Uso de un clúster de HDInsight Spark para analizar los datos en Data Lake Storage Gen1
En este artículo usará Jupyter Notebook, disponible con los clústeres de HDInsight Spark, para ejecutar un trabajo que lee datos de una cuenta de Data Lake Storage.
Prerequisites
Cuenta de Azure Data Lake Storage Gen1. Siga las instrucciones de Introducción a Azure Data Lake Storage Gen1 con Azure Portal.
Clúster de Azure HDInsight Spark con Data Lake Storage Gen1 como almacenamiento. Siga las instrucciones de Guía de inicio rápido: Configuración de clústeres en HDInsight.
Preparación de los datos
Nota
No hay que realizar este paso si ha creado el clúster de HDInsight con Data Lake Storage como almacenamiento predeterminado. El proceso de creación del clúster agrega algunos datos de ejemplo a la cuenta de Data Lake Storage que especifique durante la creación del clúster. Avance a la sección Uso de un clúster de HDInsight Spark con Data Lake Storage.
Si ha creado un clúster de HDInsight con Data Lake Storage como almacenamiento adicional y Azure Storage Blob como almacenamiento predeterminado, primero debe copiar algunos datos de ejemplo en la cuenta de Data Lake Storage. Puede usar los datos de ejemplo de la instancia de Azure Storage Blob asociada al clúster de HDInsight.
Abra un símbolo del sistema y vaya al directorio donde está instalada la herramienta AdlCopy, normalmente
%HOMEPATH%\Documents\adlcopy.Ejecute el siguiente comando para copiar un blob específico desde el contenedor de origen a Data Lake Storage:
AdlCopy /source https://<source_account>.blob.core.windows.net/<source_container>/<blob name> /dest swebhdfs://<dest_adls_account>.azuredatalakestore.net/<dest_folder>/ /sourcekey <storage_account_key_for_storage_container>Copie el archivo de datos de ejemplo HVAC.csv situado en /HdiSamples/HdiSamples/SensorSampleData/hvac/ en la cuenta de Azure Data Lake Storage. El fragmento de código debería tener este aspecto:
AdlCopy /Source https://mydatastore.blob.core.windows.net/mysparkcluster/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv /dest swebhdfs://mydatalakestore.azuredatalakestore.net/hvac/ /sourcekey uJUfvD6cEvhfLoBae2yyQf8t9/BpbWZ4XoYj4kAS5Jf40pZaMNf0q6a8yqTxktwVgRED4vPHeh/50iS9atS5LQ==Advertencia
Asegúrese de que los nombres de archivo y ruta de acceso estén escritos con las mayúsculas adecuadas.
Se le pide que escriba las credenciales de la suscripción a Azure en la que tiene la cuenta de Data Lake Storage. Debe ver una salida similar al siguiente fragmento de código:
Initializing Copy. Copy Started. 100% data copied. Copy Completed. 1 file copied.El archivo de datos (HVAC.csv) se copiará en una carpeta /hvac en la cuenta de Data Lake Storage.
Uso de un clúster de HDInsight Spark con Data Lake Storage Gen1
En Azure Portal, en el panel de inicio, haga clic en el icono del clúster de Apache Spark (si lo ancló al panel de inicio). También puede navegar hasta el clúster en Examinar todo>Clústeres de HDInsight.
En la hoja del clúster Spark, haga clic en Vínculos rápidos y, luego, en la hoja Panel de clúster, haga clic en Jupyter Notebook. Cuando se le pida, escriba las credenciales del clúster.
Nota
También puede comunicarse con el equipo Jupyter Notebook en el clúster si abre la siguiente dirección URL en el explorador. Reemplace CLUSTERNAME por el nombre del clúster:
https://CLUSTERNAME.azurehdinsight.net/jupyterCree un nuevo notebook. Haga clic en Nuevo y, luego, en PySpark.
Dado que creó un cuaderno con el kernel PySpark, no necesitará crear ningún contexto explícitamente. Los contextos Spark y Hive se crearán automáticamente al ejecutar la primera celda de código. Puede empezar por importar los tipos necesarios para este escenario. Para ello, pegue el siguiente fragmento de código en una celda y presione MAYÚS + ENTRAR.
from pyspark.sql.types import *Cada vez que se ejecuta un trabajo en Jupyter, el título de la ventana del explorador web mostrará el estado (Busy) (Ocupado) junto con el título del cuaderno. También verá un círculo sólido junto al texto PySpark en la esquina superior derecha. Una vez completado el trabajo, cambiará a un círculo hueco.

Cargue los datos de ejemplo en una tabla temporal mediante el archivo HVAC.csv que copió en la cuenta de Data Lake Storage Gen1. Ahora puede obtener acceso a los datos de la cuenta de Data Lake Storage con el siguiente patrón de dirección URL.
Si dispone de Data Lake Storage Gen1 como almacenamiento predeterminado, HVAC.csv estará en la ruta de acceso similar a la siguiente dirección URL:
adl://<data_lake_store_name>.azuredatalakestore.net/<cluster_root>/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csvTambién podría usar un formato abreviado como el siguiente:
adl:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csvSi cuenta con Data Lake Storage como almacenamiento adicional, HVAC.csv estará en la ubicación donde lo copió, por ejemplo:
adl://<data_lake_store_name>.azuredatalakestore.net/<path_to_file>En una celda vacía, pegue el siguiente ejemplo de código, reemplace MYDATALAKESTORE por el nombre de su cuenta de Azure Data Lake Storage y presione MAYÚS+ENTRAR. Este ejemplo de código registra los datos en una tabla temporal llamada hvac.
# Load the data. The path below assumes Data Lake Storage is default storage for the Spark cluster hvacText = sc.textFile("adl://MYDATALAKESTORazuredatalakestore. net/cluster/mysparkclusteHdiSamples/HdiSamples/ SensorSampleData/hvac/HVAC.csv") # Create the schema hvacSchema = StructType([StructField("date", StringTy(), False) ,StructField("time", StringType(), FalseStructField ("targettemp", IntegerType(), FalseStructField("actualtemp", IntegerType(), FalseStructField("buildingID", StringType(), False)]) # Parse the data in hvacText hvac = hvacText.map(lambda s: s.split(",")).filt(lambda s: s [0] != "Date").map(lambda s:(str(s[0]), s(s[1]), int(s[2]), int (s[3]), str(s[6]) )) # Create a data frame hvacdf = sqlContext.createDataFrame(hvac,hvacSchema) # Register the data fram as a table to run queries against hvacdf.registerTempTable("hvac")
Al usar un kernel de PySpark, puede ejecutar directamente una consulta SQL en la tabla temporal hvac que acaba de crear con la instrucción mágica
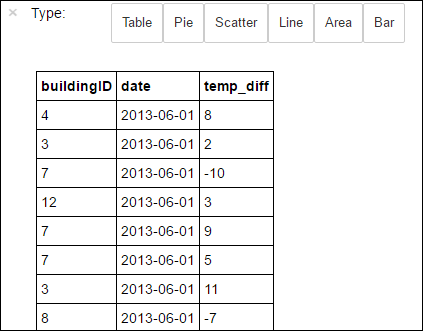
%%sql. Para más información sobre la función mágica%%sql, así como otras funciones mágicas disponibles con el kernel de PySpark, consulte Kernels disponibles para cuadernos de Jupyter Notebook con clústeres de Apache Spark en HDInsight.%%sql SELECT buildingID, (targettemp - actualtemp) AS temp_diff, date FROM hvac WHERE date = \"6/1/13\"Una vez que el trabajo se completa correctamente, se muestra de forma predeterminada el resultado tabular siguiente.
También puede ver la salida en otras visualizaciones. Por ejemplo, un gráfico de área con la misma salida tendría el siguiente aspecto.
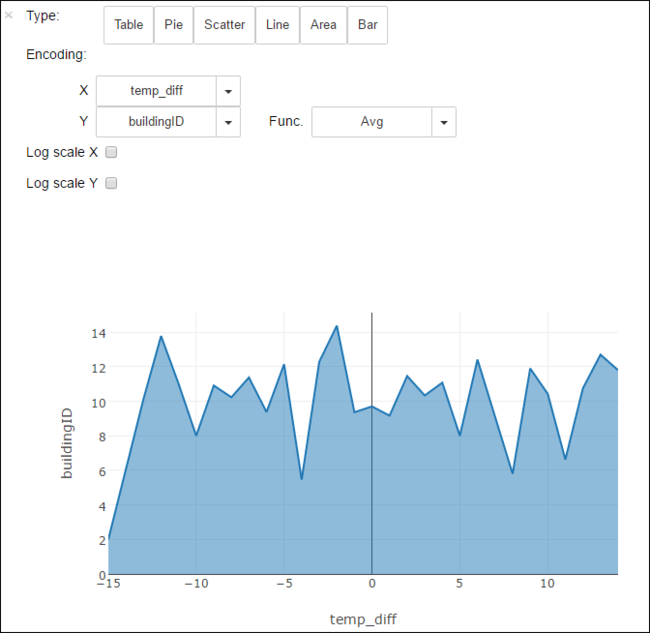
Cuando haya terminado de ejecutar la aplicación, debe cerrar el cuaderno para liberar los recursos. Para ello, en el menú Archivo del cuaderno, haga clic en Cerrar y detener. De esta manera se apagará y se cerrará el cuaderno.
Pasos siguientes
- Creación de una aplicación independiente con Scala para ejecutarla en un clúster de Apache Spark
- Uso de las herramientas de HDInsight de Azure Toolkit for IntelliJ para crear aplicaciones de Apache Spark destinadas al clúster Spark en HDInsight (Linux)
- Uso de las herramientas de HDInsight de Azure Toolkit for Eclipse con el fin de crear aplicaciones de Apache Spark destinadas al clúster Spark en HDInsight (Linux)
- Uso de Data Lake Storage Gen2 con clústeres de Azure HDInsight