Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
HDInsight tiene dos instalaciones de Python integradas en el clúster de Spark: Anaconda Python 2.7 y Python 3.5. Es posible que los clientes tengan que personalizar el entorno de Python, por ejemplo con la instalación de paquetes de Python externos. En este artículo, se muestra el procedimiento recomendado de administración segura de entornos de Python para clústeres de Apache Spark en HDInsight.
Requisitos previos
Un clúster de Apache Spark en HDInsight. Para obtener instrucciones, vea Creación de clústeres Apache Spark en HDInsight de Azure. Si aún no tiene un clúster de Spark en HDInsight, puede ejecutar acciones de script durante la creación del clúster. Consulte la documentación sobre cómo usar acciones de script personalizadas.
Soporte técnico para el software de código abierto utilizado en clústeres de HDInsight
El servicio Microsoft Azure HDInsight usa un entorno de tecnologías de código abierto formado en torno a Apache Hadoop. Microsoft Azure proporciona un nivel general de soporte técnico para las tecnologías de código abierto. Para obtener más información, consulte el sitio web de las preguntas más frecuentes de soporte técnico de Azure. Además, el servicio HDInsight ofrece un nivel adicional de soporte técnico para los componentes incorporados.
Hay dos tipos de componentes de código abierto que están disponibles en el servicio de HDInsight:
| Componente | Descripción |
|---|---|
| Integrada | Estos componentes están instalados previamente en clústeres de HDInsight y proporcionan la funcionalidad básica del clúster. Por ejemplo, el administrador de recursos de Apache Hadoop YARN, el lenguaje de consulta de Apache Hive (HiveQL) y la biblioteca Mahout pertenecen a esta categoría. Hay una lista completa de componentes del clúster disponible en Novedades en las versiones de clústeres de Apache Hadoop proporcionadas por HDInsight. |
| Personalizado | Como usuario del clúster, puede instalar o usar en la carga de trabajo cualquier componente disponible en la comunidad o que haya creado personalmente. |
Importante
Los componentes proporcionados con el clúster de HDInsight son totalmente compatibles. Soporte técnico de Microsoft ayuda a aislar y a solucionar problemas relacionados con estos componentes.
Los componentes personalizados reciben soporte técnico comercialmente razonable para ayudarle a solucionar el problema. El soporte técnico de Microsoft podría resolver el problema O pedirle que aborde los canales disponibles para las tecnologías de código abierto donde se encuentra la más amplia experiencia para esa tecnología. Por ejemplo, hay diversos sitios de la comunidad que se pueden usar, como la página de preguntas de Microsoft Q&A sobre HDInsight, https://stackoverflow.com. Los proyectos de Apache también tienen sitios de proyecto en https://apache.org.
Descripción de la instalación predeterminada de Python
El clúster de HDInsight Spark tienen Anaconda instalado. Hay dos instalaciones de Python en el clúster: Anaconda Python 2.7 y Python 3.5 En la tabla siguiente se muestra la configuración predeterminada de Python para Spark, Livy y Jupyter.
| Configuración | Python 2.7 | Python 3.5 |
|---|---|---|
| Path | /usr/bin/anaconda/bin | /usr/bin/anaconda/envs/py35/bin |
| Versión de Spark | Valor predeterminado establecido en 2.7 | Puede cambiar la configuración a 3.5. |
| Versión de Livy | Valor predeterminado establecido en 2.7 | Puede cambiar la configuración a 3.5. |
| Jupyter | Kernel de PySpark | Kernel de PySpark3 |
Para la versión 3.1.2 de Spark, se ha eliminado el kernel de Apache PySpark y se ha instalado un nuevo entorno de Python 3.8 en /usr/bin/miniforge/envs/py38/bin, que el kernel de PySpark3 utiliza. Las variables de entorno PYSPARK_PYTHON y PYSPARK3_PYTHON se actualizan con lo siguiente:
export PYSPARK_PYTHON=${PYSPARK_PYTHON:-/usr/bin/miniforge/envs/py38/bin/python}
export PYSPARK3_PYTHON=${PYSPARK_PYTHON:-/usr/bin/miniforge/envs/py38/bin/python}
Instalación segura de paquetes externos de Python
El clúster de HDInsight depende del entorno integrado de Python, tanto Python 2.7 como Python 3.5. La instalación directa de paquetes personalizados en esos entornos integrados predeterminados puede producir cambios inesperados en la versión de la biblioteca y generar más interrupciones en el clúster. Para instalar de forma segura paquetes externos personalizados de Python para las aplicaciones de Spark, siga los pasos.
Cree un entorno virtual de Python mediante Conda. Un entorno virtual proporciona un espacio aislado para sus proyectos sin interrumpir otros. Al crear el entorno virtual de Python, puede especificar la versión de Python que quiere usar. Sin embargo, seguirá siendo necesario crear el entorno virtual, aunque quiera usar Python 2.7 y 3.5. Este requisito tiene como fin asegurarse de que no se interrumpa el entorno predeterminado del clúster. Ejecute las acciones de script en el clúster para todos los nodos con el siguiente script para crear un entorno virtual de Python.
--prefixespecifica una ruta de acceso donde reside un entorno virtual de Conda. Hay varias configuraciones que deben seguirse cambiando en función de la ruta de acceso especificada aquí. En este ejemplo, usamos py35new, ya que el clúster tiene un entorno virtual existente denominado py35.python=especifica la versión de Python para el entorno virtual. En este ejemplo, usamos la versión 3.5, la misma versión que el clúster creado anteriormente. También puede usar otras versiones de Python para crear el entorno virtual.anacondaespecifica el package_spec como anaconda para instalar paquetes de Anaconda en el entorno virtual.
sudo /usr/bin/anaconda/bin/conda create --prefix /usr/bin/anaconda/envs/py35new python=3.5 anaconda=4.3 --yesInstale los paquetes externos de Python en el entorno virtual creado si es necesario. Ejecute las acciones de script en el clúster para todos los nodos con el siguiente script para instalar los paquetes externos de Python. Debe tener el privilegio sudo aquí para escribir archivos en la carpeta del entorno virtual.
Buscar en el índice de paquetes la lista completa de paquetes que están disponibles. También puede obtener una lista de paquetes disponibles de otras fuentes. Por ejemplo, puede instalar paquetes que están disponibles a través de conda-forge.
Use el comando siguiente si quiere instalar una biblioteca en su versión más reciente:
Usar el canal de Conda:
seabornes el nombre del paquete que desea instalar.-n py35newespecifica el nombre del entorno virtual que acaba de crearse. Asegúrese de cambiar el nombre correspondiente en función de la creación del entorno virtual.
sudo /usr/bin/anaconda/bin/conda install seaborn -n py35new --yesO bien use el repositorio de PyPi y cambie
seabornypy35newsegún corresponda:sudo /usr/bin/anaconda/envs/py35new/bin/pip install seaborn
Use el comando siguiente si quiere instalar una biblioteca con una versión específica:
Usar el canal de Conda:
numpy=1.16.1es el nombre y la versión del paquete que quiere instalar.-n py35newespecifica el nombre del entorno virtual que acaba de crearse. Asegúrese de cambiar el nombre correspondiente en función de la creación del entorno virtual.
sudo /usr/bin/anaconda/bin/conda install numpy=1.16.1 -n py35new --yesO bien use el repositorio de PyPi y cambie
numpy==1.16.1ypy35newsegún corresponda:sudo /usr/bin/anaconda/envs/py35new/bin/pip install numpy==1.16.1
Si no conoce el nombre del entorno virtual, puede utilizar SSH en el nodo de encabezado del clúster y ejecutar
/usr/bin/anaconda/bin/conda info -epara mostrar todos los entornos virtuales.Cambie las configuraciones de Spark y Livy, y apunte al entorno virtual creado.
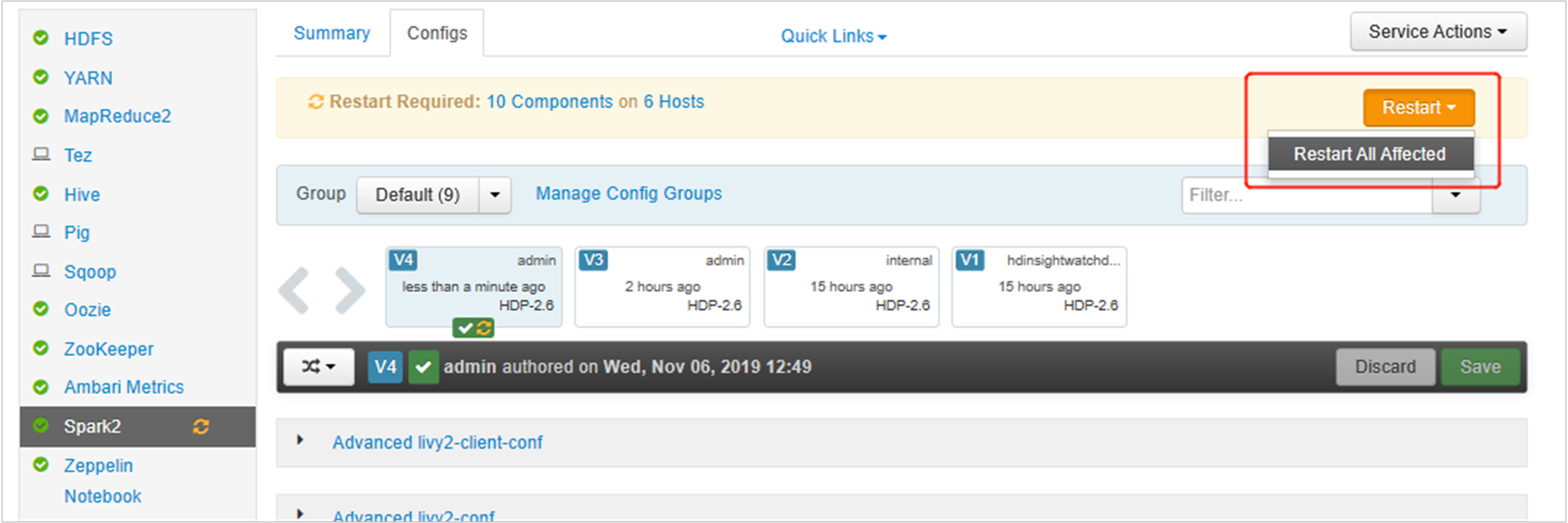
Abra la interfaz de usuario de Ambari, vaya a la página Spark2, pestaña Configuraciones.
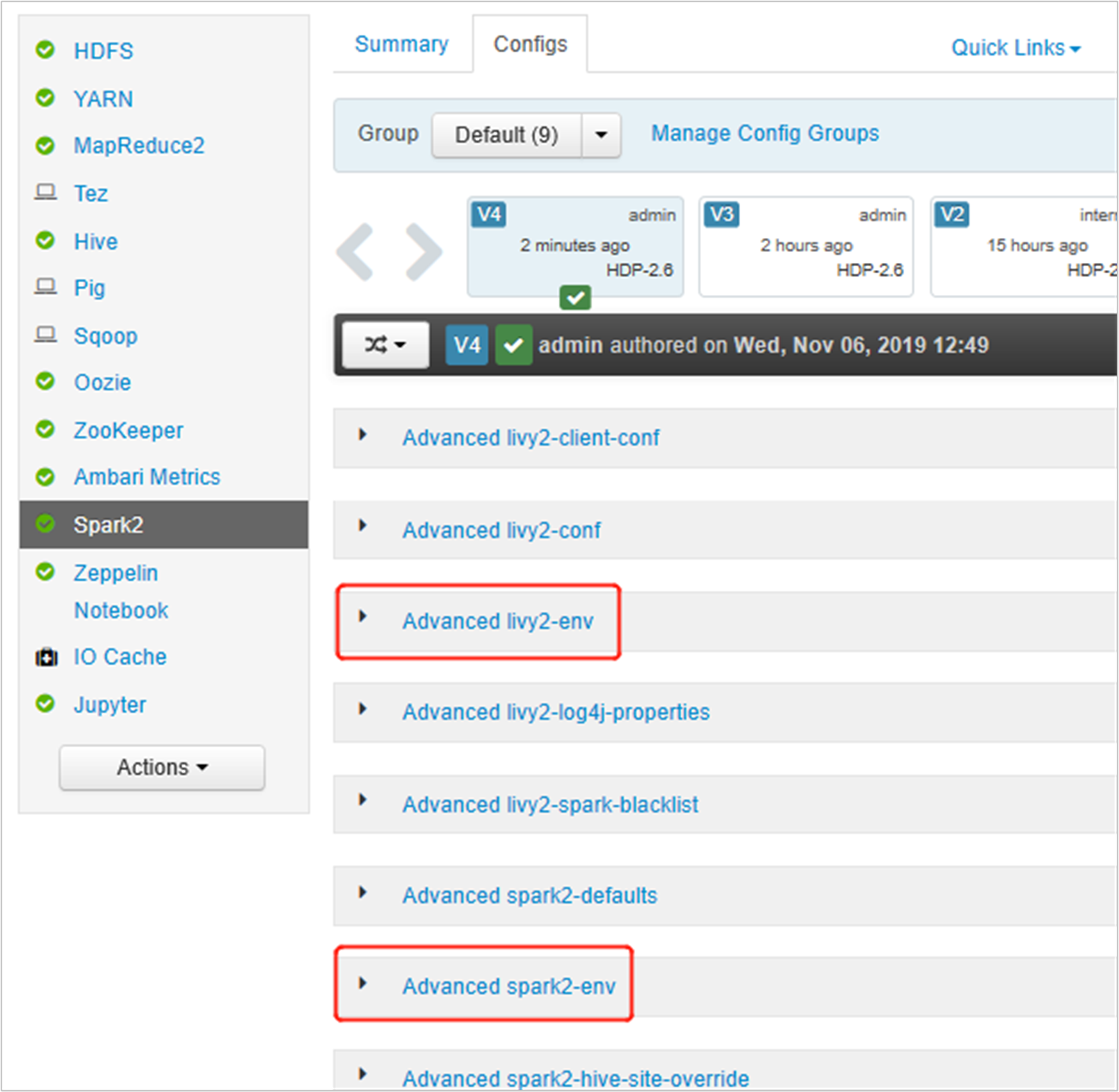
Expanda Advanced livy2-env y agregue las siguientes instrucciones al final. Si instaló el entorno virtual con otro prefijo, cambie la ruta de acceso correspondiente.
export PYSPARK_PYTHON=/usr/bin/anaconda/envs/py35new/bin/python export PYSPARK_DRIVER_PYTHON=/usr/bin/anaconda/envs/py35new/bin/python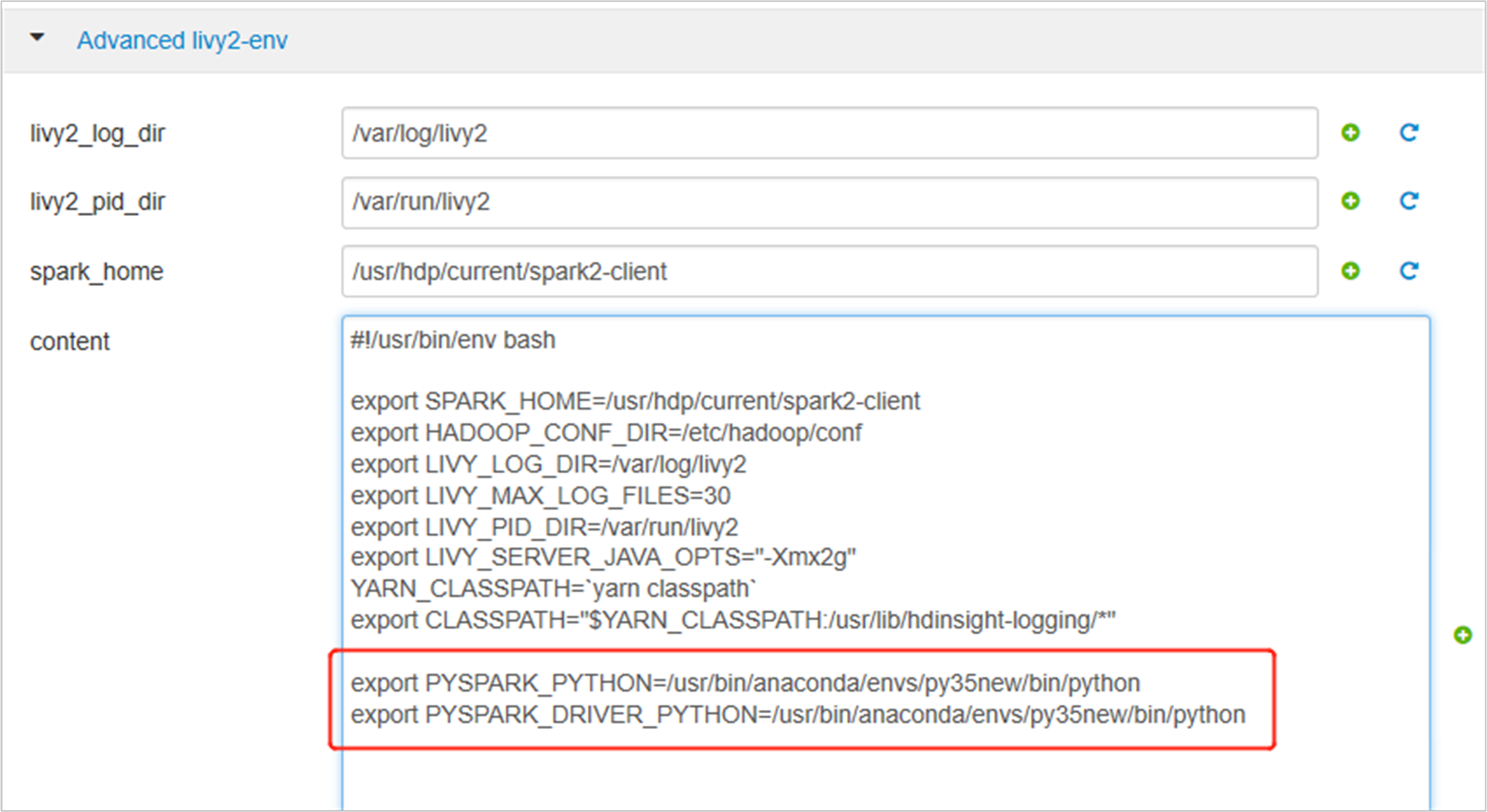
Expanda Advanced spark2-env y reemplace la instrucción de exportación PYSPARK_PYTHON existente al final. Si instaló el entorno virtual con otro prefijo, cambie la ruta de acceso correspondiente.
export PYSPARK_PYTHON=${PYSPARK_PYTHON:-/usr/bin/anaconda/envs/py35new/bin/python}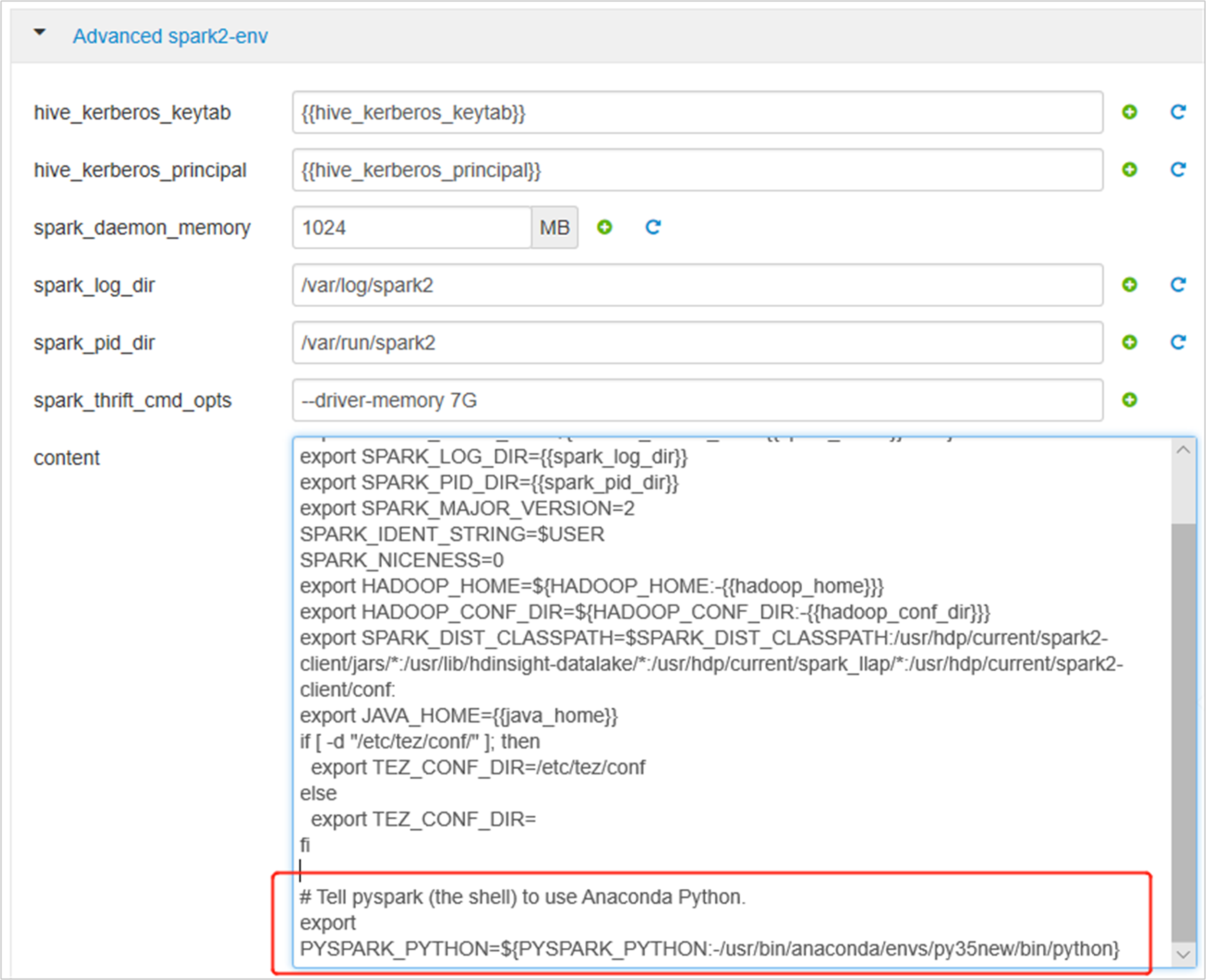
Guarde los cambios y reinicie los servicios afectados. Estos cambios necesitan el reinicio del servicio Spark2. La UI de Ambari le mostrará un aviso de reinicio obligatorio, haga clic en Restart para reiniciar todos los servicios afectados.
Establezca dos propiedades en la sesión de Spark para asegurarse de que el trabajo apunte a la configuración de Spark actualizada:
spark.yarn.appMasterEnv.PYSPARK_PYTHONyspark.yarn.appMasterEnv.PYSPARK_DRIVER_PYTHON.Mediante el terminal o un cuaderno, utilice la función
spark.conf.set.spark.conf.set("spark.yarn.appMasterEnv.PYSPARK_PYTHON", "/usr/bin/anaconda/envs/py35/bin/python") spark.conf.set("spark.yarn.appMasterEnv.PYSPARK_DRIVER_PYTHON", "/usr/bin/anaconda/envs/py35/bin/python")Si usa
livy, agregue las siguientes propiedades al cuerpo de la solicitud:"conf" : { "spark.yarn.appMasterEnv.PYSPARK_PYTHON":"/usr/bin/anaconda/envs/py35/bin/python", "spark.yarn.appMasterEnv.PYSPARK_DRIVER_PYTHON":"/usr/bin/anaconda/envs/py35/bin/python" }
Si desea usar el nuevo entorno virtual creado en Jupyter, cambie las configuraciones de Jupyter y reinicie Jupyter. Ejecute las acciones de script en todos los nodos de encabezado con la siguiente instrucción para apuntar Jupyter al nuevo entorno virtual creado. Asegúrese de modificar la ruta de acceso al prefijo que especificó para el entorno virtual. Después de ejecutar esta acción de script, reinicie el servicio de Jupyter a través de la UI de Ambari para que este cambio esté disponible.
sudo sed -i '/python3_executable_path/c\ \"python3_executable_path\" : \"/usr/bin/anaconda/envs/py35new/bin/python3\"' /home/spark/.sparkmagic/config.jsonPuede volver a confirmar el entorno de Python en Jupyter Notebook ejecutando el código: