Referencia del componente Extracción de características de n-gramas a partir de texto
En este artículo se describe un componente del diseñador de Azure Machine Learning. Use el componente Extracción de características de n-gramas a partir de texto para caracterizar datos de texto no estructurados.
Configuración del componente Extracción de características de n-gramas a partir de texto
El componente admite los siguientes escenarios de uso de un diccionario de n-gramas:
Creación de un nuevo diccionario de n-gramas a partir de una columna de texto libre.
Uso de un conjunto existente de características de texto para caracterizar una columna de texto libre.
Puntuación o implementación de un modelo que usa n-gramas.
Creación de un nuevo diccionario de n-gramas
Agregue el componente Extracción de características de n-gramas a partir de texto a la canalización y conecte el conjunto de datos que contiene el texto que quiere procesar.
Use Columna de texto para elegir una columna de tipo cadena que contiene el texto que desea extraer. Dado que los resultados son detallados, solo se puede procesar una única columna cada vez.
Establezca Vocabulary mode (Modo Vocabulario) en Create (Crear) para indicar que va a crear una nueva lista de características de n-gramas.
Establezca N-Grams size (Tamaño de los n-gramas) en maximum (máximo) para indicar el tamaño de los n-gramas que se van a extraer y almacenar.
Por ejemplo, si escribe 3, se crearán unigramas, bigramas y trigramas.
Weighting function (Función de ponderación) especifica cómo crear el vector de características del documento y cómo extraer el vocabulario de los documentos.
Binary Weight (Peso binario): asigna un valor de presencia binaria a los n-gramas extraídos. El valor de cada n-grama es 1 si existe en el documento y 0 en caso contrario.
TF Weight (Peso TF): asigna una puntuación de frecuencia de términos (TF) a los n-gramas extraídos. El valor de cada n-grama es su frecuencia de aparición en el documento.
IDF Weight (Peso IDF): asigna una puntuación de frecuencia inversa de documento (IDF) a los n-gramas extraídos. El valor de cada n-grama es el registro del tamaño del corpus dividido por su frecuencia de aparición en todo el corpus.
IDF = log of corpus_size / document_frequencyTF-IDF Weight (Peso TF-IDF): asigna una puntuación de frecuencia de términos o de frecuencia inversa de documento (TF/IDF) a los n-gramas extraídos. El valor de cada n-grama es su puntuación de TF multiplicada por su puntuación de IDF.
Establezca Minimum word length (Longitud mínima de la palabra) en el número mínimo de letras que se pueden usar en una sola palabra de un n-grama.
Use Maximum word length (Longitud máxima de la palabra) para establecer el número máximo de letras que se pueden usar en una sola palabra de un n-grama.
De forma predeterminada, se permiten hasta 25 caracteres por palabra o token.
Use Minimum n-gram document absolute frequency (Frecuencia absoluta mínima de un documento de n-gramas) para establecer el número mínimo de apariciones necesario para que se incluya un n-grama en el diccionario de n-gramas.
Por ejemplo, si usa el valor predeterminado de 5, cualquier n-grama deberá aparecer al menos cinco veces en el corpus para que se pueda incluir en el diccionario de n-gramas.
Establezca Maximum n-gram document ratio (Proporción máxima del documento de n-gramas) en la proporción máxima entre el número de filas que contiene un n-grama determinado y el número de filas total del corpus.
Por ejemplo, una proporción de 1 indicaría que, incluso aunque un n-grama concreto esté presente en todas las filas, se podría agregar al diccionario de n-gramas. Por lo general, una palabra que aparece en todas las filas se considera una palabra irrelevante y se elimina. Para filtrar las palabras irrelevantes que dependen de un dominio, intente reducir esta proporción.
Importante
La frecuencia de aparición de palabras concretas no es uniforme. Varía de un documento a otro. Por ejemplo, si está analizando los comentarios de los clientes sobre un producto específico, el nombre del producto puede tener una frecuencia muy alta y estar próximo a considerarse una palabra irrelevante y, sin embargo, ser un término significativo en otros contextos.
Seleccione la opción Normalize n-gram feature vectors (Normalizar vectores de características de n-gramas) para normalizar los vectores de características. Si esta opción está habilitada, cada vector de características de n-grama se divide por su norma L2.
Envíe la canalización.
Uso de un diccionario de n-gramas existente
Agregue el componente Extracción de características de n-gramas a partir de texto a la canalización y conecte el conjunto de datos que contiene el texto que quiere procesar al puerto Conjunto de datos.
Use Text column (Columna de texto) para seleccionar la columna que contiene el texto que desea caracterizar. De manera predeterminada, el componente selecciona todas las columnas de tipo string. Para obtener los mejores resultados, procese una sola columna cada vez.
Agregue el conjunto de datos guardado que contiene un diccionario de n-gramas que se generó previamente y conéctelo al puerto Input vocabulary (Vocabulario de entrada). También puede conectar la salida Vocabulario resultante de una instancia de nivel superior del componente Extracción de características de n-gramas a partir de texto.
En Vocabulary mode (Modo Vocabulario), seleccione la opción de actualización ReadOnly de la lista desplegable.
La opción ReadOnly representa el corpus de entrada del vocabulario de entrada. En lugar de procesar las frecuencias de los términos a partir del nuevo conjunto de datos de texto (en la entrada de la izquierda), los pesos de los n-gramas del vocabulario de entrada se aplican tal cual están.
Sugerencia
Use esta opción cuando puntúe un clasificador de texto.
Para todas las demás opciones, consulte las descripciones de las propiedades de la sección anterior.
Envíe la canalización.
Creación de una canalización de inferencias que usa n-gramas para implementar un punto de conexión en tiempo real
Las canalizaciones de entrenamiento que contienen Extract N-Grams Feature From Text (Extracción de características de n-gramas del texto) y Score Model (Puntuación de modelos) para hacer predicciones en el conjunto de pruebas se basa en la estructura siguiente:
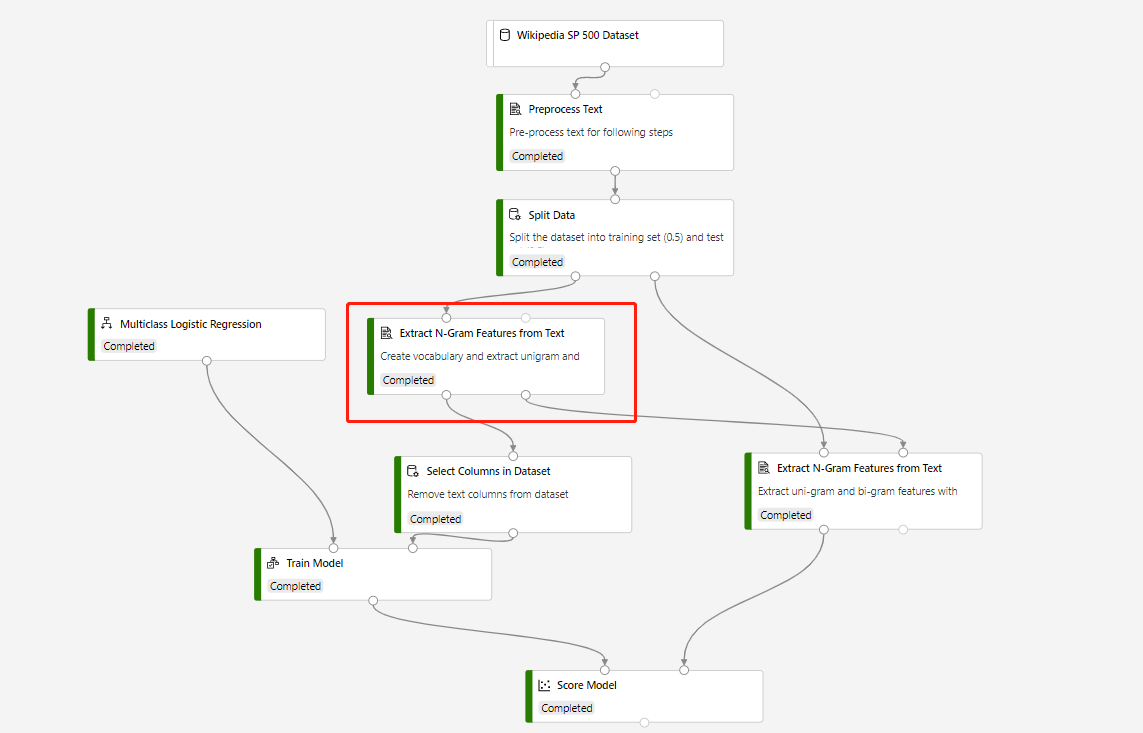
El modo de vocabulario del componente Extracción de características de n-gramas a partir de texto seleccionado es Crear, mientras que el modo de vocabulario del componente que se conecta al componente Puntuación de modelo es Solo lectura.
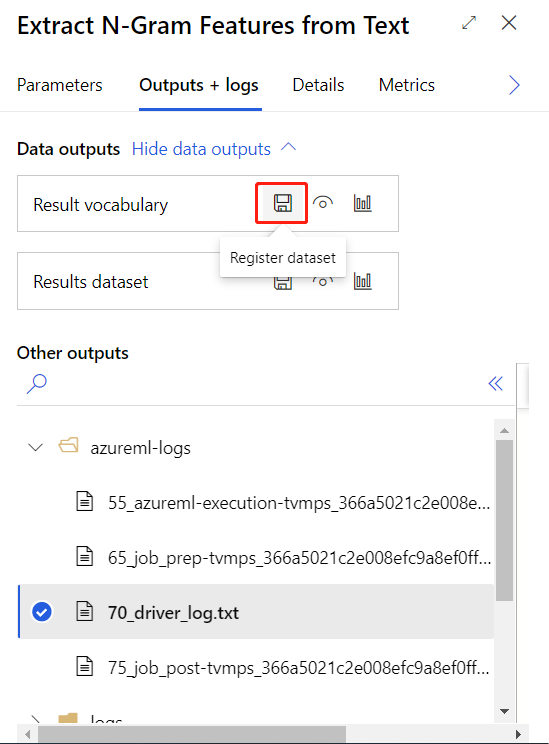
Después de enviar correctamente la canalización de entrenamiento anterior, puede registrar la salida del componente seleccionado como un conjunto de datos.
A continuación, puede crear una canalización de inferencias en tiempo real. Una vez creada la canalización de inferencias, tendrá que ajustarla manualmente tal y como se muestra a continuación:
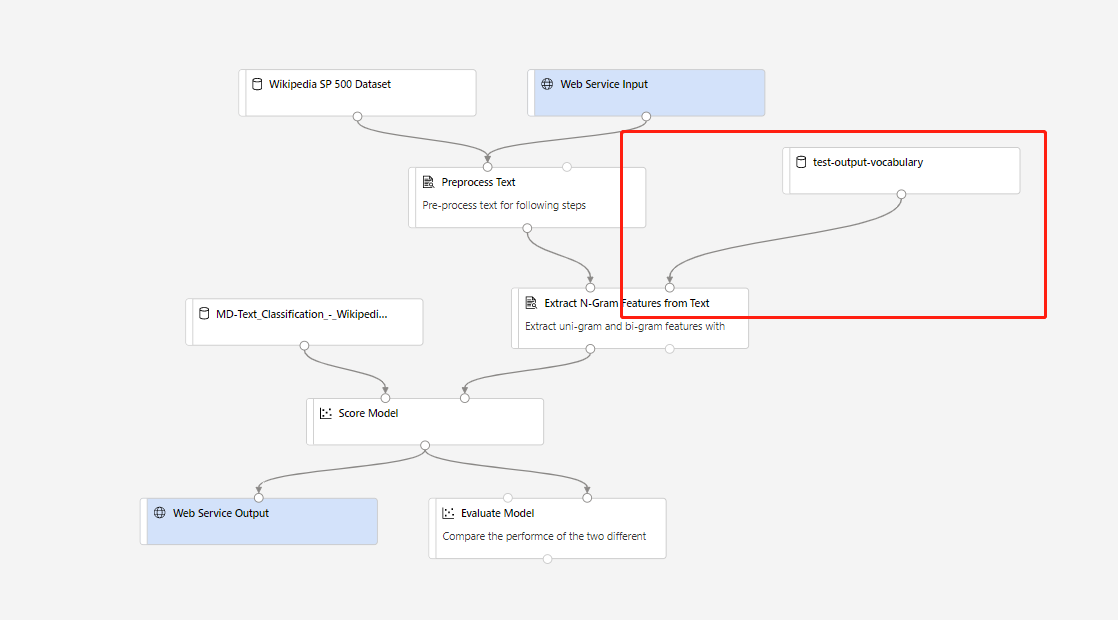
A continuación, envíe la canalización de inferencias e implemente un punto de conexión en tiempo real.
Results
El componente Extracción de características de n-gramas a partir de texto crea dos tipos de salida:
Result dataset (Conjunto de datos del resultado): esta salida es un resumen del texto analizado combinado con los n-gramas extraídos. Las columnas que no seleccionó en la opción Text column (Columna de texto) se pasan a la salida. Por cada columna de texto que se analiza, el componente genera estas columnas:
- Matriz de apariciones de n-gramas: el componente genera una columna para cada n-grama detectado en el corpus total y agrega una puntuación en cada columna para indicar el peso del n-grama en esa fila.
Result vocabulary (Vocabulario resultante): el vocabulario contiene el diccionario de n-gramas real, junto con las puntuaciones de frecuencia de los términos que se generan como parte del análisis. Puede guardar el conjunto de datos para reutilizarlo con un conjunto diferente de entradas o para una actualización posterior. También puede reutilizar el vocabulario para el modelado y la puntuación.
Vocabulario resultante
El vocabulario contiene el diccionario de n-gramas junto con las puntuaciones de frecuencia de los términos que se generan como parte del análisis. Las puntuaciones DF e IDF se generan independientemente de otras opciones.
- Identificador: un identificador generado para cada n-grama único.
- NGram: el n-grama. Los espacios u otros separadores de palabras se reemplazan por el carácter de subrayado.
- DF: la puntuación de frecuencia de términos del n-grama en el corpus original.
- IDF: la puntuación de la frecuencia inversa de documento del n-grama en el corpus original.
Puede actualizar manualmente este conjunto de datos, pero podría cometer errores. Por ejemplo:
- Se genera un error si el componente detecta filas duplicadas con la misma clave en el vocabulario de entrada. Asegúrese de que no haya dos filas en el vocabulario que contengan la misma palabra.
- El esquema de entrada de los conjuntos de datos de vocabulario debe coincidir exactamente, incluidos los tipos y nombres de las columnas.
- Las columnas ID (Identificador) y DF deben ser de tipo entero.
- La columna IDF debe ser de tipo flotante.
Nota:
No conecte directamente la salida de datos al componente Entrenar modelo. Debe quitar las columnas de texto libre antes de introducirlas en el módulo Train Model (Entrenar modelo). De lo contrario, las columnas de texto libre se tratarán como características de categorías.
Pasos siguientes
Vea el conjunto de componentes disponibles para Azure Machine Learning.