Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo se describe cómo configurar directivas de Apache Ranger para Spark SQL con Enterprise Security Package en HDInsight.
En este artículo aprenderá a:
- Crear directivas de Apache Ranger.
- Comprobar las directivas de Ranger aplicadas.
- Aplicar directrices para establecer Apache Ranger para Spark SQL.
Prerrequisitos
- Un clúster de Apache Spark en HDInsight versión 5.1 con Enterprise Security Package.
Conexión a la interfaz de usuario de administrador de Apache Ranger
En un explorador, conéctese a la interfaz de usuario de administrador de Ranger mediante la dirección URL
https://ClusterName.azurehdinsight.net/Ranger/.Cambie
ClusterNamepor el nombre del clúster de Spark.Inicie sesión con sus credenciales de administrador de Microsoft Entra. Las credenciales de administrador de Microsoft Entra no son las mismas que las credenciales del clúster de HDInsight ni las credenciales de Secure Shell (SSH) del nodo de HDInsight en Linux.
Crear usuarios de dominio
Para obtener información sobre cómo crear sparkuserusuarios de dominio, consulte Creación de un clúster de HDInsight con ESP. En un escenario de producción, los usuarios del dominio proceden de su inquilino de Microsoft Entra.
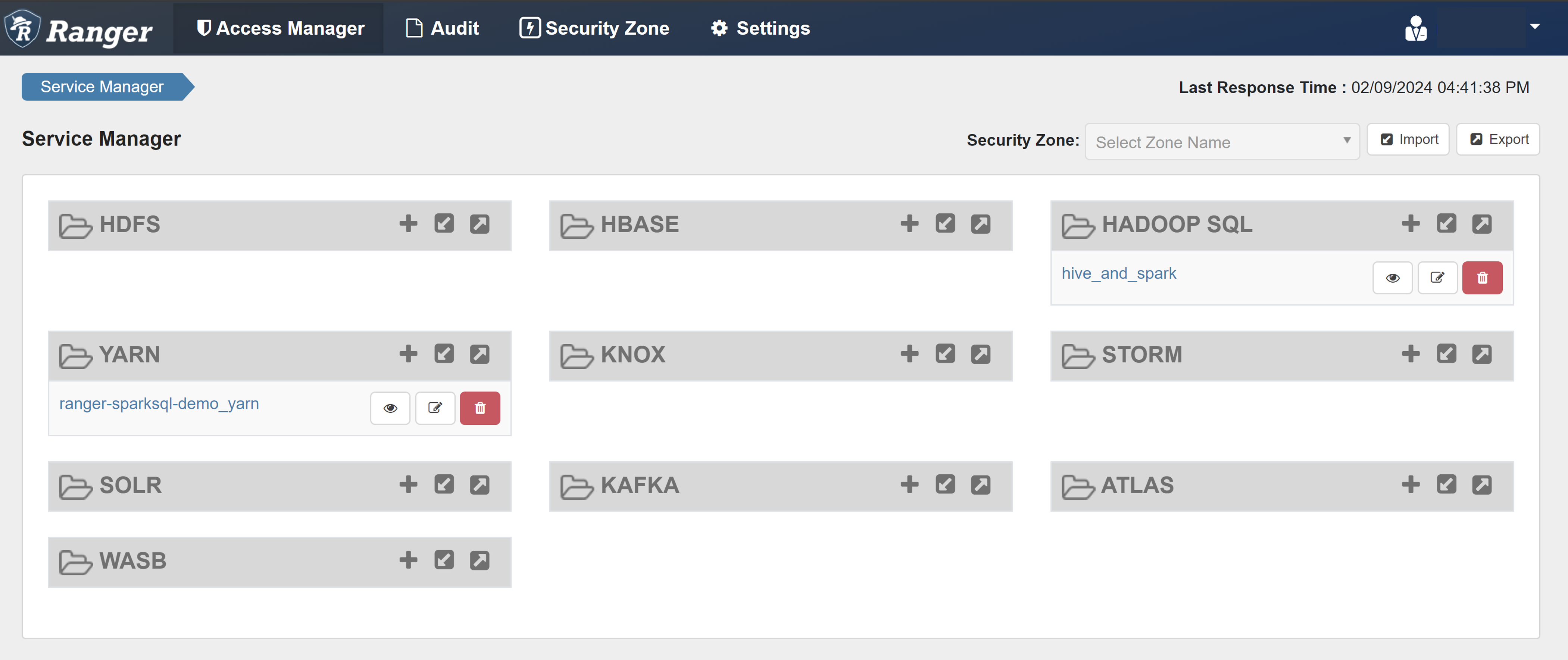
Creación de directivas de Ranger
En esta sección, creará dos directivas de Ranger:
- Una directiva de acceso para acceder a
hivesampletabledesde Spark SQL. - Una directiva de enmascaramiento para ocultar las columnas de
hivesampletable.
Creación de directivas de acceso de Ranger
Abra la interfaz de usuario de administrador de Ranger.
En HADOOP SQL, seleccione hive_and_spark.
En la pestaña Acceso, seleccione Agregar nueva directiva.
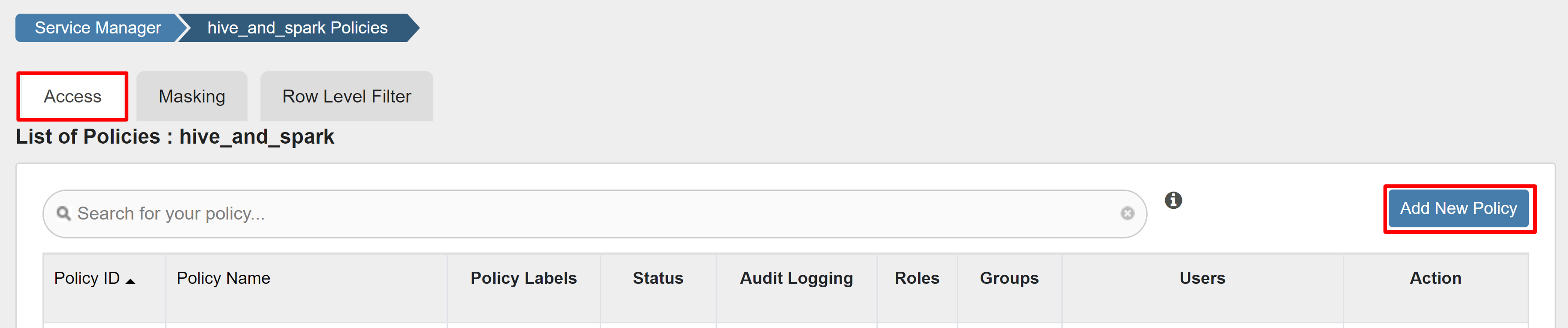
Escriba los siguientes valores:
Propiedad Valor Nombre de directiva read-hivesampletable-all base de datos default table hivesampletable columna * Seleccionar usuario sparkuserPermisos select 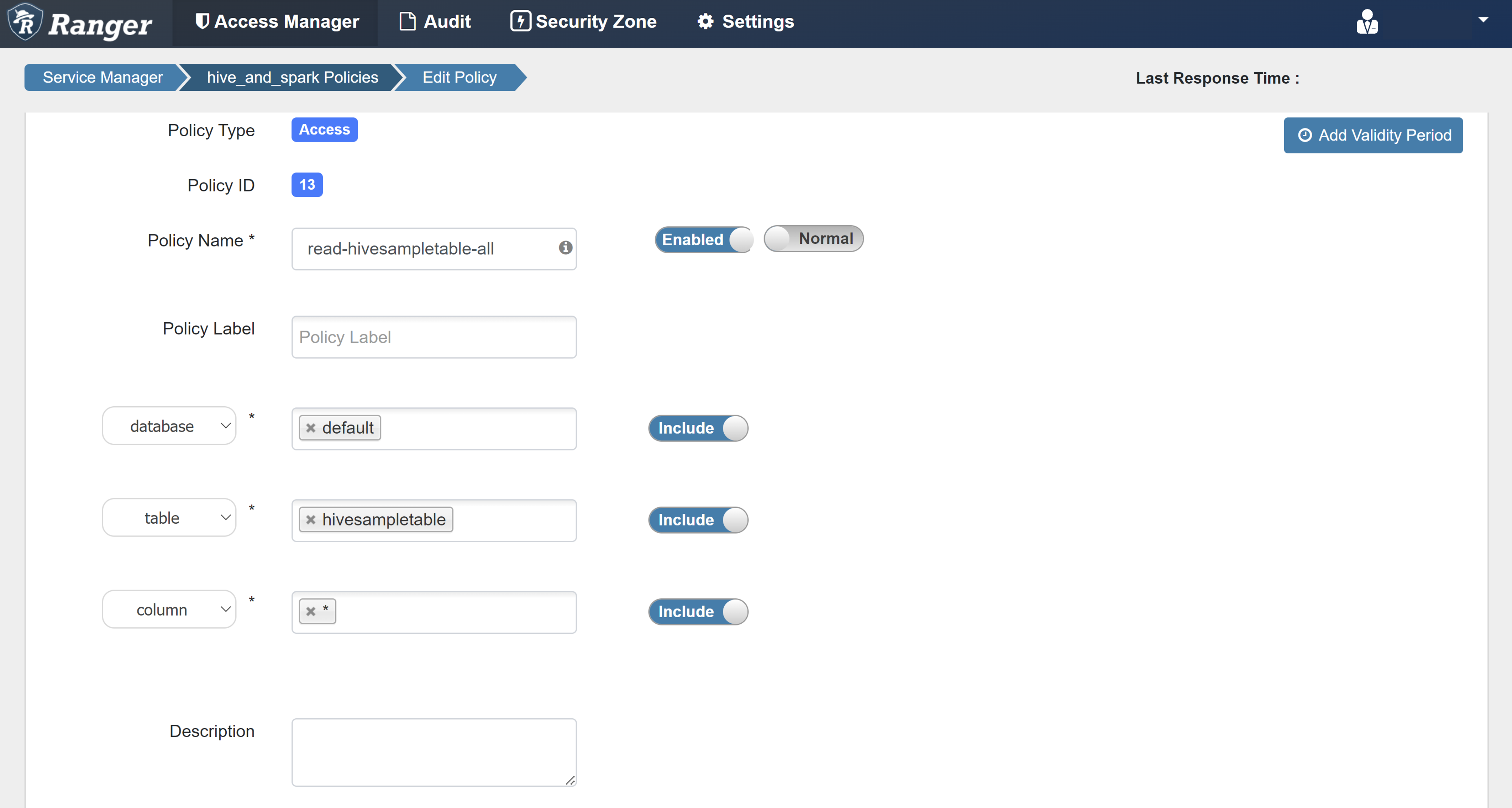
Si un usuario del dominio no se rellena automáticamente en Seleccionar usuario, espere unos instantes a que Ranger se sincronice con Microsoft Entra ID.
Seleccione Agregar para guardar la directiva.
Abra un cuaderno de Zeppelin y ejecute el siguiente comando para comprobar la directiva:
%sql select * from hivesampletable limit 10;Este es el resultado antes de aplicar una directiva:
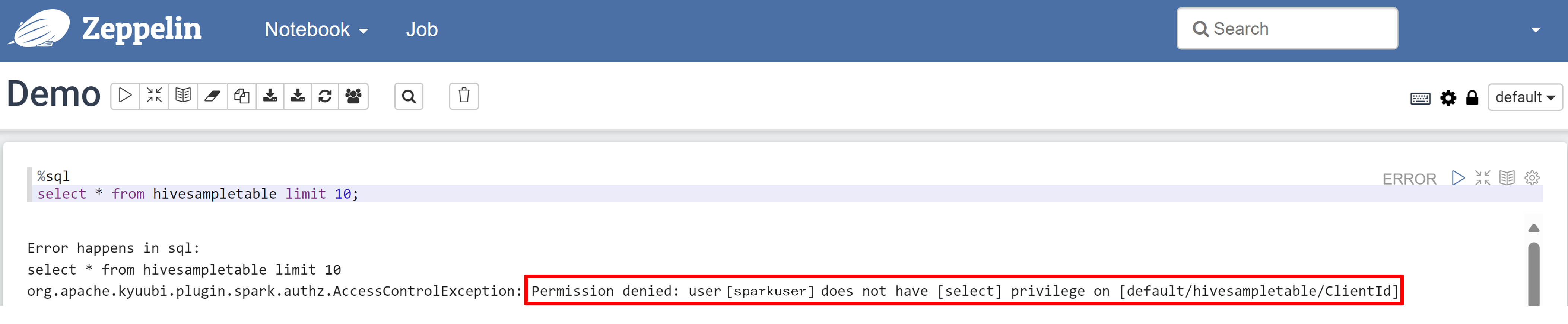
Este es el resultado después de aplicar una directiva:





Creación de una directiva de enmascaramiento de Ranger
En el ejemplo siguiente se muestra cómo crear una directiva para enmascarar una columna:
En la pestaña Enmascaramiento, seleccione Agregar nueva directiva.
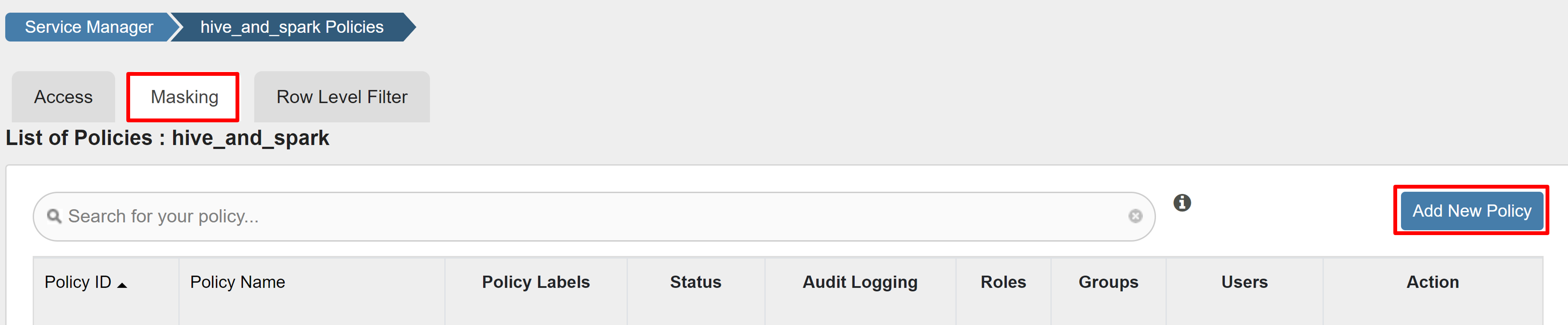
Escriba los siguientes valores:
Propiedad Valor Nombre de directiva mask-hivesampletable Base de datos de Hive default Tabla de Hive hivesampletable Columna de Hive devicemake Seleccionar usuario sparkuserTipos de acceso select Selección de la opción de enmascaramiento Hash 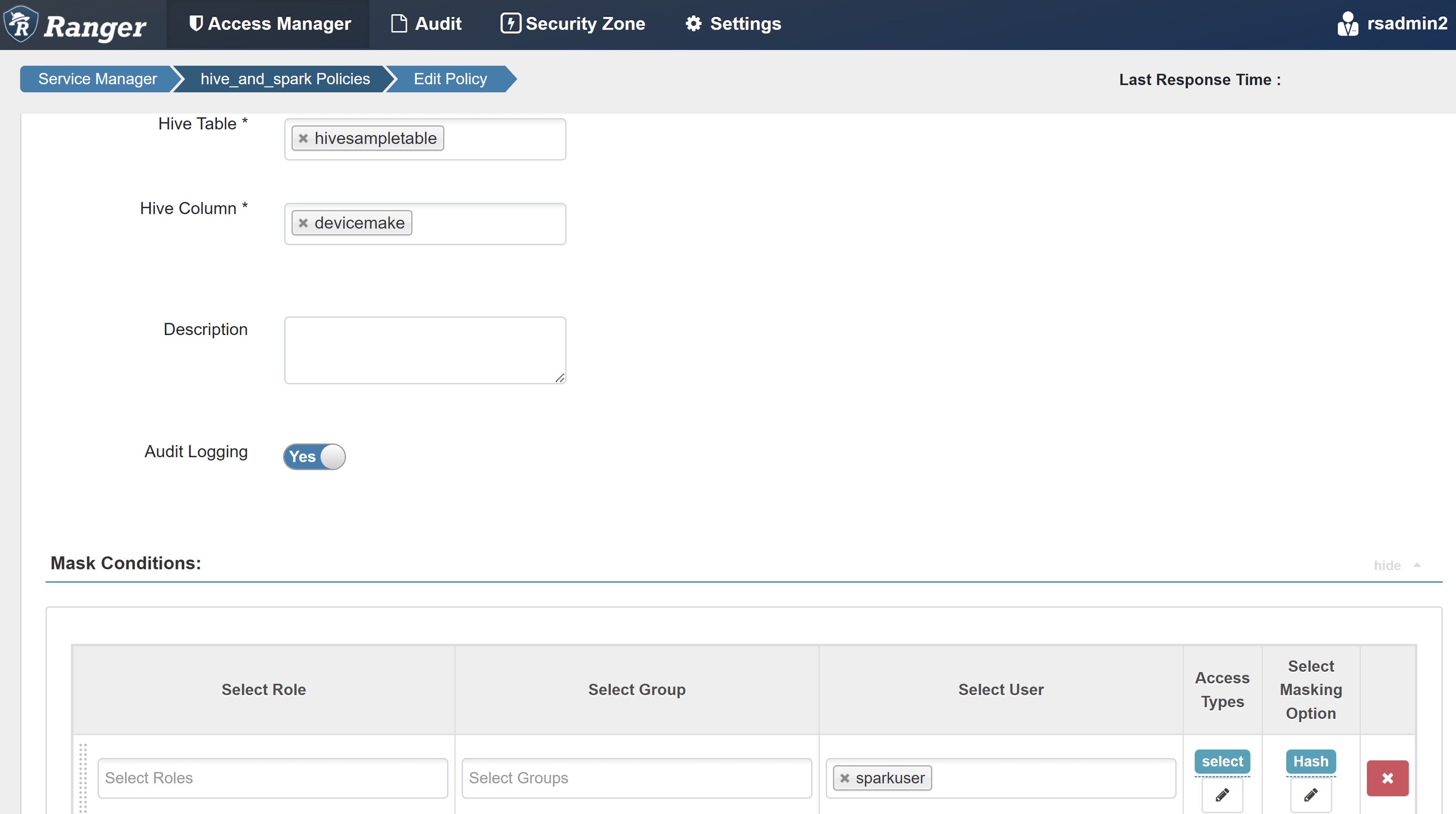
Seleccione Guardar para guardar la directiva.
Abra un cuaderno de Zeppelin y ejecute el siguiente comando para comprobar la directiva:
%sql select clientId, deviceMake from hivesampletable;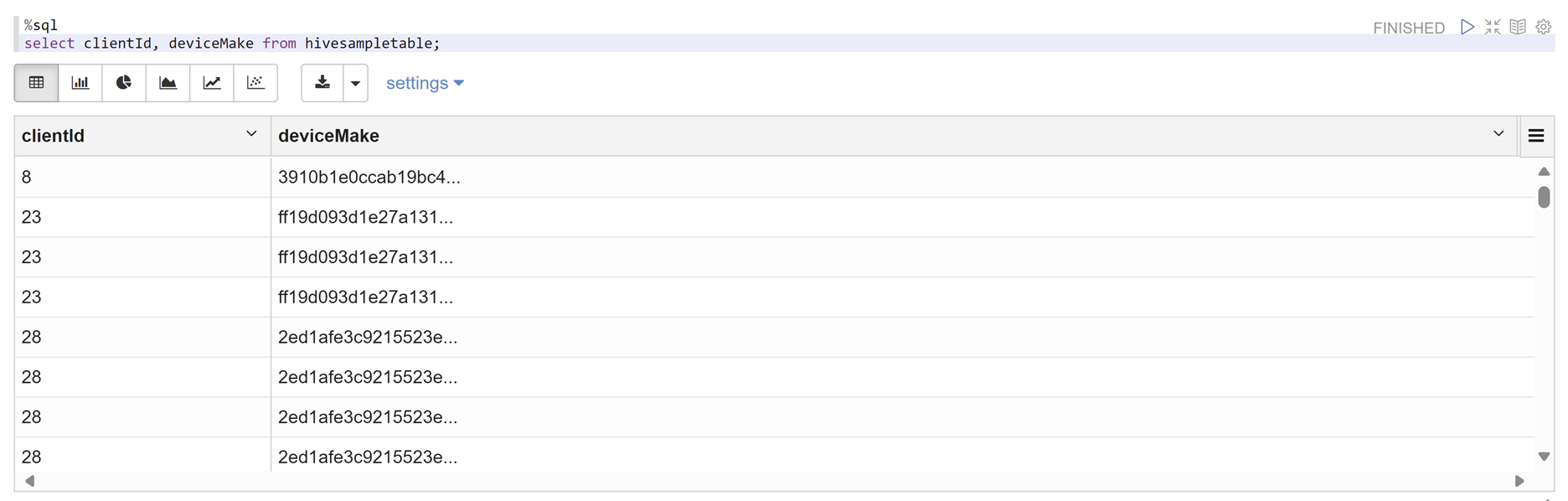



Nota:
De forma predeterminada, las directivas de Hive y Spark SQL son comunes en Ranger.
Aplicación de directrices para configurar Apache Ranger para Spark SQL
En los escenarios siguientes se exploran las directrices para crear un clúster de Spark en HDInsight 5.1 mediante una nueva base de datos de Ranger y una base de datos de Ranger existente.
Escenario 1: Uso de una nueva base de datos de Ranger al crear un clúster de Spark en HDInsight 5.1
Cuando use una nueva base de datos de Ranger para crear un clúster, se crea el repositorio de Ranger correspondiente que contiene las directivas de Ranger para Hive y Spark con el nombre hive_and_spark en el servicio SQL de Hadoop de la base de datos de Ranger.

Si edita las directivas, se aplican a Hive y Spark.
Tenga en cuenta estos puntos:
Si tiene dos bases de datos de metastore con el mismo nombre para los catálogos de Hive (por ejemplo, DB1) y Spark (por ejemplo, DB1):
- Si Spark usa el catálogo de Spark (
metastore.catalog.default=spark), las directivas se aplican a la base de datos DB1 del catálogo de Spark. - Si Spark usa el catálogo de Hive (
metastore.catalog.default=hive), las directivas se aplican a la base de datos DB1 del catálogo de Hive.
Desde la perspectiva de Ranger, no hay forma de diferenciar entre DB1 de los catálogos de Hive y Spark.
En tales casos, se recomienda lo siguiente:
- Use el catálogo de Hive para Hive y Spark.
- Mantenga los nombres de base de datos, tablas y columnas diferentes para los catálogos de Hive y Spark para que las directivas no se apliquen a las bases de datos entre catálogos.
- Si Spark usa el catálogo de Spark (
Si usa el catálogo de Hive para Hive y Spark, tenga en cuenta el ejemplo siguiente.
Supongamos que crea una tabla llamada table1 mediante Hive con el usuario xyz actual. Se crea un archivo del Sistema de archivos distribuido de Hadoop (HDFS) llamado table1.db cuyo propietario es el usuario de xyz.
Ahora imagine que usa el usuario abc para iniciar la sesión de Spark SQL. En esta sesión del usuario abc, si intenta escribir algo en table1, se producirá un error, ya que el propietario de la tabla es xyz.
En tal caso, se recomienda usar el mismo usuario en Hive y Spark SQL para actualizar la tabla. El usuario debe tener privilegios suficientes para realizar operaciones de actualización.
Escenario 2: Uso de una base de datos de Ranger existente (con directivas existentes) al crear un clúster de Spark en HDInsight 5.1
Cuando se crea un clúster de HDInsight 5.1 mediante la base de datos de Ranger existente, se vuelve a crear un nuevo repositorio de Ranger en esta base de datos con el nombre del nuevo clúster en este formato: hive_and_spark.

Supongamos que ya tiene las directivas definidas en el repositorio de Ranger con el nombre oldclustername_hive en la base de datos de Ranger existente dentro del servicio SQL de Hadoop. Quiere compartir las mismas directivas en el nuevo clúster de Spark en HDInsight 5.1. Para lograr este objetivo, siga estos pasos:
Nota:
Un usuario que tenga privilegios de administrador de Ambari puede realizar actualizaciones de la configuración.
Abra la interfaz de usuario de Ambari desde el nuevo clúster de HDInsight 5.1.
Vaya al servicio Spark3 y, luego, vaya a Configs.
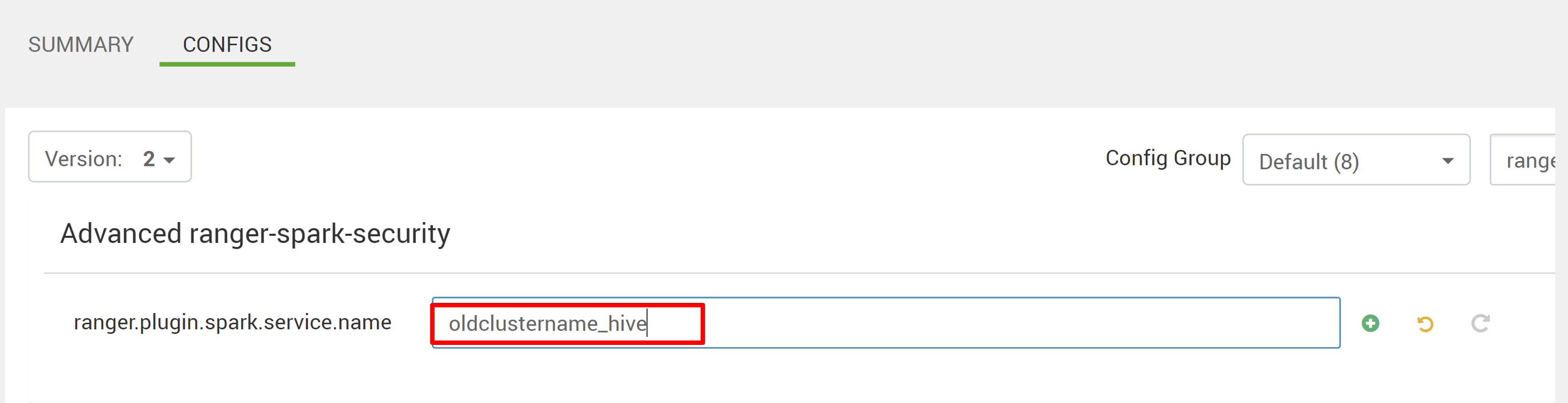
Abra la configuración Advanced ranger-spark-security.
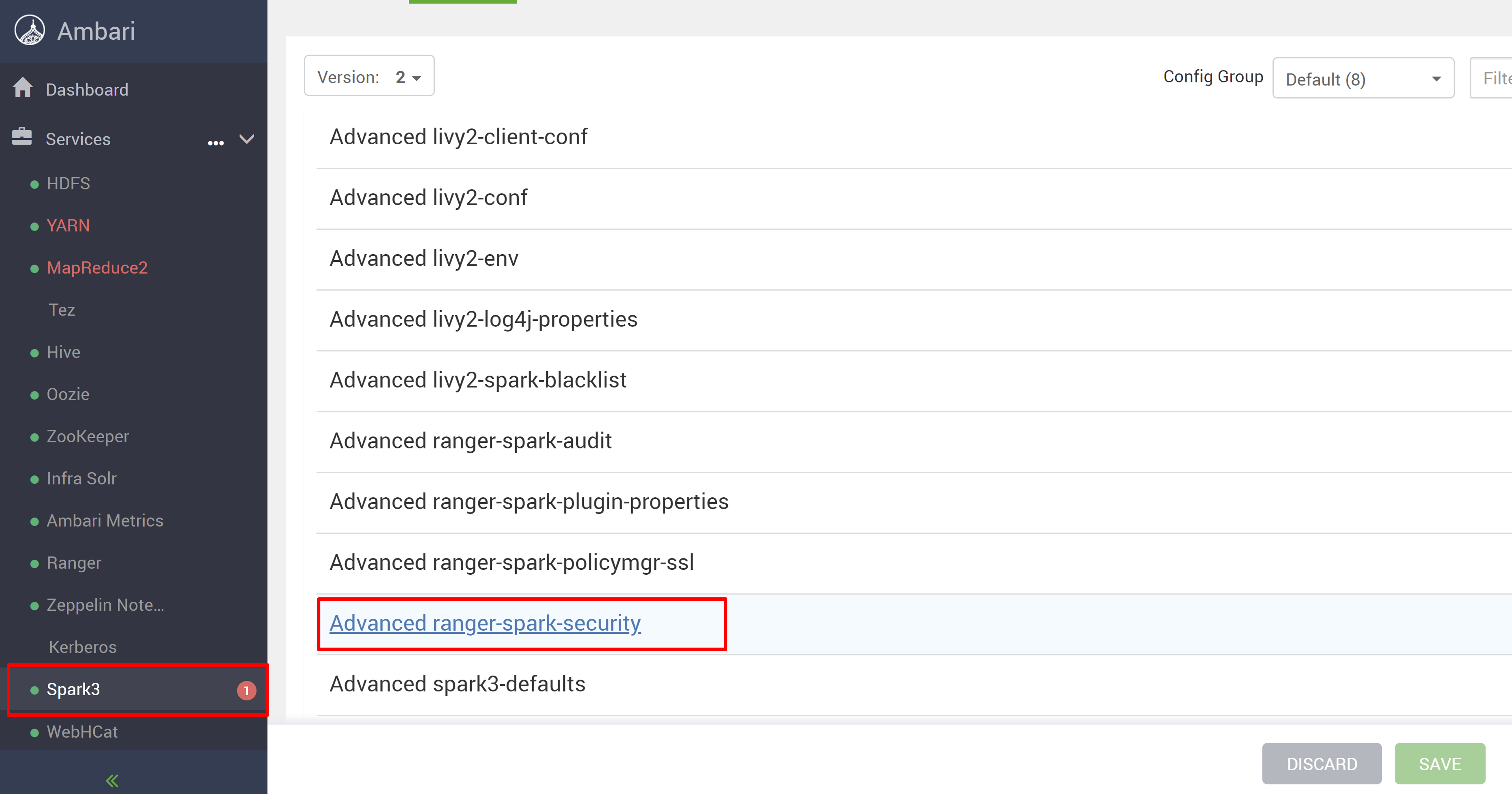
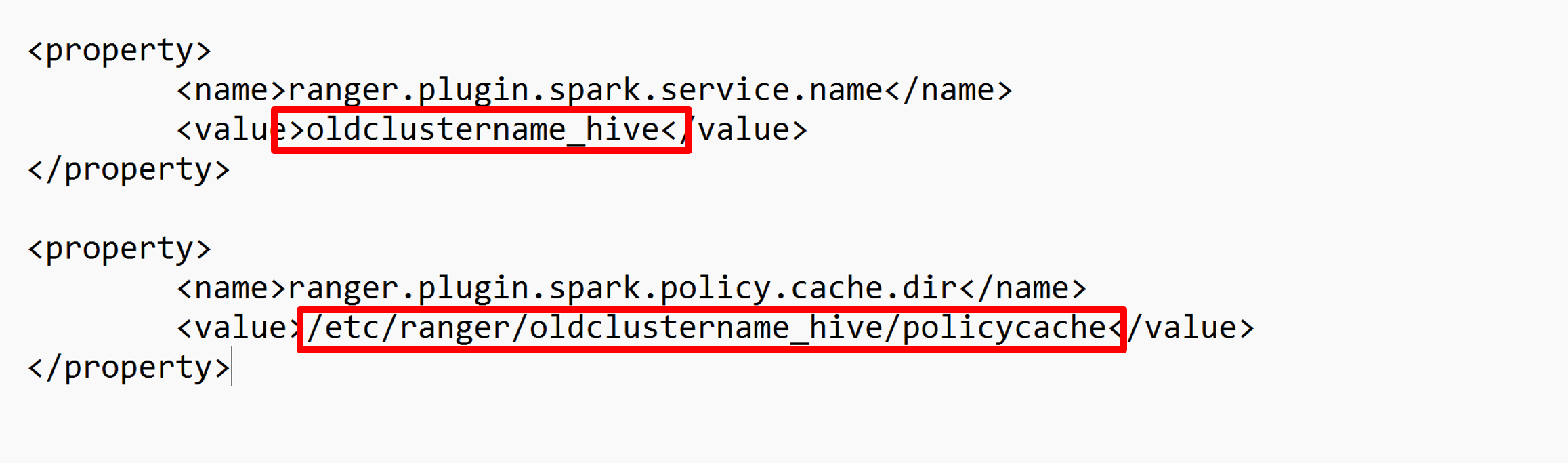
o también puede abrir esta configuración en /etc/spark3/conf mediante SSH.
Edite dos configuraciones (ranger.plugin.spark.service.name y ranger.plugin.spark.policy.cache.dir) para que apunten al repositorio de directivas anterior oldclustername_hive y, luego, guarde las configuraciones.
Ambari:
Archivo XML:
Reinicie los servicios Ranger y Spark desde Ambari.
Abra la interfaz de usuario de administrador de Ranger y haga clic en el botón Editar en servicio SQL de HADOOP.
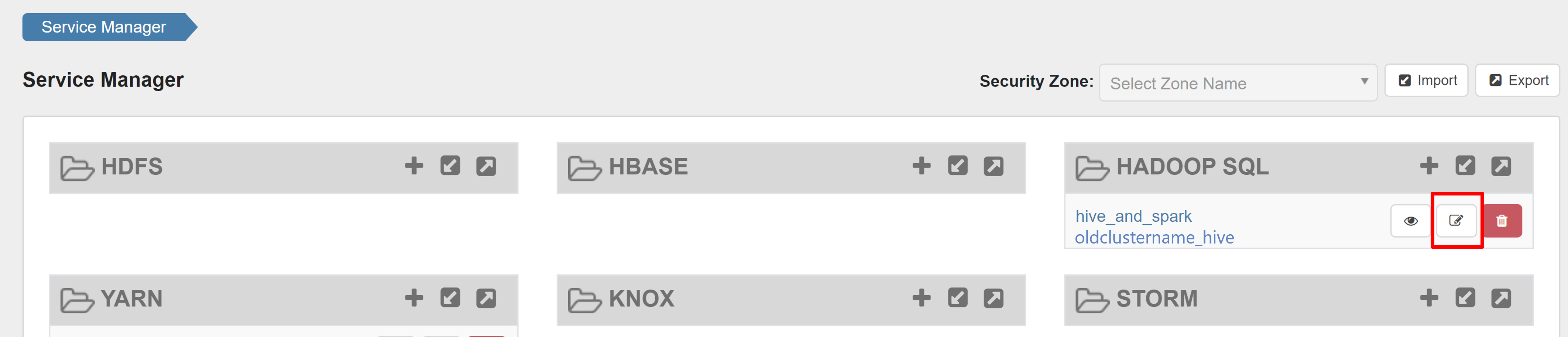
Para el servicio oldclustername_hive, agregue el usuario rangersparklookup en la lista policy.download.auth.users y tag.download.auth.users y haga clic en Guardar.






Las directivas se aplican a las bases de datos del catálogo de Spark. Si quiere acceder a las bases de datos del catálogo de Hive:
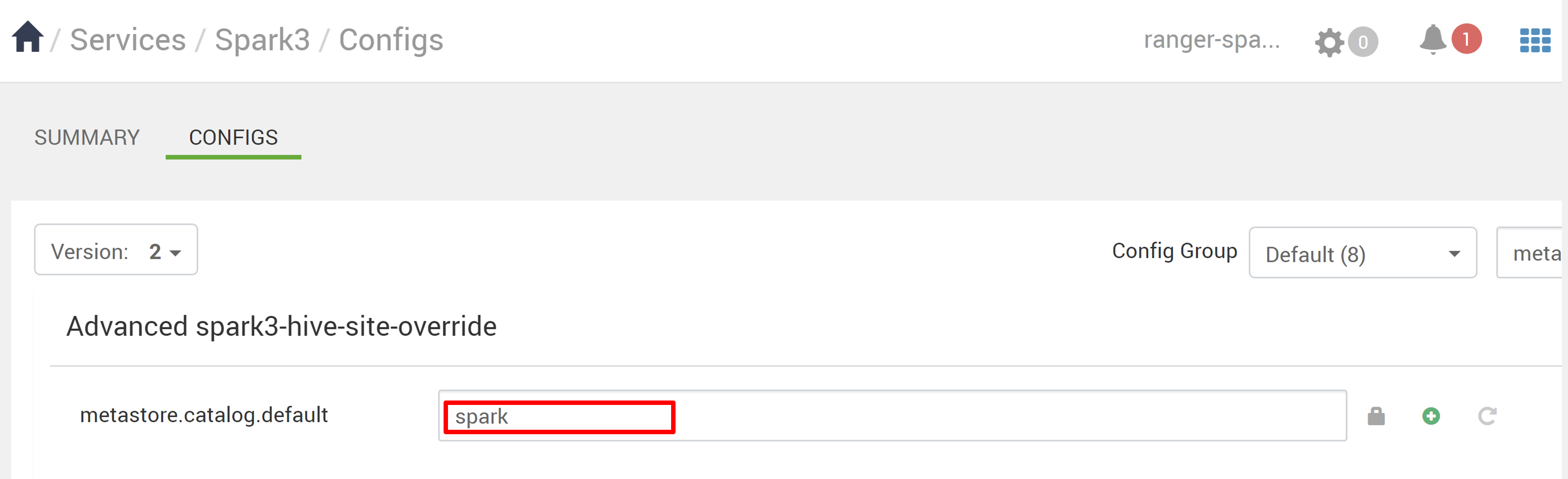
En Ambari, vaya a Spark3>Configs.
Cambie metastore.catalog.default de spark a hive.

Problemas conocidos
- La integración de Apache Ranger con Spark SQL no funciona si el administrador de Ranger está inactivo.
- En los registros de auditoría de Ranger, al mantener el puntero sobre la columna de Recursos, no puede mostrar toda la consulta que ejecutó.