Transformación de datos en el diseñador de Azure Machine Learning
En este artículo, aprenderá a transformar y guardar conjuntos de datos en el diseñador de Azure Machine Learning para que pueda preparar sus propios datos para el aprendizaje automático.
Usará el conjunto de datos Adult Census Income Binary Classification de ejemplo para preparar dos conjuntos de datos: uno que incluya la información del censo de adultos solo de los Estados Unidos y otro que incluya la información del censo de los adultos que no son de EE. UU.
En este artículo, aprenderá a:
- Transformar un conjunto de datos para prepararlo para el entrenamiento.
- Exportar los conjuntos de datos resultantes a un almacén de datos.
- Vea los resultados.
Este procedimiento es requisito previo para el artículo sobre cómo volver a entrenar modelos con el diseñador. En ese artículo, aprenderá a usar los conjuntos de datos transformados para entrenar varios modelos, con parámetros de canalización.
Importante
Si no ve los elementos gráficos que se mencionan en este documento, como los botones en Studio o en el diseñador, es posible que no tenga el nivel de permisos adecuado para el área de trabajo. Póngase en contacto con el administrador de suscripciones de Azure para verificar que se le ha concedido el nivel de acceso correcto. Para más información, consulte Administración de usuarios y roles.
Transformación de un conjunto de datos
En esta sección, aprenderá a importar el conjunto de datos de ejemplo y a dividir los datos en conjuntos de datos de EE. UU. y de fuera de EE. UU. Consulte cómo importar datos para más información sobre cómo importar sus propios datos en el diseñador.
Importar datos
Use estos pasos para importar el conjunto de datos de ejemplo:
Inicie sesión en Azure Machine Learning Studio y seleccione el área de trabajo que desea usar
Vaya al diseñador. Seleccione Crear una canalización mediante componentes creados previamente clásicos para crear una nueva canalización
A la izquierda del lienzo de canalización, en la pestaña Componente, expanda el nodo Datos de ejemplo
Arrastre y coloque el conjunto de datos Clasificación binaria de ingresos en el censo de adultos en el lienzo
Seleccione con el botón derecho el componente del conjunto de datos Ingresos del censo de adultos y seleccione Vista previa de los datos
Use la ventana de vista previa de los datos para explorar el conjunto de datos. Tenga en cuenta especialmente los valores de la columna "native-country"
División de los datos
En esta sección, se usa el componenteSplit Data para identificar y dividir las filas que contienen "United-States" en la columna "native-country"
En la pestaña de componentes que se encuentra a la izquierda del lienzo, expanda la sección Data Transformation y busque el componente Split Data
Arrastre el componente Split Data al lienzo y colóquelo debajo del componente de conjunto de datos
Conecte el componente de conjunto de datos al componente Split Data (Dividir datos)
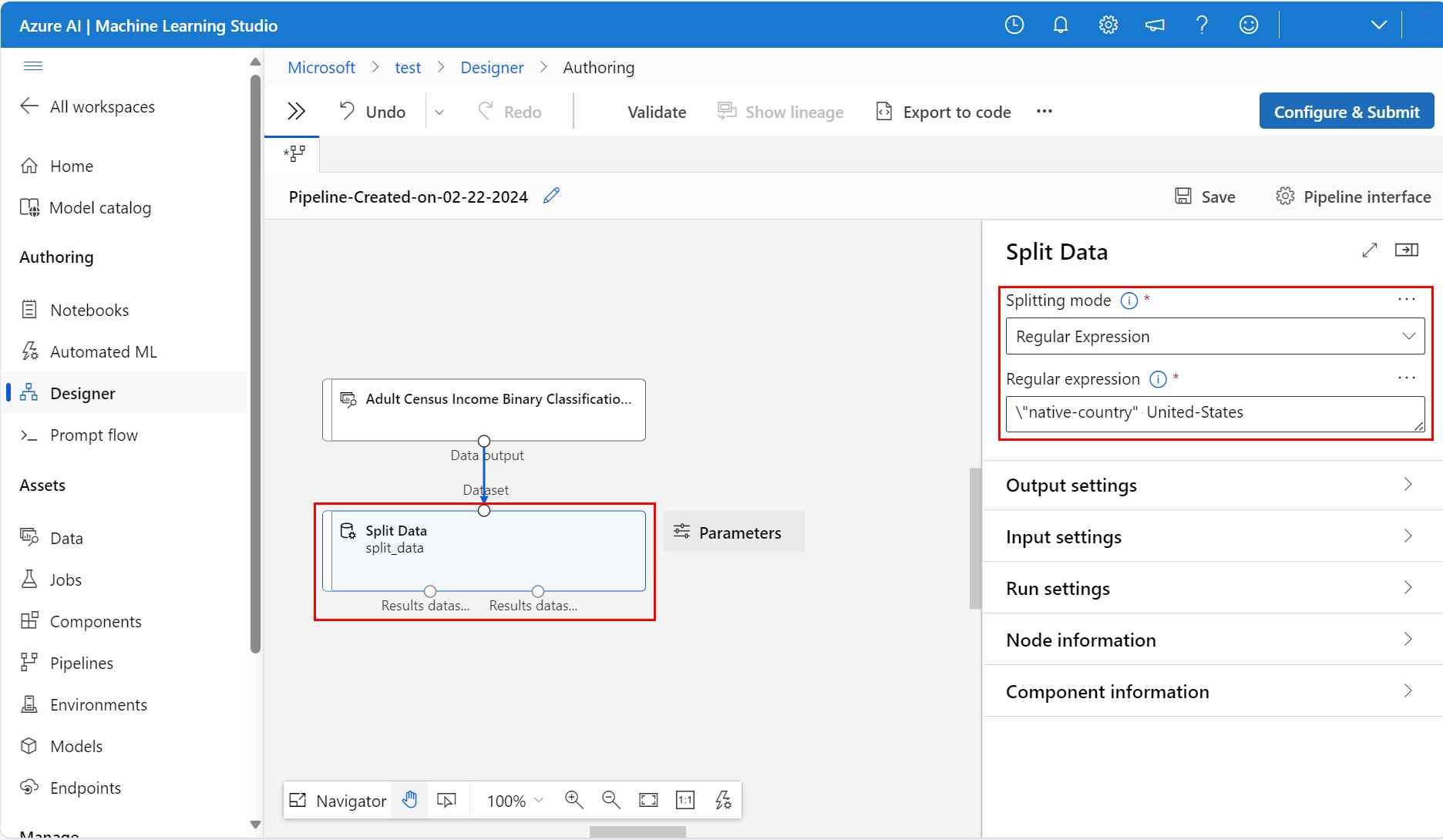
Seleccione el componente Dividir datos para abrir el panel Dividir datos
A la derecha del lienzo en el icono Parámetros, establezca el Modo de división en Expresión regular
Escriba la expresión regular:
\"native-country" United-StatesEl modo Expresión regular prueba una columna con respecto a un valor. Para más información sobre el componente Split Data, consulte la página de referencia del componente de algoritmo relacionado
La canalización debe ser similar a esta captura de pantalla:
Guardado de los conjuntos de datos
Ahora que la canalización está configurada para dividir los datos, debe especificar dónde quiere guardar los conjuntos de datos. En este ejemplo, use el componente Exportar datos para guardar el conjunto de datos en un almacén de datos. Consulte Conexión a los servicios de almacenamiento de Azure para más información sobre los almacenes de datos.
En la paleta de componentes que se encuentra a la izquierda del lienzo, expanda la sección Data Input and Output y busque el módulo Export Data
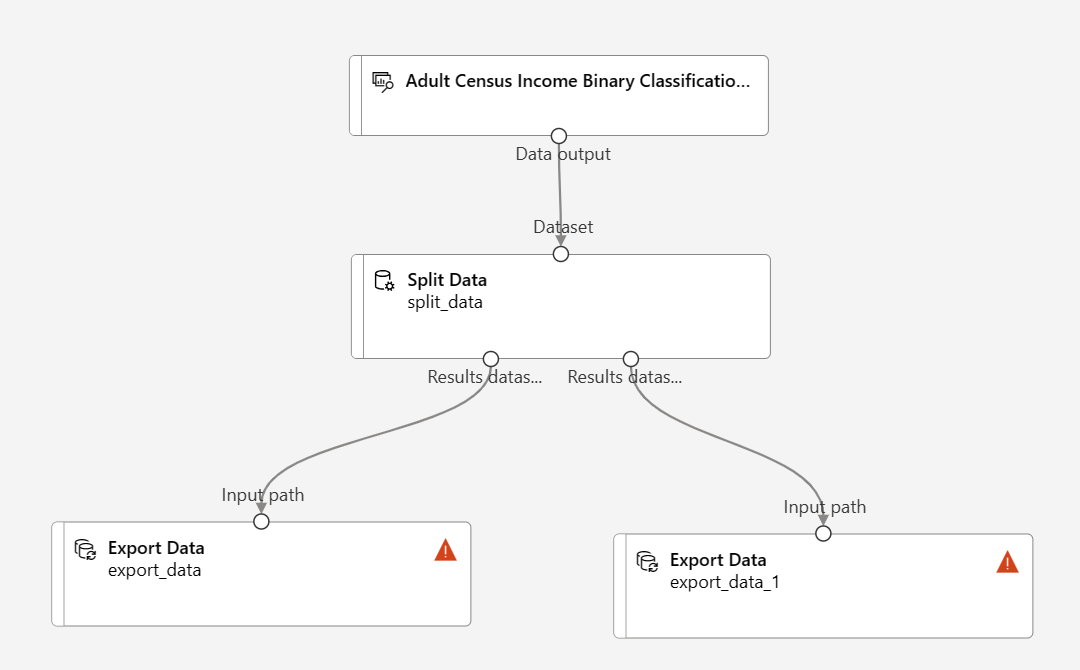
Arrastre y coloque dos componentes Exportar datos debajo del componente Split Data (Dividir datos)
Conecte cada puerto de salida del componente Split Data (Dividir datos) a un componente Exportar datos distinto
La canalización debe ser similar a la siguiente:
Seleccione el componente Export Data conectado al puerto que está más a la izquierda del componente Split Data para abrir el panel Exportar configuración de datos
Para el componente Split Data, el orden del puerto de salida es importante. El primer puerto de salida contiene las filas en las que el valor de la expresión regular es true. En este caso, el primer puerto contiene filas para los ingresos basados en Estados Unidos y el segundo puerto contiene filas para ingresos no basados en Estados Unidos
En el panel de detalles del componente que se encuentra a la derecha del lienzo, establezca estas opciones:
Tipo de almacén de datos: Azure Blob Storage
Almacén de datos: seleccione un almacén de datos existente o seleccione "Nuevo almacén de datos" para crear uno nuevo
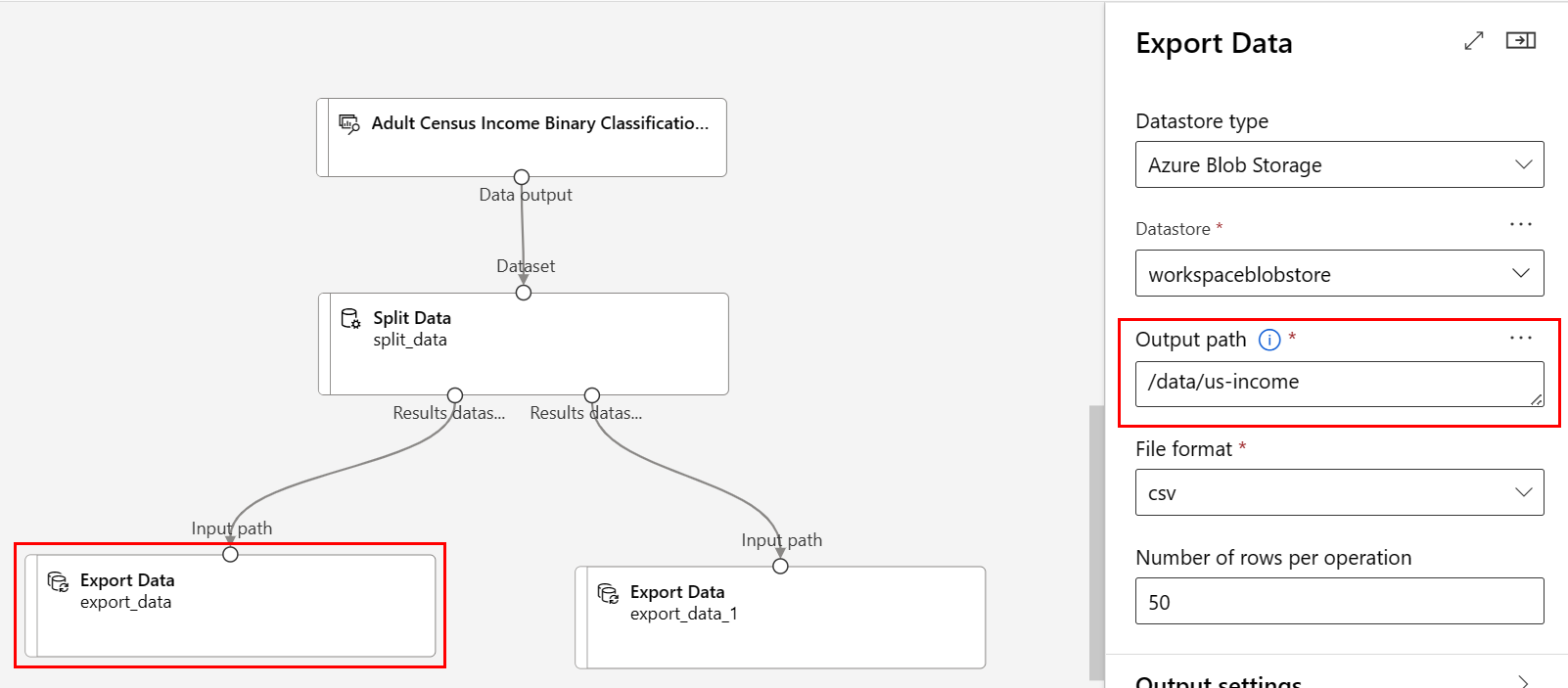
Ruta de acceso:
/data/us-incomeFormato de archivo: csv
Nota
En este artículo se da por supuesto que tiene acceso a un almacén de datos registrado en el área de trabajo de Azure Machine Learning actual. Consulte Conexión a los servicios de almacenamiento de Azure para obtener instrucciones de configuración del almacén de datos
Puede crear un almacén de datos si no tiene uno. Para fines de ejemplo, en este artículo se guardarán los conjuntos de datos en la cuenta de almacenamiento de blobs predeterminada asociada con el área de trabajo. Los conjuntos de datos se guardarán en el contenedor
azureml, en una carpeta nueva llamadadataSeleccione el componente Export Data conectado al puerto que está más a la derecha del componente Split Data para abrir el panel Exportar configuración de datos
A la derecha del lienzo en el panel de detalles del componente, establezca las siguientes opciones:
Tipo de almacén de datos: Azure Blob Storage
Almacén de datos: seleccione el almacén de datos anterior
Ruta de acceso:
/data/non-us-incomeFormato de archivo: csv
Confirme que el componente Exportar datos conectado al puerto izquierdo del componente Dividir datos tiene la Ruta de acceso
/data/us-incomeCompruebe que el componente Exportar datos conectado al puerto derecho tiene la Ruta de acceso
/data/non-us-incomeLa canalización y configuración deberían ser similares a estas:
Enviar el archivo
Ahora que la canalización está configurada para dividir y exportar los datos, envíe un trabajo de canalización.
Seleccione Configurar y enviar en la parte superior del lienzo
Seleccione la opción Crear nuevo en el panel Aspectos básicos de Configurar trabajo de canalización para crear un experimento
Los experimentos agrupan de manera lógica los trabajos de canalización relacionados. Si ejecuta esta canalización en el futuro, debe usar el mismo experimento con fines de registro y seguimiento
Proporcione un nombre descriptivo para el experimento, por ejemplo, "datos del censo divididos"
Seleccione Revisar y enviar y, a continuación, seleccione Enviar
Vista de resultados
Cuando termine de ejecutarse la canalización, puede ir al almacenamiento de blobs de Azure Portal para ver los resultados. También puede ver los resultados intermedios del componente Split Data (Dividir datos) para confirmar que los datos se dividieron correctamente.
Seleccione el componente Split Data (Dividir datos)
En el panel de detalles del componente, situado a la derecha del lienzo, seleccione la pestaña Resultados y registros
Seleccione la lista desplegable Mostrar salidas de datos
Seleccione el icono de visualización
 junto a Conjunto de datos de resultados 1
junto a Conjunto de datos de resultados 1Compruebe que la columna "native-country" solo contiene el valor "United-States"
Seleccione el icono de visualización
junto a Conjunto de datos de resultados 2Compruebe que la columna "native-country" no contiene el valor "United-States"
Limpieza de recursos
Para continuar con la segunda parte del procedimiento Volver a entrenar modelos con el diseñador de Azure Machine Learning, omita esta sección.
Importante
Los recursos que creó pueden usarse como requisitos previos de otros tutoriales y artículos de procedimientos de Azure Machine Learning.
Eliminar todo el contenido
Si no va a usar nada de lo que ha creado, elimine el grupo de recursos completo para que no le genere gastos.
En Azure Portal, seleccione Grupos de recursos en la parte izquierda de la ventana.
En la lista, seleccione el grupo de recursos que creó.
Seleccione Eliminar grupo de recursos.
Al eliminar el grupo de recursos también se eliminan todos los recursos que creó en el diseñador.
Eliminación de recursos individuales
En diseñador donde creó el experimento, elimine recursos individuales; para ello, selecciónelos y, luego, haga clic en el botón Eliminar.
El destino de proceso que ha creado aquí se escala automáticamente a cero nodos cuando no se usa. Esta acción se lleva a cabo para minimizar los cargos. Si quiere eliminar el destino de proceso, siga estos pasos:
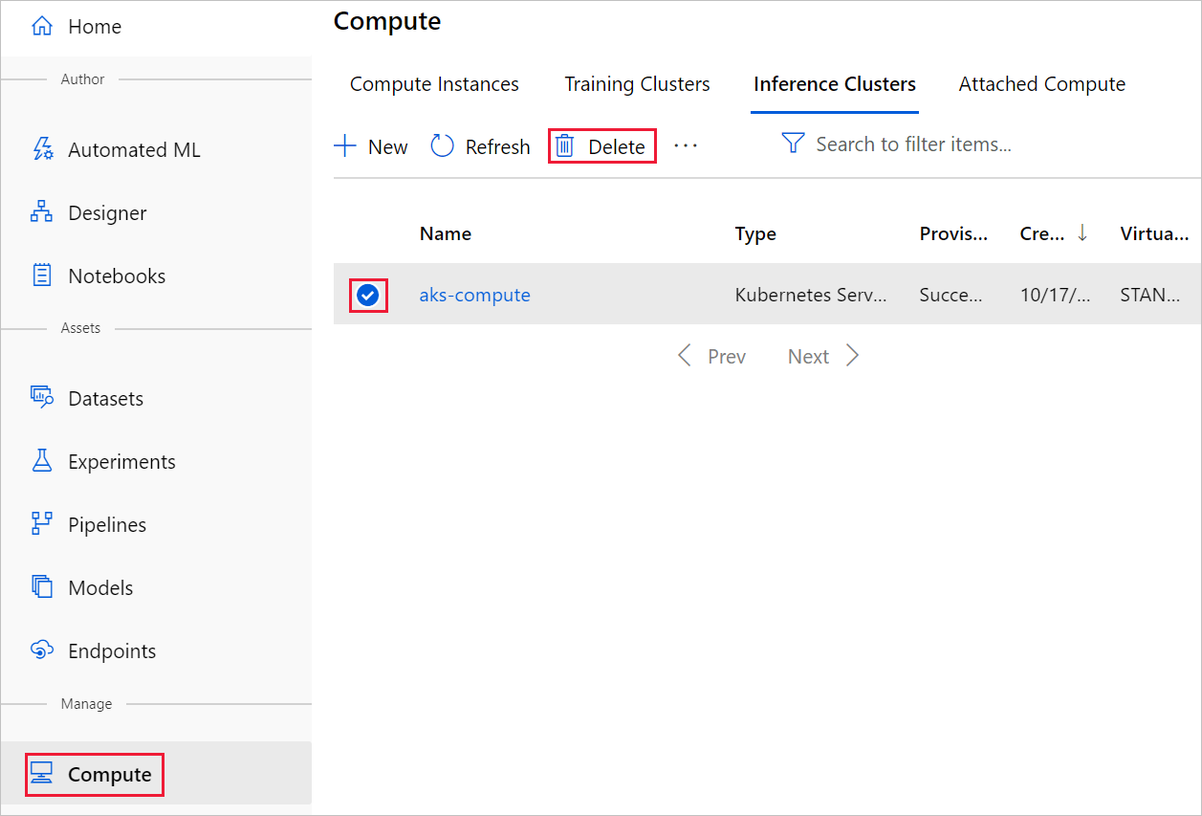
Puede anular el registro de los conjuntos de datos del área de trabajo seleccionando cada conjunto de datos y Anular el registro.
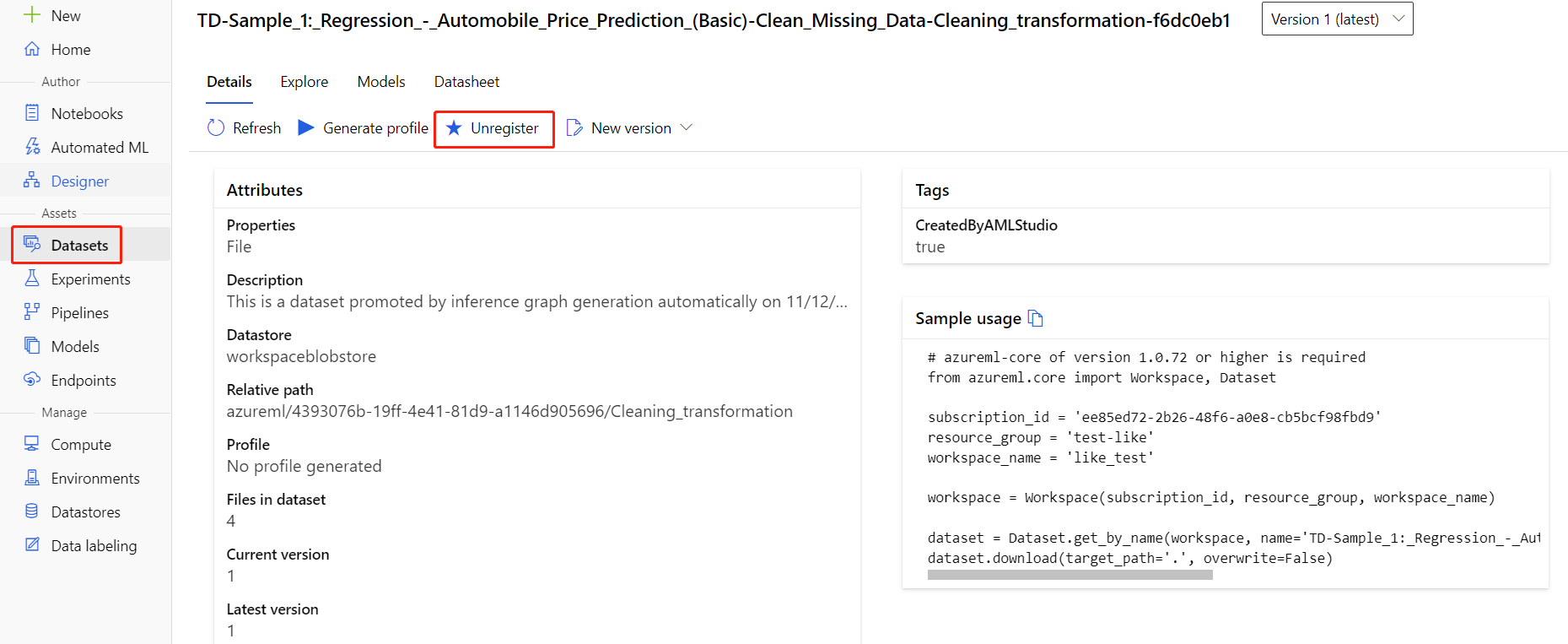
Para eliminar un conjunto de datos, vaya a la cuenta de almacenamiento mediante Azure Portal o el Explorador de Azure Storage y elimine manualmente esos recursos.
Pasos siguientes
En este artículo, aprendió a transformar un conjunto de datos y guardarlo en un almacén de datos registrado.
Continúe con la siguiente parte de esta serie de procedimientos con Volver a entrenar modelos con el diseñador de Azure Machine Learning, para usar los conjuntos de datos transformados y los parámetros de canalización para entrenar modelos de aprendizaje automático.