Evaluación de errores en los modelos de Machine Learning
Uno de los mayores desafíos en las prácticas actuales de depuración de modelos es usar métricas agregadas para puntuar modelos en un conjunto de datos de punto de referencia. La precisión del modelo puede no ser uniforme entre subgrupos de datos y puede haber cohortes de entrada para las que se produce un error en el modelo con más frecuencia. Las consecuencias directas de estos errores son una falta de confiabilidad y seguridad, la aparición de problemas de equidad y la pérdida de confianza en el aprendizaje automático por completo.

El análisis de errores se aleja de las métricas de precisión agregadas. Expone la distribución de los errores a los desarrolladores de forma transparente y les permite identificar y diagnosticar los errores de forma eficaz.
El componente de análisis de errores del panel de IA responsable proporciona a los profesionales de aprendizaje automático una comprensión más profunda de la distribución de errores del modelo y les ayuda a identificar rápidamente cohortes erróneas de datos. Este componente identifica las cohortes de datos con una tasa de errores más alta frente a la tasa de errores de punto de referencia general. Contribuye a la fase de identificación del flujo de trabajo del ciclo de vida del modelo mediante:
- Un árbol de decisión que revela las cohortes con altas tasas de error.
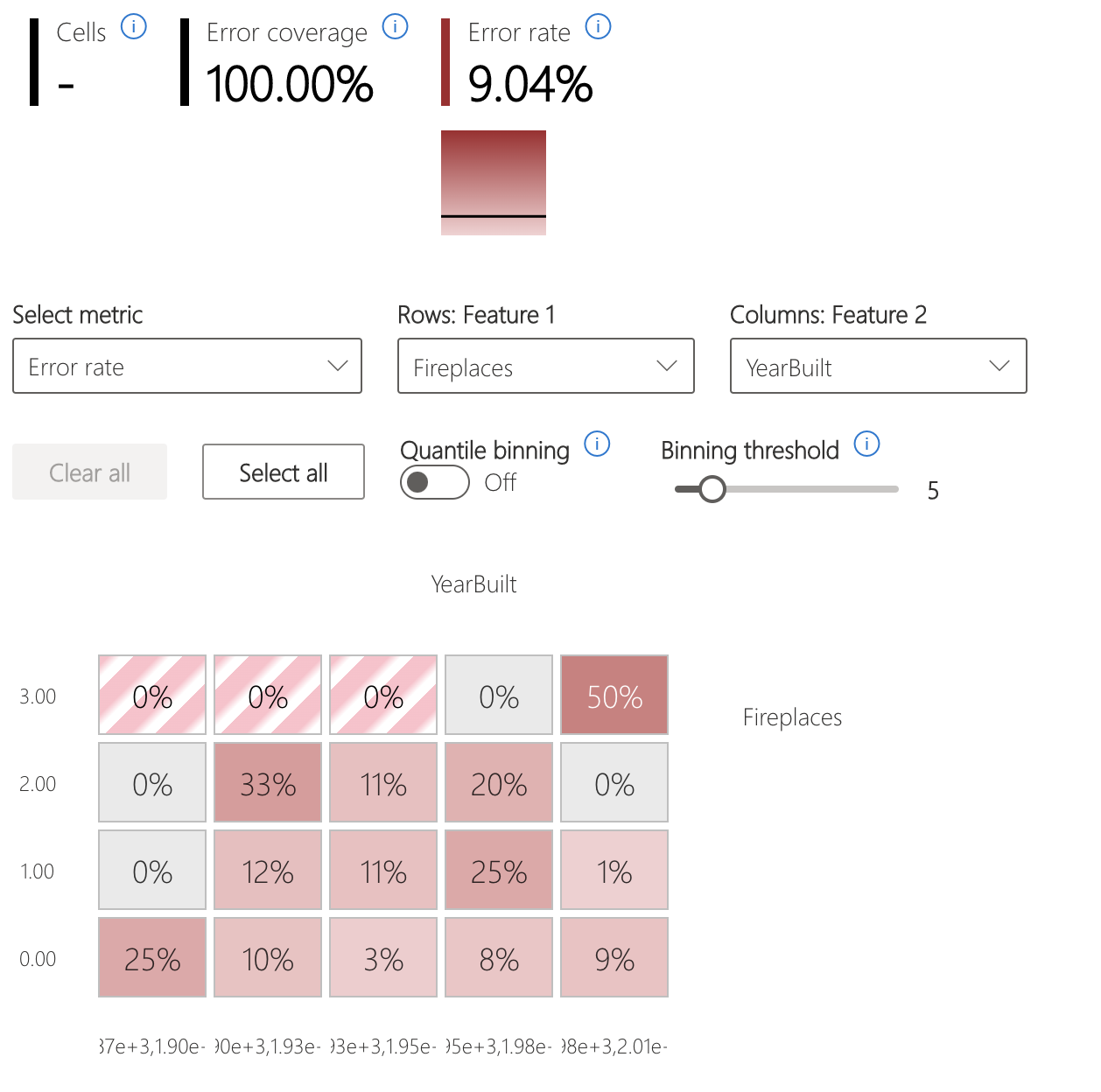
- Mapa térmico que visualiza cómo afectan las características de entrada a la tasa de errores entre cohortes.
Pueden producirse discrepancias de errores cuando el sistema tiene un rendimiento inferior para grupos demográficos específicos o cohortes de entrada observadas con poca frecuencia en los datos de entrenamiento.
Las funcionalidades de este componente proceden del paquete de análisis de errores, que genera perfiles de error del modelo.
Use el análisis de errores cuando necesite:
- Obtener un conocimiento profundo de cómo se distribuyen los errores del modelo en un conjunto de datos determinado y en varias dimensiones de entrada y características.
- Desglosar las métricas de rendimiento agregadas para detectar automáticamente cohortes erróneas para ofrecer información a los pasos de mitigación de destino.
Árbol de errores
A menudo, los patrones de errores son complejos e implican más de una o dos características. Los desarrolladores pueden tener dificultades al explorar todas las combinaciones posibles de características para detectar bolsas de datos ocultas con errores críticos.
Para aliviar esa carga, la visualización de árbol binario divide automáticamente los datos de punto de referencia en subgrupos interpretables, que tienen tasas de errores inesperadamente altas o bajas. Es decir, el árbol usa las características de entrada para separar lo máximo posible los errores del modelo de lo que es correcto. Para cada nodo que define un subgrupo de datos, los usuarios pueden investigar la siguiente información:
- Tasa de errores: una parte de las instancias del nodo para el que el modelo es incorrecto. Se muestra mediante la intensidad del color rojo.
- Cobertura de errores: una parte de todos los errores que se encuentran en el nodo. Se muestra mediante la velocidad de relleno del nodo.
- Representación de datos: número de instancias de cada nodo en el árbol de errores. Se muestra mediante el grosor del borde entrante al nodo junto con el número total real de instancias en el nodo.

Mapa térmico de errores
La vista segmenta los datos basándose en una cuadrícula unidimensional o bidimensional de las características de entrada. Los usuarios pueden elegir las características de entrada de interés para el análisis.
El mapa térmico visualiza las celdas con un número alto de errores mediante un color rojo más oscuro para atraer la atención del usuario a esas regiones. Esta característica es especialmente beneficiosa cuando los temas de error son diferentes entre particiones, lo que ocurre con frecuencia en la práctica. En esta vista de identificación de errores, el análisis está muy dirigido por los usuarios y sus conocimientos o las hipótesis de qué características podrían ser más importantes para comprender el error.
Pasos siguientes
- Aprenda a generar el panel de IA responsable mediante la CLI y el SDK o la UI de Estudio de Azure Machine Learning.
- Explore las visualizaciones de análisis de errores admitidas.
- Obtenga información sobre cómo generar un cuadro de mandos de IA responsable en función de la información observada en el panel de IA responsable.