Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Un clúster de HDInsight Spark incluye una instalación de la biblioteca de Apache Spark. Cada clúster de HDInsight incluye parámetros de configuración predeterminados para todos sus servicios instalados, incluido Spark. Un aspecto clave de la administración de un clúster de HDInsight Apache Hadoop es la supervisión de la carga de trabajo, lo que incluye los trabajos de Spark. Para ejecutar mejor los trabajos de Spark, considere la configuración física del clúster al determinar la configuración lógica del clúster.
El clúster de HDInsight Apache Spark predeterminado incluye los siguientes nodos: tres nodos de Apache ZooKeeper, dos nodos principales y uno o más nodos de trabajo:
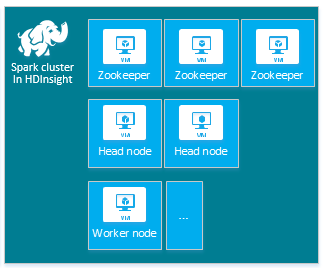
El número de máquinas virtuales y el tamaño de las máquinas virtuales, para los nodos del clúster de HDInsight, pueden afectar a la configuración de Spark. Los valores de la configuración HDInsight no predeterminados a menudo requieren valores de configuración de Spark no predeterminados. Al crear un clúster de HDInsight Spark, se muestran los tamaños sugeridos de la máquina virtual para cada uno de los componentes. Actualmente los tamaños de la máquina virtual Linux optimizado para memoria para Azure son D12 v2 o posterior.
Versiones de Apache Spark
Utilice la mejor versión de Spark para el clúster. El servicio HDInsight incluye varias versiones tanto de Spark como del propio HDInsight. Cada versión de Spark incluye un conjunto de configuración de clúster predeterminadas.
Al crear un clúster nuevo, puede elegir entre varias versiones de Spark. Para ver la lista completa, consulte Componentes y versiones de HDInsight.
Nota
La versión predeterminada de Apache Spark en el servicio HDInsight puede cambiar sin previo aviso. Microsoft recomienda especificar la versión particular al crear clústeres con el .NET SDK, Azure PowerShell y la CLI de Azure clásica, si tiene una dependencia de versiones.
Apache Spark cuenta con tres ubicaciones de configuración del sistema:
- Las propiedades de Spark controlan la mayoría de los parámetros de la aplicación y se pueden establecer mediante el uso de un objeto
SparkConfo a través de las propiedades del sistema de Java. - Se pueden utilizar variables de entorno para establecer la configuración por máquina, como la dirección IP, a través del script
conf/spark-env.shen cada nodo. - Puede configurar el registro mediante
log4j.properties.
Al seleccionar una versión concreta de Spark, el clúster incluye las opciones de configuración predeterminadas. Para los valores predeterminados de la configuración de Spark, utilice un archivo de configuración personalizado de Spark. A continuación se muestra un ejemplo.
spark.hadoop.io.compression.codecs org.apache.hadoop.io.compress.GzipCodec
spark.hadoop.mapreduce.input.fileinputformat.split.minsize 1099511627776
spark.hadoop.parquet.block.size 1099511627776
spark.sql.files.maxPartitionBytes 1099511627776
spark.sql.files.openCostInBytes 1099511627776
El ejemplo mostrado antes reemplaza varios valores predeterminados en cinco parámetros de configuración de Spark. Estos valores son el códec de compresión, el tamaño mínimo de división de MapReduce de Apache Hadoop y los tamaños de bloques de Parquet, Así como la partición de Spark SQL y los valores predeterminados de los tamaños de los archivos abiertos. Estos cambios de configuración se eligen porque los datos y trabajos asociados (en este ejemplo, los datos genómicos) tienen características concretas. Estas características se ejecutarán mejor con estos valores de configuración personalizados.
Visualización de las opciones de configuración del clúster
Compruebe las opciones de configuración actuales del clúster de HDInsight antes de realizar la optimización del rendimiento en el clúster. Para iniciar el panel de HDInsight desde Azure Portal, haga clic en el vínculo Panel en el panel del clúster de Spark. Inicie sesión con el nombre de usuario y la contraseña del administrador del clúster.
Aparece la interfaz de usuario web de Apache Ambari, con un panel de las principales métricas de uso de los recursos del clúster. El panel de Ambari muestra la configuración de Apache Spark y otros servicios instalados. El panel incluye una pestaña con el historial de configuración, donde puede ver información de los servicios instalados, incluido Spark.
Para ver los valores de configuración de Apache Spark, seleccione Config History (Historial de configuración) y, después, seleccione Spark2. Seleccione la pestaña Configs (Configuraciones) y, después, seleccione el vínculo Spark (o Spark2, dependiendo de la versión) en la lista de servicios. Verá una lista de valores de configuración para el clúster:
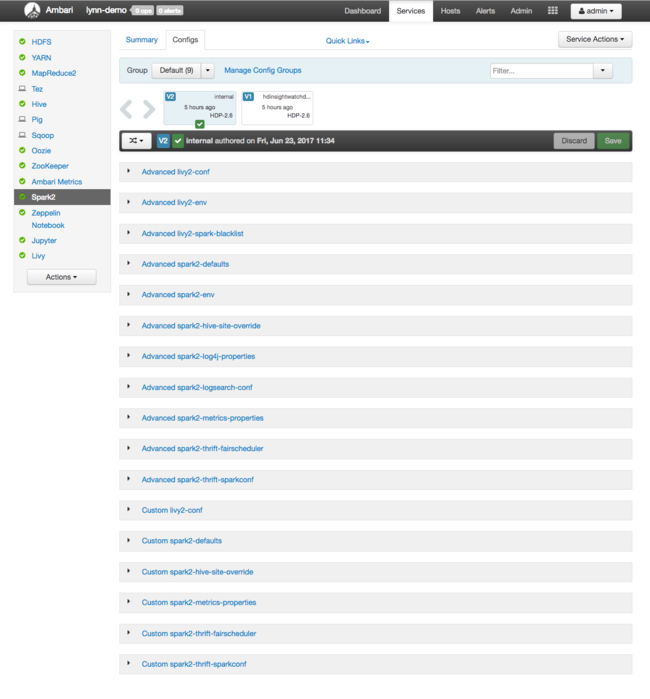
Para ver y cambiar los valores de configuración individuales de Spark, seleccione cualquier vínculo con la palabra "spark" en el título. Las configuraciones para Spark incluyen tanto valores de configuración personalizados como avanzados en estas categorías:
- Custom Spark2-defaults
- Custom Spark2-metrics-properties
- Advanced Spark2-defaults
- Advanced Spark2-env
- Advanced spark2-hive-site-override
Si crea un conjunto de valores de configuración no predeterminado, el historial de actualizaciones será visible. Este historial de configuración puede ser útil para ver qué configuración no predeterminada tiene un rendimiento óptimo.
Nota
Para ver, pero no cambiar, los valores comunes de configuración del clúster de Spark, seleccione la pestaña Environment (Entorno) en la interfaz Spark Job UI de nivel superior.
Configuración de los ejecutores de Spark
El diagrama siguiente muestra los principales objetos de Spark: el programa del controlador y su contexto de Spark asociado, y el administrador del clúster y sus n nodos de trabajo. Cada uno de estos nodos incluye un Ejecutor, una cache y n instancias de tarea.
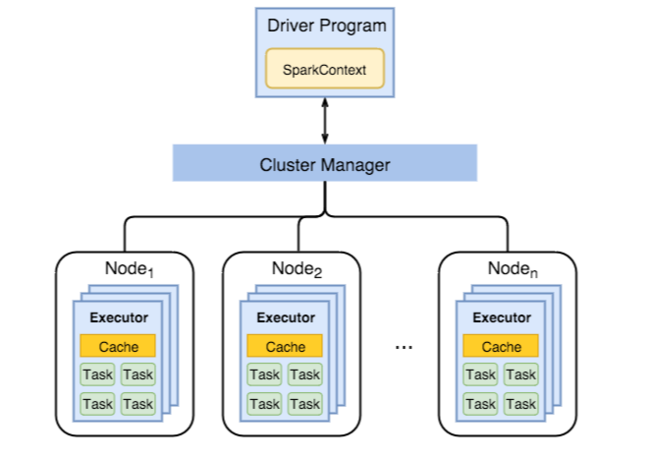
Los trabajos de Spark utilizan los recursos del nodo de trabajo, en particular la memoria, por lo que es común ajustar los valores de configuración de Spark para los ejecutores de los nodos de trabajo.
Tres parámetros clave que a menudo se ajustan para optimizar las configuraciones de Spark para mejorar los requisitos de la aplicación son spark.executor.instances, spark.executor.cores y spark.executor.memory. Un ejecutor es un proceso que se inicia para una aplicación Spark. Un ejecutor se ejecuta en el nodo de trabajo y es responsable de realizar las tareas de la aplicación. El número de nodos de trabajo y el tamaño de los nodos de trabajo determinan el número de ejecutores y los tamaños de los ejecutores. Estos valores se almacenan en spark-defaults.conf en los nodos principales del clúster. Puede modificar estos valores en un clúster en ejecución si selecciona Custom spark-defaults (spark-defaults personalizado) en la interfaz de usuario web de Ambari. Después de realizar cambios, la interfaz de usuario le solicitará que reinicie todos los servicios afectados.
Nota
Estos tres parámetros de configuración se pueden configurar en el nivel de clúster (para todas las aplicaciones que se ejecutan en el clúster) y especificar también para cada aplicación individual.
Otra fuente de información sobre los recursos que utilizan los ejecutores de Spark es la interfaz de usuario de la aplicación de Spark. En la interfaz de usuario, Ejecutores muestra las vistas de resumen y detalles de la configuración y los recursos consumidos. Determine si desea cambiar los valores de los ejecutores para todo el clúster o para un conjunto determinado de ejecuciones de trabajos.
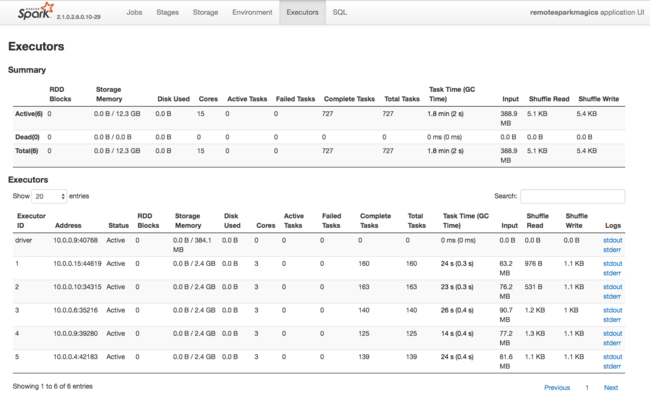
También puede usar la API REST de Ambari para comprobar mediante programación los valores de configuración del clúster de HDInsight y Spark. Hay disponible más información en la referencia de la API de Apache Ambari en GitHub.
En función de la carga de trabajo de Spark, puede determinar que una configuración de Spark no predeterminada proporcione ejecuciones de trabajos de Spark más optimizadas. Realice pruebas comparativas con cargas de trabajo de ejemplo para validar las configuraciones de clúster no predeterminadas. Algunos de los parámetros comunes que puede considerar ajustar son:
| Parámetro | Descripción |
|---|---|
| --num-executors | Establece el número de ejecutores. |
| --executor-cores | Establece el número de núcleos para cada ejecutor. Le recomendamos usar ejecutores de tamaño medio, ya que otros procesos consumen también parte de la memoria disponible. |
| --executor-memory | Controla el tamaño de la memoria (tamaño del montón) de cada ejecutor en Apache Hadoop YARN. Deberá dejar algo de memoria para la sobrecarga de ejecución. |
Este es un ejemplo de dos nodos de trabajo con diferentes valores de configuración:

La siguiente lista muestra los parámetros clave de la memoria del ejecutor de Spark.
| Parámetro | Descripción |
|---|---|
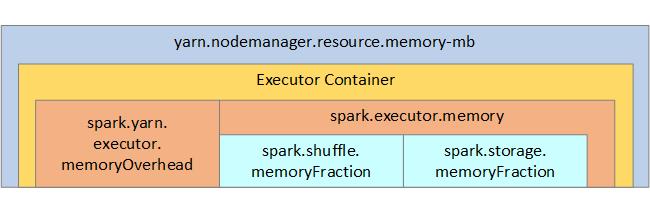
| spark.executor.memory | Define la cantidad total de memoria disponible para un ejecutor. |
| spark.storage.memoryFraction | Define la cantidad de memoria disponible para almacenar RDD persistentes (valor predeterminado del 60 % aproximadamente). |
| spark.shuffle.memoryFraction | Define la cantidad de memoria reservada para el orden aleatorio (valor predeterminado del 20 % aproximadamente). |
| spark.storage.unrollFraction y spark.storage.safetyFraction | Estos valores los utiliza internamente Spark y no deben cambiarse (suman un total del 30 % del total de memoria aproximadamente). |
YARN controla la suma máxima de memoria que usan los contenedores en cada nodo de Spark. En el siguiente diagrama se muestran las relaciones por nodos entre objetos de configuración de YARN y objetos de Spark.
Cambio de los parámetros de una aplicación que se ejecuta en un cuaderno de Jupyter Notebook
Los clústeres de Spark en HDInsight incluyen un número de componentes de forma predeterminada. Cada uno de estos componentes incluyen unos valores de configuración predeterminados que se pueden reemplazar según sea necesario.
| Componente | Descripción |
|---|---|
| Spark Core | Spark Core, Spark SQL, API de Spark Streaming, GraphX y Apache Spark MLlib. |
| Anaconda | Un administrador de paquetes de Python. |
| Apache Livy | API REST de Apache Spark que se usa para enviar trabajos remotos a un clúster Spark de HDInsight. |
| Cuadernos de Jupyter Notebook y Apache Zeppelin | Interfaz de usuario interactiva basada en explorador para interactuar con el clúster de Spark. |
| Controlador ODBC | Conecta clústeres de Spark en HDInsight con herramientas de inteligencia empresarial (BI), como Microsoft Power BI y Tableau. |
Para las aplicaciones que se ejecutan en un cuaderno de Jupyter Notebook, puede utilizar el comando %%configure para realizar los cambios de configuración dentro del mismo cuaderno. Estos cambios de configuración se aplicarán a la ejecución de trabajos de Spark desde la instancia del cuaderno. Realice estos cambios al comienzo de la aplicación, antes de ejecutar la primera celda de código. La configuración modificada se aplica a la sesión de Livy cuando esta se cree.
Nota
Para cambiar la configuración en una fase posterior de la aplicación, debe utilizar el parámetro -f (force). Sin embargo, se perderá todo el progreso en la aplicación.
El código siguiente muestra cómo cambiar la configuración de una aplicación que se ejecuta en un cuaderno de Jupyter Notebook.
%%configure
{"executorMemory": "3072M", "executorCores": 4, "numExecutors":10}
Conclusión
Supervise valores de configuración básicos para garantizar que los trabajos de Spark se ejecuten de forma predecible y eficaz. Estas opciones ayudan a determinar la mejor configuración del clúster de Spark para las cargas de trabajo determinadas. También debe supervisar la ejecución de los trabajos de Spark de larga duración o que consumen recursos. Las mayores dificultades están relacionadas con la presión en la memoria debido a configuraciones inadecuadas, como un tamaño incorrecto de los ejecutores, así como operaciones de ejecución prolongada y tareas que dan lugar a operaciones cartesianas.