Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Aprenda a usar Apache Pig con HDInsight.
Apache Pig es una plataforma para crear programas de Apache Hadoop mediante un lenguaje de procedimientos que se conoce como Pig Latin. Pig es una alternativa a Java para crear soluciones MapReduce y se incluye con HDInsight de Azure. Utilice la tabla siguiente para conocer las distintas formas de usar Pig con HDInsight:
Motivos para usar Apache Pig
Uno de los desafíos del procesamiento de datos mediante el uso de MapReduce en Hadoop es la implementación de la lógica de procesamiento únicamente con un mapa y una función de reducción. Para el procesamiento complejo, a menudo debe interrumpir el procesamiento en varias operaciones de MapReduce que están encadenadas para lograr el resultado deseado.
Pig permite definir los procesos como una serie de transformaciones por la que fluyen los datos para producir el resultado deseado.
El lenguaje de Pig Latin le permite describir el flujo de datos desde entrada sin formato, a través de una o varias transformaciones, para producir el resultado deseado. Los programas de Pig Latin siguen este patrón general:
Carga: lectura de los datos que se van a manipular desde el sistema de archivos.
Transformación: manipulación de los datos.
Volcado o almacén: generación de datos en la pantalla o almacenamiento para su procesamiento.
Funciones definidas por el usuario
Pig Latin también admite las funciones definidas por el usuario (UDF), que le permiten invocar componentes externos que implementan la lógica que es difícil de modelar en Pig Latin.
Para más información sobre Pig Latin, consulte el manual de referencia de Pig Latin 1 y el manual de referencia de Pig Latin 2.
Datos de ejemplo
HDInsight proporciona diversos conjuntos de datos de ejemplo que se almacenan en los directorios /example/data y /HdiSamples. Estos directorios están en el almacenamiento predeterminado de su clúster. El ejemplo de Pig de este documento utiliza el archivo Log4j de /example/data/sample.log.
Cada registro del archivo consta de una línea de campos que contiene un campo [LOG LEVEL] para mostrar el tipo y la gravedad, por ejemplo:
2012-02-03 20:26:41 SampleClass3 [ERROR] verbose detail for id 1527353937
En el ejemplo anterior, el nivel de registro es ERROR.
Nota
También puede generar un archivo log4j con la herramienta de registro Apache Log4j y luego cargarlo en el blob. Consulte Carga de datos en HDInsight para obtener instrucciones. Para obtener más información sobre el uso de los blobs en Azure Storage con HDInsight, consulte Uso de Azure Blob Storage con HDInsight.
Trabajo de ejemplo
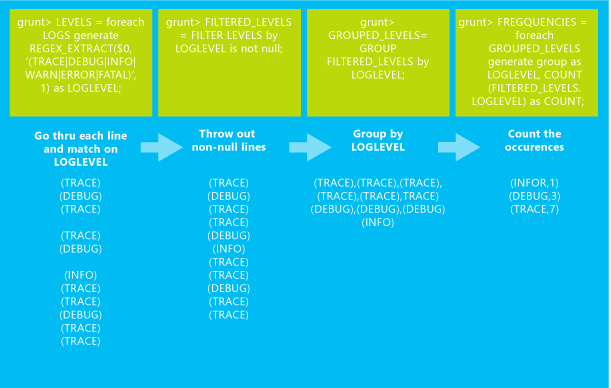
El siguiente trabajo de Pig Latin carga el archivo sample.log desde el almacenamiento predeterminado para el clúster de HDInsight. A continuación, realiza una serie de transformaciones que generan un recuento de cuántas veces se ha producido cada nivel de registro en los datos de entrada. Los resultados se escriben en STDOUT.
LOGS = LOAD 'wasb:///example/data/sample.log';
LEVELS = foreach LOGS generate REGEX_EXTRACT($0, '(TRACE|DEBUG|INFO|WARN|ERROR|FATAL)', 1) as LOGLEVEL;
FILTEREDLEVELS = FILTER LEVELS by LOGLEVEL is not null;
GROUPEDLEVELS = GROUP FILTEREDLEVELS by LOGLEVEL;
FREQUENCIES = foreach GROUPEDLEVELS generate group as LOGLEVEL, COUNT(FILTEREDLEVELS.LOGLEVEL) as COUNT;
RESULT = order FREQUENCIES by COUNT desc;
DUMP RESULT;
En la siguiente imagen se muestra un resumen de lo que hace cada transformación a los datos.
Ejecutar el trabajo de Pig Latin
HDInsight puede ejecutar trabajos de Pig Latin mediante varios métodos. Use la tabla siguiente para decidir cuál es el método adecuado para usted luego siga el vínculo para ver un tutorial.
Pig y SQL Server Integration Services
Puede usar SQL Server Integration Services (SSIS) para ejecutar un trabajo de Pig. El paquete de características de Azure para SSIS proporciona los siguientes componentes que funcionan con trabajos de Pig en HDInsight.
Obtenga más información sobre el paquete de características de Azure para SSIS aquí.
Pasos siguientes
Ahora que aprendió a usar Pig con HDInsight, use los siguientes vínculos para explorar otras formas de trabajar con HDInsight de Azure.