Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo se describe un componente del diseñador de Azure Machine Learning.
Use el componente Preprocesamiento de texto para limpiar y simplificar texto. Admite estas operaciones de procesamiento de texto habituales:
- Eliminación de palabras irrelevantes
- Uso de expresiones regulares para buscar y reemplazar cadenas de destino específicas
- Lematización: esta operación convierte varias palabras relacionadas en una única forma canónica
- Normalización de mayúsculas
- Eliminación de ciertas clases de caracteres, como números, caracteres especiales y secuencias de caracteres repetidos, como "aaaa"
- Identificación y eliminación de correos electrónicos y direcciones URL
El componente Preprocesamiento de texto de momento solo admite inglés.
Configuración de Preprocess Text
Agregue el componente Preprocesamiento de texto a la canalización de Azure Machine Learning. Puede encontrar este componente en Text Analytics.
Conecte un conjunto de datos que incluya al menos una columna que contenga texto.
Seleccione el idioma en la lista desplegable Language (Idioma).
Text column to clean (Columna de texto que se va a limpiar): seleccione la columna que quiere preprocesar.
Remove stop words (Eliminar palabras irrelevantes): seleccione esta opción si desea aplicar una lista de palabras irrelevantes predefinida a la columna de texto.
Las listas de palabras irrelevantes dependen del idioma y son personalizables.
Lemmatization (Lematización): seleccione esta opción si desea que las palabras se representen en su forma canónica. Esta opción es útil para reducir el número de apariciones únicas de otros tokens de texto similares.
El proceso de lematización depende en gran medida del idioma.
Detect sentences (Detectar frases): seleccione esta opción si quiere que el componente inserte una marca de límite de frase al realizar el análisis.
Este componente usa una serie de tres caracteres de barra vertical
|||para representar el terminador de frase.Realice operaciones opcionales de búsqueda y reemplazo mediante expresiones regulares. La expresión regular se procesará al principio, antes de todas las demás opciones integradas.
- Custom regular expression (Personalizar expresión regular): defina el texto que está buscando.
- Custom replacement string (Personalizar cadena de sustitución): defina un único valor de sustitución.
Normalize case to lowercase (Normalización de mayúsculas en minúsculas): seleccione esta opción si desea convertir los caracteres ASCII en mayúsculas a sus correspondientes formas en minúsculas.
Si no se normalizan los caracteres, la misma palabra en mayúsculas y minúsculas se considerarán como dos palabras diferentes.
También puede eliminar los siguientes tipos de caracteres o secuencias de caracteres del texto de salida procesado:
Remove numbers (Quitar números): seleccione esta opción para quitar todos los caracteres numéricos del idioma especificado. Los números de identificación dependen del dominio y dependen del idioma. Si los caracteres numéricos forman parte integral de una palabra conocida, es posible que no se quite el número. Obtenga más información en Notas técnicas.
Remove special characters (Quitar caracteres especiales): utilice esta opción para quitar los caracteres especiales no alfanuméricos.
Remove duplicate characters (Quitar caracteres duplicados): seleccione esta opción para quitar los caracteres adicionales de las secuencias que se repiten más de dos veces. Por ejemplo, una secuencia como "aaaaa" se reduciría a "aa".
Remove email addresses (Quitar direcciones de correo electrónico): seleccione esta opción para quitar cualquier secuencia del formato
<string>@<string>.Remove URLs (Quitar direcciones URL): seleccione esta opción para quitar cualquier secuencia que incluya los siguientes prefijos de direcciones URL:
http,https,ftp,www.
Expand verb contractions (Expandir contracciones verbales): esta opción solo se aplica a los idiomas que usan contracciones verbales. Actualmente, solo se aplica al inglés.
Por ejemplo, si selecciona esta opción, podría sustituir la expresión "wouldn't stay there" por "would not stay there" .
Normalize backslashes to slashes (Normalizar barras diagonales inversas en barras diagonales: seleccione esta opción para asignar todas las instancias de
\\a/.Split tokens on special characters (Dividir tokens en caracteres especiales): seleccione esta opción si desea dividir las palabras en caracteres como
&,-, etc. Esta opción también puede reducir los caracteres especiales cuando se repite más de dos veces.Por ejemplo, la cadena
MS---WORDse dividiría en tres tokensMS,-yWORD.Envíe la canalización.
Notas técnicas
El componente Preprocesamiento de texto de Studio (clásico) y el diseñador usan modelos de lenguaje diferentes. El diseñador usa un modelo multitarea entrenado en CNN de spaCy. Los diferentes modelos proporcionan diferentes tokenizadores y etiquetadores de la parte de voz, lo que conduce a resultados diferentes.
A continuación se muestran algunos ejemplos:
| Configuración | Resultado de salida |
|---|---|
| Con todas las opciones seleccionadas Explicación: En los casos como "3test" de "WC-3 3test 4test", el diseñador quita toda la palabra "3test", ya que, en este contexto, el etiquetador de la parte de voz especifica el token "3test" como numérico y, según la parte de la voz, el componente lo quita. |
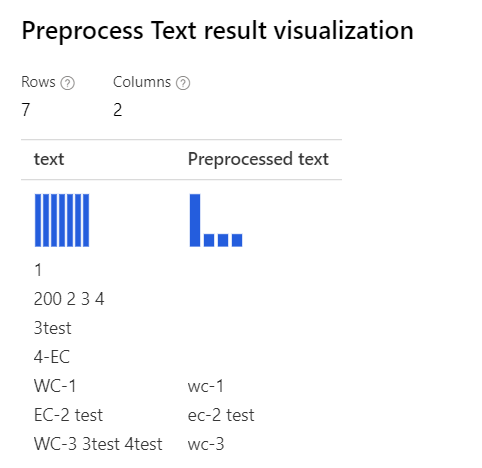
|
Solo con la opción Removing number seleccionada Explicación: En los casos como "3test", "4-EC", la dosis de tokenizador del diseñador no divide estos casos y los trata como los tokens completos. Por lo tanto, no quitará los números de estas palabras. |

|
También puede usar una expresión regular para generar resultados personalizados:
| Configuración | Resultado de salida |
|---|---|
| Con todas las opciones seleccionadas Expresión regular personalizada: (\s+)*(-|\d+)(\s+)*Cadena de reemplazo personalizada: \1 \2 \3 |

|
Con solo Removing number la expresión regular personalizada seleccionada : (\s+)*(-|\d+)(\s+)*cadena de reemplazo personalizada: \1 \2 \3 |
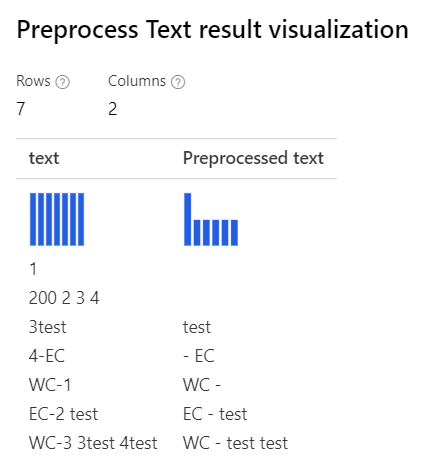
|
Pasos siguientes
Vea el conjunto de componentes disponibles para Azure Machine Learning.