Aprendizaje profundo frente a aprendizaje automático en Azure Machine Learning
En este artículo se explica el aprendizaje profundo frente al aprendizaje automático y cómo encajan en la categoría más amplia de inteligencia artificial. Aprenda sobre las soluciones de aprendizaje profundo que puede crear en Azure Machine Learning, como la detección de fraudes, el reconocimiento facial y de voz, el análisis de opiniones y la previsión de series temporales.
Puede encontrar instrucciones sobre cómo elegir algoritmos para las soluciones en la hoja de referencia rápida de Machine Learning.
Foundation Models de Azure Machine Learning son modelos de aprendizaje profundo entrenados previamente que se pueden ajustar para casos de uso específicos. Obtenga más información sobre Foundation Models (versión preliminar) en Azure Machine Learning y cómo usar Foundation Models en Azure Machine Learning (versión preliminar).
Aprendizaje profundo, Machine Learning e inteligencia artificial
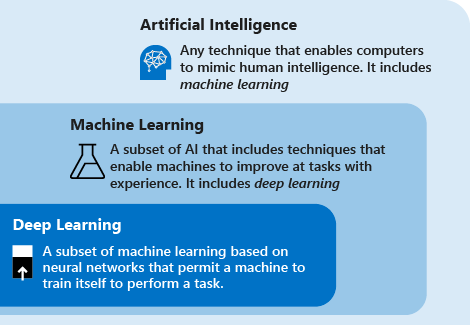
Tenga en cuenta las siguientes definiciones para comprender el aprendizaje profundo y el aprendizaje automático. Inteligencia artificial:
El aprendizaje profundo es un subconjunto del aprendizaje automático basado en redes neuronales artificiales. El proceso de aprendizaje se llama profundo porque la estructura de redes neuronales artificiales se compone de varias capas de entrada, salida y ocultas. Cada capa contiene unidades que transforman los datos de entrada en información que la capa siguiente puede usar para realizar una tarea de predicción determinada. Gracias a esta estructura, una máquina puede aprender a través de su propio procesamiento de datos.
El aprendizaje automático es un subconjunto de la inteligencia artificial que incluye técnicas (como el aprendizaje profundo) que permiten a las máquinas mejorar en las tareas con la experiencia. El proceso de aprendizaje se basa en los pasos siguientes:
- Agregue datos a un algoritmo. (En este paso puede proporcionar información adicional al modelo como, por ejemplo, realizando la extracción de características).
- Utilice estos datos para entrenar un modelo.
- Pruebe e implemente el modelo.
- Use el modelo implementado para realizar una tarea de predicción automatizada. (En otras palabras, llame y use el modelo implementado para recibir las predicciones que devuelva el modelo).
La inteligencia artificial (IA) es una técnica que permite a los equipos imitar la inteligencia humana. Incluye el aprendizaje automático.
La inteligencia artificial generativa es un subconjunto de inteligencia artificial que usa técnicas (como el aprendizaje profundo) para generar contenido nuevo. Por ejemplo, puede usar IA generativa para crear imágenes, texto o audio. Estos modelos aprovechan el conocimiento entrenado previamente de forma masiva para generar este contenido.
Al usar el aprendizaje automático y las técnicas de aprendizaje profundo, puede compilar sistemas y aplicaciones de equipos que realicen tareas que normalmente se asocian a la inteligencia humana. Estas tareas incluyen el reconocimiento de imágenes, el reconocimiento de voz y la traducción de idiomas.
Técnicas del aprendizaje profundo y del aprendizaje automático
Ahora que ya tiene información general acerca del aprendizaje automático y el aprendizaje profundo, vamos a comparar ambas técnicas. En el aprendizaje automático, se debe indicar al algoritmo cómo realizar una predicción precisa; para ello debe conseguir más información (por ejemplo, realizando la extracción de características). En el aprendizaje profundo, en cambio, el algoritmo puede obtener información sobre cómo hacer una predicción precisa a través de su propio procesamiento de datos, gracias a la estructura de red neuronal artificial.
En la tabla siguiente se comparan las dos técnicas con más detalle:
| Todo el aprendizaje automático | Solo aprendizaje profundo | |
|---|---|---|
| Número de puntos de datos | Puede usar pequeñas cantidades de datos para hacer predicciones. | Necesita usar grandes cantidades de datos de entrenamiento para hacer predicciones. |
| Dependencias del hardware | Puede trabajar en equipos lentos. No necesita una gran cantidad de potencia de cálculo. | Depende de máquinas rápidas. Realiza intrínsecamente un gran número de operaciones de multiplicación de matrices. Una GPU puede optimizar eficazmente estas operaciones. |
| Proceso de características | Requiere que los usuarios creen e identifiquen con precisión las características. | Aprende las características de alto nivel de los datos y crea nuevas características automáticamente. |
| Enfoque del aprendizaje | Divide el proceso de aprendizaje en pasos más pequeños. Luego, combina los resultados de cada paso en una salida. | Pasa por el proceso de aprendizaje mediante la resolución del problema de un extremo a otro. |
| Tiempo de ejecución | Comparativamente, tarda menos tiempo en entrenarse; puede tardar unos segundos o unas pocas horas. | Normalmente, tarda demasiado tiempo en entrenarse, porque los algoritmos de aprendizaje profundo tienen muchas capas. |
| Salida | La salida suele ser un valor numérico, como una puntuación o una clasificación. | La salida puede tener varios formatos, como texto, una puntuación o un sonido. |
¿Qué es el aprendizaje de transferencia?
Entrenar modelos de aprendizaje profundo a menudo requiere grandes cantidades de datos de entrenamiento, recursos de proceso de alto nivel (GPU, TPU) y un tiempo de entrenamiento más largo. En escenarios en los que no tenga ninguno de estos disponible, puede obtener acceso directo al proceso de entrenamiento mediante una técnica conocida como aprendizaje por transferencia.
El aprendizaje por transferencia es una técnica que aplica los conocimientos que se adquieren al resolver un problema en un problema diferente, pero relacionado.
Debido a la estructura de redes neuronales, el primer conjunto de capas normalmente contiene características de nivel inferior, mientras que el conjunto final de capas contiene características de nivel superior que están más cerca del dominio en cuestión. Al reasignar las capas finales para su uso en un nuevo dominio o problema, puede reducir significativamente la cantidad de tiempo, datos y recursos de proceso necesarios para entrenar el nuevo modelo. Por ejemplo, si ya tiene un modelo que reconoce automóviles, puede reasignarlo con el aprendizaje por transferencia para que reconozca también camiones, motocicletas y otros tipos de vehículos.
Aprenda a aplicar el aprendizaje por transferencia para la clasificación de imágenes mediante un marco de código abierto en Azure Machine Learning: Entrenamiento de un modelo de PyTorch de aprendizaje profundo mediante aprendizaje por transferencia.
Casos de uso del aprendizaje profundo
A causa de la estructura de la red neuronal artificial, el aprendizaje profundo es excelente para identificar patrones en datos no estructurados, como imágenes, sonido, vídeo y texto. Por esta razón, el aprendizaje profundo está transformando rápidamente muchos sectores, como la atención sanitaria, la energía, las finanzas y el transporte. Gracias a ello, estos sectores se están replanteando los procesos empresariales tradicionales.
En los párrafos siguientes se describen algunas de las aplicaciones más comunes del aprendizaje profundo. En Azure Machine Learning, puede usar un modelo que ha compilado a partir de un marco de código abierto o compilar el modelo con las herramientas proporcionadas.
Reconocimiento de entidades con nombre
El reconocimiento de entidades con nombre es un método de aprendizaje profundo que toma un fragmento de texto como entrada y lo transforma en una clase especificada previamente. Esta nueva información podría ser un código postal, una fecha y un identificador de producto. Asimismo, esa información se puede almacenar en un esquema estructurado para compilar una lista de direcciones, o puede servir como banco de pruebas de un motor de validación de identidades.
Detección de objetos
El aprendizaje profundo se ha aplicado en muchos casos de uso de detección de objetos. La detección de objetos se usa para identificar objetos en una imagen (como automóviles o personas) y proporcionar una ubicación específica para cada objeto con un rectángulo delimitador.
La detección de objetos ya se está usando en sectores como los videojuegos, los comercios minoristas, el turismo y los vehículos autónomos.
Generación de subtítulos para imágenes
De forma similar a la tarea de reconocimiento de imágenes, la generación de subtítulos para imágenes es la tarea en que, para una imagen determinada, el sistema debe generar un subtítulo que describa el contenido de la imagen. Una vez que puede detectar y etiquetar objetos en fotografías, el siguiente paso es convertir esas etiquetas en oraciones descriptivas.
Normalmente, las aplicaciones de subtítulos para imágenes emplean redes neuronales circunvolucionales para identificar los objetos en una imagen y, luego, usan una red neuronal recurrente para convertir las etiquetas en oraciones coherentes.
Traducción automática
La traducción automática toma palabras u oraciones de un idioma y las traduce automáticamente a otro. La traducción automática lleva mucho tiempo utilizándose, pero el aprendizaje profundo está obteniendo magníficos resultados en dos áreas específicas: la traducción automática de texto (y de voz a texto) y la traducción automática de imágenes.
Con la transformación apropiada de los datos, una red neuronal es capaz de comprender texto, audio y señales visuales. La traducción automática se puede usar para identificar fragmentos de sonido en archivos de audio mayores y transcribir la palabra hablada o la imagen como texto.
Análisis de texto
El análisis de texto basado en métodos de aprendizaje profundo implica el análisis de grandes cantidades de datos de texto (por ejemplo, documentos médicos o recibos de gastos), el reconocimiento de patrones y la creación de información organizada y concisa como resultado de dicho análisis.
Las empresas usan el aprendizaje profundo para realizar análisis de texto con el fin de detectar negociaciones en el mercado de valores y el cumplimiento normativo gubernamental. Otro ejemplo común es el fraude en los seguros: el análisis de texto se ha usado a menudo para analizar grandes cantidades de documentos y reconocer las posibilidades de reclamaciones de seguros fraudulentas.
Redes neuronales artificiales
Las redes neuronal artificiales se forman con capas de nodos conectados. Los modelos de aprendizaje profundo usan redes neuronales que tienen un gran número de capas.
En las secciones siguientes se exploran las topologías de redes neuronales artificiales más populares.
Red neuronal del tipo feedforward
La red neuronal de tipo feedforward es el tipo más simple de red neuronal artificial. En una red de tipo feedforward, la información se desplaza solo en una dirección: desde la capa de entrada a la de salida. Las redes neuronales de tipo feedforward transforman una entrada pasándola por una serie de capas ocultas. Cada capa consta de un conjunto de neuronas, donde cada capa está totalmente conectada a todas los neuronas de la capa anterior. Por último, hay una última capa totalmente conectada (la capa de salida) que representa las predicciones generadas.
Red neuronal recurrente (RNN)
Las redes neuronales recurrentes son una red neuronal artificial que se usa ampliamente. Estas redes guardan la salida de una capa y la reenvían a la capa de entrada para poder predecir el resultado de esa capa. Las redes neuronales recurrentes tienen grandes capacidades de aprendizaje. Suelen utilizarse en tareas complejas, como la predicción de series temporales, el aprendizaje de escritura a mano y el reconocimiento de idiomas.
Red neuronal convolucional (CNN)
Una red neuronal convolucional es un tipo especialmente eficaz de red neuronal artificial que presenta una arquitectura única. Las capas se organizan en tres dimensiones: ancho, alto y profundo. Además, las neuronas de una capa no se conectan con todas las neuronas de la capa siguiente, sino que solo se conectan a una pequeña región de la misma. Asimismo, la salida final se reducirá a un solo vector de puntuaciones de probabilidad, organizadas a lo largo de la dimensión de profundidad.
Las redes neuronales circunvolucionadas se han usado en áreas como el reconocimiento de vídeo, el reconocimiento de imágenes y los sistemas de recomendación.
Red generativa antagónica (GAN)
Las redes generativas antagónicas son modelos generativos entrenados para crear contenido realista, como imágenes. Se compone de dos redes, conocidas como generador y discriminador. Ambas redes se entrenan simultáneamente. Durante el entrenamiento, el generador usa ruido aleatorio para crear nuevos datos sintéticos que se parecen mucho a los datos reales. El discriminador toma la salida del generador como entrada y usa datos reales para determinar si el contenido generado es real o sintético. Las redes compiten entre sí. El generador intenta generar contenido sintético que no se pueda distinguir del contenido real y el discriminador intenta clasificar correctamente las entradas como reales o sintéticas. A continuación, la salida se usa para actualizar los pesos de ambas redes para ayudarles a alcanzar mejor sus respectivos objetivos.
Las redes generativas antagónicas se usan para resolver problemas, como la traslación de imagen a imagen y la progresión de la edad.
Transformadores
Los transformadores son una arquitectura de modelo adecuada para resolver problemas que contienen secuencias, como texto o datos de serie temporal. Constan de capas de codificador y descodificador. El codificador toma una entrada y la asigna a una representación numérica que contiene información, como el contexto. El descodificador usa la información del codificador para generar una salida, como texto traducido. Lo que hace que los transformadores sean diferentes de otras arquitecturas que contienen codificadores y descodificadores son las subcapas de atención. La atención es la idea de centrarse en partes específicas de una entrada en función de la importancia de su contexto en relación con otras entradas de una secuencia. Por ejemplo, al resumir un artículo de noticias, no todas las frases son pertinentes para describir la idea principal. Al centrarse en las palabras clave a lo largo del artículo, el resumen se puede realizar en una sola frase, el titular.
Los transformadores se han usado para resolver problemas de procesamiento de lenguaje natural, como la traducción, la generación de texto, la respuesta a preguntas y el resumen de texto.
Algunas implementaciones conocidas de transformadores son:
- Representaciones de codificador bidireccional de transformadores (BERT)
- Transformador generativo previamente generativo 2 (GPT-2)
- Transformador generativo previamente entrenado 3 (GPT-3)
Pasos siguientes
En los artículos siguientes se muestran más opciones para usar modelos de aprendizaje profundo de código abierto en Azure Machine Learning:
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de