Información general acerca de Apache Spark Structured Streaming
Apache Spark Structured Streaming permite implementar aplicaciones escalables, de alto rendimiento y tolerantes a errores para el procesamiento de flujos de datos. Structured Streaming se basa en el motor de Spark SQL y mejora las construcciones de las tramas de datos y los conjuntos de datos de Spark SQL, lo que permite escribir consultas de streaming de la misma manera que se escribirían las consultas por lotes.
Las aplicaciones de Structured Streaming se ejecutan en clústeres de HDInsight Spark y se conectan a los datos de streaming de Apache Kafka, un socket de TCP (para la depuración), Azure Storage o Azure Data Lake Storage. Las dos últimas opciones, que usan servicios de almacenamiento externo, permiten inspeccionar los nuevos archivos agregados al almacenamiento y procesar su contenido como si se transmitieran en secuencias.
El flujo estructurado crea una consulta de larga ejecución durante la que se aplican operaciones a los datos de entrada, como las de selección, proyección, agregación, división en periodos de tiempo y la combinación de marcos de datos de streaming con marcos de datos de referencia. A continuación, se generan los resultados en el almacenamiento de archivos (Azure Storage Blob o Data Lake Storage) o en cualquier almacén de datos mediante el uso de código personalizado (como SQL Database o Power BI). Structured Streaming también proporciona salida a la consola para su depuración local y a una tabla en memoria para que se puedan ver los datos generados para la depuración en HDInsight.

Nota:
Spark Structured Streaming va a reemplazar a Spark Streaming (DStreams). En el futuro, Structured Streaming recibirá mejoras y el mantenimiento, mientras que DStreams estará solo en modo de mantenimiento. En la actualidad, Structured Streaming no tiene tantas características como DStreams para los orígenes y receptores que admite de forma estándar, así que es aconsejable evaluar los requisitos para elegir la opción de procesamiento de secuencias de Spark adecuada.
Secuencias como tablas
Spark Structured Streaming representa una secuencia de datos como una tabla cuya profundidad es ilimitada, es decir, la tabla no para de crecer mientras lleguen datos nuevos. Esta tabla de entrada la procesa continuamente una consulta de ejecución prolongada y los resultados se envían a una tabla de salida:

En Structured Streaming, los datos llegan al sistema, se ingieran de inmediato y se colocan en una tabla de entrada. Se escriben consultas (mediante las API de DataFrame y Dataset) que realizan operaciones en esta tabla de entrada. La salida de la consulta genera otra tabla, la tabla de resultados. La tabla de resultados contiene los resultados de la consulta, a partir de la cual se extraen datos para un almacén de datos externo, como una base de datos relacional. El intervalo del desencadenador controla el momento en el que se procesan los datos desde la tabla de entrada. De manera predeterminada, el valor del intervalo del desencadenador es cero, por lo que Structured Streaming intenta procesar los datos en cuanto llegan. En la práctica, esto significa que en cuanto Structured Streaming finaliza el procesamiento de la ejecución de la consulta anterior, inicia otro procesamiento en el que se ejecutan los datos recién recibidos. Puede configurar el desencadenador para que se ejecute en un intervalo, con el fin de que los datos de streaming se procesen en lotes temporales.
Los datos de la tabla de resultados pueden contener solo los datos nuevos, con respecto a la última vez que se procesó la consulta (modo de anexión), o bien se puede actualizar la tabla cada vez que haya nuevos datos, con el fin de que incluya todos los datos de salida desde el inicio de la consulta de streaming (modo completo).
Modo de anexión
En este modo, las filas que se han agregado a la tabla de resultados desde la última vez que se ejecutó la consulta son las únicas que aparecen en la tabla de resultados y que se escriben en un almacenamiento externo. Por ejemplo, la consulta más sencilla solo copia todos los datos de la tabla de entrada en la tabla de resultados, sin modificaciones. Cada vez que transcurre un intervalo del desencadenador, se procesan los datos nuevos y las filas que representa dichos datos aparecen en la tabla de resultados.
Considere un escenario en el que procesa la telemetría de los sensores de temperatura, como un termostato. Suponga que el primer desencadenador procesó un evento a la hora 00:01 para el dispositivo 1 con una lectura de temperatura de 95 grados. En el primer desencadenador de la consulta, la fila con la hora 00:01 es la única que aparece en la tabla de resultados. A las 00:02, cuando se recibe otro evento, la única fila nueva es la fila con la hora 00:02 y, por tanto, la tabla de resultados contendrá solo esa fila.

Si se usa el modo de anexión, la consulta aplicará proyecciones (se seleccionan las columnas implicadas), filtro (se eligen solo las filas que cumplen ciertas condiciones) o combinación (aumenta los datos con data de una tabla de consulta estática). El modo de anexión facilita la inserción exclusiva de los puntos de datos nuevos relevantes en el almacenamiento externo.
Modo completo
Imagine el mismo escenario, pero esta vez con el modo completo. En el modo completo, toda la tabla de resultados completo se actualiza en cada desencadenador para que la tabla no incluya solo los datos de la última vez que se ejecutó el desencadenador, sino de todas las ejecuciones. El modo completo se puede usar para copiar los datos sin modificaciones de la tabla de entrada a la de resultados. En cada ejecución desencadenada, las filas de resultados nuevas aparecen junto con todas las anteriores. La tabla de resultados de salida acabará almacenando todos los datos recopilados desde que comenzó la consulta y, finalmente, se quedaría sin memoria. El modo completo está pensado para usarlo con consultas agregadas que resumen los datos de entrada de alguna manera, por lo que en cada desencadenador la tabla de resultados se actualiza con un resumen nuevo.
Imagine que hasta ahora ya se han procesado cinco segundos de datos y es el momento de procesar los datos del sexto segundo. La tabla de entrada tiene eventos para las horas 00:01 y 00:03. El objetivo de esta consulta de ejemplo es dar la temperatura media del dispositivo cada cinco segundos. La implementación de esta consulta aplica una agregado que toma todos los valores que se encuentren en cada periodo de 5 segundos, calcula el promedio de la temperatura y genera una fila para la temperatura media en ese intervalo. Al final del primera periodo de 5 segundos, hay dos tuplas: (00:01, 1, 95) y (00:03, 1, 98). Por tanto en el periodo 00:00-00:05 la agregación genera una tupla con la temperatura media de 96,5 grados. En el siguiente periodo de 5 segundos, hay solo un punto de datos en la hora 00:06, por lo que la temperatura media resultante es 98 grados. En la hora 00:10, utilizando el modo completo, la tabla de resultados tiene las filas de ambos periodos 00:00-00:05 y 05:00-00:10, porque la consulta devuelve todas las filas agregadas, no solo las nuevas. Por consiguiente, la tabla de resultados sigue creciendo a medida que se agregan nuevas periodos.

No todas las consultas que utilicen el modo completo harán que la tabla crezca sin límites. Suponga que, en el ejemplo anterior, en lugar de calcular el promedio de la temperatura por período de tiempo, lo hace por identificador de dispositivo. La tabla de resultados contiene un número fijo de filas (una por dispositivo) con la temperatura promedio del dispositivo en todos los puntos de datos procedentes del mismo. Cuando se reciben nuevas temperaturas, se actualiza la tabla de resultados para que sus medias estén siempre actualizadas.
Componentes de una aplicación de Spark Structured Streaming
Una consulta de ejemplo simple puede resumir las lecturas de temperatura por periodos de una hora. En este caso, los datos se almacenan en archivos JSON en Azure Storage (que se asocia como almacenamiento predeterminado para el clúster de HDInsight):
{"time":1469501107,"temp":"95"}
{"time":1469501147,"temp":"95"}
{"time":1469501202,"temp":"95"}
{"time":1469501219,"temp":"95"}
{"time":1469501225,"temp":"95"}
Estos archivos JSON se almacenan en la subcarpeta temps debajo del contenedor del clúster de HDInsight.
Definición del origen de entrada
En primer lugar, configure una instancia de DataFrame que describa el origen de los datos y todos los valores que requiera dicho origen. En este ejemplo se extraen los archivos JSON de Azure Storage y se les aplica un esquema en el momento en que se leen.
import org.apache.spark.sql.types._
import org.apache.spark.sql.functions._
//Cluster-local path to the folder containing the JSON files
val inputPath = "/temps/"
//Define the schema of the JSON files as having the "time" of type TimeStamp and the "temp" field of type String
val jsonSchema = new StructType().add("time", TimestampType).add("temp", StringType)
//Create a Streaming DataFrame by calling readStream and configuring it with the schema and path
val streamingInputDF = spark.readStream.schema(jsonSchema).json(inputPath)
Aplicación de la consulta
A continuación, aplique una consulta que contenga las operaciones deseadas a la instancia de DataFrame de Streaming. En este caso, una agregación agrupa todas las filas en periodos de 1 hora y, a continuación, calcula las temperaturas mínima, máxima y media en el periodo de 1 hora.
val streamingAggDF = streamingInputDF.groupBy(window($"time", "1 hour")).agg(min($"temp"), avg($"temp"), max($"temp"))
Definición del receptor de salida
A continuación, defina el destino de las filas que se agregan a la tabla de resultados en cada intervalo del desencadenador. En este ejemplo solo se generan todas las filas en una tabla en memoria temps que posteriormente se puede consultar con SparkSQL. El modo de salida completa garantiza que siempre se generen todas las filas de todos los periodos.
val streamingOutDF = streamingAggDF.writeStream.format("memory").queryName("temps").outputMode("complete")
Inicio de la consulta
Inicie la consulta de streaming y ejecútela hasta que reciba una señal de finalización.
val query = streamingOutDF.start()
Visualización de los resultados
Mientras se ejecuta la consulta, en la misma sesión de Spark, puede ejecutar una consulta de SparkSQL en el tempstabla en que se almacenan los resultados de la consulta.
select * from temps
Esta consulta devuelve resultados similares a los siguientes:
| periodo | mín. (temp.) | media (temp.) | máx. (temp.) |
|---|---|---|---|
| {u'start': u'2016-07-26T02:00:00.000Z', u'end'... | 95 | 95,231579 | 99 |
| {u'start': u'2016-07-26T03:00:00.000Z', u'end'... | 95 | 96,023048 | 99 |
| {u'start': u'2016-07-26T04:00:00.000Z', u'end'... | 95 | 96,797133 | 99 |
| {u'start': u'2016-07-26T05:00:00.000Z', u'end'... | 95 | 96,984639 | 99 |
| {u'start': u'2016-07-26T06:00:00.000Z', u'end'... | 95 | 97,014749 | 99 |
| {u'start': u'2016-07-26T07:00:00.000Z', u'end'... | 95 | 96,980971 | 99 |
| {u'start': u'2016-07-26T08:00:00.000Z', u'end'... | 95 | 96,965997 | 99 |
Para más información acerca de la API de Spark Structured Streaming, además de los orígenes de datos de entrada, las operaciones y los receptores de salida que admite, consulte Apache Spark Structured Streaming Programming Guide (Guía de programación de Apache Spark Structured Streaming).
Puntos de control y registros de escritura previa
Para proporcionar resistencia y tolerancia a errores, Structured Streaming utiliza los puntos de control para garantizar que el procesamiento de secuencias puede continuar sin interrupciones, aunque se produzcan errores en el nodo. En HDInsight, Spark crea puntos de control en un almacenamiento duradero, Azure Storage o Data Lake Storage. Dichos puntos almacenan la información de progreso de la consulta de streaming. Además, Structured Streaming usa un registro de escritura previa (WAL) que captura los datos ingeridos que se han recibido, pero que aún no ha procesado una consulta. Si se produce un error y se reinicia el procesamiento desde el WAL, los eventos recibidos del origen no se pierden.
Implementación de aplicaciones de Spark Streaming
Normalmente, las aplicaciones de Spark Streaming se compilan localmente en un archivo JAR y, luego, se implementan en Spark en HDInsight, para lo que se copia el archivo JAR en el almacenamiento predeterminado asociado al clúster de HDInsight. Después, puede iniciar la aplicación mediante las API REST de Apache Livy disponibles en el clúster mediante una operación POST. El cuerpo de la operación POST incluye un documento JSON que proporciona la ruta de acceso al archivo JAR, el nombre de la clase cuyo método principal define y ejecuta la aplicación de streaming y, opcionalmente, los requisitos de recursos del trabajo (por ejemplo, el número de ejecutores, la memoria y los núcleos) y los valores de configuración que requiere el código de la aplicación.
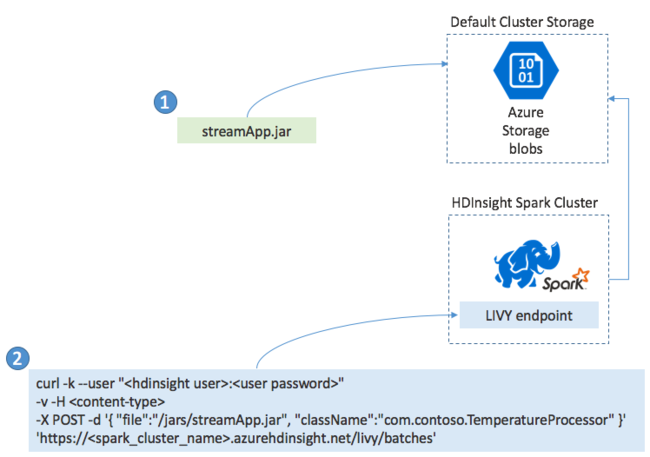
También se puede comprobar el estado de todas las aplicaciones con una solicitud GET en un punto de conexión de LIVY. Por último, para finalizar una aplicación en ejecución, emita una solicitud DELETE en el punto de conexión de LIVY. Para más información sobre la API de LIVY, consulte Trabajos remotos con Apache LIVY.
Pasos siguientes
- Creación de un clúster de Apache Spark en Azure HDInsight
- Apache Spark Structured Streaming Programming Guide (Guía de programación de Apache Spark Structured Streaming)
- Launch Apache Spark jobs remotely with Apache LIVY (Inicio remoto de los trabajos de Apache Spark con Apache LIVY)