Requisitos de conectividad y enrutador de inferencia de Azure Machine Learning
El enrutador de inferencia de Azure Machine Learning es un componente crítico para la inferencia en tiempo real con el clúster de Kubernetes. En este artículo, aprenderá lo siguiente:
- ¿Qué es el enrutador de inferencia de Azure Machine Learning?
- Cómo funciona la escalabilidad automática
- Cómo configurar y satisfacer el rendimiento de las solicitudes de inferencia (número de solicitudes por segundo y latencia)
- Requisitos de conectividad para el clúster de inferencia de AKS
¿Qué es el enrutador de inferencia de Azure Machine Learning?
El enrutador de inferencia de Azure Machine Learning es el componente de front-end (azureml-fe) que se implementa en el clúster de Kubernetes de AKS o Arc en tiempo de implementación de la extensión Azure Machine Learning. Tiene las siguientes funciones:
- Enruta las solicitudes de inferencia entrantes desde el equilibrador de carga del clúster o el controlador de entrada a los pods del modelo correspondientes.
- Equilibre la carga de todas las solicitudes de inferencia entrantes con enrutamiento coordinado inteligente.
- Administra el escalado automático de los pods del modelo.
- Funcionalidad tolerante a errores y conmutación por error, lo que garantiza que las solicitudes de inferencia siempre se sirven para aplicaciones empresariales críticas.
Los pasos siguientes son la forma en que el front-end procesa las solicitudes:
- El cliente envía la solicitud al equilibrador de carga.
- El equilibrador de carga la envía a uno de los servidores front-end.
- El front-end localiza el enrutador de servicio (la instancia de front-end que actúa como coordinador) para el servicio.
- El enrutador de servicio selecciona un back-end y la devuelve al front-end.
- El front-end reenvía la solicitud al back-end.
- Una vez procesada la solicitud, el back-end envía una respuesta al componente de front-end.
- El front-end propaga la respuesta al cliente.
- El front-end informa al enrutador de servicio de que el back-end ha terminado de procesarla y está disponible para otras solicitudes.
En el diagrama siguiente se muestra este flujo:
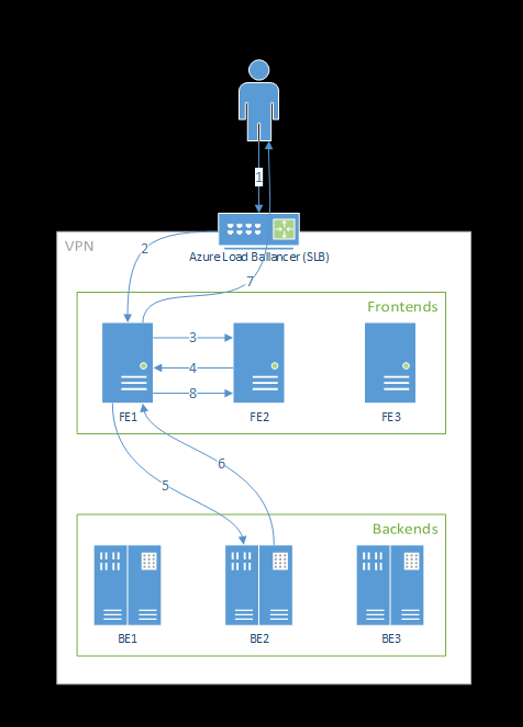
Como puede ver en el diagrama anterior, de forma predeterminada se crean tres instancias de azureml-fe durante la implementación de la extensión Azure Machine Learning: una instancia actúa como rol de coordinación y las demás atienden las solicitudes de inferencia entrantes. La instancia de coordinación tiene toda la información sobre los pods del modelo y toma la decisión sobre cuál de ellos atenderá la solicitud entrante, mientras que las instancias azureml-fe de servicio son responsables de enrutar la solicitud al pod del modelo seleccionado y propagar la respuesta al usuario original.
Escalado automático
El enrutador de inferencia de Azure Machine Learning controla la escalabilidad automática de todas las implementaciones de modelos en el clúster de Kubernetes. Dado que todas las solicitudes de inferencia pasan por él, tiene los datos necesarios para escalar automáticamente los modelos implementados.
Importante
No habilite el Escalador horizontal automático de pods (HPA) de Kubernetes para las implementaciones de modelos. Si lo hace, los dos componentes de escalado automático competirán entre sí. Azureml-fe está diseñado para el escalado automático de modelos implementados por Azure Machine Learning, donde HPA tendría que adivinar o estimar el uso del modelo a partir de una métrica genérica, como el uso de la CPU o una configuración de métricas personalizada.
Azureml-fe no escala el número de nodos en un clúster de AKS, ya que esto podría provocar un aumento inesperado en los costos. En su lugar, escala el número de réplicas para el modelo dentro de los límites del clúster físico. Si necesita escalar el número de nodos dentro del clúster, puede escalar manualmente el clúster o configurar el escalador automático del clúster de AKS.
La escalabilidad automática se puede controlar mediante la propiedad scale_settings en YAML de implementación. En el ejemplo siguiente se muestra cómo habilitar el escalado automático:
# deployment yaml
# other properties skipped
scale_setting:
type: target_utilization
min_instances: 3
max_instances: 15
target_utilization_percentage: 70
polling_interval: 10
# other deployment properties continue
La decisión de escalar o reducir verticalmente se basa en utilization of the current container replicas.
utilization_percentage = (The number of replicas that are busy processing a request + The number of requests queued in azureml-fe) / The total number of current replicas
Si este número supera target_utilization_percentage, se crean más réplicas. Si es menor, se reducen las réplicas. De manera predeterminada, la utilización de destino es del 70 %.
Las decisiones de agregar réplicas son diligentes y rápidas (aproximadamente un segundo). Las decisiones de quitar réplicas son conservadoras (aproximadamente un minuto).
Por ejemplo, si quiere implementar un servicio de modelo y desea saber cuántas instancias (pods/réplicas) se deben configurar para las solicitudes de destino por segundo (RPS) y el tiempo de respuesta de destino. Puede calcular las réplicas necesarias mediante el código siguiente:
from math import ceil
# target requests per second
targetRps = 20
# time to process the request (in seconds)
reqTime = 10
# Maximum requests per container
maxReqPerContainer = 1
# target_utilization. 70% in this example
targetUtilization = .7
concurrentRequests = targetRps * reqTime / targetUtilization
# Number of container replicas
replicas = ceil(concurrentRequests / maxReqPerContainer)
Rendimiento de azureml-fe
azureml-fe puede llegar a 5000 solicitudes por segundo (QPS) con una buena latencia, con una sobrecarga que no supera los 3 ms de media y los 15 ms en un percentil del 99 %.
Nota:
Si tiene requisitos de RPS superiores a 10 000, tenga en cuenta las siguientes opciones:
- Aumente las solicitudes o límites de recursos para los pods
azureml-fe; de forma predeterminada, tienen 2 vCPU y 1,2 GB de límites de recurso de memoria. - Aumente el número de instancias de
azureml-fe. De manera predeterminada, Azure Machine Learning crea 3 o 1 instancias deazureml-fepor clúster.- Este recuento de instancias depende de la configuración de
inferenceRouterHAde la extensión Azure Machine Learning. - No se puede conservar el recuento de instancias aumentado, ya que se sobrescribirá con el valor configurado una vez que se actualice la extensión.
- Este recuento de instancias depende de la configuración de
- Póngase en contacto con expertos de Microsoft para obtener ayuda.
Descripción de los requisitos de conectividad para el clúster de inferencia de AKS
Un clúster de AKS se implementa con uno de los dos siguientes modelos de red:
- Red de kubenet: los recursos de la red normalmente se crean y se configuran cuando se implementa el clúster de AKS.
- Redes Azure Container Networking Interface (CNI): el clúster de AKS está conectado a configuraciones y a un recurso de red virtual existente.
En el caso de las redes Kubenet, la red se crea y configura correctamente para Azure Machine Learning Service. En el caso de las redes CNI, debe comprender los requisitos de conectividad y garantizar la resolución de DNS y la conectividad saliente para la inferencia de AKS. Por ejemplo, si usa un firewall para bloquear el tráfico de red, puede que necesite realizar algunos pasos más.
En el diagrama siguiente se muestran todos los requisitos de conectividad para la inferencia de AKS. Las flechas negras representan la comunicación real y las flechas azules representan los nombres de dominio. Es posible que tenga que agregar entradas para estos hosts al firewall o al servidor DNS personalizado.
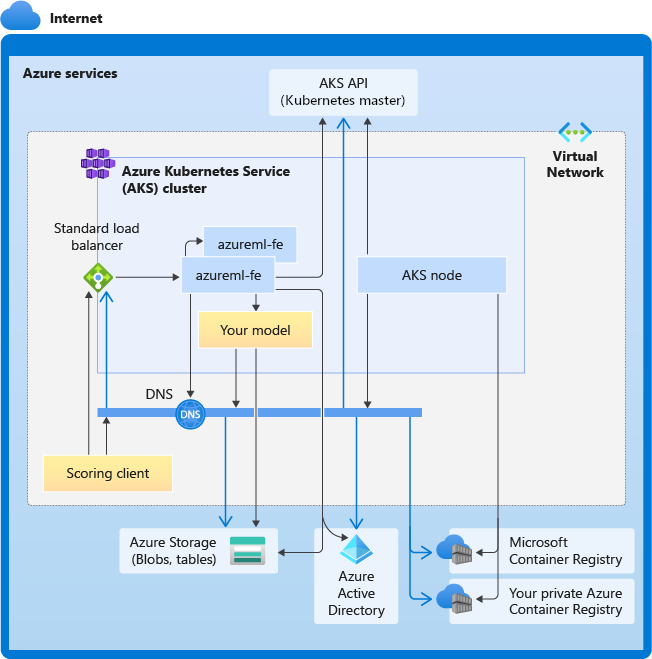
Para ver los requisitos generales de conectividad de AKS, consulte Control del tráfico de salida de los nodos de clúster en Azure Kubernetes Service.
Para acceder a los servicios de Azure Machine Learning detrás de un firewall, vea Configuración del tráfico de red entrante y saliente.
Requisitos generales de resolución de DNS
La resolución de DNS en una red virtual existente está bajo su control. Por ejemplo, un firewall o un servidor DNS personalizado. Los hosts siguientes deben ser accesibles:
| Nombre de host | Usado por |
|---|---|
<cluster>.hcp.<region>.azmk8s.io |
Servidor de API de AKS |
mcr.microsoft.com |
Microsoft Container Registry (MCR) |
<ACR name>.azurecr.io |
Su instancia de Azure Container Registry (ACR) |
<account>.blob.core.windows.net |
Cuenta de Azure Storage (Blob Storage) |
api.azureml.ms |
Autenticación de Microsoft Entra |
ingest-vienna<region>.kusto.windows.net |
Punto de conexión de Kusto para cargar telemetría |
Requisitos de conectividad en orden cronológico: desde la creación de clústeres hasta la implementación de modelos
Justo después de implementar azureml-fe, se intentará iniciar, y esto requiere:
- Resolver DNS para el servidor de API de AKS
- Consultar el servidor de API de AKS para detectar otras instancias de sí mismo (es un servicio multipod)
- Conectarse a otras instancias de sí mismo
Una vez iniciado azureml-fe, requiere conectividad adicional para funcionar correctamente:
- Conectarse a Azure Storage para descargar la configuración dinámica
- Resolver DNS para el servidor de autenticación de Microsoft Entra api.azureml.ms y comunicarse con él cuando el servicio implementado use la autenticación de Microsoft Entra.
- Consultar al servidor API de AKS para detectar modelos implementados
- Comunicar con modelos POD implementados
En el momento de la implementación del modelo, para un nodo AKS de implementación de modelo correcta, debe ser capaz de:
- Resolver DNS para ACR del cliente
- Descargar imágenes del ACR del cliente
- Resolver DNS para Azure BLOB donde se almacena el modelo
- Descargar modelos de Azure BLOB
Una vez implementado el modelo y cuando se inicie el servicio, azureml-fe lo detectará automáticamente mediante la API de AKS y estará listo para enrutar la solicitud al mismo. Debe ser capaz de comunicarse con los POD modelo.
Nota
Si el modelo implementado requiere cualquier conectividad (por ejemplo, consultar la base de datos externa u otro servicio REST, descargar un BLOB, etc.), se debe habilitar tanto la resolución DNS como la comunicación saliente para estos servicios.
Pasos siguientes
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de