Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
SE APLICA A: Extensión ML de la CLI de Azure v2 (actual)SDK de Python azure-ai-ml v2 (actual)
Extensión ML de la CLI de Azure v2 (actual)SDK de Python azure-ai-ml v2 (actual)
Después de entrenar modelos o canalizaciones de Machine Learning, o de encontrar modelos de nuestro catálogo de modelos que se adapten a sus necesidades, debe implementarlos en la producción para que otros usuarios puedan usarlos para hacer inferencias. La inferencia es el proceso de aplicar nuevos datos de entrada al modelo o canalización de Machine Learning para generar salidas. Aunque estas salidas se conocen normalmente como "predicciones", la inferencia se puede usar para generar salidas para otras tareas de aprendizaje automático, como la clasificación y la agrupación en clústeres. En Azure Machine Learning, se realiza la inferencia mediante puntos de conexión.
Puntos de conexión e implementaciones
Un punto de conexión es una URL estable y duradera que puede utilizarse para solicitar o invocar un modelo. Las entradas necesarias se proporcionan al punto de conexión y se devuelven las salidas. Azure Machine Learning permite implementar implementaciones estándar, puntos de conexión en línea y puntos de conexión por lotes. Los puntos de conexión proporcionan:
- una dirección URL estable y duradera (como endpoint-name.region.inference.ml.azure.com),
- un mecanismo de autenticación y
- un mecanismo de autorización.
Una implementación es un conjunto de recursos y procesos necesarios para hospedar el modelo o el componente que realiza la inferencia real. Un punto de conexión contiene una implementación y, para los puntos de conexión en línea y por lotes, un punto de conexión puede contener varias implementaciones. Las implementaciones pueden hospedar recursos independientes y consumir distintos recursos en función de las necesidades de los primeros. Además, un punto de conexión tiene un mecanismo de enrutamiento que puede dirigir las solicitudes a cualquiera de sus implementaciones.
Por un lado, algunos tipos de puntos de conexión de Azure Machine Learning consumen recursos dedicados en sus implementaciones. Para que estos puntos de conexión se ejecuten, debe tener cuota de proceso en la suscripción de Azure. Por otro lado, algunos modelos admiten una implementación sin servidor, lo que les permite consumir ninguna cuota de la suscripción. En el caso de la implementación sin servidor, se le factura según el uso.
Intuición
Supongamos que está trabajando en una aplicación que predice el tipo y el color de un automóvil según su foto. Para esta aplicación, un usuario con determinadas credenciales realiza una solicitud HTTP a una dirección URL y proporciona una imagen de un automóvil como parte de la solicitud. A cambio, el usuario obtiene una respuesta que incluye el tipo y el color del coche como valores de cadena. En este escenario, la dirección URL actúa como punto de conexión.
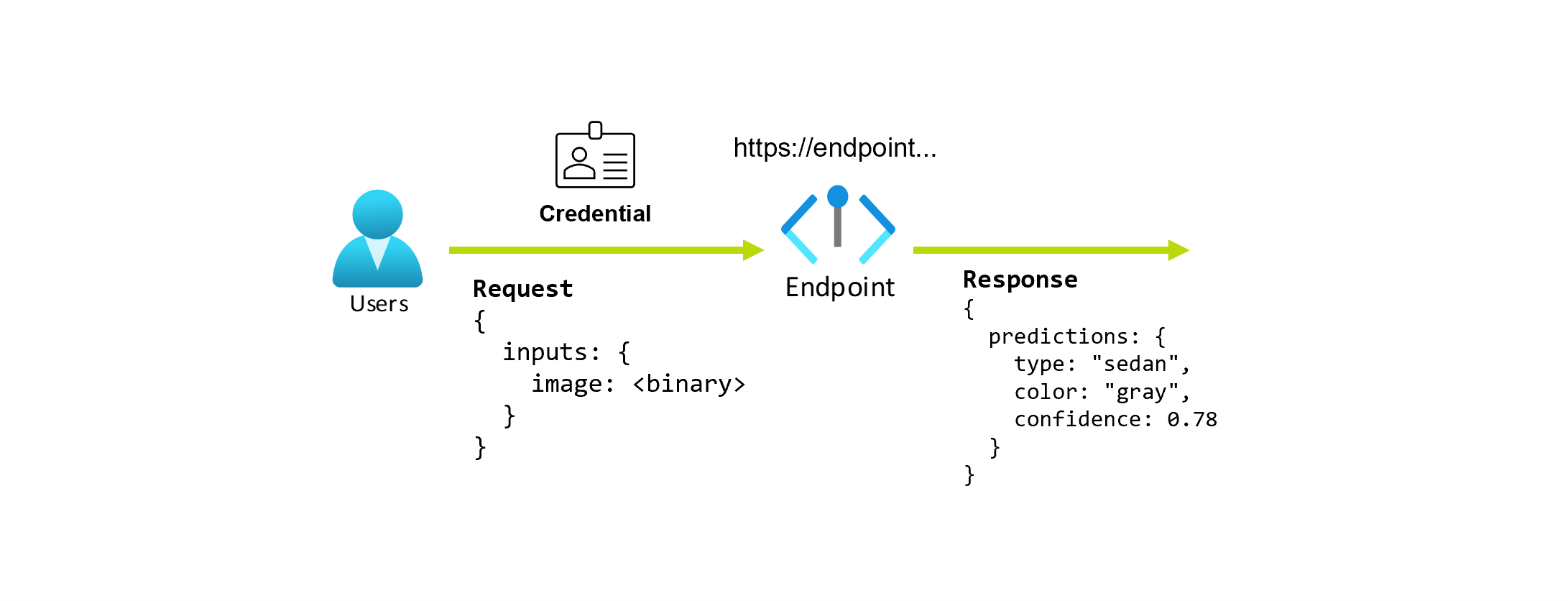
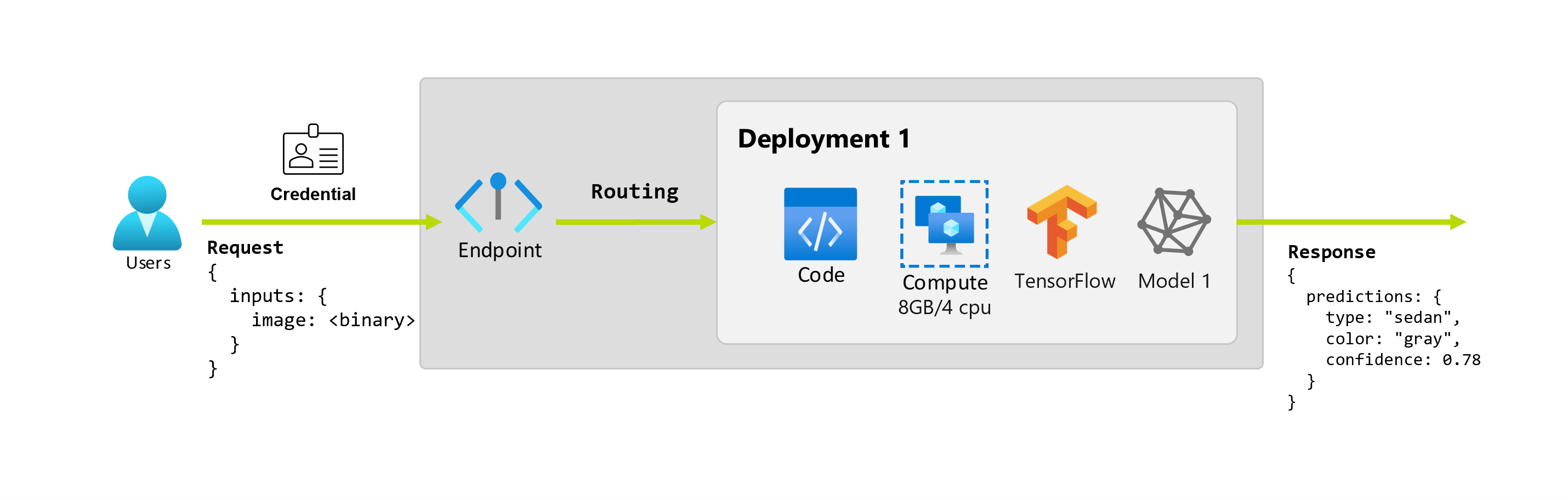
Además, supongamos que una científica de datos, Alice, trabaja en la implementación de la aplicación. Alice sabe mucho sobre TensorFlow y decide implementar el modelo mediante un clasificador secuencial Keras con una arquitectura restNet de TensorFlow Hub. Después de probar el modelo, Alice está satisfecha con los resultados y decide usar el modelo para resolver el problema de predicción del automóvil. El modelo tiene un tamaño grande y necesita 8 GB de memoria con 4 núcleos para ejecutarse. En este escenario, el modelo y los recursos de Alice necesarios para ejecutar el modelo, como el código y el proceso, constituyen una implementación en el punto de conexión.
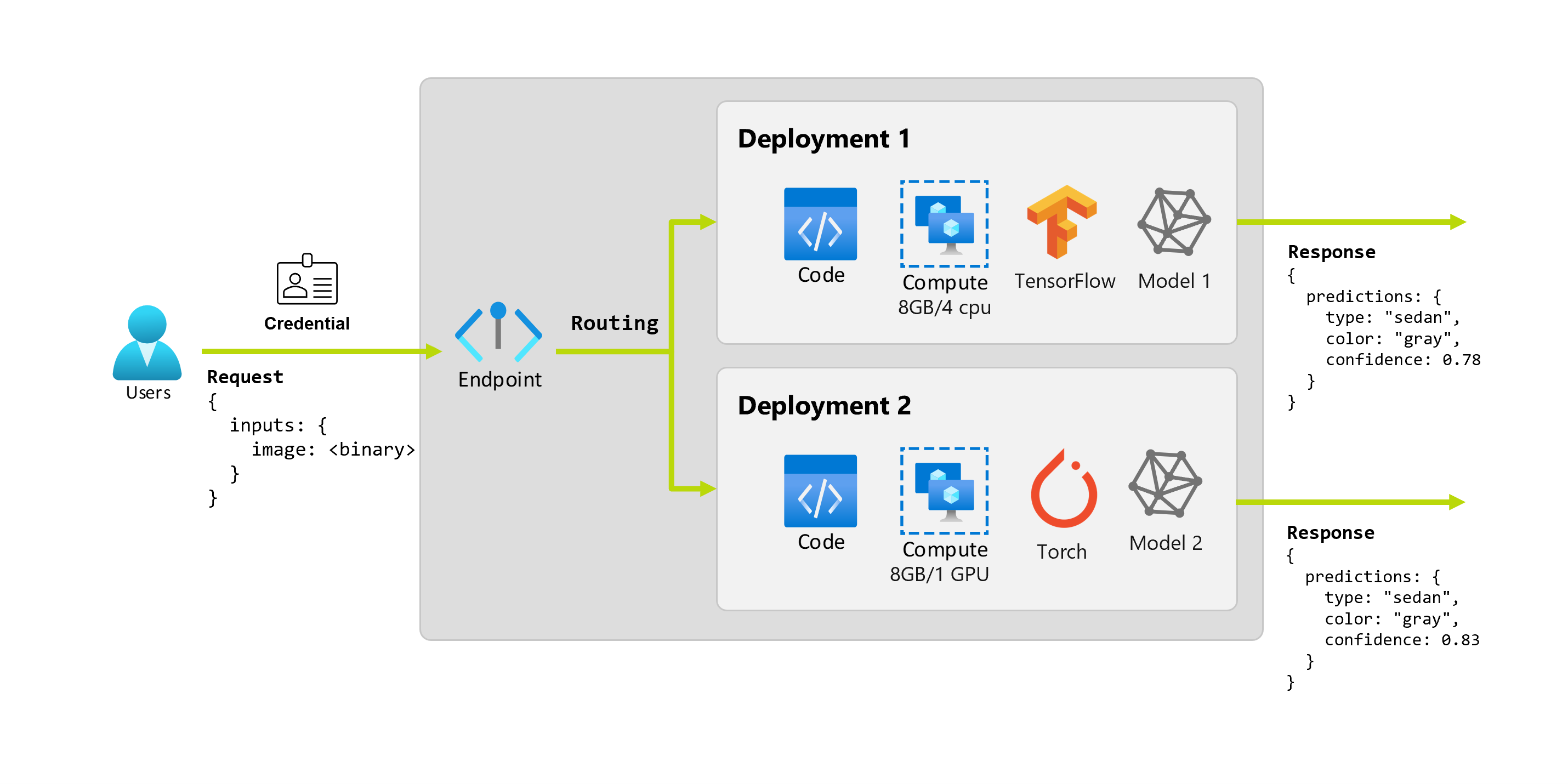
Imaginemos que después de un par de meses, la organización descubre que la aplicación funciona mal en imágenes con condiciones de iluminación no ideales. Bob, otro científico de datos, sabe mucho sobre técnicas de aumento de datos que pueden utilizarse para ayudar al modelo a crear solidez en ese factor. Sin embargo, Bob se siente más cómodo usando Torch a la hora de implementar el modelo y entrena un nuevo modelo con Torch. A Bob le gustaría probar este modelo en producción gradualmente hasta que la organización esté preparada para retirar el antiguo. El nuevo modelo también muestra un mejor rendimiento cuando se implementa en GPU, por lo que la implementación debe incluir una GPU. En este escenario, el modelo y los recursos de Bob necesarios para ejecutar el modelo, como el código y el proceso, constituyen otra implementación en el mismo punto de conexión.
Puntos de conexión: implementación estándar, en línea y por lotes
Azure Machine Learning permite implementar implementaciones estándar, puntos de conexión en línea y puntos de conexión por lotes.
La implementación estándar y los puntos de conexión en línea están diseñados para la inferencia en tiempo real. Siempre que invoque el punto de conexión, los resultados se devuelven en la respuesta del punto de conexión. Las implementaciones estándar no reducen la cuota de tu suscripción; en cambio, se facturan según la tarifa estándar.
Los puntos de conexión de Batch están diseñados para la inferencia por lotes de larga duración. Cada vez que se invoca un punto de conexión por lotes, se genera un trabajo por lotes que lleva a cabo el trabajo real.
Cuándo usar puntos de conexión de implementación estándar, en línea y por lotes
implementación estándar:
Use implementaciones estándar para utilizar modelos fundacionales grandes en inferencias en tiempo real, ya sea listos para usar o para ajustarlos según sus necesidades. No todos los modelos están disponibles para la implementación en implementaciones estándar. Se recomienda usar este modo de implementación cuando:
- El modelo es un modelo básico o una versión optimizada de un modelo básico que está disponible para las implementaciones estándar.
- Puede beneficiarse de una implementación sin cuota.
- No es necesario personalizar la pila de inferencia que se usa para ejecutar el modelo.
Puntos de conexión en línea:
Use puntos de conexión en línea para operacionalizar modelos para la inferencia en tiempo real en solicitudes sincrónicas de baja latencia. Se recomienda usarlos cuando:
- Su modelo es un modelo básico o una versión ajustada de un modelo base, pero no es compatible con la implementación estándar.
- Tiene requisitos de baja latencia.
- El modelo puede responder a la solicitud en un período de tiempo relativamente corto.
- Las entradas del modelo se ajustan a la carga HTTP de la solicitud.
- Debe escalar verticalmente en términos del número de solicitudes.
Puntos de conexión por lotes:
Usa puntos de conexión por lotes para operacionalizar modelos o canalizaciones para la inferencia asincrónica de larga duración. Se recomienda usarlos cuando:
- Tiene modelos o canalizaciones costosos que requieren un tiempo más largo para ejecutarse.
- Quiere operacionalizar canalizaciones de aprendizaje automático y reutilizar componentes.
- Si debe realizar la inferencia en grandes cantidades de datos distribuidos en varios archivos.
- Si no tiene requisitos de latencia baja.
- Las entradas del modelo se almacenan en una cuenta de almacenamiento o en un recurso de datos de Azure Machine Learning.
- Si puede aprovechar la paralelización.
Comparación de puntos de conexión de implementación estándar, en línea y por lotes
Todos los puntos de conexión de implementación estándar, en línea y por lotes se basan en la misma estructura de puntos de conexión, por lo que puede pasar de uno a otro fácilmente. Los puntos de conexión en línea y por lotes también son capaces de administrar varias implementaciones para el mismo punto de conexión.
Puntos de conexión
La siguiente tabla muestra un resumen de las diferentes características de los puntos de conexión de implementación estándar, en línea y por lotes en el nivel de punto de conexión.
| Característica | Implementaciones estándar | Puntos de conexión en línea | Puntos de conexión por lotes |
|---|---|---|---|
| Dirección URL de invocación estable | Sí | Sí | Sí |
| Compatibilidad con varias implementaciones | No | Sí | Sí |
| Enrutamiento de la implementación | Ninguno | División del tráfico | Cambiar al valor predeterminado |
| Tráfico reflejado para el lanzamiento seguro | No | Sí | No |
| Compatibilidad con Swagger | Sí | Sí | No |
| Autenticación | Clave | Clave y Microsoft Entra ID (versión preliminar) | Microsoft Entra ID |
| Compatibilidad con redes privadas (heredada) | No | Sí | Sí |
| Aislamiento de red gestionada | Sí | Sí | Sí (consulte la configuración adicional necesaria) |
| Claves administradas por el cliente | N/D | Sí | Sí |
| Base de costos | Por punto de conexión, por minuto1 | Ninguno | Ninguno |
1Se cobra una pequeña fracción por minuto por el despliegue estándar. Consulte la sección implementaciones para ver los cargos relacionados con el consumo, que se facturan por token.
Implementaciones
La siguiente tabla muestra un resumen de las diferentes características de los puntos de conexión de implementación estándar, en línea y por lotes en el nivel de implementación. Estos conceptos se aplican a cada implementación en el punto de conexión (para puntos de conexión en línea y por lotes) y se aplican a la implementación estándar (donde el concepto de implementación está integrado en el punto de conexión).
| Característica | Implementación estándar | Puntos de conexión en línea | Puntos de conexión por lotes |
|---|---|---|---|
| Tipos de implementación | Modelos | Modelos | Modelos y componentes de canalización |
| Implementación de modelo de MLflow | No, solo modelos específicos del catálogo | Sí | Sí |
| Implementación de modelo personalizado | No, solo modelos específicos del catálogo | Sí, con script de puntuación | Sí, con script de puntuación |
| Implementación de paquetes de modelo 2 | Integrada | Sí (versión preliminar) | No |
| Servidor de inferencia 3 | API de inferencia de modelos de Azure AI | - Servidor de inferencia de Azure Machine Learning -Tritón - Personalizado (mediante BYOC) |
Inferencia por lotes |
| Recurso de proceso consumido | Ninguno (sin servidor) | Instancias o recursos pormenorizados | Instancias de clúster |
| Compute type (Tipo de proceso) | Ninguno (sin servidor) | Proceso administrado y Kubernetes | Proceso administrado y Kubernetes |
| Proceso de prioridad baja | N/D | No | Sí |
| Escala del proceso a cero | Integrada | No | Sí |
| Proceso de escalado automático4 | Integrada | Sí, en función del uso de recursos | Sí, en función del número de trabajos |
| Administración de exceso de capacidad | Limitaciones | Limitaciones | Cola |
| Base de costos5 | Por token | Por implementación: instancias de proceso que se ejecutan | Por trabajo: instancias de proceso consumidas en el trabajo (este valor está limitado al número máximo de instancias del clúster) |
| Pruebas locales de implementaciones | No | Sí | No |
2 La implementación de modelos de MLflow en puntos de conexión sin conectividad saliente a Internet o redes privadas requiere empaquetar el modelo primero.
3 Elservidor de inferencia hace referencia a la tecnología de servicio que toma solicitudes, las procesa y crea respuestas. El servidor de inferencia también dicta el formato de la entrada y las salidas esperadas.
4 Laescalabilidad automática es la capacidad de escalar o reducir verticalmente y de manera dinámica los recursos asignados de la implementación en función de su carga. Las implementaciones en línea y por lotes usan diferentes estrategias de escalado automático. Aunque las implementaciones en línea se escalan y reducen verticalmente en función del uso de recursos (como CPU, memoria, solicitudes, etc.), los puntos de conexión por lotes se escalan o reducen verticalmente en función del número de trabajos creados.
5 Las implementaciones en línea y por lotes cobran por los recursos consumidos. En las implementaciones en línea, los recursos se aprovisionan en el momento de la implementación. En la implementación por lotes, los recursos no se consumen en el momento de la implementación, sino en el momento en que se ejecuta el trabajo. Por lo tanto, no hay ningún costo asociado a la propia implementación por lotes. Del mismo modo, los trabajos en cola tampoco consumen recursos.
Interfaces para desarrolladores
Los puntos de conexión están diseñados para ayudar a las organizaciones a operacionalizar cargas de trabajo de nivel de producción en Azure Machine Learning. Los puntos de conexión son recursos sólidos y escalables y ofrecen las mejores funcionalidades para implementar flujos de trabajo de MLOps.
Puede crear y administrar puntos de conexión por lotes y en línea con varias herramientas de desarrollo:
- La CLI de Azure y el SDK de Python
- API de REST o Azure Resource Manager
- Portal web de Azure Machine Learning Studio
- Azure Portal (TI o administrador)
- Compatibilidad con canalizaciones de MLOps de CI/CD mediante la interfaz de la CLI de Azure y las interfaces de REST y Azure Resource Manager