Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Importante
En este artículo se proporciona información sobre el uso del SDK de Azure Machine Learning v1. El SDK v1 está en desuso a partir del 31 de marzo de 2025 y la compatibilidad con él finalizará el 30 de junio de 2026. Puede instalar y usar el SDK v1 hasta esa fecha.
Se recomienda realizar la transición al SDK v2 antes del 30 de junio de 2026. Para más información sobre el SDK v2, consulte ¿Qué es el SDK de Python de Azure Machine Learning v2 y la referencia del SDK v2?
En este artículo, aprenderá a implementar un modelo de diseñador en un punto de conexión en línea en tiempo real en Azure Machine Learning Studio.
Una vez registrado o descargado, puede usar modelos entrenados por el diseñador como cualquier otro modelo. Los modelos exportados se pueden implementar en casos de uso como Internet de las cosas (IoT) e implementaciones locales.
La implementación en Studio consta de los siguientes pasos:
- Registro del modelo entrenado.
- Descarga del script de entrada y el archivo de dependencias de Conda para el modelo.
- (Opcional) Configure el script de entrada.
- Implementación del modelo en el destino de proceso.
También puede implementar modelos directamente en el diseñador para omitir los pasos de registro de modelos y descarga de archivos. Esto puede ser útil para una rápida implementación. Para obtener más información, consulte Tutorial: Implementación de un modelo de Machine Learning mediante el diseñador.
Los modelos entrenados en el diseñador también se pueden implementar a través del SDK o la interfaz de la línea de comandos (CLI). Para más información, vea Implementación de modelos de aprendizaje automático en Azure.
Requisitos previos
Una canalización de entrenamiento completada que contenga alguno de los componentes siguientes:
- Componente Entrenar modelo
- Componente Entrenamiento de un modelo de detección de anomalías
- Componente Entrenamiento del modelo de agrupación en clústeres
- Componente de modelo de PyTorch de entrenamiento
- Componente Entrenamiento del recomendador SVD
- Componente Entrenamiento del modelo de Vowpal Wabbit
- Componente Entrenamiento del recomendador ancho y profundo
Para más información sobre las canalizaciones, consulte ¿Qué son las canalizaciones de Azure Machine Learning?
Registro del modelo
Una vez finalizada la canalización de entrenamiento, registre el modelo entrenado en el área de trabajo de Azure Machine Learning para tener acceso al modelo en otros proyectos.
Inicie sesión en Azure Machine Learning Studio y seleccione la canalización completada.
Haga doble clic en el componente Entrenar modelo para abrir el panel de detalles.
Seleccione la pestaña Salidas y registros en el panel de detalles.
Seleccione Registrar modelo.
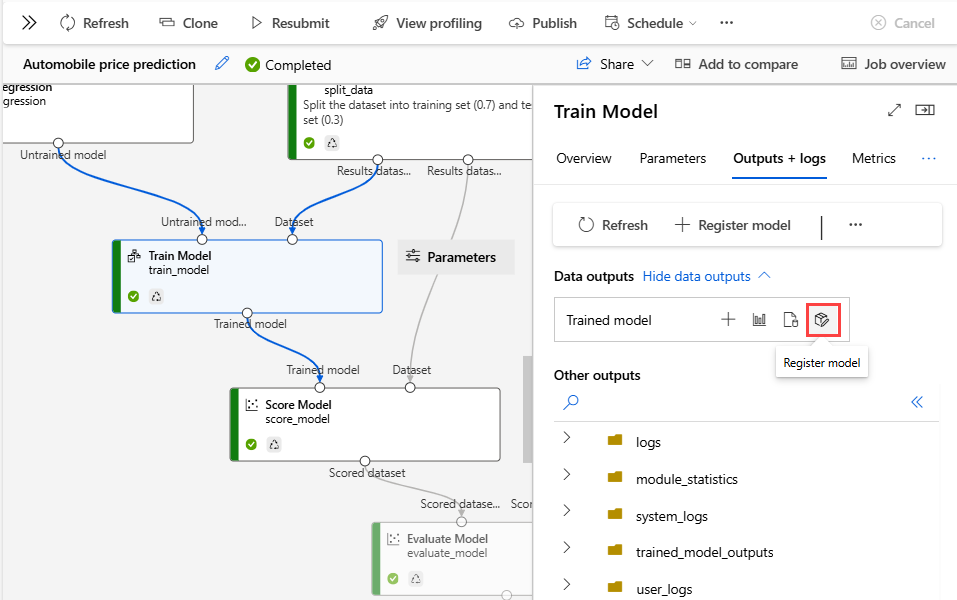
Escriba un nombre para el modelo y, a continuación, seleccione Guardar.

Después de registrar el modelo, puede encontrarlo en la página de recursos de Modelos en Studio.
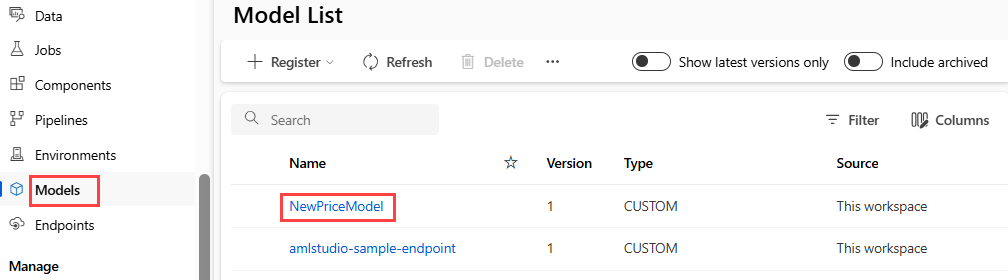
Descarga del archivo de script de entrada y el archivo de dependencias de Conda
Necesita los siguientes archivos para implementar un modelo en Azure Machine Learning Studio:
Archivo de script de entrada: carga el modelo entrenado, procesa los datos de entrada de las solicitudes, realiza inferencias en tiempo real y devuelve el resultado. El diseñador genera automáticamente un archivo de script de entrada
score.pycuando se completa el componente Entrenar modelo.Archivo de dependencias de Conda: especifica los paquetes pip y conda de los que depende el servicio web. El diseñador crea automáticamente un archivo
conda_env.yamlcuando se completa el componente Entrenar modelo.
Puede descargar estos dos archivos en el panel derecho del componente Entrenar modelo:
Seleccione el componente Entrenar modelo.
En la pestaña Resultados y registros, seleccione la carpeta
trained_model_outputs.Descargue los archivos
conda_env.yamlyscore.py.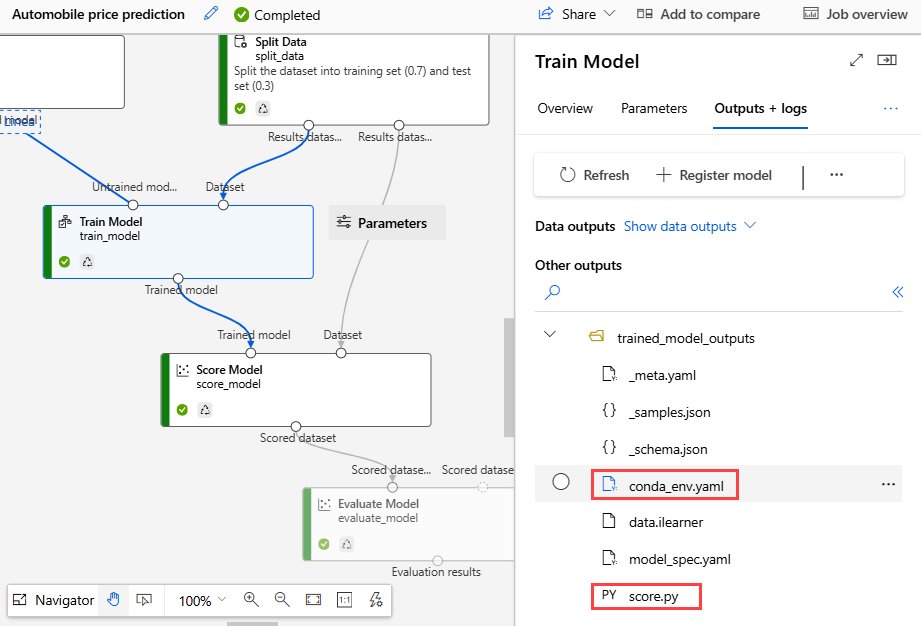

Como alternativa, puede descargar los archivos desde la página de recursos de Modelos después de registrar el modelo:
Vaya a la página de recursos de Modelos.
Seleccione el modelo que quiere implementar.
Seleccione la pestaña Artefactos.
Seleccione la carpeta
trained_model_outputs.Descargue los archivos
conda_env.yamlyscore.py.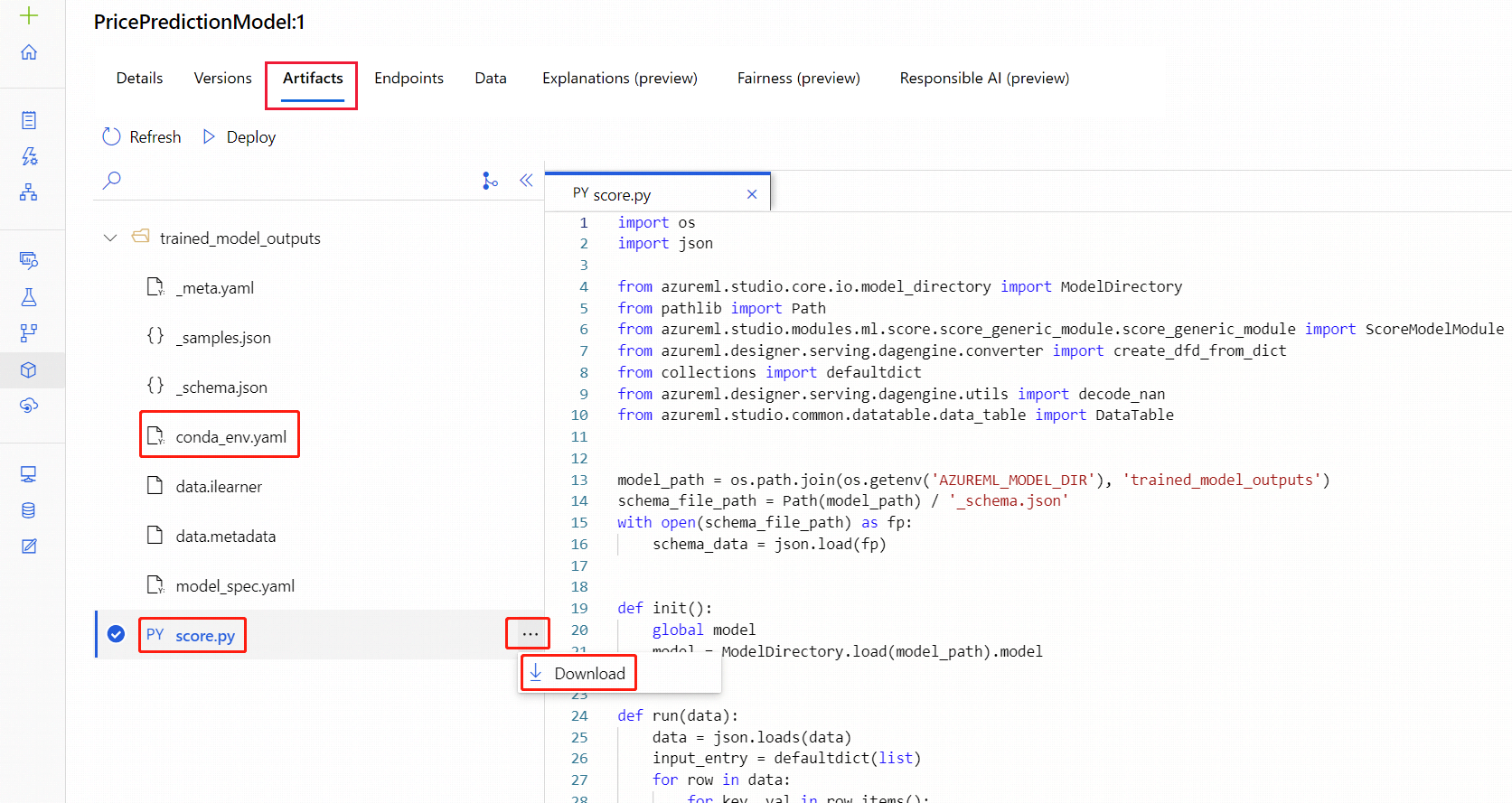

Nota:
El archivo score.py proporciona prácticamente la misma funcionalidad que los componentes Puntuación de modelo. Pero algunos componentes, como Puntuación del recomendador SVD, Puntuación del recomendador ancho y profundo y Puntuación del modelo de Vowpal Wabbit, tienen parámetros para diferentes modos de puntuación. También puede cambiar esos parámetros en el script de entrada.
Para obtener más información sobre la configuración de parámetros en el archivo score.py, vea la sección Configuración del script de entrada.
Implementación del modelo
Después de descargar los archivos necesarios, ya puede implementar el modelo.
En la página de recursos de Modelos, seleccione el modelo registrado.
Seleccione Usar este modelo y, a continuación, seleccione Servicio web en el menú desplegable.
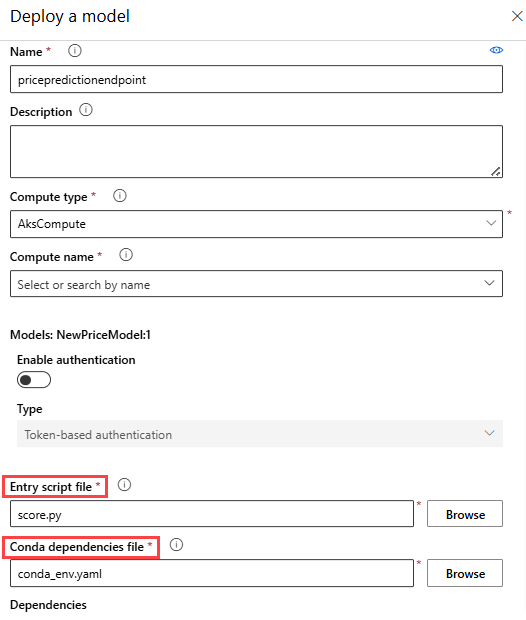
En el menú de configuración, escriba la siguiente información:
- Escriba un nombre para el punto de conexión.
- Seleccione el tipo de proceso AksCompute o Azure Container Instance .
- Seleccione un nombre de proceso.
- Cargue
score.pypara el archivo de script de entrada. - Cargue
conda_env.ymlpara el archivo de dependencias de Conda.
Sugerencia
En la configuración Avanzadas , puede establecer la capacidad de CPU/memoria y otros parámetros para la implementación. Esta configuración es importante para determinados modelos, como los modelos de PyTorch, que consumen una cantidad considerable de memoria (aproximadamente 4 GB).
Seleccione Implementar para implementar el modelo como un punto de conexión en línea.

Utilización del punto de conexión en línea
Una vez que la implementación se realiza correctamente, puede encontrar el punto de conexión en la página de recursos de Puntos de conexión. Una vez allí, encontrará un punto de conexión de REST, que los clientes pueden usar para enviar solicitudes al punto de conexión.
Nota:
El diseñador también genera un archivo JSON de datos de ejemplo para las pruebas. Puede descargar _samples.json en la carpeta trained_model_outputs.
Use el siguiente ejemplo de código para consumir un punto de conexión en línea.
import json
from pathlib import Path
from azureml.core.workspace import Workspace, Webservice
service_name = 'YOUR_SERVICE_NAME'
ws = Workspace.get(
name='WORKSPACE_NAME',
subscription_id='SUBSCRIPTION_ID',
resource_group='RESOURCEGROUP_NAME'
)
service = Webservice(ws, service_name)
sample_file_path = '_samples.json'
with open(sample_file_path, 'r') as f:
sample_data = json.load(f)
score_result = service.run(json.dumps(sample_data))
print(f'Inference result = {score_result}')
Consumo de puntos de conexión en línea relacionados con Computer Vision
Al consumir puntos de conexión en línea relacionados con Computer Vision, es necesario convertir las imágenes en bytes, ya que el servicio web solo acepta cadenas como entrada. El siguiente es el código de ejemplo:
import base64
import json
from copy import deepcopy
from pathlib import Path
from azureml.studio.core.io.image_directory import (IMG_EXTS, image_from_file, image_to_bytes)
from azureml.studio.core.io.transformation_directory import ImageTransformationDirectory
# image path
image_path = Path('YOUR_IMAGE_FILE_PATH')
# provide the same parameter setting as in the training pipeline. Just an example here.
image_transform = [
# format: (op, args). {} means using default parameter values of torchvision.transforms.
# See https://pytorch.org/docs/stable/torchvision/transforms.html
('Resize', 256),
('CenterCrop', 224),
# ('Pad', 0),
# ('ColorJitter', {}),
# ('Grayscale', {}),
# ('RandomResizedCrop', 256),
# ('RandomCrop', 224),
# ('RandomHorizontalFlip', {}),
# ('RandomVerticalFlip', {}),
# ('RandomRotation', 0),
# ('RandomAffine', 0),
# ('RandomGrayscale', {}),
# ('RandomPerspective', {}),
]
transform = ImageTransformationDirectory.create(transforms=image_transform).torch_transform
# download _samples.json file under Outputs+logs tab in the right pane of Train PyTorch Model component
sample_file_path = '_samples.json'
with open(sample_file_path, 'r') as f:
sample_data = json.load(f)
# use first sample item as the default value
default_data = sample_data[0]
data_list = []
for p in image_path.iterdir():
if p.suffix.lower() in IMG_EXTS:
data = deepcopy(default_data)
# convert image to bytes
data['image'] = base64.b64encode(image_to_bytes(transform(image_from_file(p)))).decode()
data_list.append(data)
# use data.json as input of consuming the endpoint
data_file_path = 'data.json'
with open(data_file_path, 'w') as f:
json.dump(data_list, f)
Configuración del script de entrada
Algunos componentes del diseñador, como Puntuación del recomendador SVD, Puntuación del recomendador ancho y profundo y Puntuación del modelo de Vowpal Wabbit, tienen parámetros para diferentes modos de puntuación.
En esta sección, aprenderá a actualizar estos parámetros en el archivo de script de entrada.
En el ejemplo siguiente se actualiza el comportamiento predeterminado de un modelo entrenado de Wide & Deep Recommender . De manera predeterminada, el archivo score.py indica al servicio web que prediga las clasificaciones entre los usuarios y los elementos.
Puede modificar el archivo de script de entrada para realizar recomendaciones de elementos y devolver elementos recomendados cambiando el recommender_prediction_kind parámetro .
import os
import json
from pathlib import Path
from collections import defaultdict
from azureml.studio.core.io.model_directory import ModelDirectory
from azureml.designer.modules.recommendation.dnn.wide_and_deep.score. \
score_wide_and_deep_recommender import ScoreWideAndDeepRecommenderModule
from azureml.designer.serving.dagengine.utils import decode_nan
from azureml.designer.serving.dagengine.converter import create_dfd_from_dict
model_path = os.path.join(os.getenv('AZUREML_MODEL_DIR'), 'trained_model_outputs')
schema_file_path = Path(model_path) / '_schema.json'
with open(schema_file_path) as fp:
schema_data = json.load(fp)
def init():
global model
model = ModelDirectory.load(load_from_dir=model_path)
def run(data):
data = json.loads(data)
input_entry = defaultdict(list)
for row in data:
for key, val in row.items():
input_entry[key].append(decode_nan(val))
data_frame_directory = create_dfd_from_dict(input_entry, schema_data)
# The parameter names can be inferred from Score Wide and Deep Recommender component parameters:
# convert the letters to lower cases and replace whitespaces to underscores.
score_params = dict(
trained_wide_and_deep_recommendation_model=model,
dataset_to_score=data_frame_directory,
training_data=None,
user_features=None,
item_features=None,
################### Note #################
# Set 'Recommender prediction kind' parameter to enable item recommendation model
recommender_prediction_kind='Item Recommendation',
recommended_item_selection='From All Items',
maximum_number_of_items_to_recommend_to_a_user=5,
whether_to_return_the_predicted_ratings_of_the_items_along_with_the_labels='True')
result_dfd, = ScoreWideAndDeepRecommenderModule().run(**score_params)
result_df = result_dfd.data
return json.dumps(result_df.to_dict("list"))
Para los modelos Wide & Deep Recommender y Vowpal Wabbit , puede configurar el parámetro de modo de puntuación mediante los métodos siguientes:
- Los nombres de parámetro son las combinaciones de minúsculas y caracteres de subrayado de los nombres de parámetro de puntuación del modelo de Vowpal Wabbit y puntuación del recomendador Wide and Deep.
- Los valores de parámetro de tipo modo son cadenas de los nombres de opción correspondientes. Tome el tipo de predicción Del recomendador en los códigos anteriores como ejemplo, el valor puede ser
'Rating Prediction'o'Item Recommendation'. No se permiten otros valores.
En el caso del modelo entrenado del recomendador SVD, los nombres de los parámetros y los valores pueden ser menos obvios, y puede consultar las tablas siguientes para decidir cómo establecer los parámetros.
| Nombre del parámetro de Puntuación del recomendador SVD | Nombre del parámetro del archivo de script de entrada |
|---|---|
| Tipo de predicción de recomendador | tipo_de_predicción |
| Selección de elementos recomendados | selección de artículos recomendados |
| Tamaño mínimo de la agrupación de recomendación para un solo usuario | tamaño_minimo_del_pool_de_recomendaciones |
| Número máximo de elementos para recomendar a un usuario | cantidad_máxima_de_elementos_recomendados |
| Si se van a devolver las clasificaciones previstas de los elementos junto con las etiquetas | return_ratings |
En el código siguiente se muestra cómo establecer parámetros para un recomendador SVD, que usa los seis parámetros para recomendar elementos clasificados con clasificaciones previstas adjuntas.
score_params = dict(
learner=model,
test_data=DataTable.from_dfd(data_frame_directory),
training_data=None,
# RecommenderPredictionKind has 2 members, 'RatingPrediction' and 'ItemRecommendation'. You
# can specify prediction_kind parameter with one of them.
prediction_kind=RecommenderPredictionKind.ItemRecommendation,
# RecommendedItemSelection has 3 members, 'FromAllItems', 'FromRatedItems', 'FromUndatedItems'.
# You can specify recommended_item_selection parameter with one of them.
recommended_item_selection=RecommendedItemSelection.FromRatedItems,
min_recommendation_pool_size=1,
max_recommended_item_count=3,
return_ratings=True,
)
Contenido relacionado
- Tutorial: Entrenamiento de un modelo de regresión sin código mediante el diseñador
- Implementación de modelos de aprendizaje automático en Azure
- Solución de problemas de una implementación de modelo remota
- Implementación de un modelo en un clúster de Azure Kubernetes Service
- Creación de aplicaciones cliente para consumir servicios web
- Actualización de un servicio web implementado