Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Se aplica a:![]() IoT Edge 1.5
IoT Edge 1.5
Importante
IoT Edge 1.5 LTS es la versión compatible. IoT Edge 1.4 LTS finaliza su ciclo de vida el 12 de noviembre de 2024. Si está usando una versión anterior, consulte Actualización de IoT Edge.
En este artículo, aprenderá los conceptos y técnicas para implementar dimensiones de observabilidad: medición y supervisión y solución de problemas. Obtendrá información sobre los temas siguientes:
- Definición de los indicadores de rendimiento del servicio que se van a supervisar
- Medición de indicadores de rendimiento del servicio mediante métricas
- Supervisar las métricas y detectar problemas mediante cuadernos de Azure Monitor
- Solución de problemas básicos mediante cuadernos de trabajo seleccionados
- Solución de problemas avanzados mediante el seguimiento distribuido y los registros correlacionados
- Opcionalmente, implemente un escenario de ejemplo en Azure para practicar lo que aprende.
Escenario
Para ir más allá de las consideraciones abstractas, vamos a usar un escenario de la vida real que recopila las temperaturas de la superficie del océano de los sensores en Azure IoT.
La Niña
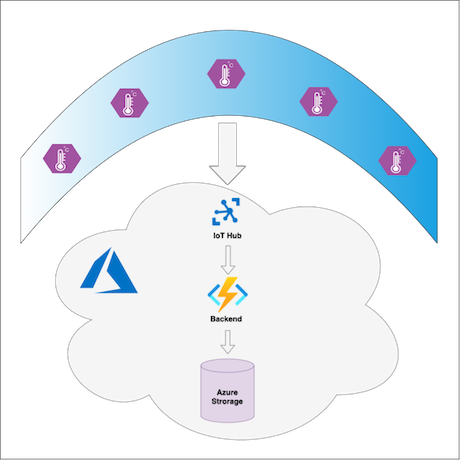
El servicio La Niña mide la temperatura expuesta en el océano Pacífico para predecir los inviernos de La Niña. Las boyas en el océano tienen dispositivos IoT Edge que envían datos de temperatura de la superficie a la nube de Azure. Un módulo personalizado en cada dispositivo IoT Edge preprocesa los datos de telemetría antes de enviarlos a la nube. En la nube, el back-end de Azure Functions procesa los datos y los guarda en Azure Blob Storage. Los clientes del servicio, como flujos de trabajo de inferencia de ML, sistemas de toma de decisiones y diferentes interfaces de usuario, pueden obtener mensajes con datos de temperatura de Azure Blob Storage.
Medición y supervisión
Vamos a crear una solución de medición y supervisión para el servicio La Niña, que se centra en su valor de negocios.
Qué medimos y supervisamos
Para comprender qué vamos a supervisar, debemos comprender qué hace realmente el servicio y qué esperan los clientes de servicio que les ofrezca el sistema. En este escenario, las expectativas de un consumidor común del servicio La Niña podrían clasificarse por los siguientes factores:
- Cobertura. Los datos proceden de la mayoría de las boyas instaladas.
- Actualidad. Los datos procedentes de las boyas están actualizados y son pertinentes.
- Rendimiento. Los datos de temperatura se entregan desde las boyas sin mayores retrasos.
- Corrección. La proporción de mensajes perdidos (errores) es pequeña.
La satisfacción con respecto a estos factores significa que el servicio funciona según las expectativas del cliente.
El siguiente paso consiste en definir instrumentos para medir los valores de estos factores. Este trabajo se realiza mediante los siguientes indicadores de nivel de servicio (SLI):
| Indicadores de nivel de servicio | Factores |
|---|---|
| Proporción de dispositivos en línea al número total de dispositivos | Cobertura |
| Proporción de dispositivos que envían informes con frecuencia al número de dispositivos que envían informes | Actualización, rendimiento |
| Proporción de dispositivos que entregan correctamente mensajes al número total de dispositivos | Exactitud |
| Proporción de dispositivos que entregan mensajes rápidamente al número total de dispositivos | Capacidad de procesamiento |
Una vez hecho esto, podemos aplicar una escala deslizante en cada indicador y definir valores de umbral exactos que representen qué significa que el cliente está "satisfecho". En este escenario, se seleccionan los valores de umbral de ejemplo que se establecen en la tabla siguiente con objetivos formales de nivel de servicio (SLO):
| Objetivo de nivel de servicio | Factor |
|---|---|
| El 90 % de los dispositivos informaron métricas no hace más de 10 minutos (estaban en línea) para el intervalo de observación. | Cobertura |
| El 95 % de los dispositivos en línea envían temperatura 10 veces por minuto para el intervalo de observación. | Actualización, rendimiento |
| El 99 % de los dispositivos en línea entregan mensajes correctamente con menos de un 5 % de error para el intervalo de observación. | Exactitud |
| El 95 % de los dispositivos en línea entregan el percentil 90 de los mensajes en un plazo de 50 ms para el intervalo de observación. | Capacidad de procesamiento |
La definición de los SLO también debe describir el enfoque de cómo se miden los valores de los indicadores:
- Intervalo de observación: 24 horas. Las declaraciones SLO son verdaderas en las últimas 24 horas. Esto significa que si una SLI deja de funcionar y interrumpe un SLO correspondiente, se tarda 24 horas después de que el SLI se corrija para considerar el SLO bueno de nuevo.
- Frecuencia de las mediciones: 5 minutos. Hacemos las mediciones para evaluar los valores de SLI cada 5 minutos.
- Lo que se mide: la interacción entre el dispositivo IoT y la nube. El consumo adicional de los datos de temperatura está fuera del ámbito.
Cómo se mide
En este punto, está claro qué vamos a medir y qué valores de umbral usaremos para determinar si el servicio se comporta según las expectativas.
Es habitual medir los indicadores de nivel de servicio, como los que hemos definido, por medio de métricas. Se considera que este tipo de datos de observabilidad tienen valores relativamente pequeños. La información se genera mediante varios componentes del sistema y se recopila en un backend de observabilidad central para supervisarla con paneles, libros de trabajo y alertas.
Vamos a aclarar de qué componentes consta el servicio La Niña:
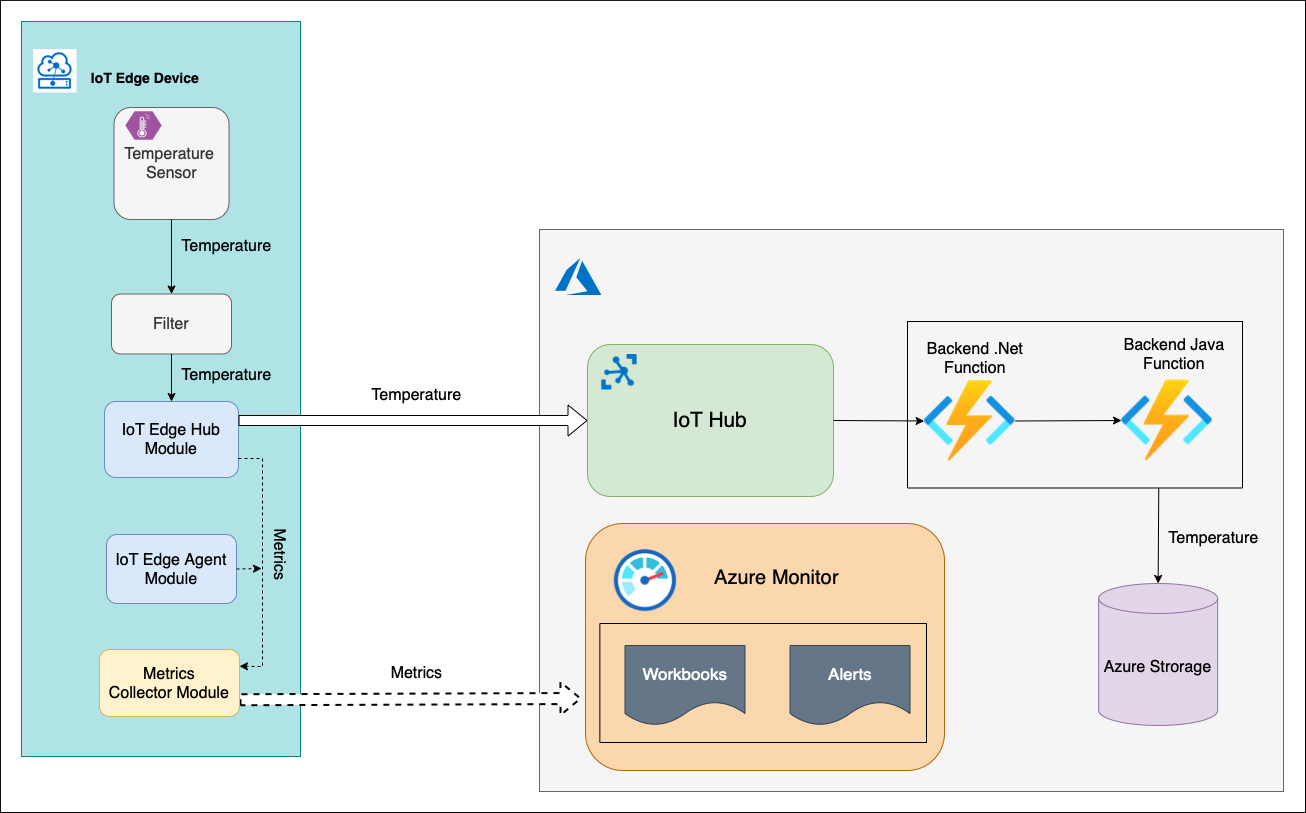
Hay un dispositivo IoT Edge con Temperature Sensor módulo personalizado (C#) que genera un valor de temperatura y lo envía hacia arriba con un mensaje de telemetría. Este mensaje se enruta a otro módulo personalizado Filter (C#). Este módulo compara la temperatura recibida con una ventana de umbral (de 0 a 100 grados centígrados). Si la temperatura está dentro de la ventana, el módulo Filter envía el mensaje de telemetría a la nube.
En la nube, el back-end procesa el mensaje. El back-end consta de una cadena de dos instancias de Azure Functions y una cuenta de almacenamiento. La función .NET de Azure recoge el mensaje de telemetría del punto de conexión de eventos de IoT Hub, lo procesa y lo envía a la función Java de Azure. La función Java guarda el mensaje en el contenedor de blobs de la cuenta de almacenamiento.
Un dispositivo IoT Hub incluye los módulos del sistema edgeHub y edgeAgent. Estos módulos exponen a través de un punto de conexión de Prometheus una lista de métricas integradas. Estas métricas se recopilan e insertan en el servicio Log Analytics de Azure Monitor mediante el módulo recopilador de métricas que se ejecuta en el dispositivo IoT Edge. Además de los módulos del sistema, los módulos Temperature Sensor y Filter también se pueden instrumentar con algunas métricas específicas de la empresa. Sin embargo, los indicadores de nivel de servicio que hemos definido se pueden medir solo con las métricas integradas. Por lo tanto, no es necesario implementar nada más en este momento.
En este escenario, tenemos una flota de 10 boyas. Una de las boyas se configura intencionadamente para mal funcionamiento para que podamos demostrar la detección de problemas y la solución de problemas de seguimiento.
Cómo se supervisa
Vamos a supervisar los objetivos de nivel de servicio (SLO) y los indicadores de nivel de servicio (SLI) correspondientes con los libros de Azure Monitor. La implementación de este escenario incluye el libro LaNina SLO/SLI asignado a IoT Hub.
Para lograr la mejor experiencia del usuario, los libros están diseñados para seguir el concepto ojeada ->examen ->confirmación:
Ojeada
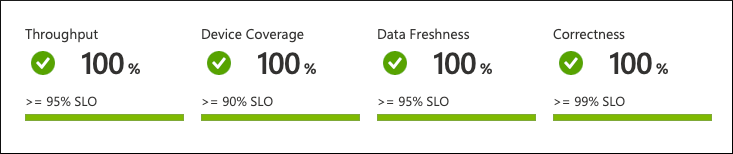
En este nivel, podemos ver todo el panorama de un solo vistazo. Los datos se agregan y representan a nivel de la flota:
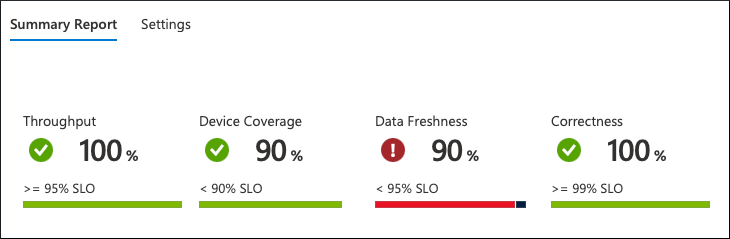
Desde lo que podemos ver, el servicio no funciona según las expectativas. Hay una infracción de la Actualización de datos SLO. Solo el 90 % de los dispositivos envían los datos con frecuencia, y los clientes del servicio esperan un 95 %.
Todos los valores de umbral y de SLO se pueden configurar en la pestaña de configuración del libro:
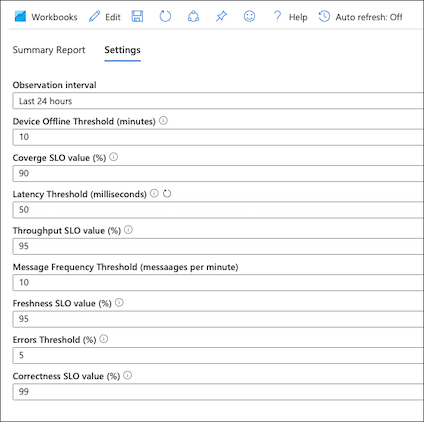
Digitalizar
Al hacer clic en el SLO en infracción, podemos explorar en profundidad el nivel de examen y ver de qué manera los dispositivos contribuyen al valor de SLI agregado.
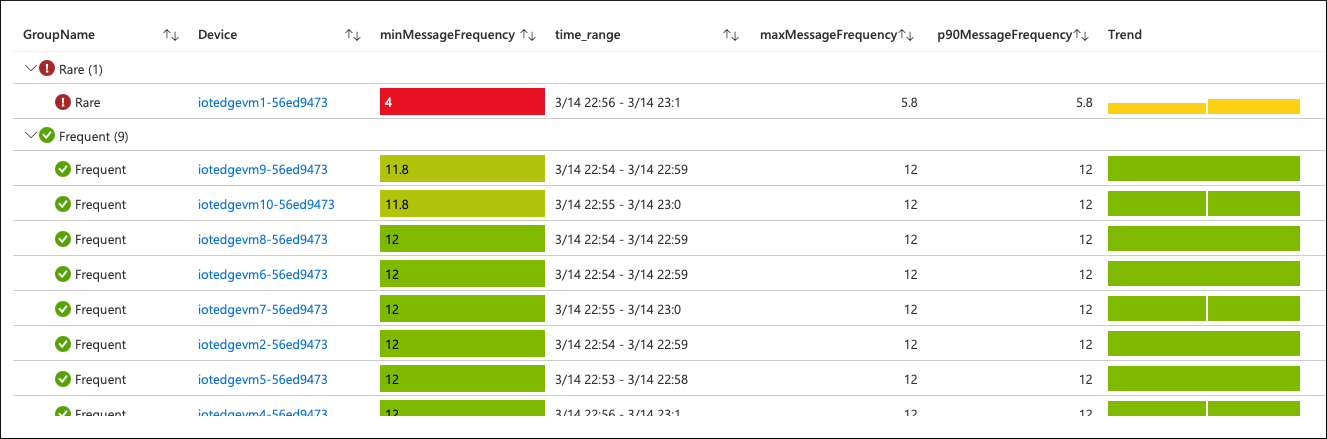
Hay un único dispositivo (de 10) que envía los datos de telemetría a la nube "rara vez". En la definición del SLO, declaramos que "con frecuencia" significa al menos 10 veces por minuto. La frecuencia de este dispositivo está por debajo de ese umbral.
Confirmación
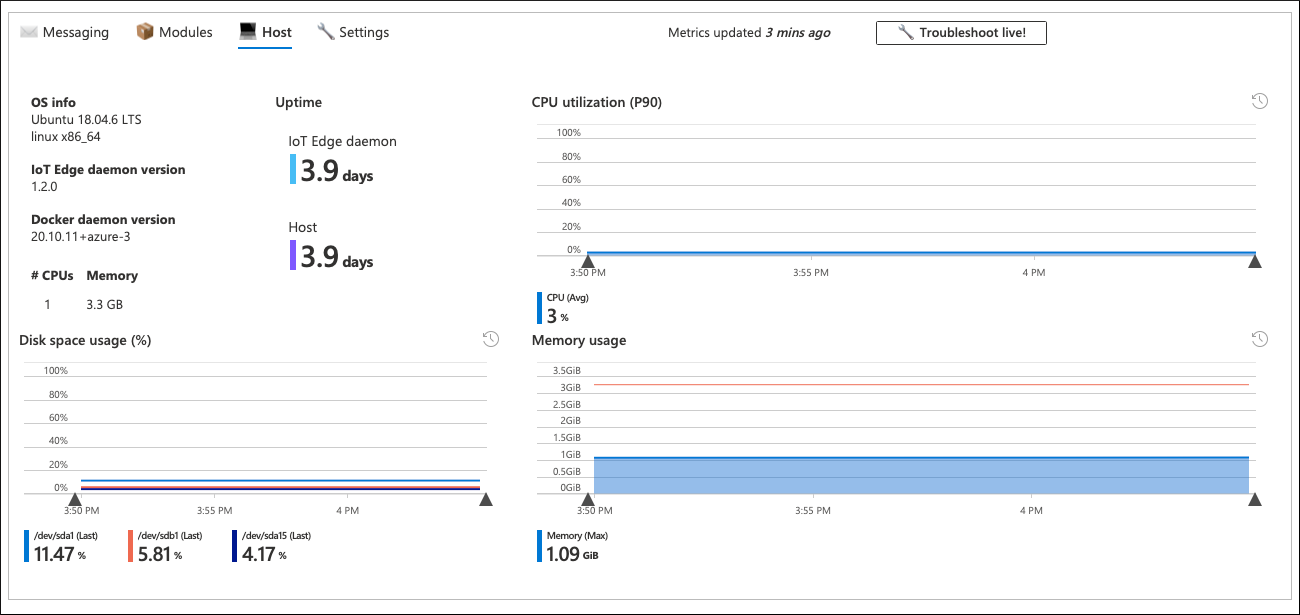
Al hacer clic en el dispositivo problemático, profundizamos en el nivel de confirmación. Se trata de un libro mantenido Detalles del dispositivo que viene de fábrica con la oferta de supervisión de IoT Hub. El libro LaNina SLO/SLI lo reutiliza para aportar los detalles del rendimiento del dispositivo específico.
Solución de problemas
Medir y supervisar nos permite observar y predecir el comportamiento del sistema, compararlo con las expectativas definidas y, en última instancia, detectar problemas existentes o potenciales. Por otro lado, la solución de problemas permite identificar y ubicar la causa del problema.
Solución de problemas de conexiones del Escritorio remoto a una máquina virtual de Azure
El confirmación libro de nivel proporciona información detallada sobre el estado del dispositivo. Esto incluye el consumo de recursos en el nivel de módulo y dispositivo, la latencia de mensajes, la frecuencia, QLen, etc. En muchos casos, esta información puede ayudar a localizar la raíz del problema.
En este escenario, todos los parámetros del dispositivo de problemas tienen un aspecto normal y no es claro por qué el dispositivo envía mensajes con menos frecuencia de lo esperado. La pestaña de mensajería del libro de nivel de dispositivo también confirma lo siguiente:
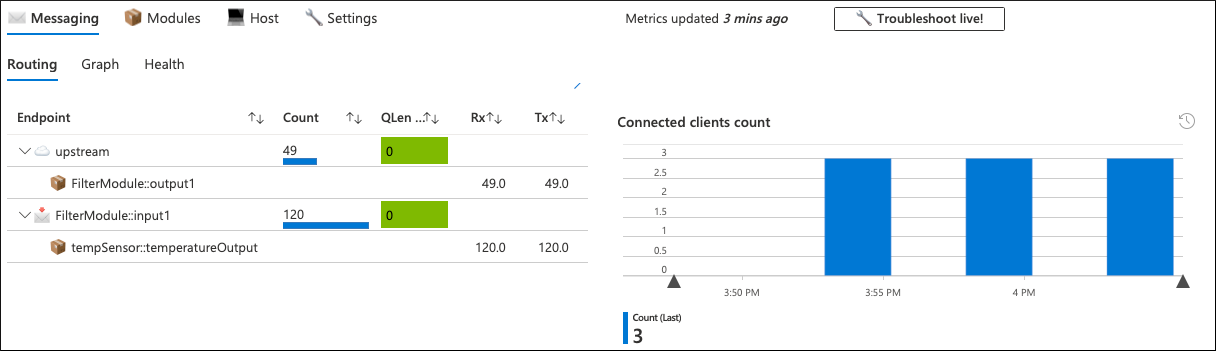
El módulo Temperature Sensor (tempSensor) produjo 120 mensajes de telemetría, pero solo 49 de ellos se subieron a la nube.
En primer lugar, compruebe los registros generados por el Filter módulo. Seleccione Solucionar problemas en directo y, a continuación, seleccione el Filter módulo.
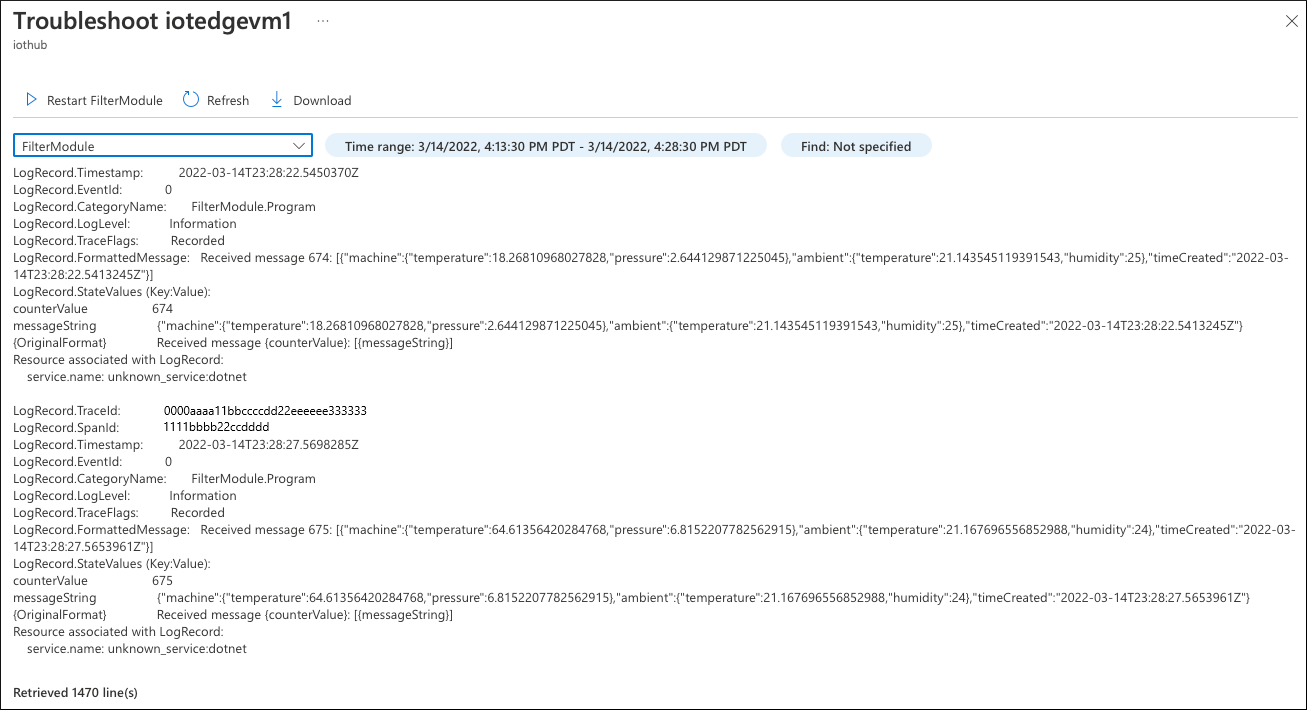
El análisis de los registros del módulo no revela el problema. El módulo recibe mensajes y no hay errores. Todo parece estar bien.
Solución de problemas a fondo
Dos instrumentos de observabilidad sirven para solucionar problemas profundos: seguimientos y registros. En este escenario, los seguimientos muestran cómo un mensaje de telemetría con la temperatura de la superficie del océano viaja desde el sensor al almacenamiento en la nube, qué invoca qué y con qué parámetros. Los registros muestran lo que sucede dentro de cada componente del sistema durante este proceso. La eficacia real de los seguimientos y registros se logra cuando se correlacionan. Con esta configuración, puede leer los registros de un componente de sistema específico, como un módulo en un dispositivo IoT o una función de back-end, mientras procesa un mensaje de telemetría específico.
El servicio La Niña usa OpenTelemetry para generar y recopilar seguimientos y registros en Azure Monitor.
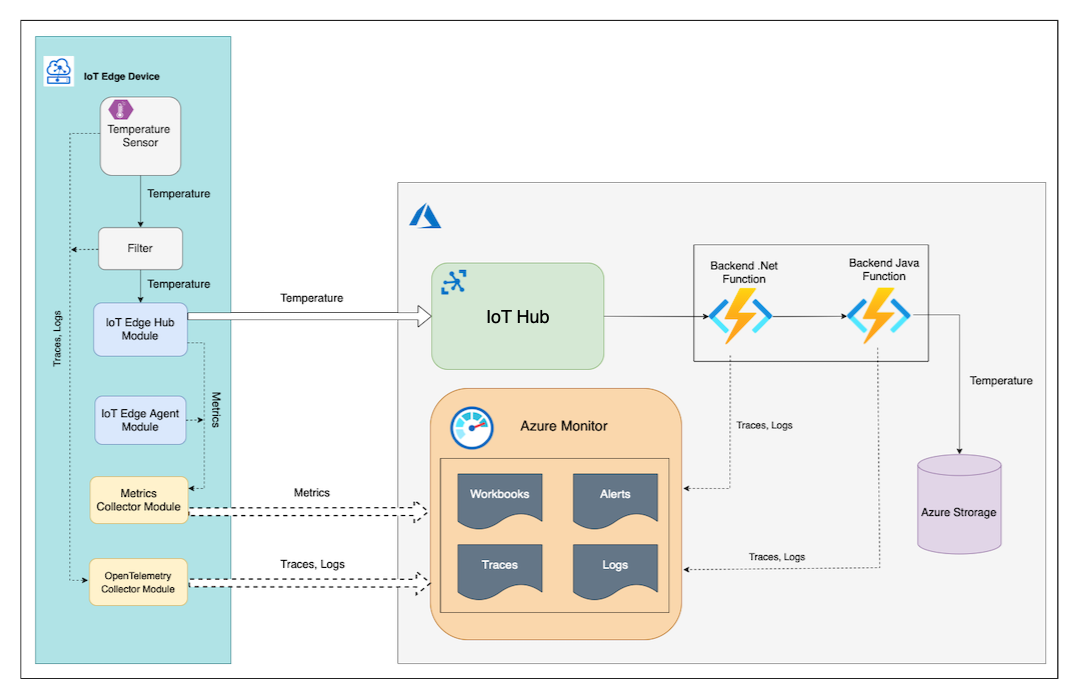
Los módulos de IoT Edge Temperature Sensor y Filter exportar registros y datos de seguimiento mediante OTLP (protocolo OpenTelemetry) en el módulo OpenTelemetryCollector que se ejecuta en el mismo dispositivo perimetral. A continuación, el OpenTelemetryCollector módulo exporta registros y seguimientos a Application Insights de Azure Monitor.
La función de Azure .NET envía datos de seguimiento a Application Insights con el exportador directo de telemetría abierta de Azure Monitor. También envía registros correlacionados directamente a Application Insights mediante una instancia de ILogger configurada.
La función Java de back-end usa el agente Java de instrumentación automática de OpenTelemetry para generar y exportar los datos de seguimiento y registros correlacionados a la instancia de Application Insights.
De forma predeterminada, los módulos de IoT Edge en los dispositivos del servicio La Niña no están establecidos para generar datos de seguimiento y el nivel de registro se establece Informationen . La cantidad de datos de seguimiento se controla mediante un sampler basado en proporción. El muestreador se establece con una probabilidad de que una actividad determinada se incluya en un seguimiento. De forma predeterminada, la probabilidad es 0. Con esta configuración, los dispositivos no inundan Azure Monitor con datos detallados de observabilidad si no es necesario.
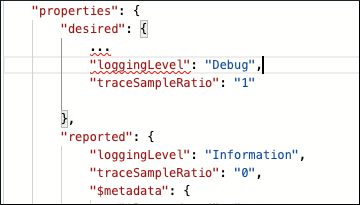
Después de analizar los Information registros de nivel del Filter módulo, debe profundizar en la causa del problema. Actualice las propiedades en los gemelos del módulo Temperature Sensor y Filter, aumente loggingLevel a Debug, y cambie el traceSampleRatio de 0 a 1.
Después de realizar estos cambios, reinicie los Temperature Sensor módulos y Filter :
En unos minutos, los seguimientos y los registros detallados llegan a Azure Monitor desde el dispositivo de problemas. Todo el flujo de mensajes de un extremo a otro desde el sensor del dispositivo al almacenamiento en la nube está disponible para la supervisión con el mapa de aplicaciones en Application Insights:
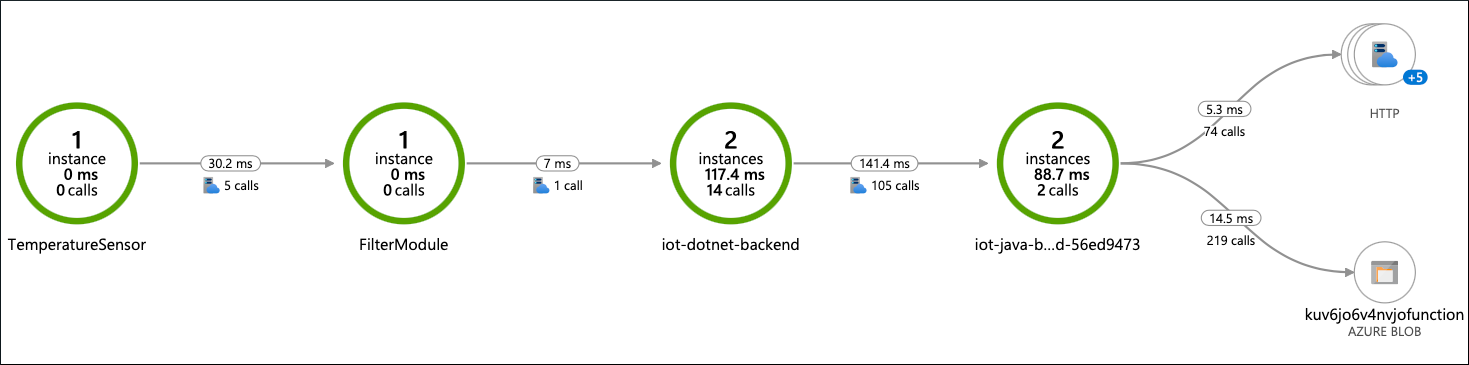
Desde este mapa, puede explorar en profundidad los seguimientos. Algunos seguimientos parecen normales y contienen todos los pasos del flujo, pero algunos son cortos, por lo que no ocurre nada después del Filter módulo.
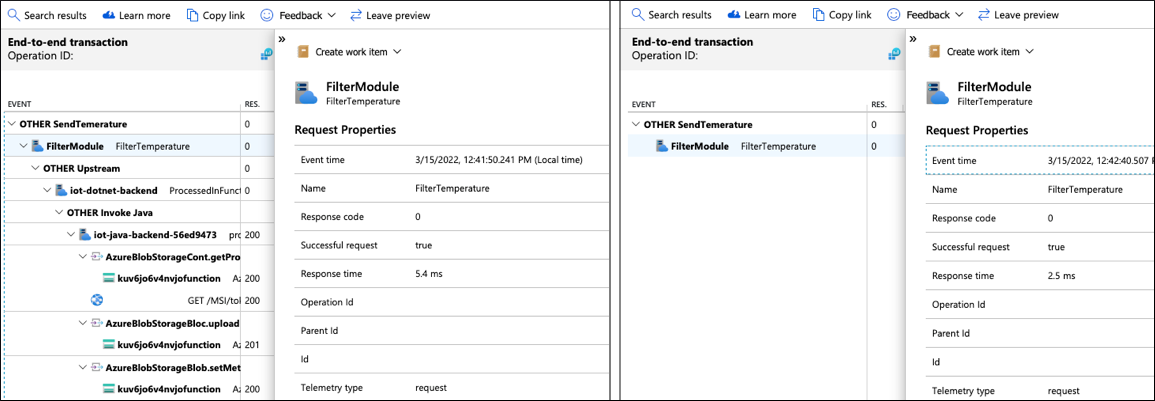
Analice uno de esos seguimientos cortos para averiguar lo que sucedió en el Filter módulo y por qué no envió el mensaje ascendente a la nube.
Dado que los registros se correlacionan con las trazas, puede consultar los registros especificando TraceId y SpanId para recuperar los registros de esta instancia de ejecución del módulo Filter.
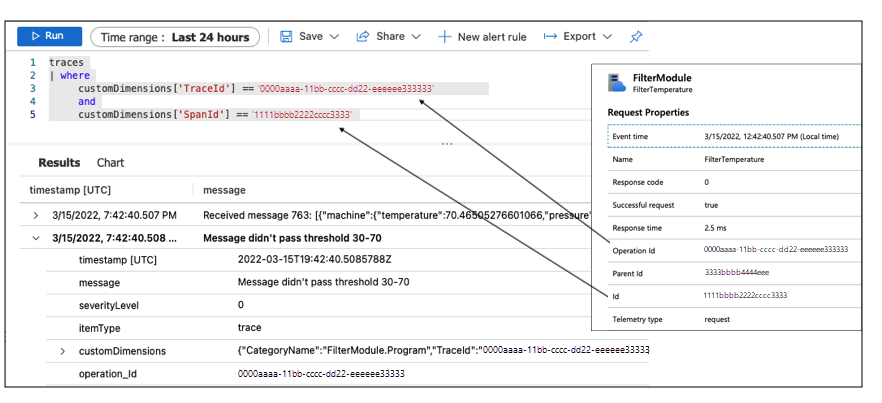
Los registros muestran que el módulo recibió un mensaje con una temperatura de 70,465 grados. Pero el umbral de filtrado establecido en este dispositivo es de 30 a 70. Por lo tanto, el mensaje no ha superado el umbral. Este dispositivo está configurado incorrectamente. Esta configuración es la causa del problema detectado al supervisar el rendimiento del servicio La Niña con el libro de trabajo.
Corrija la configuración del módulo Filter en este dispositivo actualizando las propiedades en el módulo gemelo. Además, reduzca el loggingLevel a Information y configure el traceSampleRatio a 0:

Después de realizar estos cambios, reinicie el módulo. En unos minutos, el dispositivo notifica nuevos valores de métrica a Azure Monitor. Los gráficos del libro de trabajo reflejan estas actualizaciones:
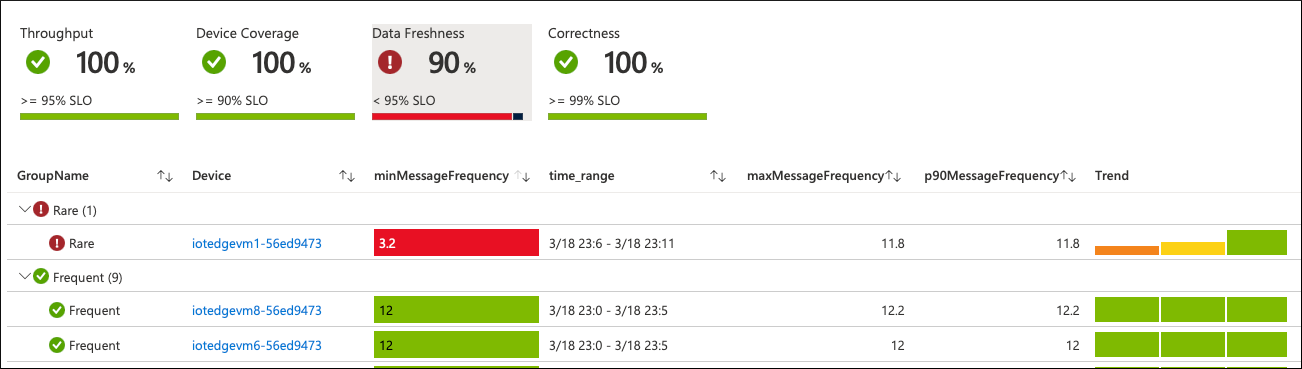
La frecuencia del mensaje en el dispositivo problemático vuelve a ser normal. El valor de SLO general vuelve a ser verde si no ocurre nada más durante el intervalo de observación configurado:
Pruebe el ejemplo
En este momento, puede implementar el ejemplo de escenario en Azure para seguir los pasos y probar sus propios casos de uso.
Para implementar esta solución, necesita:
- PowerShell
- Azure CLI
- Una cuenta de Azure con una suscripción activa. cree una de forma gratuita.
Clone el repositorio IoT Elms.
git clone https://github.com/Azure-Samples/iotedge-logging-and-monitoring-solution.gitAbra una consola de PowerShell y ejecute el script
deploy-e2e-tutorial.ps1../Scripts/deploy-e2e-tutorial.ps1
Pasos siguientes
En este artículo se configurará una solución con capacidades de observabilidad integral para supervisar y solucionar problemas. Un desafío común en estas soluciones para sistemas IoT es enviar datos de observabilidad desde dispositivos a la nube. Se espera que los dispositivos de este escenario estén en línea y tengan una conexión estable a Azure Monitor, pero eso no siempre es el caso.
Vaya a artículos de seguimiento como Seguimiento distribuido con IoT Edge para obtener recomendaciones y técnicas para controlar escenarios en los que los dispositivos suelen estar sin conexión o tienen conexiones limitadas o restringidas al back-end de observabilidad en la nube.