Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este tutorial, aprenderá a crear una trama de datos a partir de un archivo CSV y a ejecutar consultas SQL de Spark interactivas en un clúster de Apache Spark en Azure HDInsight. En Spark, una trama de datos es una colección distribuida de datos que se organizan en columnas con nombre. Una trama de datos es conceptualmente equivalente a una tabla de una base de datos relacional o a una trama de datos de R/Python.
En este tutorial, aprenderá a:
- Creación de una trama de datos a partir de un archivo csv
- Ejecución de consultas en la trama de datos
Prerrequisitos
Un clúster de Apache Spark en HDInsight. Vea Creación de un clúster de Apache Spark.
Creación de un cuaderno de Jupyter Notebook
Jupyter Notebook es un entorno de cuaderno interactivo que admite varios lenguajes de programación. El cuaderno le permite interactuar con los datos, combinar código con el texto de marcado y realizar visualizaciones básicas.
Edite la dirección URL
https://SPARKCLUSTER.azurehdinsight.net/jupyter; para ello, reemplaceSPARKCLUSTERpor el nombre del clúster de Spark. Después, escriba la dirección URL editada en un explorador web. Cuando se le solicite, escriba las credenciales de inicio de sesión del clúster.En la página web de Jupyter, para los clústeres de Spark 2.4, seleccione New>PySpark para crear un cuaderno. Para la versión de Spark 3.1, seleccione Nuevo>PySpark3 en su lugar para crear un cuaderno porque el kernel de PySpark ya no está disponible en Spark 3.1.
Se crea y se abre un nuevo cuaderno con el nombre Untitled(
Untitled.ipynb).Nota
Si se usa el kernel de PySpark o PySpark3 para crear un cuaderno, la sesión
sparkse crea automáticamente al ejecutar la primera celda de código. No es necesario crear la sesión explícitamente.
Creación de una trama de datos a partir de un archivo csv
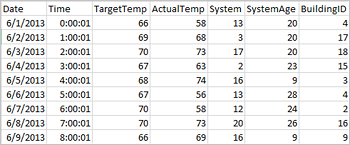
Las aplicaciones pueden crear tramas de datos directamente desde archivos o carpetas del almacenamiento remoto, como Azure Storage o Azure Data Lake Storage; desde una tabla de Hive; o desde otros orígenes de datos compatibles con Spark, como Azure Cosmos DB, Azure SQL DB, DW, etc. La captura de pantalla siguiente muestra una instantánea del archivo HVAC.csv que se usa en este tutorial. El archivo csv incluye todos los clústeres de HDInsight Spark. Los datos capturan las variaciones de temperatura de varios edificios.
Pegue el código siguiente en una celda vacía del cuaderno de Jupyter Notebook y presione MAYÚS + ENTRAR para ejecutarlo. El código importa los tipos necesarios para este escenario:
from pyspark.sql import * from pyspark.sql.types import *Al ejecutar una consulta interactiva en Jupyter, la ventana del explorador web o la leyenda de la pestaña muestran el estado (Busy) [(Ocupado)] junto con el título del cuaderno. También verá un círculo sólido junto al texto PySpark en la esquina superior derecha. Cuando finaliza el trabajo, cambia a un círculo vacío.
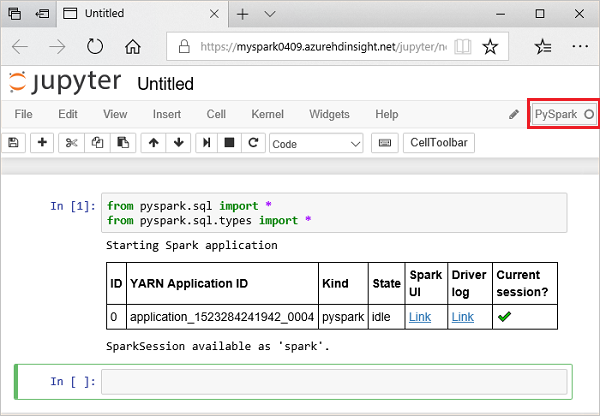
Anote el identificador de sesión devuelto. En la imagen anterior, el identificador de sesión es 0. Si lo desea, puede recuperar los detalles de la sesión. Para ello, vaya a
https://CLUSTERNAME.azurehdinsight.net/livy/sessions/ID/statements, donde CLUSTERNAME es el nombre del clúster de Spark y el identificador es el número de identificación de la sesión.Ejecute el código siguiente para crear una trama de datos y una tabla temporal (hvac).
# Create a dataframe and table from sample data csvFile = spark.read.csv('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv', header=True, inferSchema=True) csvFile.write.saveAsTable("hvac")
Ejecución de consultas en datanami
Una vez creada la tabla, puede ejecutar una consulta interactiva en los datos.
Ejecute el siguiente código en una celda vacía del cuaderno:
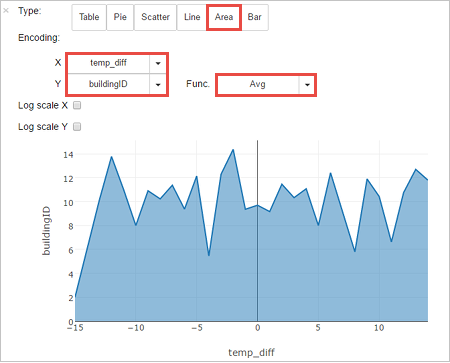
%%sql SELECT buildingID, (targettemp - actualtemp) AS temp_diff, date FROM hvac WHERE date = \"6/1/13\"Se muestra la siguiente salida tabular.
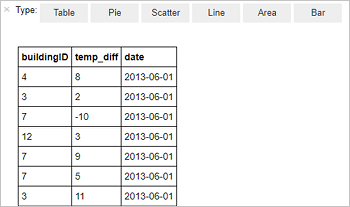
También puede ver la salida en otras visualizaciones. Para ver un gráfico de áreas para la misma salida, seleccione Área y establezca otros valores tal como se muestra.
En la barra de menús de cuaderno, vaya a Archivo>Save and Checkpoint (Guardar y punto de control).
Si ahora va a empezar con el siguiente tutorial, deje el bloc de notas abierto. Si no va a hacerlo, cierre el cuaderno para liberar los recursos de clúster: en la barra de menús del cuaderno, vaya a Archivo>Close and Halt (Cerrar y detener).
Limpieza de recursos
Con HDInsight, los datos y los cuadernos de Jupyter Notebook se almacenan en Azure Storage o Azure Data Lake Storage, por lo que puede eliminar de forma segura un clúster cuando no esté en uso. También se le cobrará por un clúster de HDInsight aunque no se esté usando. Como en muchas ocasiones los cargos por el clúster son mucho más elevados que los cargos por el almacenamiento, desde el punto de vista económico tiene sentido eliminar clústeres cuando no se usen. Si tiene previsto pasar inmediatamente al siguiente tutorial, es aconsejable que no elimine el clúster.
Abra el clúster en Azure Portal y seleccione Eliminar.
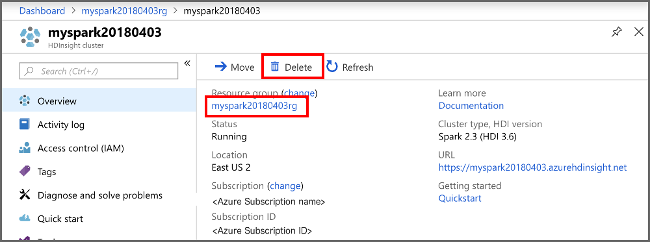
También puede seleccionar el nombre del grupo de recursos para abrir la página del grupo de recursos y, a continuación, seleccionar Eliminar grupo de recursos. Al eliminar el grupo de recursos, se eliminan tanto el clúster de HDInsight Spark como la cuenta de almacenamiento predeterminada.
Pasos siguientes
En este tutorial, aprenderá a crear una trama de datos a partir de un archivo CSV y a ejecutar consultas SQL de Spark interactivas en un clúster de Apache Spark en Azure HDInsight. En el siguiente artículo podrá ver cómo extraer en una herramienta de análisis de BI, como Power BI, los datos que registró en Apache Spark.