Configuración de AutoML para entrenar modelos de Computer Vision con Python (v1)
SE APLICA A: Azure ML del SDK de Python v1
Azure ML del SDK de Python v1
Importante
Algunos de los comandos de la CLI de Azure de este artículo usan la extensión azure-cli-ml o v1 para Azure Machine Learning. La compatibilidad con la extensión v1 finalizará el 30 de septiembre de 2025. La extensión v1 se podrá instalar y usar hasta esa fecha.
Se recomienda pasar a la extensión ml, o v2, antes del 30 de septiembre de 2025. Para más información sobre la extensión v2, consulte Extensión de la CLI de Azure ML y SDK de Python v2.
Importante
Esta característica actualmente está en su versión preliminar pública. Esta versión preliminar se proporciona sin un contrato de nivel de servicio. Es posible que algunas características no sean compatibles o que tengan sus funcionalidades limitadas. Para más información, consulte Términos de uso complementarios de las Versiones Preliminares de Microsoft Azure.
En este artículo, aprenderá a entrenar modelos de Computer Vision en datos de imagen con ML automatizado en el SDK de Python de Azure Machine Learning.
ML automatizado admite el entrenamiento de modelos para tareas de Computer Vision, como la clasificación de imágenes, la detección de objetos y la segmentación de instancias. La creación de modelos de AutoML para tareas de Computer Vision se admite actualmente a través del SDK de Python de Azure Machine Learning. Se puede acceder a las ejecuciones, modelos y salidas de experimentación resultantes desde IU de Estudio de Azure Machine Learning. Obtenga más información sobre ML automatizado para tareas de Computer Vision en datos de imagen.
Nota
ML automatizado para tareas de Computer Vision solo está disponible a través del SDK de Python de Azure Machine Learning.
Requisitos previos
Un área de trabajo de Azure Machine Learning. Para crear el área de trabajo, consulte Creación de recursos del área de trabajo.
El SDK de Azure Machine Learning para Python instalado. Para instalar el SDK, puede:
Crear una instancia de proceso, que instala automáticamente el SDK y está preconfigurada para flujos de trabajo de aprendizaje automático. Para más información, consulte Creación y administración de una instancia de proceso de Azure Machine Learning.
Instale el paquete
automl, que incluye la instalación predeterminada del SDK.
Nota
Solo Python 3.7 y 3.8 son compatibles con el soporte de ML automatizado para tareas de Computer Vision.
Selección de su tipo de tarea
ML automatizado para imágenes admite los siguientes tipos de tareas:
| Tipo de tarea | sintaxis de configuración de AutoMLImage |
|---|---|
| clasificación de imágenes | ImageTask.IMAGE_CLASSIFICATION |
| clasificación de imágenes con varias etiquetas | ImageTask.IMAGE_CLASSIFICATION_MULTILABEL |
| detección de objetos de imagen | ImageTask.IMAGE_OBJECT_DETECTION |
| segmentación de instancias de imagen | ImageTask.IMAGE_INSTANCE_SEGMENTATION |
Este tipo de tarea es un parámetro obligatorio y se pasa mediante el parámetro task en AutoMLImageConfig.
Por ejemplo:
from azureml.train.automl import AutoMLImageConfig
from azureml.automl.core.shared.constants import ImageTask
automl_image_config = AutoMLImageConfig(task=ImageTask.IMAGE_OBJECT_DETECTION)
Datos de entrenamiento y validación
Para generar modelos para Computer Vision, debe traer datos de imagen etiquetados como entrada para el entrenamiento del modelo en forma de TabularDataset de Azure Machine Learning. Puede usar un objeto TabularDataset que haya exportado desde un proyecto de etiquetado de datos o crear un nuevo TabularDataset con los datos de entrenamiento etiquetados.
Si los datos de entrenamiento están en un formato diferente (por ejemplo, Pascal VOC o COCO), puede aplicar los scripts auxiliares incluidos con los cuadernos de ejemplo para convertir los datos a JSONL. Obtenga más información sobre la preparación de datos para tareas de Computer Vision con ML automatizado.
Advertencia
La creación de TabularDatasets a partir de datos en formato JSONL solo se admite mediante el SDK para esta funcionalidad. En este momento no se admite la creación del conjunto de datos a través de la interfaz de usuario. A partir de ahora, la interfaz de usuario no reconoce el tipo de datos StreamInfo, que es el tipo de datos que se usa para las direcciones URL de imagen en formato JSONL.
Nota
El conjunto de datos de entrenamiento debe tener al menos 10 imágenes para poder enviar una ejecución de AutoML.
Ejemplos de esquemas JSONL
La estructura del TabularDataset depende de la tarea que se vaya a realizar. Para los tipos de tareas de Computer Vision, consta de los siguientes campos:
| Campo | Descripción |
|---|---|
image_url |
Contiene filepath como un objeto StreamInfo. |
image_details |
La información de metadatos de imagen consta de alto, ancho y formato. Este campo es opcional y, por tanto, puede existir o no. |
label |
Representación json de la etiqueta de imagen, basada en el tipo de tarea. |
A continuación se muestra un archivo JSONL de ejemplo para la clasificación de imágenes:
{
"image_url": "AmlDatastore://image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label": "cat"
}
{
"image_url": "AmlDatastore://image_data/Image_02.jpeg",
"image_details":
{
"format": "jpeg",
"width": "3456px",
"height": "3467px"
},
"label": "dog"
}
El código siguiente es un archivo JSONL de ejemplo para la detección de objetos:
{
"image_url": "AmlDatastore://image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label":
{
"label": "cat",
"topX": "1",
"topY": "0",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "true",
}
}
{
"image_url": "AmlDatastore://image_data/Image_02.png",
"image_details":
{
"format": "jpeg",
"width": "1230px",
"height": "2356px"
},
"label":
{
"label": "dog",
"topX": "0",
"topY": "1",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "false",
}
}
Consumo de datos
Una vez que los datos están en formato JSONL, puede crear un objeto TabularDataset con el código siguiente:
ws = Workspace.from_config()
ds = ws.get_default_datastore()
from azureml.core import Dataset
training_dataset = Dataset.Tabular.from_json_lines_files(
path=ds.path('odFridgeObjects/odFridgeObjects.jsonl'),
set_column_types={'image_url': DataType.to_stream(ds.workspace)})
training_dataset = training_dataset.register(workspace=ws, name=training_dataset_name)
ML automatizado no impone ninguna restricción en el tamaño de los datos de entrenamiento o validación para las tareas de Computer Vision. El tamaño máximo del conjunto de datos solo está limitado por la capa de almacenamiento detrás del conjunto de datos (es decir, el almacén de blobs). No hay ningún número mínimo de imágenes o etiquetas. Sin embargo, se recomienda empezar con un mínimo de 10-15 ejemplos por etiqueta para asegurarse de que el modelo de salida está suficientemente entrenado. Cuanto mayor sea el número total de etiquetas o clases, más ejemplos necesitará por etiqueta.
Los datos de entrenamiento son obligatorios y se pasan mediante el parámetro training_data. Opcionalmente, puede especificar otro TabularDataset como conjunto de datos de validación que se usará para el modelo con el parámetro validation_data de AutoMLImageConfig. Si no se especifica ningún conjunto de datos de validación, el 20 % de los datos de entrenamiento se usará para la validación de forma predeterminada, a menos que pase el argumento validation_size con un valor diferente.
Por ejemplo:
from azureml.train.automl import AutoMLImageConfig
automl_image_config = AutoMLImageConfig(training_data=training_dataset)
Proceso para ejecutar el experimento
Proporcione un destino de proceso para que ML automatizado realice el entrenamiento del modelo. Los modelos de ML automatizado para tareas de Computer Vision requieren SKU de GPU y son compatibles con las familias NC y ND. Se recomienda la serie NCsv3 (con GPU v100) para un entrenamiento más rápido. Un destino de proceso con una SKU de máquina virtual con varias GPU aprovecha varias GPU para acelerar también el entrenamiento. Además, al configurar un destino de proceso con varios nodos, puede realizar un entrenamiento del modelo más rápido a través del paralelismo al ajustar hiperparámetros para el modelo.
Nota
Si usa una instancia de proceso como destino de proceso, asegúrese de que varios trabajos de AutoML no se ejecuten al mismo tiempo. Además, asegúrese de que max_concurrent_iterations está establecido en 1 en los recursos del experimento.
El destino de proceso es un parámetro obligatorio y se pasa mediante el parámetro compute_target de AutoMLImageConfig. Por ejemplo:
from azureml.train.automl import AutoMLImageConfig
automl_image_config = AutoMLImageConfig(compute_target=compute_target)
Configuración de algoritmos de modelo e hiperparámetros
Con la compatibilidad con tareas de Computer Vision, puede controlar el algoritmo del modelo y los hiperparámetros de barrido. Estos algoritmos de modelo y los hiperparámetros se pasan como espacio de parámetros para el barrido.
El algoritmo del modelo es necesario y se pasa a través del parámetro model_name. Puede especificar un único model_name o elegir entre varios.
Algoritmos de modelo admitidos
En la tabla siguiente se resumen los modelos admitidos para cada tarea de Computer Vision.
| Tarea | Algoritmos de modelo | Sintaxis de literal de cadenadefault_model* indicado con * |
|---|---|---|
| Clasificación de imágenes (varias clases y varias etiquetas) |
MobileNet: modelos ligeros para aplicaciones móviles ResNet: redes residuales ResNeSt: redes de atención dividida SE-ResNeXt50: redes de compresión y excitación ViT: redes de transformadores de visión |
mobilenetv2 resnet18 resnet34 resnet50 resnet101 resnet152 resnest50 resnest101 seresnext vits16r224 (pequeña) vitb16r224* (base) vitl16r224 (grande) |
| Detección de objetos | YOLOv5: modelo de detección de objetos de una fase Faster RCNN ResNet FPN: modelos de detección de objetos de dos fases RetinaNet ResNet FPN: desequilibrio de la clase de dirección con pérdida focal Nota: Consulte el hiperparámetro model_size para ver los tamaños de modelo YOLOv5. |
yolov5* fasterrcnn_resnet18_fpn fasterrcnn_resnet34_fpn fasterrcnn_resnet50_fpn fasterrcnn_resnet101_fpn fasterrcnn_resnet152_fpn retinanet_resnet50_fpn |
| Segmentación de instancias | MaskRCNN ResNet FPN | maskrcnn_resnet18_fpn maskrcnn_resnet34_fpn maskrcnn_resnet50_fpn* maskrcnn_resnet101_fpn maskrcnn_resnet152_fpn maskrcnn_resnet50_fpn |
Además de controlar el algoritmo de modelo, también puede ajustar los hiperparámetros usados para el entrenamiento del modelo. Aunque muchos de los hiperparámetros expuestos son independientes del modelo, hay instancias en las que los hiperparámetros son específicos de la tarea o el modelo. Obtenga más información sobre los hiperparámetros disponibles para estas instancias.
Aumento de datos
En general, el rendimiento del modelo de aprendizaje profundo a menudo puede mejorar con más datos. El aumento de datos es una técnica práctica para ampliar el tamaño y la variabilidad de los datos de un conjunto de datos que ayuda a evitar el sobreajuste y a mejorar la capacidad de generalización del modelo en datos no vistos. ML automatizado aplica diferentes técnicas de aumento de datos en función de la tarea de Computer Vision, antes de proporcionar las imágenes de entrada al modelo. Actualmente, no hay ningún hiperparámetro expuesto para controlar los aumentos de datos.
| Tarea | Conjunto de datos afectado | Técnicas de aumento de datos aplicadas |
|---|---|---|
| Clasificación de imágenes (varias clases y varias etiquetas) | Formación
Validación y prueba |
Cambio de tamaño y recorte aleatorios, volteo horizontal, vibración de color (brillo, contraste, saturación y matiz), normalización mediante la media y la desviación estándar de ImageNet por canal Cambio de tamaño, recorte central, normalización |
| Detección de objetos, segmentación de instancias | Formación
Validación y prueba |
Recorte aleatorio alrededor de rectángulos delimitadores, expansión, volteo horizontal, normalización, cambio de tamaño Normalización, cambio de tamaño |
| Detección de objetos mediante yolov5 | Formación
Validación y prueba |
Mosaico, afín aleatorio (rotación, traslación, escala, distorsión), volteo horizontal Cambio de tamaño de formato letterbox |
Establecer la configuración de experimento
Antes de realizar un barrido grande para buscar los modelos óptimos y los hiperparámetros, se recomienda probar los valores predeterminados para obtener una primera línea base. A continuación, puede explorar varios hiperparámetros para el mismo modelo antes de examinar varios modelos y sus parámetros. De este modo, puede emplear un enfoque más iterativo, ya que con varios modelos y varios hiperparámetros para cada uno, el espacio de búsqueda crece exponencialmente y necesita más iteraciones para encontrar configuraciones óptimas.
Si desea usar los valores de hiperparámetro predeterminados para un algoritmo determinado (por ejemplo, yolov5), puede especificar la configuración de la imagen de AutoML que se ejecuta de la siguiente manera:
from azureml.train.automl import AutoMLImageConfig
from azureml.train.hyperdrive import GridParameterSampling, choice
from azureml.automl.core.shared.constants import ImageTask
automl_image_config_yolov5 = AutoMLImageConfig(task=ImageTask.IMAGE_OBJECT_DETECTION,
compute_target=compute_target,
training_data=training_dataset,
validation_data=validation_dataset,
hyperparameter_sampling=GridParameterSampling({'model_name': choice('yolov5')}),
iterations=1)
Una vez que haya creado un modelo de línea base, es posible que desee optimizar el rendimiento del modelo con el fin de realizar un barrido sobre el algoritmo del modelo y el espacio de hiperparámetros. Puede usar la siguiente configuración de ejemplo para realizar un barrido de los hiperparámetros de cada algoritmo, eligiendo entre un intervalo de valores para learning_rate, optimizer, lr_scheduler, etc., para generar un modelo con la métrica principal óptima. Si no se especifican los valores de hiperparámetro, se usan los valores predeterminados para el algoritmo especificado.
Métrica principal
La métrica principal usada para la optimización del modelo y el ajuste de hiperparámetros depende del tipo de tarea. Actualmente no se admite el uso de otros valores de métricas principales.
accuracypara IMAGE_CLASSIFICATIONioupara IMAGE_CLASSIFICATION_MULTILABELmean_average_precisionpara IMAGE_OBJECT_DETECTIONmean_average_precisionpara IMAGE_INSTANCE_SEGMENTATION
Presupuesto del experimento
Opcionalmente, puede especificar el presupuesto de tiempo máximo para el experimento de AutoML Vision mediante experiment_timeout_hours, la cantidad de tiempo en horas antes de que finalice el experimento. Si no se especifica ninguno, el tiempo de espera predeterminado del experimento es de siete días (máximo de 60 días).
Barrido de los hiperparámetros de un modelo
Al entrenar modelos de Computer Vision, el rendimiento del modelo depende en gran medida de los valores de hiperparámetro seleccionados. A menudo, es posible que desee optimizar los hiperparámetros para obtener un rendimiento óptimo. Gracias a la compatibilidad con tareas de Computer Vision en ML automatizado, puede barrer hiperparámetros para encontrar la configuración óptima para el modelo. Esta característica aplica las funcionalidades de ajuste de hiperparámetros en Azure Machine Learning. Aprenda a ajustar los hiperparámetros.
Definir el espacio de búsqueda de parámetros
Puede definir los algoritmos de modelo y los hiperparámetros para barrido en el espacio de parámetros.
- Consulte Configuración de algoritmos de modelo e hiperparámetros para obtener la lista de algoritmos de modelo admitidos para cada tipo de tarea.
- Consulte Hiperparámetros para tareas de Computer Vision para cada tipo de tarea de Computer Vision.
- Consulte los detalles sobre las distribuciones admitidas para hiperparámetros discretos y continuos.
Métodos de muestreo para el barrido
Al realizar el barrido de hiperparámetros, debe especificar el método de muestreo que se usará para el barrido en el espacio de parámetros definido. Actualmente, se admiten los siguientes métodos de muestreo con el parámetro hyperparameter_sampling:
Nota:
Actualmente solo el muestreo aleatorio y de cuadrícula admiten espacios condicionales de hiperparámetros.
Directivas de terminación anticipada
Puede terminar de forma automática las series con un bajo rendimiento con la ayuda de una directiva de terminación anticipada. La terminación anticipada mejora la eficacia computacional, lo que ahorra recursos de proceso que, de lo contrario, se habrían invertido en configuraciones menos prometedoras. ML automatizado para imágenes admite las siguientes directivas de terminación anticipada mediante el parámetro early_termination_policy. Si no se especifica ninguna directiva de terminación, todas las configuraciones se ejecutan hasta su finalización.
Obtenga más información sobre cómo configurar la directiva de terminación anticipada para el barrido de hiperparámetros.
Recursos para el barrido
Puede controlar los recursos invertidos en el barrido de hiperparámetros especificando iterations y max_concurrent_iterations para el barrido.
| Parámetro | Detalle |
|---|---|
iterations |
Parámetro necesario para el número máximo de configuraciones que se deben barrer. Debe ser un entero entre 1 y 1000. Al explorar solo los hiperparámetros predeterminados para un algoritmo de modelo determinado, establezca este parámetro en 1. |
max_concurrent_iterations |
Número máximo de series que se pueden ejecutar simultáneamente. Si no se especifica, todas las series se inician en paralelo. Si se especifica, el tiempo de espera debe ser un entero comprendido entre 1 y 100. NOTA: El número de ejecuciones simultáneas viene determinado por los recursos disponibles en el destino de proceso especificado. Asegúrese de que el destino de proceso tenga los recursos disponibles para la simultaneidad deseada. |
Nota
Para obtener un ejemplo completo de configuración de barrido, consulte este tutorial.
Argumentos
Puede pasar valores fijos o parámetros que no cambien durante el barrido de espacio de parámetros como argumentos. Los argumentos se pasan en pares nombre-valor y el nombre debe ir precedido por un guion doble.
from azureml.train.automl import AutoMLImageConfig
arguments = ["--early_stopping", 1, "--evaluation_frequency", 2]
automl_image_config = AutoMLImageConfig(arguments=arguments)
Entrenamiento incremental (opcional)
Una vez realizada la ejecución de entrenamiento, tiene la opción de entrenar aún más el modelo si carga el punto de control del modelo entrenado. Puede usar el mismo conjunto de datos u otro diferente para el entrenamiento incremental.
Hay dos opciones disponibles para el entrenamiento incremental. Puede:
- Pasar el identificador de ejecución desde el que desea cargar el punto de control.
- Pasar los puntos de control a través de FileDataset.
Pasaje del punto de control a través del identificador de ejecución
Para buscar el identificador de ejecución del modelo deseado, puede usar el código siguiente.
# find a run id to get a model checkpoint from
target_checkpoint_run = automl_image_run.get_best_child()
Para pasar un punto de control a través del identificador de ejecución, debe usar el parámetro checkpoint_run_id.
automl_image_config = AutoMLImageConfig(task='image-object-detection',
compute_target=compute_target,
training_data=training_dataset,
validation_data=validation_dataset,
checkpoint_run_id= target_checkpoint_run.id,
primary_metric='mean_average_precision',
**tuning_settings)
automl_image_run = experiment.submit(automl_image_config)
automl_image_run.wait_for_completion(wait_post_processing=True)
Pasaje del punto de control a través de FileDataset
Para pasar un punto de control a través de FileDataset, debe usar los parámetros checkpoint_dataset_id y checkpoint_filename.
# download the checkpoint from the previous run
model_name = "outputs/model.pt"
model_local = "checkpoints/model_yolo.pt"
target_checkpoint_run.download_file(name=model_name, output_file_path=model_local)
# upload the checkpoint to the blob store
ds.upload(src_dir="checkpoints", target_path='checkpoints')
# create a FileDatset for the checkpoint and register it with your workspace
ds_path = ds.path('checkpoints/model_yolo.pt')
checkpoint_yolo = Dataset.File.from_files(path=ds_path)
checkpoint_yolo = checkpoint_yolo.register(workspace=ws, name='yolo_checkpoint')
automl_image_config = AutoMLImageConfig(task='image-object-detection',
compute_target=compute_target,
training_data=training_dataset,
validation_data=validation_dataset,
checkpoint_dataset_id= checkpoint_yolo.id,
checkpoint_filename='model_yolo.pt',
primary_metric='mean_average_precision',
**tuning_settings)
automl_image_run = experiment.submit(automl_image_config)
automl_image_run.wait_for_completion(wait_post_processing=True)
Envío de la ejecución
Cuando tenga el objeto AutoMLImageConfig listo, puede enviar el experimento.
ws = Workspace.from_config()
experiment = Experiment(ws, "Tutorial-automl-image-object-detection")
automl_image_run = experiment.submit(automl_image_config)
Salidas y métricas de evaluación
Las ejecuciones de entrenamiento de ML automatizado generan archivos de modelo de salida, métricas de evaluación, registros y artefactos de implementación, como el archivo de puntuación y el archivo de entorno que se pueden ver desde la pestaña salidas, registros y métricas de las ejecuciones secundarias.
Sugerencia
Compruebe cómo navegar a los resultados de la ejecución en la sección Visualización de los resultados de los trabajos.
Para obtener definiciones y ejemplos de los gráficos de rendimiento y las métricas proporcionadas en cada ejecución, vea Evaluación de los resultados del experimento de aprendizaje automático automatizado.
Registrar e implementar el modelo
Una vez completada la ejecución, puede registrar el modelo que se creó a partir de la mejor ejecución (configuración que dio lugar a la mejor métrica principal).
best_child_run = automl_image_run.get_best_child()
model_name = best_child_run.properties['model_name']
model = best_child_run.register_model(model_name = model_name, model_path='outputs/model.pt')
Después de registrar el modelo que desea usar, puede implementarlo como un servicio web en Azure Container Instances (ACI) o Azure Kubernetes Service (AKS). ACI es la opción perfecta para las implementaciones de prueba, mientras que AKS es más adecuado para el uso de producción a gran escala.
En este ejemplo se implementa el modelo como un servicio web en AKS. Para realizar la implementación en AKS, cree primero un clúster de proceso de AKS o use un clúster de AKS existente. Puede usar las SKU de máquina virtual de CPU o GPU para el clúster de implementación.
from azureml.core.compute import ComputeTarget, AksCompute
from azureml.exceptions import ComputeTargetException
# Choose a name for your cluster
aks_name = "cluster-aks-gpu"
# Check to see if the cluster already exists
try:
aks_target = ComputeTarget(workspace=ws, name=aks_name)
print('Found existing compute target')
except ComputeTargetException:
print('Creating a new compute target...')
# Provision AKS cluster with GPU machine
prov_config = AksCompute.provisioning_configuration(vm_size="STANDARD_NC6",
location="eastus2")
# Create the cluster
aks_target = ComputeTarget.create(workspace=ws,
name=aks_name,
provisioning_configuration=prov_config)
aks_target.wait_for_completion(show_output=True)
A continuación, puede definir la configuración de inferencia, que describe cómo configurar el servicio web que contiene el modelo. Puede usar el script de puntuación y el entorno de la ejecución de entrenamiento en la configuración de inferencia.
from azureml.core.model import InferenceConfig
best_child_run.download_file('outputs/scoring_file_v_1_0_0.py', output_file_path='score.py')
environment = best_child_run.get_environment()
inference_config = InferenceConfig(entry_script='score.py', environment=environment)
A continuación, puede implementar el modelo como un servicio web de AKS.
# Deploy the model from the best run as an AKS web service
from azureml.core.webservice import AksWebservice
from azureml.core.webservice import Webservice
from azureml.core.model import Model
from azureml.core.environment import Environment
aks_config = AksWebservice.deploy_configuration(autoscale_enabled=True,
cpu_cores=1,
memory_gb=50,
enable_app_insights=True)
aks_service = Model.deploy(ws,
models=[model],
inference_config=inference_config,
deployment_config=aks_config,
deployment_target=aks_target,
name='automl-image-test',
overwrite=True)
aks_service.wait_for_deployment(show_output=True)
print(aks_service.state)
También puede implementar el modelo desde la interfaz de usuario de Estudio de Azure Machine Learning. Vaya al modelo que desea implementar en la pestaña Modelos de la ejecución de ML automatizado y seleccione Implementar.
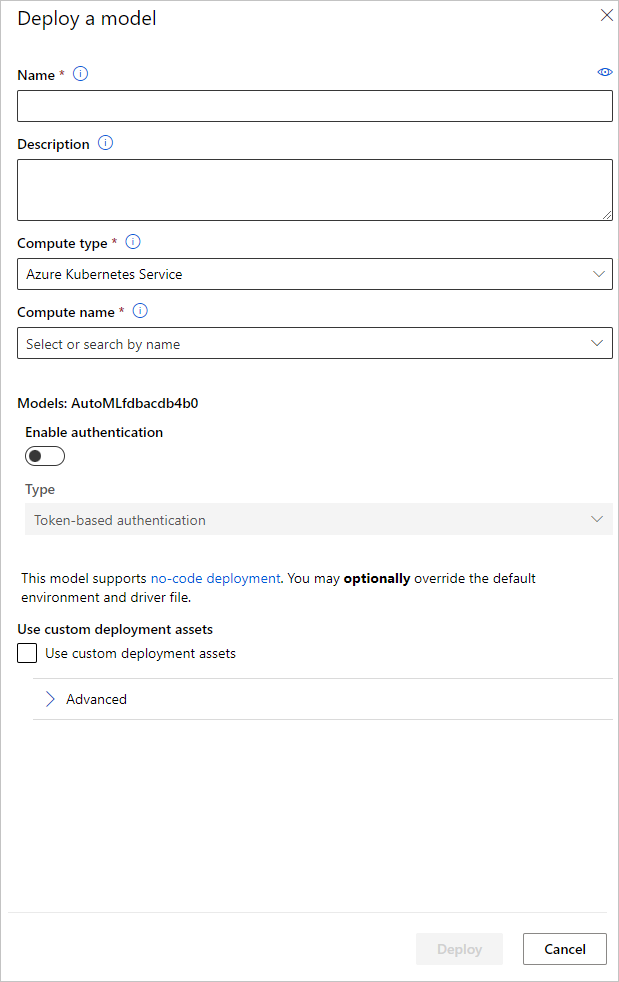
Puede configurar el nombre del punto de conexión de implementación del modelo y el clúster de inferencia que se usará para la implementación del modelo en el panel Implementar un modelo.
Actualización de la configuración de inferencia
En el paso anterior, se descargó el archivo de puntuación outputs/scoring_file_v_1_0_0.py del mejor modelo en un archivo score.py local y se usó para crear un objeto InferenceConfig. Este script se puede modificar para cambiar la configuración de inferencia específica del modelo si es necesario una vez descargado y antes de crear InferenceConfig. Por ejemplo, esta es la sección de código que inicializa el modelo en el archivo de puntuación:
...
def init():
...
try:
logger.info("Loading model from path: {}.".format(model_path))
model_settings = {...}
model = load_model(TASK_TYPE, model_path, **model_settings)
logger.info("Loading successful.")
except Exception as e:
logging_utilities.log_traceback(e, logger)
raise
...
Cada una de las tareas (y algunos modelos) tienen un conjunto de parámetros en el diccionario model_settings. De forma predeterminada, usamos los mismos valores para los parámetros que se usaron durante el entrenamiento y la validación. Dependiendo del comportamiento que necesitemos al usar el modelo para la inferencia, podemos cambiar estos parámetros. A continuación puede encontrar una lista de parámetros para cada tipo de tarea y modelo.
| Tarea | Nombre de parámetro | Valor predeterminado |
|---|---|---|
| Clasificación de imágenes (varias clases y varias etiquetas) | valid_resize_sizevalid_crop_size |
256 224 |
| Detección de objetos | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_img |
600 1333 0,3 0.5 100 |
Detección de objetos con yolov5 |
img_sizemodel_sizebox_score_threshnms_iou_thresh |
640 medio 0,1 0.5 |
| Segmentación de instancias | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_imgmask_pixel_score_thresholdmax_number_of_polygon_pointsexport_as_imageimage_type |
600 1333 0,3 0.5 100 0.5 100 Falso JPG |
Para obtener una descripción detallada sobre los hiperparámetros específicos de la tarea, consulte Hiperparámetros para tareas de Computer Vision en aprendizaje automático automatizado.
Si desea usar la colocación en mosaico y desea controlar su comportamiento, están disponibles los parámetros tile_grid_size, tile_overlap_ratio y tile_predictions_nms_thresh. Para más información sobre estos parámetros, consulte Entrenamiento de un modelo de detección de objetos pequeños mediante AutoML.
Cuadernos de ejemplo
Revise los ejemplos de código y los casos de uso detallados en el repositorio del cuaderno de GitHub para obtener muestras de aprendizaje automático automatizado. Compruebe las carpetas con el prefijo "image-" para obtener ejemplos específicos de la creación de modelos de Computer Vision.