Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Apache Spark Streaming permite implementar aplicaciones escalables, de alto rendimiento y tolerancia a errores para el procesamiento de flujos de datos. Puede conectar las aplicaciones de Spark Streaming en un clúster de HDInsight Spark a diferentes tipos de orígenes de datos, como Azure Event Hubs, Azure IoT Hub, Apache Kafka, Apache Flume, Twitter, ZeroMQ, sockets TCP sin formato o bien, mediante la supervisión del sistema de archivos HDFS de Apache Hadoop en busca de cambios. Spark Streaming admite la tolerancia a errores con la garantía de que cualquier evento se procesa exactamente una vez, incluso con un error de nodo.
Spark Streaming crea trabajos de ejecución prolongada durante los cuales se pueden aplicar transformaciones a los datos y después insertar los resultados en sistemas de archivos, bases de datos, paneles y en la consola. Spark Streaming procesa microlotes de datos al recopilar primero un lote de eventos durante un intervalo de tiempo definido. A continuación, ese lote se envía para su procesamiento y salida. Los intervalos de tiempo de los lotes se definen normalmente en fracciones de segundo.

DStreams
Spark Streaming representa un flujo continuo de datos que utiliza un flujo discretizado (DStream). Este flujo DStream se puede crear a partir de orígenes de entrada, como Event Hubs o Kafka, o bien aplicando transformaciones a otro flujo DStream. Cuando este evento llega a la aplicación de Spark Streaming, se almacena de forma confiable. Es decir, los datos del evento se replican para que varios nodos tengan una copia de él. Esto garantiza que un error de un solo nodo no provocará la pérdida del evento.
El núcleo de Spark utiliza los conjuntos de datos distribuidos resistentes (RDD). Estos conjuntos de datos distribuyen los datos en varios nodos del clúster, donde cada nodo suele mantener sus datos completamente en memoria para garantizar un rendimiento óptimo. Cada conjunto de datos distribuido resistente representa los eventos recopilados en un intervalo de lote. Cuando transcurre el intervalo de lote, Spark Streaming produce un nuevo conjunto de datos distribuido resistente que contiene todos los datos en ese intervalo. Este conjunto continuo de datos distribuidos resistentes se recopila en un flujo DStream. Una aplicación de Spark Streaming procesa los datos almacenados en el RDD de cada lote.

Trabajos de Spark Structured Streaming
Spark Structured Streaming se introdujo en Spark 2.0 como un motor de análisis para su uso en la transmisión de datos estructurados. Spark Structured Streaming utiliza las API de motor de procesamiento por lotes de SparkSQL. Al igual que Spark Streaming, Spark Structured Streaming ejecuta sus cálculos sobre microlotes de datos que llegan continuamente. Spark Structured Streaming representa el flujo de datos como una tabla de entrada con filas ilimitadas. Es decir, la tabla de entrada sigue aumentando conforme llegan datos nuevos. Esta tabla de entrada se procesa continuamente mediante una consulta de ejecución prolongada y los resultados se escriben en una tabla de salida.
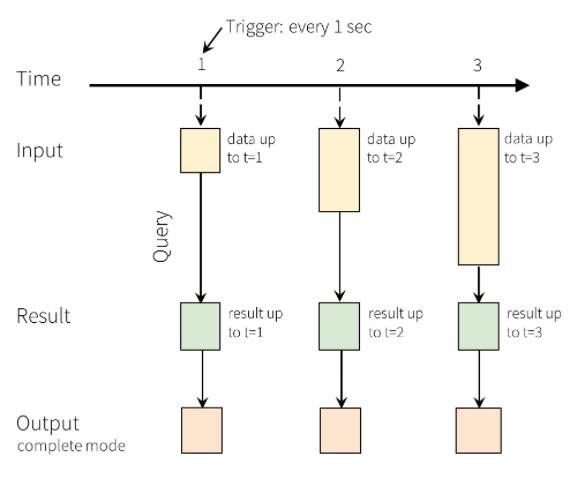
En Structured Streaming, los datos llegan al sistema y se ingieren de inmediato en la tabla de entrada. Las consultas que realizan operaciones se escriben en esta tabla de entrada. La salida de la consulta produce otra tabla, llamada Tabla de resultados. La tabla de resultados contiene los resultados de la consulta, a partir de la cual se extraen datos para enviarlos a un almacén de datos externo, como una base de datos relacional. El intervalo de desencadenador establece el momento en el que se procesan los datos desde la tabla de entrada. De forma predeterminada, Structured Streaming procesa los datos tan pronto como llegan. Sin embargo, también puede configurar el desencadenador para que se ejecute en un intervalo más prolongado, de modo que los datos de streaming se procesen en lotes temporales. Los datos de la tabla de resultados pueden actualizarse cada vez que haya nuevos datos, de modo que incluyan todos los datos de salida desde el inicio de la consulta de streaming (modo completo) o solo puede contener los datos nuevos desde la última vez que se procesó la consulta (modo de anexión).
Creación de trabajos de Spark Streaming con tolerancia a errores
Para crear un entorno de alta disponibilidad para sus trabajos de Spark Streaming, empiece por codificar sus trabajos individuales para su recuperación en caso de error. Estos trabajos de recuperación automática toleran errores.
Los RDD tienen varias propiedades que ayudan a los trabajos de Spark Streaming altamente disponibles y tolerantes a errores:
- Los lotes de datos de entrada almacenados en RDD como DStream se replican automáticamente en memoria para una tolerancia a errores.
- Los datos perdidos debido a un error de trabajo pueden volver a procesarse a partir de datos de entrada replicados en diferentes trabajos, siempre y cuando esos nodos de trabajo estén disponibles.
- La recuperación rápida de errores puede ocurrir en un segundo, ya que la recuperación de errores o incidencias ocurre mediante el cálculo en memoria.
Semántica del tipo "exactamente una vez" con Spark Streaming
Para crear una aplicación que procese cada evento una vez (y solo una vez), considere cómo se reinician todos los puntos de error del sistema después de tener un problema y cómo se puede evitar la pérdida de datos. La semántica de tipo "exactamente una vez" requiere que no se pierda ningún dato en ningún punto y que el procesamiento de mensajes se pueda reiniciar, con independencia del lugar donde ocurra el error. Consulte Creación de trabajos de Spark Streaming con el procesamiento de eventos de tipo "exactamente una vez".
Spark Streaming y Apache Hadoop YARN
En HDInsight, el trabajo de clústeres se coordina con Yet Another Resource Negotiator (YARN). El diseño de alta disponibilidad para Spark Streaming incluye técnicas para Spark Streaming y también para los componentes de YARN. A continuación se muestra un ejemplo de configuración que utiliza YARN.
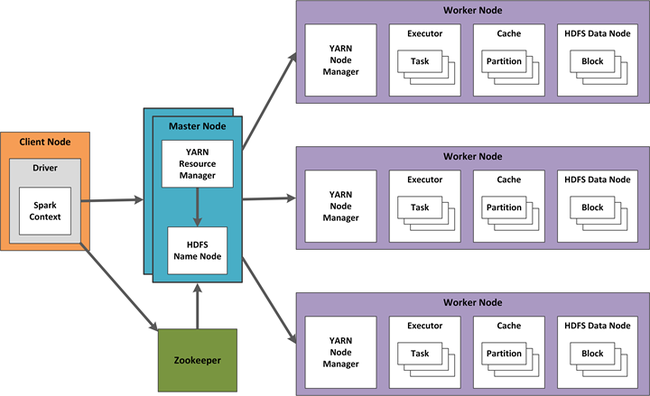
Las secciones siguientes describen las consideraciones de diseño para esta configuración.
Planear la detección de errores
Para crear una configuración YARN para alta disponibilidad, debe planear un posible error del controlador o del ejecutor. Algunos trabajos de Spark Streaming también incluyen requisitos de garantía de datos que requieren instalación y configuración adicionales. Por ejemplo, una aplicación de streaming puede tener un requisito de negocio para una garantía de que no haya pérdidas de datos a pesar de cualquier error que tenga lugar en el sistema de streaming del hospedaje o en el clúster de HDInsight.
Si un ejecutor produce un error, Spark reinicia automáticamente sus tareas y receptores, por lo que no es necesario ningún cambio de configuración.
Sin embargo, si un controlador produce un error, todos sus ejecutores asociados producirán un error, y todos los bloques recibidos y resultados de proceso se perderán. Para recuperarse de un error del controlador, utilice la creación de puntos de comprobación de DStream, tal como se describe en Creación de trabajos de Spark Streaming con el procesamiento de eventos de tipo "exactamente una vez". La creación de puntos de comprobación de DStream guarda periódicamente el grafo acíclico dirigido (DAG) de DStreams en un almacenamiento tolerante a errores, como Azure Storage. La creación de puntos de comprobación permite que Spark Structured Streaming reinicie el controlador erróneo a partir de la información del punto de comprobación. El reinicio del controlador lanza nuevos ejecutores y también reinicia receptores.
Para recuperar controladores con la creación de puntos de comprobación de DStream:
Configure el reinicio del controlador automático en YARN con la opción de configuración
yarn.resourcemanager.am.max-attempts.Establezca un directorio de punto de comprobación en un sistema de archivos compatible con HDFS con
streamingContext.checkpoint(hdfsDirectory).Reestructure el código fuente para usar puntos de comprobación para la recuperación, por ejemplo:
def creatingFunc() : StreamingContext = { val context = new StreamingContext(...) val lines = KafkaUtils.createStream(...) val words = lines.flatMap(...) ... context.checkpoint(hdfsDir) } val context = StreamingContext.getOrCreate(hdfsDir, creatingFunc) context.start()Configure la recuperación de datos perdidos mediante la habilitación del registro de escritura previa con
sparkConf.set("spark.streaming.receiver.writeAheadLog.enable","true")y deshabilite la replicación en memoria para los flujos DStreams de entrada conStorageLevel.MEMORY_AND_DISK_SER.
Para resumir, con los puntos de comprobación + el registro de escritura previa + receptores confiables, podrá entregar una recuperación de datos "al menos una vez":
- Exactamente una vez, siempre y cuando no se pierdan los datos recibidos y las salidas sean idempotentes o transaccionales.
- Exactamente una vez, con el nuevo enfoque de Kafka Direct que usa Kafka como un registro replicado, en lugar de utilizar receptores o registros de escritura previa.
Preocupaciones típicas de alta disponibilidad
Es más difícil supervisar los trabajos de streaming que los trabajos por lotes. Los trabajos de Spark Streaming son normalmente de ejecución prolongada y YARN no agrega registros hasta que termina un trabajo. Los puntos de comprobación de Spark se pierden durante las actualizaciones de la aplicación o de Spark, y tendrá que borrar el directorio de puntos de comprobación durante una actualización.
Configure el modo de clúster de YARN para ejecutar los controladores, incluso si se produce un error en un cliente. Para configurar el reinicio automático en los controladores:
spark.yarn.maxAppAttempts = 2 spark.yarn.am.attemptFailuresValidityInterval=1hSpark y la interfaz de usuario de Spark Streaming tienen un sistema de métricas configurable. También puede utilizar bibliotecas adicionales, como Graphite/Grafana para descargar métricas de panel como "número de registros procesados", "uso de memoria/GC en el controlador y ejecutores", "retardo total" y "uso del clúster", entre otras. En Structured Streaming versión 2.1 o posterior, puede usar
StreamingQueryListenerpara recopilar métricas adicionales.Debe segmentar los trabajos de ejecución prolongada. Cuando una aplicación de Spark Streaming se envía al clúster, debe definirse la cola de YARN donde se ejecuta el trabajo. Puede usar YARN Capacity Scheduler para enviar trabajos de ejecución prolongada para separar colas.
Cierre correctamente la aplicación de streaming. Si se conocen los desplazamientos y todos los estados de la aplicación se almacenan externamente, puede detener mediante programación la aplicación de streaming en el lugar apropiado. Una técnica consiste en utilizar "enlaces de subproceso" en Spark, mediante la comprobación de un indicador externo cada n segundos. También puede usar un archivo de marcador que se creó en HDFS al iniciar la aplicación y, después, quitarlo cuando desee realizar la detención. Para obtener un enfoque de archivo de marcador, use un subproceso independiente en la aplicación de Spark que llame al código de forma similar a la siguiente:
streamingContext.stop(stopSparkContext = true, stopGracefully = true) // to be able to recover on restart, store all offsets in an external database
Pasos siguientes
- Introducción a Apache Spark Streaming
- Creación de trabajos de Apache Spark Streaming con el procesamiento de eventos de tipo "exactamente una vez"
- Long-running Apache Spark Streaming Jobs on YARN (Trabajos de Apache Spark Streaming de larga duración en YARN)
- Structured Streaming: Fault Tolerant Semantics (Structured Streaming: semántica tolerante a errores)
- Discretized Streams: A Fault-Tolerant Model for Scalable Stream Processing (Flujos discretizados: modelo tolerante a errores para el procesamiento de flujo escalable)