para obtener instrucciones sobre cómo instalar el Kit de herramientas de Azure, vea Instalación del kit de herramientas de Azure para IntelliJ.
- Inicie sesión en la suscripción de Azure desde IntelliJ IDEA. Siga las instrucciones de Uso de Azure Toolkit for IntelliJ con el fin de crear aplicaciones Apache Spark para un clúster de HDInsight.
- Solución alternativa de excepción. Mientras se ejecuta la aplicación Spark Scala para la depuración remota en un equipo Windows, puede producirse una excepción. Esta excepción se explica en SPARK-2356 y se produce porque falta el archivo WinUtils.exe en Windows. Para solucionar este error, debe descargar Winutils.exe en una ubicación como C:\WinUtils\bin. Agregue una variable de entorno HADOOP_HOME y establezca su valor en C\WinUtils.
Paso 1: Creación de una red virtual de Azure
Siga las instrucciones de los vínculos siguientes para crear una red virtual de Azure y comprobar la conectividad entre ella y el equipo de escritorio:
- Creación de una red virtual con una conexión VPN de sitio a sitio mediante Azure Portal
- Creación de una red virtual con una conexión VPN de sitio a sitio mediante Azure Resource Manager y PowerShell
- Configuración de una conexión punto a sitio a una red virtual mediante PowerShell
Paso 2: Creación de un clúster de Spark en HDInsight
Se recomienda crear también un clúster de Apache Spark en Azure HDInsight que forme parte de la red virtual de Azure que ha creado. Use la información disponible en Crear clústeres basados en Linux en HDInsight. Como parte de la configuración opcional, seleccione la red virtual de Azure que ha creado en el paso anterior.
Paso 3: Comprobación de la conectividad entre el nodo principal del clúster y el escritorio.
Obtenga la dirección IP del nodo principal. Abra la IU de Ambari para el clúster. En la hoja del clúster, seleccione Panel.
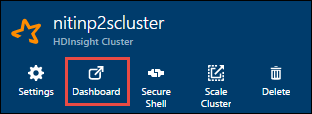
En la interfaz de usuario de Ambari, seleccione Hosts.

Se ve una lista de nodos principales, nodos de trabajo y nodos de Zookeeper. Los nodos principales tienen un prefijo hn\*. Seleccione el primer nodo principal.
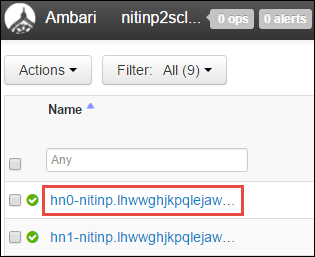
En el panel Resumen de la parte inferior de la página que se abre, copie la Dirección IP del nodo principal y el Nombre de host.
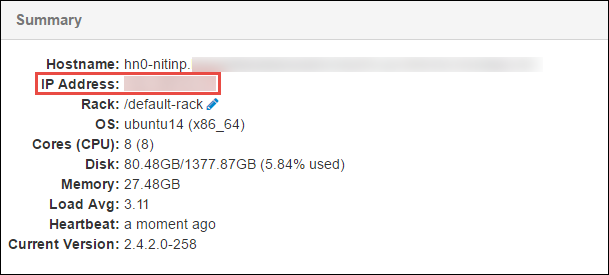
Incluya la dirección IP y el nombre de host del nodo principal en el archivo de hosts en el equipo en el que quiere ejecutar y depurar de forma remota el trabajo de Spark. Esto le permite comunicarse con el nodo principal mediante la dirección IP, así como el nombre de host.
a. Abra un archivo de Bloc de notas con permisos elevados. En el menú Archivo, seleccione Abrir y luego busque la ubicación del archivo de hosts. En un equipo Windows, la ubicación es C:\Windows\System32\Drivers\etc\hosts.
b. Agregue la siguiente información al archivo de hosts:
# For headnode0 192.xxx.xx.xx nitinp 192.xxx.xx.xx nitinp.lhwwghjkpqejawpqbwcdyp3.gx.internal.cloudapp.net # For headnode1 192.xxx.xx.xx nitinp 192.xxx.xx.xx nitinp.lhwwghjkpqejawpqbwcdyp3.gx.internal.cloudapp.netEn el equipo que ha conectado a la red virtual de Azure que usa el clúster de HDInsight, compruebe que puede hacer ping a los nodos principales mediante la dirección IP, así como el nombre de host.
Use SSH para conectarse al nodo principal del clúster según las instrucciones de Conexión a un clúster de HDInsight mediante Linux. En el nodo principal del clúster, haga ping a la dirección IP del equipo de escritorio. Pruebe la conectividad con ambas direcciones IP asignadas al equipo:
- Una para la conexión de red
- Una para la red virtual de Azure
Repita los pasos para el otro nodo principal.
Paso 4: Creación de una aplicación Apache Spark Scala mediante las herramientas de HDInsight de Azure Toolkit for IntelliJ y configuración para la depuración remota.
Abra IntelliJ IDEA y cree un nuevo proyecto. En el cuadro de diálogo Nuevo proyecto , haga lo siguiente:
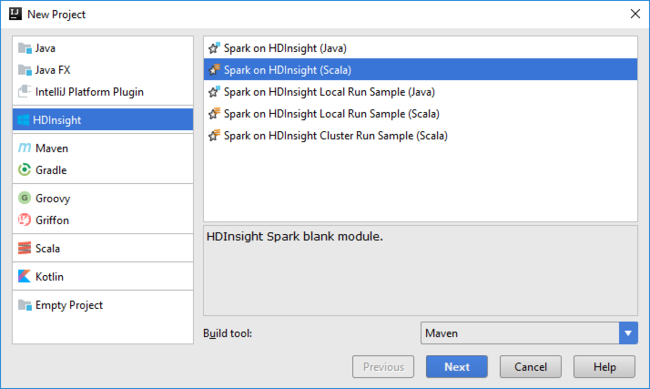
a. Seleccione HDInsight>Spark en HDInsight (Scala) .
b. Seleccione Next (Siguiente).
En el cuadro de diálogo Nuevo proyecto, haga lo siguiente y luego seleccione Finalizar:
Escriba un nombre de proyecto y una ubicación.
En la lista desplegable Project SDK (SDK del proyecto), seleccione Java 1.8 para el clúster de Spark 2.x o Java 1.7 para el clúster de Spark 1.x.
En la lista desplegable Versión de Spark, el asistente para la creación de proyectos de Scala integra la versión correcta del SDK de Spark y el SDK de Scala. Si la versión del clúster de Spark es anterior a 2.0, seleccione Spark 1.x. De lo contrario, seleccione Spark2.x. En este ejemplo se usa Spark 2.0.2 (Scala 2.11.8) .
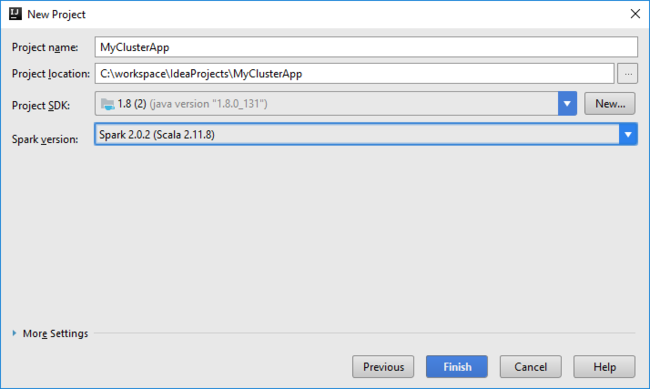
El proyecto de Spark crea automáticamente un artefacto. Para ver el artefacto, haga lo siguiente:
a. En el menú Archivo, seleccione Estructura del proyecto.
b. En el cuadro de diálogo Estructura del proyecto, seleccione Artefactos para ver el artefacto predeterminado que se ha creado. También puede crear su propio artefacto si selecciona el signo más ( + ).
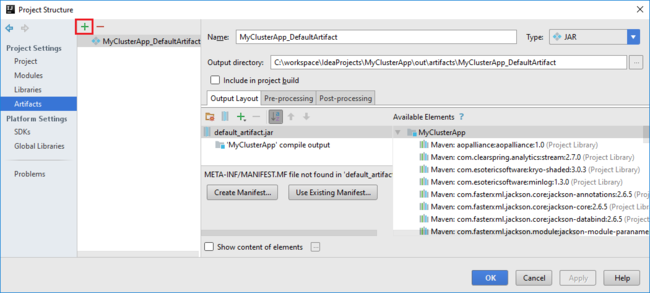
Agregue bibliotecas al proyecto. Para agregar una biblioteca, haga lo siguiente:
a. Haga clic con el botón derecho en el nombre del proyecto en el árbol y después seleccione Open Module Settings(Abrir configuración de módulo).
b. En el cuadro de diálogo Estructura del proyecto, seleccione Bibliotecas, seleccione el símbolo ( + ) y luego Desde Maven.
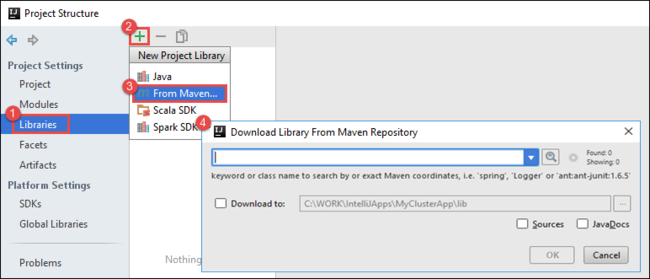
c. En el cuadro de diálogo Download Library from Maven Repository (Descargar biblioteca desde repositorio de Maven), busque y agregue las siguientes bibliotecas:
org.scalatest:scalatest_2.10:2.2.1org.apache.hadoop:hadoop-azure:2.7.1
Copie
yarn-site.xmlycore-site.xmldesde el nodo principal del clúster y agréguelos al proyecto. Use los comandos siguientes para copiar los archivos. Puede usar Cygwin para ejecutar los siguientes comandosscpy copiar los archivos desde los nodos principales del clúster:scp <ssh user name>@<headnode IP address or host name>://etc/hadoop/conf/core-site.xml .Como ya se han agregado la dirección IP del nodo principal del clúster y los nombres de host para el archivo de hosts en el equipo de escritorio, se pueden usar los comandos
scpde la siguiente manera:scp sshuser@nitinp:/etc/hadoop/conf/core-site.xml . scp sshuser@nitinp:/etc/hadoop/conf/yarn-site.xml .Para agregar estos archivos al proyecto, cópielos en la carpeta /src del árbol del proyecto, por ejemplo,
<your project directory>\src.Actualice el archivo
core-site.xmlpara realizar los siguientes cambios:a. Reemplace la clave cifrada. El archivo
core-site.xmlincluye la clave cifrada de la cuenta de almacenamiento asociada al clúster. En el archivocore-site.xmlque se ha agregado al proyecto, reemplace la clave cifrada por la clave de almacenamiento real asociada a la cuenta de almacenamiento predeterminada. Para obtener más información, consulte Administración de las claves de acceso de la cuenta de almacenamiento.<property> <name>fs.azure.account.key.hdistoragecentral.blob.core.windows.net</name> <value>access-key-associated-with-the-account</value> </property>b. Quite las siguientes entradas de
core-site.xml:<property> <name>fs.azure.account.keyprovider.hdistoragecentral.blob.core.windows.net</name> <value>org.apache.hadoop.fs.azure.ShellDecryptionKeyProvider</value> </property> <property> <name>fs.azure.shellkeyprovider.script</name> <value>/usr/lib/python2.7/dist-packages/hdinsight_common/decrypt.sh</value> </property> <property> <name>net.topology.script.file.name</name> <value>/etc/hadoop/conf/topology_script.py</value> </property>c. Guarde el archivo.
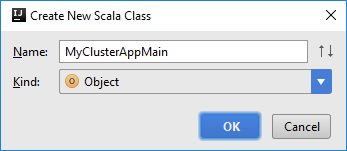
Agregue la clase Main para la aplicación. En el Explorador de proyectos, haga clic con el botón derecho en src, elija Nuevo y luego seleccione Scala class (Clase de Scala).
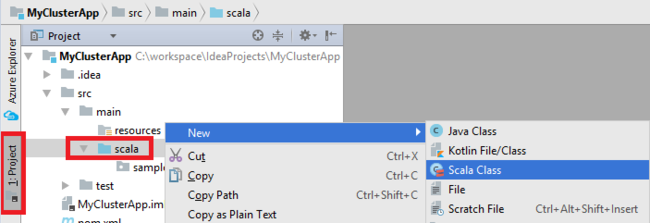
En el cuadro de diálogo Create New Scala Class (Crear nueva clase de Scala), proporcione un nombre, seleccione Object (Objeto) en Kind (Variante) y seleccione OK (Aceptar).
En el archivo
MyClusterAppMain.scala, pegue el código siguiente. Con este código se crea el contexto de Spark y se abre un métodoexecuteJobdesde el objetoSparkSample.import org.apache.spark.{SparkConf, SparkContext} object SparkSampleMain { def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("SparkSample") .set("spark.hadoop.validateOutputSpecs", "false") val sc = new SparkContext(conf) SparkSample.executeJob(sc, "wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv", "wasb:///HVACOut") } }Repita los pasos 8 y 9 para agregar un nuevo objeto de Scala denominado
*SparkSample. Agregue el siguiente código a esta clase. Este código lee los datos de HVAC.csv (disponible en todos los clústeres de HDInsight Spark). Recupera las filas que solo tienen un dígito en la séptima columna del archivo CSV y luego escribe el resultado en /HVACOut bajo el contenedor de almacenamiento predeterminado del clúster.import org.apache.spark.SparkContext object SparkSample { def executeJob (sc: SparkContext, input: String, output: String): Unit = { val rdd = sc.textFile(input) //find the rows which have only one digit in the 7th column in the CSV val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) val s = sc.parallelize(rdd.take(5)).cartesian(rdd).count() println(s) rdd1.saveAsTextFile(output) //rdd1.collect().foreach(println) } }Repita los pasos 8 y 9 para agregar una nueva clase denominada
RemoteClusterDebugging. Esta clase implementa el marco de pruebas de Spark que se usa para depurar las aplicaciones. Agregue el siguiente código a la claseRemoteClusterDebugging:import org.apache.spark.{SparkConf, SparkContext} import org.scalatest.FunSuite class RemoteClusterDebugging extends FunSuite { test("Remote run") { val conf = new SparkConf().setAppName("SparkSample") .setMaster("yarn-client") .set("spark.yarn.am.extraJavaOptions", "-Dhdp.version=2.4") .set("spark.yarn.jar", "wasb:///hdp/apps/2.4.2.0-258/spark-assembly-1.6.1.2.4.2.0-258-hadoop2.7.1.2.4.2.0-258.jar") .setJars(Seq("""C:\workspace\IdeaProjects\MyClusterApp\out\artifacts\MyClusterApp_DefaultArtifact\default_artifact.jar""")) .set("spark.hadoop.validateOutputSpecs", "false") val sc = new SparkContext(conf) SparkSample.executeJob(sc, "wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv", "wasb:///HVACOut") } }Hay un par de cosas importantes que se deben tener en cuenta:
- Para
.set("spark.yarn.jar", "wasb:///hdp/apps/2.4.2.0-258/spark-assembly-1.6.1.2.4.2.0-258-hadoop2.7.1.2.4.2.0-258.jar"), asegúrese de que el archivo JAR del ensamblado Spark está disponible en el almacenamiento de clúster de la ruta especificada. - Para
setJars, especifique la ubicación donde se ha creado el archivo JAR de artefacto. Normalmente es<Your IntelliJ project directory>\out\<project name>_DefaultArtifact\default_artifact.jar.
- Para
En la clase
*RemoteClusterDebugging, haga clic con el botón derecho en la palabra clavetesty luego seleccione Create RemoteClusterDebugging Configuration (Crear configuración de RemoteClusterDebugging).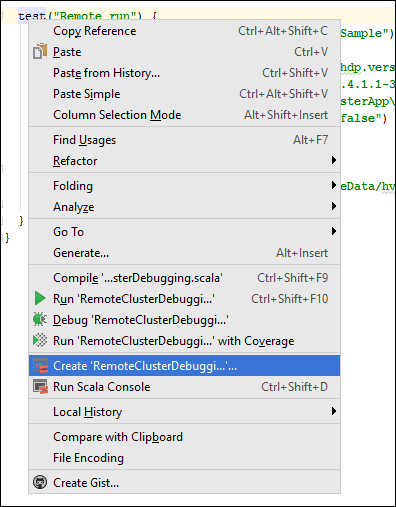
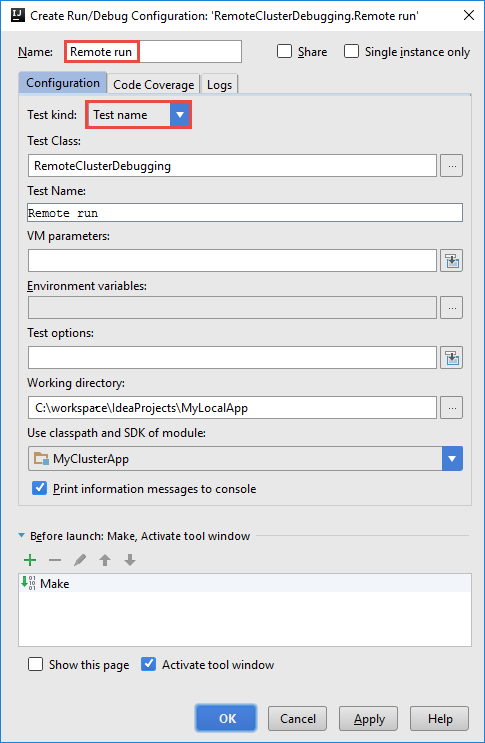
En el cuadro de diálogo Create RemoteClusterDebugging Configuration (Crear configuración de RemoteClusterDebugging), proporcione un nombre para la configuración y luego seleccione Test kind (Tipo de prueba) como Nombre de la prueba. Deje los demás valores como los predeterminados. Seleccione Aplicar y luego Aceptar.
Ahora debería ver una lista desplegable de configuración Ejecución remota en la barra de menús.

Paso 5: Ejecución de la aplicación en modo de depuración.
En el proyecto de IntelliJ IDEA, abra
SparkSample.scalay cree un punto de interrupción junto aval rdd1. En el menú emergente Create Breakpoint for (Crear punto de interrupción para), seleccione line in function executeJob(línea en función executeJob).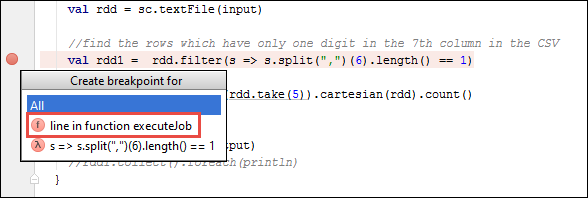
Para ejecutar la aplicación, seleccione el botón Debug Run (Ejecución de depuración) situado junto a la lista desplegable de configuración Ejecución remota.

Cuando la ejecución del programa alcanza el punto de interrupción, se ve una pestaña Depurador en el panel inferior.
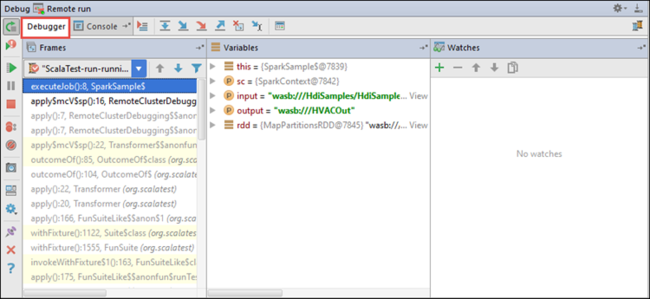
Para agregar una inspección, seleccione el icono ( + ).
En este ejemplo, la aplicación se interrumpe antes de la creación de la variable
rdd1. Con esta inspección, se pueden ver las cinco primeras filas de la variablerdd. Seleccione Entrar.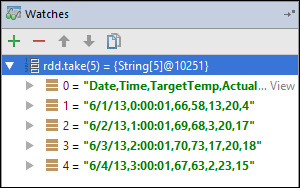
Lo que se ve en la imagen anterior es que, en tiempo de ejecución, se pueden consultar terabytes de datos y depurar el progreso de la aplicación. Por ejemplo, en el resultado que se muestra en la imagen anterior, se ve que la primera fila es un encabezado. Según esto, puede modificar el código de la aplicación para omitir la fila de encabezado si fuera necesario.
Ahora puede seleccionar el icono Resume Program (Continuar programa) para continuar con la ejecución de la aplicación.
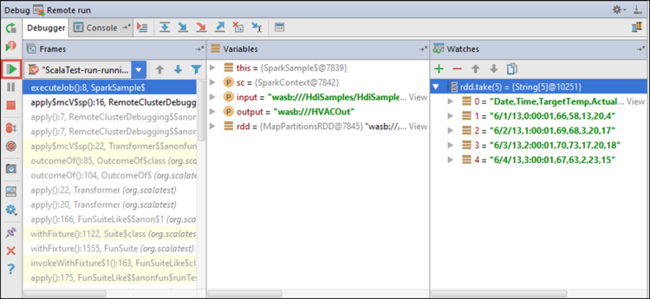
Si la aplicación termina correctamente, debería ver resultados como los siguientes:
Pasos siguientes
Escenarios
- Apache Spark con BI: Análisis de datos interactivos con Spark en HDInsight con las herramientas de BI
- Apache Spark con Machine Learning: uso de Apache Spark en HDInsight para analizar la temperatura de edificios con los datos del sistema de acondicionamiento de aire
- Apache Spark con Machine Learning: uso de Spark en HDInsight para predecir los resultados de la inspección de alimentos
- Análisis de registros de un sitio web mediante Apache Spark en HDInsight
Creación y ejecución de aplicaciones
- Crear una aplicación independiente con Scala
- Ejecución de trabajos de forma remota en un clúster de Apache Spark mediante Apache Livy
Herramientas y extensiones
- Uso de Azure Toolkit for IntelliJ con el fin de crear aplicaciones Apache Spark para un clúster de HDInsight
- Uso de Azure Toolkit for IntelliJ para depurar de forma remota aplicaciones de Apache Spark mediante SSH
- Uso de las herramientas de HDInsight de Azure Toolkit for Eclipse con el fin de crear aplicaciones Apache Spark
- Uso de cuadernos de Apache Zeppelin con un clúster Apache Spark en HDInsight
- Kernels disponibles para Jupyter Notebook en un clúster de Apache Spark para HDInsight
- Uso de paquetes externos con cuadernos de Jupyter Notebook
- Instalación de un cuaderno de Jupyter Notebook en el equipo y conexión al clúster de Apache Spark en HDInsight de Azure