Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo se describe el componente Execute Python Script (Ejecutar script de Python) del diseñador de Azure Machine Learning.
Use este componente para ejecutar código de Python. Para obtener más información sobre los principios de arquitectura y diseño de Python, consulte Ejecutar código de Python en el diseñador de Azure Machine Learning.
Con Python, puede realizar tareas que los componentes existentes no admiten, por ejemplo:
- Visualizar datos mediante
matplotlib. - Usar bibliotecas de Python para enumerar los conjuntos de datos y modelos en el área de trabajo.
- Leer, cargar y manipular datos de orígenes que el componente Importar datos no admite.
- Ejecute su propio código de aprendizaje profundo.
Paquetes de Python compatibles
Azure Machine Learning usa la distribución Anaconda de Python, que incluye muchas utilidades comunes para el procesamiento de datos. La versión de Anaconda se actualizará automáticamente. La versión actual es:
- Distribución de Anaconda para Python 3.10
Para obtener una lista completa, vea la sección Paquetes preinstalados de Python.
Para instalar otros paquetes que no están en la lista preinstalada, por ejemplo scikit-misc, agregue el código siguiente al script:
import os
os.system(f"pip install scikit-misc")
Use el código siguiente para instalar paquetes para mejorar el rendimiento, especialmente para la inferencia:
import importlib.util
package_name = 'scikit-misc'
spec = importlib.util.find_spec(package_name)
if spec is None:
import os
os.system(f"pip install scikit-misc")
Nota
Si la canalización contiene varios componentes Execute Python Script (Ejecutar script de Python) que necesitan paquetes que no están en la lista preinstalada, instale los paquetes en cada componente.
Advertencia
El componente Execute Python Script (Ejecutar script de Python) no admite la instalación de paquetes que dependan de bibliotecas nativas adicionales con comandos de tipo "apt-get", como Java, PyODBC, etc. Esto se debe a que este componente se ejecuta en un entorno simple con Python preinstalado únicamente y con permisos que no son de administrador.
Acceso al área de trabajo actual y a los conjuntos de datos registrados
Puede consultar el siguiente código de ejemplo para acceder a los conjuntos de datos registrados en el área de trabajo:
def azureml_main(dataframe1 = None, dataframe2 = None):
# Execution logic goes here
print(f'Input pandas.DataFrame #1: {dataframe1}')
from azureml.core import Run
run = Run.get_context(allow_offline=True)
#access to current workspace
ws = run.experiment.workspace
#access to registered dataset of current workspace
from azureml.core import Dataset
dataset = Dataset.get_by_name(ws, name='test-register-tabular-in-designer')
dataframe1 = dataset.to_pandas_dataframe()
# If a zip file is connected to the third input port,
# it is unzipped under "./Script Bundle". This directory is added
# to sys.path. Therefore, if your zip file contains a Python file
# mymodule.py you can import it using:
# import mymodule
# Return value must be of a sequence of pandas.DataFrame
# E.g.
# - Single return value: return dataframe1,
# - Two return values: return dataframe1, dataframe2
return dataframe1,
Carga de archivos
El componente Execute Python Script (Ejecutar script de Python) admite la carga de archivos con el SDK de Python de Azure Machine Learning.
En el ejemplo siguiente se muestra cómo cargar un archivo de imagen en el componente Execute Python Script (Ejecutar script de Python):
# The script MUST contain a function named azureml_main,
# which is the entry point for this component.
# Imports up here can be used to
import pandas as pd
# The entry point function must have two input arguments:
# Param<dataframe1>: a pandas.DataFrame
# Param<dataframe2>: a pandas.DataFrame
def azureml_main(dataframe1 = None, dataframe2 = None):
# Execution logic goes here
print(f'Input pandas.DataFrame #1: {dataframe1}')
from matplotlib import pyplot as plt
plt.plot([1, 2, 3, 4])
plt.ylabel('some numbers')
img_file = "line.png"
plt.savefig(img_file)
from azureml.core import Run
run = Run.get_context(allow_offline=True)
run.upload_file(f"graphics/{img_file}", img_file)
# Return value must be of a sequence of pandas.DataFrame
# For example:
# - Single return value: return dataframe1,
# - Two return values: return dataframe1, dataframe2
return dataframe1,
Una vez que termina la ejecución de la canalización, se puede obtener una vista previa de la imagen en el panel derecho del componente.
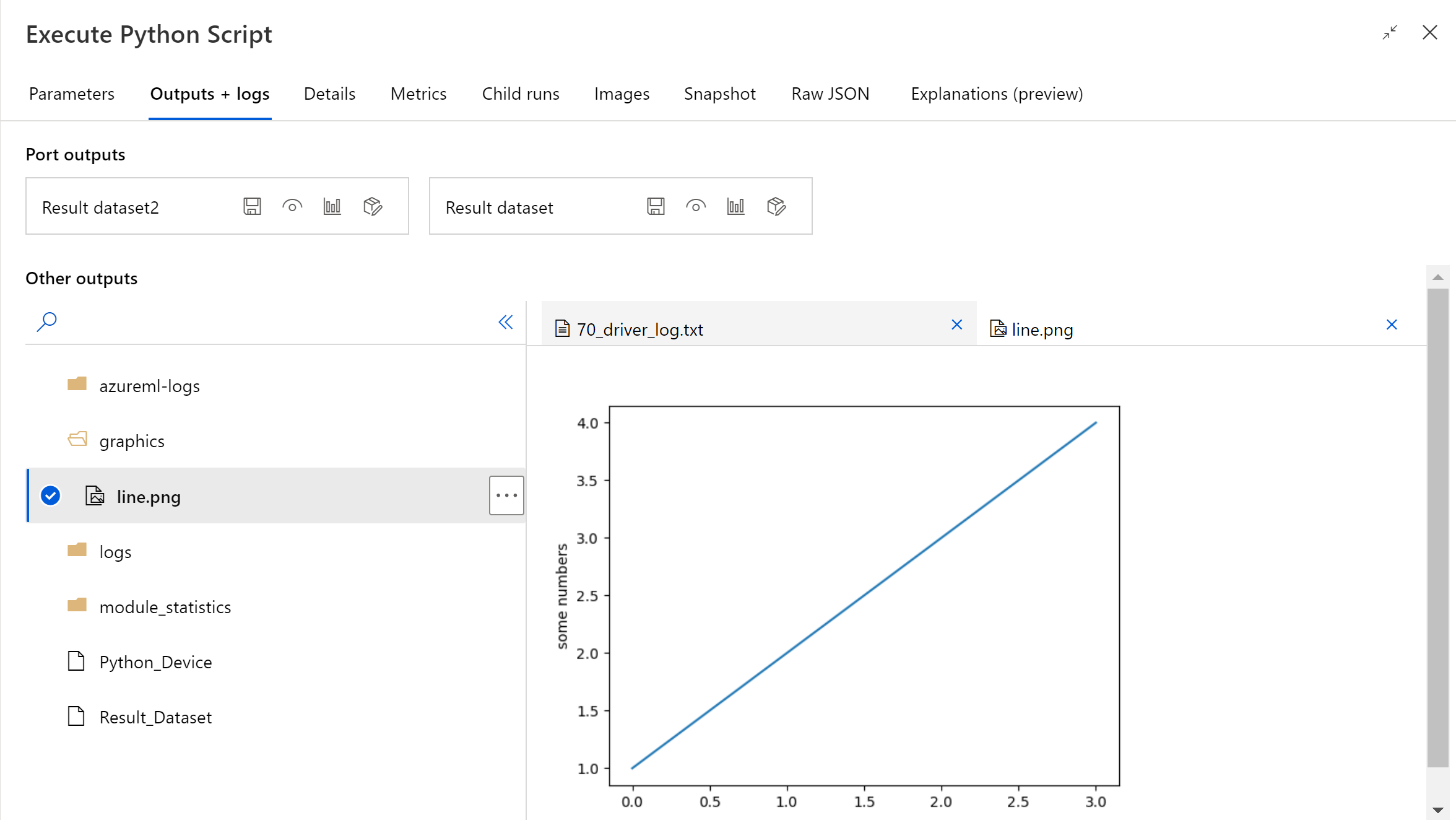
También puede cargar el archivo en cualquier almacén de datos mediante el código siguiente. Solo puede obtener una vista previa del archivo en la cuenta de almacenamiento.
import pandas as pd
# The entry point function MUST have two input arguments.
# If the input port is not connected, the corresponding
# dataframe argument will be None.
# Param<dataframe1>: a pandas.DataFrame
# Param<dataframe2>: a pandas.DataFrame
def azureml_main(dataframe1 = None, dataframe2 = None):
# Execution logic goes here
print(f'Input pandas.DataFrame #1: {dataframe1}')
from matplotlib import pyplot as plt
import os
plt.plot([1, 2, 3, 4])
plt.ylabel('some numbers')
img_file = "line.png"
# Set path
path = "./img_folder"
os.mkdir(path)
plt.savefig(os.path.join(path,img_file))
# Get current workspace
from azureml.core import Run
run = Run.get_context(allow_offline=True)
ws = run.experiment.workspace
# Get a named datastore from the current workspace and upload to specified path
from azureml.core import Datastore
datastore = Datastore.get(ws, datastore_name='workspacefilestore')
datastore.upload(path)
return dataframe1,
Procedimiento para configurar Ejecución de script de Python
El componente Execute Python Script (Ejecución de script de Python) contiene código de Python de ejemplo que puede usar como punto de partida. Para configurar el componente Execute Python Script (Ejecución de script de Python), debe proporcionar un conjunto de entradas y código de Python que se ejecutará en el cuadro de texto Script de Python.
Agregue el componente Execute Python Script (Ejecutar script de Python) a la canalización.
Agregue y conecte en Dataset1 los conjuntos de datos del diseñador que quiera usar para la entrada. Haga referencia a este conjunto de datos en el script de Python como DataFrame1.
El uso de un conjunto de datos es opcional. Úselo si quiere generar datos mediante Python, o use código de Python para importar los datos directamente en el componente.
Este componente admite la adición de un segundo conjunto de datos en Dataset2. Haga referencia al segundo conjunto de datos en el script de Python como DataFrame2.
Los conjuntos de datos almacenados en Azure Machine Learning se convierten automáticamente en dataframes de pandas cuando se cargan con este componente.
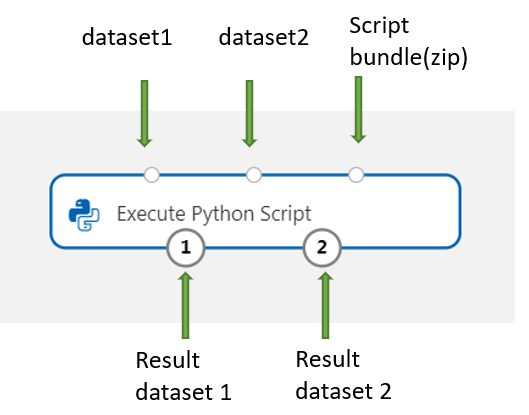
Para incluir nuevos paquetes o código de Python, conecte el archivo comprimido que contiene estos recursos personalizados en el puerto denominado Script bundle (Agrupación de scripts). Asimismo, si el script tiene más de 16 KB, use el puerto denominado Agrupación de scripts para evitar errores parecidos a CommandLine supera el límite de 16 597 caracteres.
- Agrupe el script y otros recursos personalizados en un archivo zip.
- Cargue el archivo zip como un Conjunto de datos de archivo en Studio.
- Arrastre el componente del conjunto de datos de la lista de Conjunto de datos del panel de componentes de la izquierda a la página de creación del diseñador.
- Conecte el componente de conjunto de datos al puerto Script Bundle (Agrupación de scripts) del componente Execute Python Script (Ejecutar script de Python).
Cualquier archivo incluido en el archivo comprimido cargado puede usarse durante la ejecución de la canalización. Si el archivo incluye una estructura de directorios, se conserva esa estructura.
Importante
Use un nombre único y descriptivo para los archivos del conjunto de scripts, ya que algunas palabras comunes (como
test,app, etc.) están reservadas para los servicios integrados.Después se muestra un ejemplo de un conjunto de scripts, que contiene un archivo de script de Python y un archivo txt:
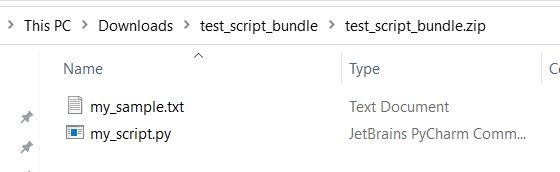
A continuación se muestra el contenido de
my_script.py:def my_func(dataframe1): return dataframe1A continuación se muestra código de ejemplo que muestra cómo consumir los archivos en el conjunto de scripts:
import pandas as pd from my_script import my_func def azureml_main(dataframe1 = None, dataframe2 = None): # Execution logic goes here print(f'Input pandas.DataFrame #1: {dataframe1}') # Test the custom defined Python function dataframe1 = my_func(dataframe1) # Test to read custom uploaded files by relative path with open('./Script Bundle/my_sample.txt', 'r') as text_file: sample = text_file.read() return dataframe1, pd.DataFrame(columns=["Sample"], data=[[sample]])En el cuadro de texto Python Script (Script de Python), escriba o pegue el script de Python válido.
Nota
Tenga cuidado al escribir el script. Asegúrese de que no haya errores de sintaxis, como el uso de variables no declaradas o de funciones o componentes no importados. Preste atención adicional a la lista de componentes preinstalados. Para importar componentes que no aparezcan en la lista, instale los paquetes correspondientes en el script como se indica a continuación:
import os os.system(f"pip install scikit-misc")El cuadro de texto Script de Python se rellena previamente con algunas instrucciones en los comentarios, y código de ejemplo para el acceso a datos y salida. Debe editar o reemplazar este código. Asegúrese de seguir las convenciones de Python sobre la aplicación de sangría y mayúsculas y minúsculas:
- El script debe contener una función denominada
azureml_maincomo punto de entrada para este componente. - La función de punto de entrada debe tener dos argumentos de entrada (
Param<dataframe1>yParam<dataframe2>), aunque estos argumentos no se usen en el script. - Los archivos comprimidos conectados al tercer puerto de entrada se descomprimen y almacenan en el directorio,
.\Script Bundle, que también se agrega asys.pathde Python.
Por lo tanto, si el archivo .zip contiene
mymodule.py, impórtelo medianteimport mymodule.Se pueden devolver dos conjuntos de datos al diseñador, que deben ser una secuencia de tipo
pandas.DataFrame. Puede crear otras salidas en el código de Python y escribirlas directamente en Azure Storage.Advertencia
No se recomienda conectarse a una base de datos ni a otros almacenamientos externos en el componente Execute Python Script (Ejecutar script de Python). Puede usar el componente Importar datos y el componente Exportar datos.
- El script debe contener una función denominada
Envíe la canalización.
Si el componente se ha completado, compruebe si el resultado es el previsto.
Si se produce un error en el componente, debe realizar algunas tareas de solución de problemas. Seleccione el componente y abra Resultados y registros en el panel derecho. Abra 70_driver_log.txt y busque in azureml_main. A continuación, busque la línea que causó el error. Por ejemplo, la línea 17, "File "/tmp/tmp01_ID/user_script.py" de azureml_main" indica que el error se produjo en la línea 17 del script de Python.
Resultados
Los resultados de los cálculos del código de Python insertado deben proporcionarse como pandas.DataFrame, que se convierte automáticamente al formato de conjunto de datos de Azure Machine Learning. Después, puede usar los resultados con otros componentes de la canalización.
El componente devuelve dos conjuntos de datos:
Conjunto de datos de resultados 1, definido por el primer dataframe de pandas devuelto en un script de Python.
Conjunto de datos de resultados 2, definido por el segundo dataframe de pandas devuelto en un script de Python.
Paquetes preinstalados de Python
Los paquetes instalados previamente son:
- adal==1.2.2
- applicationinsights==0.11.9
- attrs==19.3.0
- azure-common==1.1.25
- azure-core==1.3.0
- azure-graphrbac==0.61.1
- azure-identity==1.3.0
- azure-mgmt-authorization==0.60.0
- azure-mgmt-containerregistry==2.8.0
- azure-mgmt-keyvault==2.2.0
- azure-mgmt-resource==8.0.1
- azure-mgmt-storage==8.0.0
- azure-storage-blob==1.5.0
- azure-storage-common==1.4.2
- azureml-core==1.1.5.5
- azureml-dataprep-native==14.1.0
- azureml-dataprep==1.3.5
- azureml-defaults==1.1.5.1
- azureml-designer-classic-modules==0.0.118
- azureml-designer-core==0.0.31
- azureml-designer-internal==0.0.18
- azureml-model-management-sdk==1.0.1b6.post1
- azureml-pipeline-core==1.1.5
- azureml-telemetry==1.1.5.3
- backports.tempfile==1.0
- backports.weakref==1.0.post1
- boto3==1.12.29
- botocore==1.15.29
- cachetools==4.0.0
- certifi==2019.11.28
- cffi==1.12.3
- chardet==3.0.4
- click==7.1.1
- cloudpickle==1.3.0
- configparser==3.7.4
- contextlib2==0.6.0.post1
- cryptography==2.8
- cycler==0.10.0
- dill==0.3.1.1
- distro==1.4.0
- docker==4.2.0
- docutils==0.15.2
- dotnetcore2==2.1.13
- flask==1.0.3
- fusepy==3.0.1
- gensim==3.8.1
- google-api-core==1.16.0
- google-auth==1.12.0
- google-cloud-core==1.3.0
- google-cloud-storage==1.26.0
- google-resumable-media==0.5.0
- googleapis-common-protos==1.51.0
- gunicorn==19.9.0
- idna==2.9
- balanced-learn==0.4.3
- isodate==0.6.0
- itsdangerous==1.1.0
- jeepney==0.4.3
- jinja2==2.11.1
- jmespath==0.9.5
- joblib==0.14.0
- json-logging-py==0.2
- jsonpickle==1.3
- jsonschema==3.0.1
- kiwisolver==1.1.0
- liac-arff==2.4.0
- lightgbm==2.2.3
- markupsafe==1.1.1
- matplotlib==3.1.3
- more-itertools==6.0.0
- msal-extensions==0.1.3
- msal==1.1.0
- msrest==0.6.11
- msrestazure==0.6.3
- ndg-httpsclient==0.5.1
- nimbusml==1.6.1
- numpy==1.18.2
- oauthlib==3.1.0
- pandas==0.25.3
- pathspec==0.7.0
- pip==20.0.2
- portalocker==1.6.0
- protobuf==3.11.3
- pyarrow==0.16.0
- pyasn1-modules==0.2.8
- pyasn1==0.4.8
- pycparser==2.20
- pycryptodomex==3.7.3
- pyjwt==1.7.1
- pyopenssl==19.1.0
- pyparsing==2.4.6
- pyrsistent==0.16.0
- python-dateutil==2.8.1
- pytz==2019.3
- requests-oauthlib==1.3.0
- requests==2.23.0
- rsa==4.0
- ruamel.yaml==0.15.89
- s3transfer==0.3.3
- scikit-learn==0.22.2
- scipy==1.4.1
- secretstorage==3.1.2
- setuptools==46.1.1.post20200323
- six==1.14.0
- smart-open==1.10.0
- urllib3==1.25.8
- websocket-client==0.57.0
- werkzeug==0.16.1
- wheel==0.34.2
Pasos siguientes
Vea el conjunto de componentes disponibles para Azure Machine Learning.