Uso del paquete de interpretación de Python para explicar los modelos y las predicciones de ML (versión preliminar)
SE APLICA A:  Azure ML del SDK de Python v1
Azure ML del SDK de Python v1
En este artículo, aprenderá a usar el paquete de interpretación del SDK de Azure Machine Learning para Python para realizar las siguientes tareas:
Explicar el comportamiento completo del modelo o predicciones individuales en el equipo personal de forma local.
Habilitar técnicas de interpretación para las características diseñadas.
Explicar el comportamiento completo del modelo y predicciones individuales en Azure.
Cargar las explicaciones en el historial de ejecución de Azure Machine Learning.
Use un panel de visualización para interactuar con las explicaciones del modelo, tanto en un cuaderno de Jupyter Notebook como en Estudio de Azure Machine Learning.
Implementar un explicador de puntuaciones junto con el modelo para observar las explicaciones durante la inferencia.
Importante
Esta característica actualmente está en su versión preliminar pública. Esta versión preliminar se ofrece sin un Acuerdo de Nivel de Servicio y no se recomienda para cargas de trabajo de producción. Es posible que algunas características no sean compatibles o que tengan sus funcionalidades limitadas.
Para más información, consulte Términos de uso complementarios de las Versiones Preliminares de Microsoft Azure.
Para más información sobre las técnicas de interpretación admitidas y los modelos de aprendizaje automático, consulte Interpretación de modelos en Azure Machine Learning y Cuadernos de ejemplo.
Para instrucciones sobre cómo habilitar la interpretación de modelos entrenados con aprendizaje automático automatizado, consulte Interpretabilidad: explicaciones de modelos de aprendizaje automático automatizado (versión preliminar).
Generación del valor de importancia de la característica en el equipo personal
En el siguiente ejemplo se muestra cómo usar el paquete de interpretación en el equipo personal sin ponerse en contacto con los servicios de Azure.
Instale el paquete
azureml-interpret.pip install azureml-interpretEntrene un modelo de muestra en una instancia local de Jupyter Notebook.
# load breast cancer dataset, a well-known small dataset that comes with scikit-learn from sklearn.datasets import load_breast_cancer from sklearn import svm from sklearn.model_selection import train_test_split breast_cancer_data = load_breast_cancer() classes = breast_cancer_data.target_names.tolist() # split data into train and test from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(breast_cancer_data.data, breast_cancer_data.target, test_size=0.2, random_state=0) clf = svm.SVC(gamma=0.001, C=100., probability=True) model = clf.fit(x_train, y_train)Llame al explicador localmente:
- Para inicializar un objeto de explicación, pase el modelo y algunos datos de entrenamiento al constructor de la explicación.
- Para que las explicaciones y visualizaciones sean más informativas, puede optar por pasar los nombres de las características y los nombres de las clases de salida si está realizando la clasificación.
Los siguientes bloques de código muestran cómo crear localmente una instancia de un objeto explicador con
TabularExplainer,MimicExplaineryPFIExplainer.TabularExplainerllama a uno de los tres explicadores de SHA situados debajo (TreeExplainer,DeepExplaineroKernelExplainer).TabularExplainerselecciona automáticamente el más adecuado para su caso de uso, pero puede llamar a cada uno de los tres explicadores subyacentes directamente.
from interpret.ext.blackbox import TabularExplainer # "features" and "classes" fields are optional explainer = TabularExplainer(model, x_train, features=breast_cancer_data.feature_names, classes=classes)or
from interpret.ext.blackbox import MimicExplainer # you can use one of the following four interpretable models as a global surrogate to the black box model from interpret.ext.glassbox import LGBMExplainableModel from interpret.ext.glassbox import LinearExplainableModel from interpret.ext.glassbox import SGDExplainableModel from interpret.ext.glassbox import DecisionTreeExplainableModel # "features" and "classes" fields are optional # augment_data is optional and if true, oversamples the initialization examples to improve surrogate model accuracy to fit original model. Useful for high-dimensional data where the number of rows is less than the number of columns. # max_num_of_augmentations is optional and defines max number of times we can increase the input data size. # LGBMExplainableModel can be replaced with LinearExplainableModel, SGDExplainableModel, or DecisionTreeExplainableModel explainer = MimicExplainer(model, x_train, LGBMExplainableModel, augment_data=True, max_num_of_augmentations=10, features=breast_cancer_data.feature_names, classes=classes)or
from interpret.ext.blackbox import PFIExplainer # "features" and "classes" fields are optional explainer = PFIExplainer(model, features=breast_cancer_data.feature_names, classes=classes)
Explicación del comportamiento completo del modelo (explicación global)
Consulte el ejemplo siguiente para ayudarle a obtener los valores agregados de importancia de la característica (global).
# you can use the training data or the test data here, but test data would allow you to use Explanation Exploration
global_explanation = explainer.explain_global(x_test)
# if you used the PFIExplainer in the previous step, use the next line of code instead
# global_explanation = explainer.explain_global(x_train, true_labels=y_train)
# sorted feature importance values and feature names
sorted_global_importance_values = global_explanation.get_ranked_global_values()
sorted_global_importance_names = global_explanation.get_ranked_global_names()
dict(zip(sorted_global_importance_names, sorted_global_importance_values))
# alternatively, you can print out a dictionary that holds the top K feature names and values
global_explanation.get_feature_importance_dict()
Explicación de una predicción individual (explicación local)
Obtenga los valores individuales de importancia de la característica de distintos puntos de datos mediante llamadas a explicaciones para una instancia individual o un grupo de instancias.
Nota:
PFIExplainer no admite explicaciones locales.
# get explanation for the first data point in the test set
local_explanation = explainer.explain_local(x_test[0:5])
# sorted feature importance values and feature names
sorted_local_importance_names = local_explanation.get_ranked_local_names()
sorted_local_importance_values = local_explanation.get_ranked_local_values()
Transformaciones de características sin procesar
Puede optar por obtener explicaciones en términos de características sin procesar y sin transformar en lugar de características diseñadas. Para esta opción, se pasa la canalización de transformación de características al explicador en train_explain.py. De lo contrario, el explicador proporciona explicaciones en cuanto a las características diseñadas.
El formato de las transformaciones que se admiten es el mismo que se describe en sklearn-pandas. En general, se admiten todas las transformaciones, siempre que operen en una sola columna y, por tanto, sean claramente uno a varios.
Obtenga una explicación para las características sin procesar mediante sklearn.compose.ColumnTransformer o una lista de tuplas de transformadores apropiadas. En el ejemplo siguiente se utiliza sklearn.compose.ColumnTransformer.
from sklearn.compose import ColumnTransformer
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('onehot', OneHotEncoder(handle_unknown='ignore'))])
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)])
# append classifier to preprocessing pipeline.
# now we have a full prediction pipeline.
clf = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', LogisticRegression(solver='lbfgs'))])
# clf.steps[-1][1] returns the trained classification model
# pass transformation as an input to create the explanation object
# "features" and "classes" fields are optional
tabular_explainer = TabularExplainer(clf.steps[-1][1],
initialization_examples=x_train,
features=dataset_feature_names,
classes=dataset_classes,
transformations=preprocessor)
Si desea ejecutar el ejemplo con la lista de tuplas de transformadores apropiadas, use el siguiente código:
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.linear_model import LogisticRegression
from sklearn_pandas import DataFrameMapper
# assume that we have created two arrays, numerical and categorical, which holds the numerical and categorical feature names
numeric_transformations = [([f], Pipeline(steps=[('imputer', SimpleImputer(
strategy='median')), ('scaler', StandardScaler())])) for f in numerical]
categorical_transformations = [([f], OneHotEncoder(
handle_unknown='ignore', sparse=False)) for f in categorical]
transformations = numeric_transformations + categorical_transformations
# append model to preprocessing pipeline.
# now we have a full prediction pipeline.
clf = Pipeline(steps=[('preprocessor', DataFrameMapper(transformations)),
('classifier', LogisticRegression(solver='lbfgs'))])
# clf.steps[-1][1] returns the trained classification model
# pass transformation as an input to create the explanation object
# "features" and "classes" fields are optional
tabular_explainer = TabularExplainer(clf.steps[-1][1],
initialization_examples=x_train,
features=dataset_feature_names,
classes=dataset_classes,
transformations=transformations)
Generación de valores de importancia de características mediante ejecuciones remotas
En el ejemplo siguiente se muestra cómo usar la clase ExplanationClient para habilitar la interpretación del modelo para ejecuciones remotas. Es similar conceptualmente al proceso local, excepto que el usuario:
- Usa
ExplanationClienten la ejecución remota para cargar el contexto de interpretación. - Descarga el contexto más adelante en un entorno local.
Instale el paquete
azureml-interpret.pip install azureml-interpretCree un script de entrenamiento en una instancia local de Jupyter Notebook. Por ejemplo,
train_explain.py.from azureml.interpret import ExplanationClient from azureml.core.run import Run from interpret.ext.blackbox import TabularExplainer run = Run.get_context() client = ExplanationClient.from_run(run) # write code to get and split your data into train and test sets here # write code to train your model here # explain predictions on your local machine # "features" and "classes" fields are optional explainer = TabularExplainer(model, x_train, features=feature_names, classes=classes) # explain overall model predictions (global explanation) global_explanation = explainer.explain_global(x_test) # uploading global model explanation data for storage or visualization in webUX # the explanation can then be downloaded on any compute # multiple explanations can be uploaded client.upload_model_explanation(global_explanation, comment='global explanation: all features') # or you can only upload the explanation object with the top k feature info #client.upload_model_explanation(global_explanation, top_k=2, comment='global explanation: Only top 2 features')Configure una instancia de Azure Machine Learning Compute como destino de proceso y envíe la ejecución de entrenamiento. Consulte el artículo sobre cómo crear y administrar clústeres de proceso de Azure Machine Learning para obtener instrucciones. También puede encontrar útil los cuadernos de ejemplo.
Descargue la explicación en la instancia local de Jupyter Notebook.
from azureml.interpret import ExplanationClient client = ExplanationClient.from_run(run) # get model explanation data explanation = client.download_model_explanation() # or only get the top k (e.g., 4) most important features with their importance values explanation = client.download_model_explanation(top_k=4) global_importance_values = explanation.get_ranked_global_values() global_importance_names = explanation.get_ranked_global_names() print('global importance values: {}'.format(global_importance_values)) print('global importance names: {}'.format(global_importance_names))
Visualizaciones
Después de descargar las explicaciones en la instancia local de Jupyter Notebook, podrá usar las visualizaciones del panel de explicaciones para entender e interpretar el modelo. Para cargar el widget de panel de explicaciones en el cuaderno de Jupyter Notebook, use el siguiente código:
from raiwidgets import ExplanationDashboard
ExplanationDashboard(global_explanation, model, datasetX=x_test)
Las visualizaciones admiten explicaciones tanto en características diseñadas como en características sin procesar. Las explicaciones sin procesar se basan en las características del conjunto de datos original y las explicaciones diseñadas se basan en las características del conjunto de datos una vez aplicada la ingeniería de características.
Al intentar interpretar un modelo con relación al conjunto de datos original, se recomienda usar explicaciones sin procesar, ya que la importancia de cada característica se corresponderá con una columna del conjunto de datos original. Un escenario en el que las explicaciones diseñadas pueden ser útiles es al examinar el impacto de cada categoría de una característica categórica. Si se aplica la codificación de tipo "uno activo" a una característica categórica, las explicaciones resultantes que se diseñen incluirán un valor de importancia diferente para cada categoría, uno por cada característica diseñada con codificación de "uno activo". Esta codificación puede ser útil para identificar qué parte del conjunto de datos es más informativa para el modelo.
Nota
Las explicaciones diseñadas y las explicaciones sin procesar se procesan de forma secuencial. En primer lugar, se crea una explicación diseñada basada en el modelo y en la canalización de ingeniería de características. A continuación, se crea la explicación sin procesar basada en esa explicación diseñada, agregando la importancia de las características diseñadas que procedían de la misma característica sin procesar.
Creación, edición y visualización de cohortes del conjunto de datos
La cinta de opciones superior muestra las estadísticas generales del modelo y los datos. Puede segmentar y desglosar los datos en cohortes de conjuntos de datos, o subgrupos, para investigar o comparar el rendimiento y las explicaciones del modelo en estos subgrupos definidos. La comparación de las estadísticas y explicaciones del conjunto datos en esos subgrupos permite hacerse una idea de por qué se producen errores en un grupo y no en otro.

Descripción del comportamiento completo del modelo (explicación global)
Las tres primeras pestañas del panel de explicaciones proporcionan un análisis general del modelo entrenado junto con sus predicciones y explicaciones.
Rendimiento del modelo
Para evaluar el rendimiento del modelo, examine la distribución de los valores de predicción y los valores de las métricas de rendimiento del modelo. Para seguir investigando el modelo, consulte un análisis comparativo de su rendimiento en las diferentes cohortes o subgrupos del conjunto de datos. Seleccione los filtros situados junto a los valores Y y X para ver las distintas dimensiones. Consulte distintas métricas: precisión, recuperación, tasa de falsos positivos (FPR) y tasa de falsos negativos (FNR).

Explorador del conjunto de datos
Para explorar las estadísticas del conjunto de datos, seleccione distintos filtros en los ejes X, Y y de color para segmentar los datos por las diferentes dimensiones. Cree las cohortes del conjunto de datos anterior para analizar las estadísticas del mismo con filtros tales como los resultados previstos, las características del conjunto de datos y los grupos de errores. Use el icono de engranaje de la esquina superior derecha del grafo para cambiar el tipo de grafo.

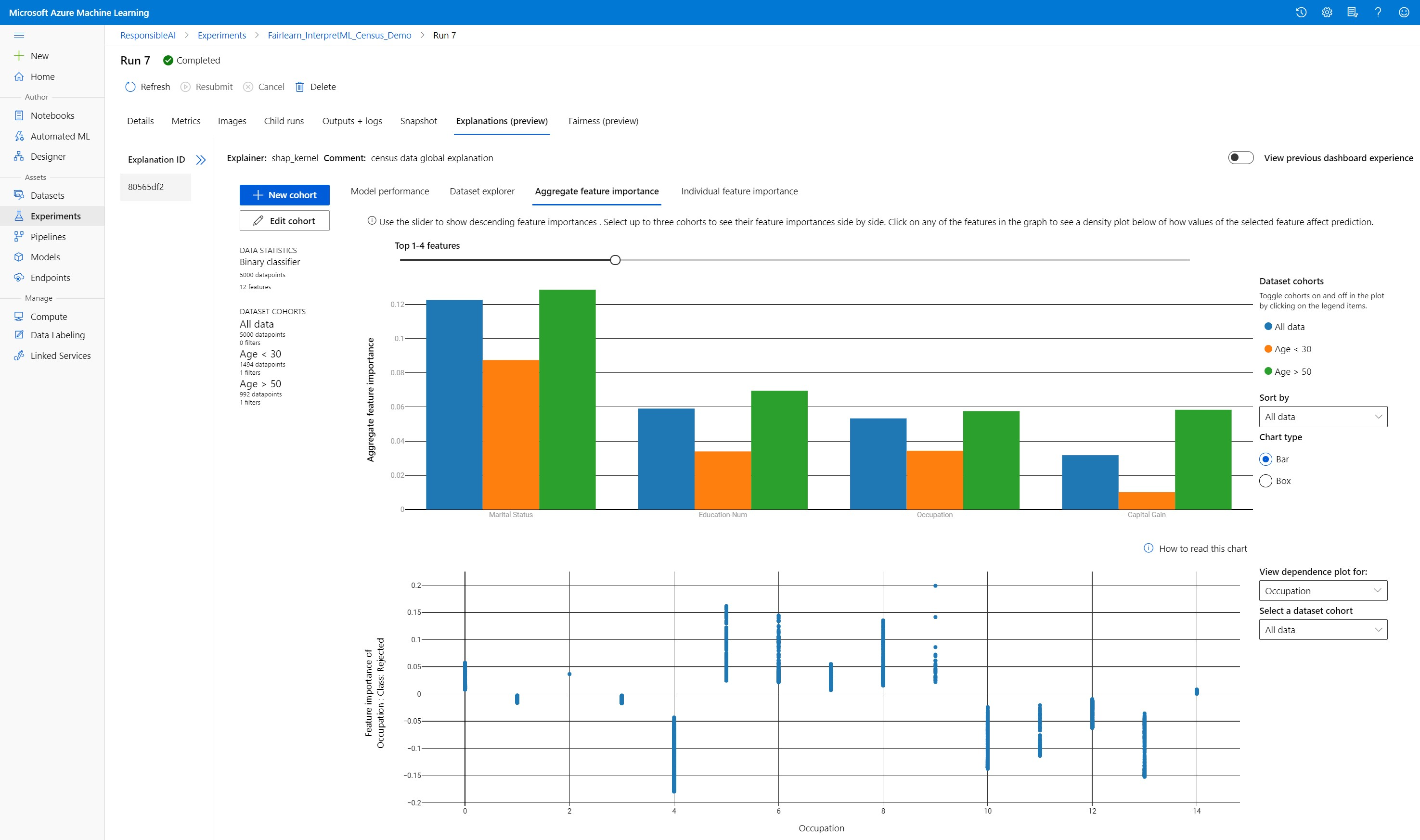
Agregación de la importancia de la característica
Explore las k características más importantes que afectan a las predicciones generales del modelo (lo que también se conoce como explicación global). Use el control deslizante para mostrar los valores de importancia de la característica en orden descendente. Seleccione tres cohortes como máximo para ver los valores de importancia de la característica en paralelo. En el trazado de dependencias siguiente, seleccione cualquiera de las barras de características del grafo para ver cómo afectan los valores de la característica seleccionada a la predicción del modelo.

Descripción de predicciones individuales (explicación local)
La cuarta pestaña de la pestaña de la explicación le permite profundizar en un punto de datos individual y en la importancia de sus características individuales. Para cargar el gráfico de un punto de datos de importancia de una característica individual, haga clic en cualquiera de los puntos de datos individuales del gráfico de dispersión principal, o seleccione un punto de datos específico en el asistente del panel, a la derecha.
| Gráfico | Descripción |
|---|---|
| Importancia de una característica individual | Muestra las k características más importantes de una predicción individual. Ayuda a mostrar el comportamiento local del modelo subyacente en un punto de datos concreto. |
| Análisis de hipótesis | Permite realizar cambios en los valores de la característica del punto de datos real seleccionado y observar los cambios resultantes en el valor de predicción; para ello, se genera un punto de datos hipotético con los nuevos valores de la característica. |
| Expectativa condicional individual (ICE) | Permite que el valor de la característica cambie de un valor mínimo a uno máximo. Ayuda a mostrar cómo cambia la predicción del punto de datos cuando se modifica una característica. |

Nota
Estas son explicaciones basadas en muchas aproximaciones y no son la "causa" de las predicciones. Sin la solidez matemática estricta de la inferencia causal, se aconseja a los usuarios que no tomen decisiones reales basándose en las perturbaciones de la característica de la herramienta de hipótesis. Esta herramienta se usa principalmente para comprender el modelo y con fines de depuración.
Visualización en Azure Machine Learning Studio
Si completa los pasos de la interpretación remota (mediante la carga de las explicaciones generadas en el historial de ejecución de Azure Machine Learning), verá las visualizaciones en el panel de explicaciones de Azure Machine Learning Studio. Este panel es una versión más sencilla del widget de panel que se genera en el cuaderno de Jupyter Notebook. La generación de puntos de datos de hipótesis y los gráficos ICE están deshabilitados porque no hay ningún proceso activo en el Estudio de Azure Machine Learning que pueda realizar sus cálculos en tiempo real.
Si el conjunto de datos y las explicaciones globales y locales están disponibles, los datos rellenan todas las pestañas. Sin embargo, si solo hay una explicación global disponible, se deshabilitará la pestaña de importancia de la característica individual.
Siga una de estas rutas de acceso para llegar al panel de explicaciones de Azure Machine Learning Studio:
Panel Experiments (Experimentos) (versión preliminar)
- Al hacer clic en Experimentos en el panel izquierdo, verá una lista de experimentos que se han ejecutado en Azure Machine Learning.
- Seleccione un experimento determinado para ver todas las ejecuciones de ese experimento.
- Seleccione una ejecución y, después, la pestaña Explanations (Explicaciones) para ver el panel de visualización de explicaciones.
Panel Models (Modelos)
- Si registró el modelo original siguiendo los pasos descritos en Implementación de modelos con Azure Machine Learning, puede seleccionar Models (Modelos) en el panel izquierdo para verlo.
- Seleccione un modelo y la pestaña Explicaciones para ver el panel de explicaciones.

Interpretación en tiempo de inferencia
Puede implementar el explicador junto con el modelo original y usarlo en el momento de la inferencia para proporcionar los valores de importancia de las características individuales (explicación local) para cualquier punto de datos nuevo. También ofrecemos explicadores de puntuación más ligeros para mejorar el rendimiento de la interpretación en el momento de la inferencia, lo cual solo se admite actualmente en el SDK de Azure Machine Learning. El proceso de implementación de una explicación de puntuación ligera es similar al de implementación de un modelo e incluye los siguientes pasos:
Cree un objeto de explicación. Por ejemplo, puede usar
TabularExplainer:from interpret.ext.blackbox import TabularExplainer explainer = TabularExplainer(model, initialization_examples=x_train, features=dataset_feature_names, classes=dataset_classes, transformations=transformations)Cree un explicador de puntuación mediante el objeto de explicación:
from azureml.interpret.scoring.scoring_explainer import KernelScoringExplainer, save # create a lightweight explainer at scoring time scoring_explainer = KernelScoringExplainer(explainer) # pickle scoring explainer # pickle scoring explainer locally OUTPUT_DIR = 'my_directory' save(scoring_explainer, directory=OUTPUT_DIR, exist_ok=True)Configure y registre una imagen que utilice al modelo de explicación de puntuación.
# register explainer model using the path from ScoringExplainer.save - could be done on remote compute # scoring_explainer.pkl is the filename on disk, while my_scoring_explainer.pkl will be the filename in cloud storage run.upload_file('my_scoring_explainer.pkl', os.path.join(OUTPUT_DIR, 'scoring_explainer.pkl')) scoring_explainer_model = run.register_model(model_name='my_scoring_explainer', model_path='my_scoring_explainer.pkl') print(scoring_explainer_model.name, scoring_explainer_model.id, scoring_explainer_model.version, sep = '\t')Como un paso opcional, puede recuperar el explicador de puntuación en la nube y probar las explicaciones.
from azureml.interpret.scoring.scoring_explainer import load # retrieve the scoring explainer model from cloud" scoring_explainer_model = Model(ws, 'my_scoring_explainer') scoring_explainer_model_path = scoring_explainer_model.download(target_dir=os.getcwd(), exist_ok=True) # load scoring explainer from disk scoring_explainer = load(scoring_explainer_model_path) # test scoring explainer locally preds = scoring_explainer.explain(x_test) print(preds)Implemente la imagen en un destino de proceso, para lo que debe seguir estos pasos:
Si lo necesita, registre el modelo de predicción original; para ello, siga los pasos de Implementación de modelos con Azure Machine Learning.
Cree un archivo de puntuación.
%%writefile score.py import json import numpy as np import pandas as pd import os import pickle from sklearn.externals import joblib from sklearn.linear_model import LogisticRegression from azureml.core.model import Model def init(): global original_model global scoring_model # retrieve the path to the model file using the model name # assume original model is named original_prediction_model original_model_path = Model.get_model_path('original_prediction_model') scoring_explainer_path = Model.get_model_path('my_scoring_explainer') original_model = joblib.load(original_model_path) scoring_explainer = joblib.load(scoring_explainer_path) def run(raw_data): # get predictions and explanations for each data point data = pd.read_json(raw_data) # make prediction predictions = original_model.predict(data) # retrieve model explanations local_importance_values = scoring_explainer.explain(data) # you can return any data type as long as it is JSON-serializable return {'predictions': predictions.tolist(), 'local_importance_values': local_importance_values}Defina la configuración de la implementación.
Esta configuración depende de los requisitos del modelo. En el ejemplo siguiente se define una configuración que usa un núcleo de CPU y 1 GB de memoria.
from azureml.core.webservice import AciWebservice aciconfig = AciWebservice.deploy_configuration(cpu_cores=1, memory_gb=1, tags={"data": "NAME_OF_THE_DATASET", "method" : "local_explanation"}, description='Get local explanations for NAME_OF_THE_PROBLEM')Cree un archivo con las dependencias del entorno.
from azureml.core.conda_dependencies import CondaDependencies # WARNING: to install this, g++ needs to be available on the Docker image and is not by default (look at the next cell) azureml_pip_packages = ['azureml-defaults', 'azureml-core', 'azureml-telemetry', 'azureml-interpret'] # specify CondaDependencies obj myenv = CondaDependencies.create(conda_packages=['scikit-learn', 'pandas'], pip_packages=['sklearn-pandas'] + azureml_pip_packages, pin_sdk_version=False) with open("myenv.yml","w") as f: f.write(myenv.serialize_to_string()) with open("myenv.yml","r") as f: print(f.read())Cree un dockerfile personalizado con g++ instalado.
%%writefile dockerfile RUN apt-get update && apt-get install -y g++Implemente la imagen creada.
Este proceso tarda unos cinco minutos.
from azureml.core.webservice import Webservice from azureml.core.image import ContainerImage # use the custom scoring, docker, and conda files we created above image_config = ContainerImage.image_configuration(execution_script="score.py", docker_file="dockerfile", runtime="python", conda_file="myenv.yml") # use configs and models generated above service = Webservice.deploy_from_model(workspace=ws, name='model-scoring-service', deployment_config=aciconfig, models=[scoring_explainer_model, original_model], image_config=image_config) service.wait_for_deployment(show_output=True)
Pruebe la implementación.
import requests # create data to test service with examples = x_list[:4] input_data = examples.to_json() headers = {'Content-Type':'application/json'} # send request to service resp = requests.post(service.scoring_uri, input_data, headers=headers) print("POST to url", service.scoring_uri) # can covert back to Python objects from json string if desired print("prediction:", resp.text)Limpiar.
Para eliminar un servicio web implementado, use
service.delete().
Solución de problemas
No se admiten los datos dispersos: el panel de explicación del modelo se bloquea o ralentiza mucho si hay un gran número de características, por lo que actualmente no se admite el formato de datos dispersos. Además, se producirán problemas de memoria generales cuando haya grandes conjuntos de datos y un gran número de características.
Matriz de características de explicaciones admitidas
| Pestaña Explicación admitida | Características sin procesar (densas) | Características sin procesar (dispersas) | Características diseñadas (densas) | Características diseñadas (dispersas) |
|---|---|---|---|---|
| Rendimiento del modelo | Compatible (sin previsión) | Compatible (sin previsión) | Compatible | Compatible |
| Explorador del conjunto de datos | Compatible (sin previsión) | No compatible. Puesto que los datos dispersos no se cargan y la interfaz de usuario tiene problemas para representar datos dispersos. | Compatible | No compatible. Puesto que los datos dispersos no se cargan y la interfaz de usuario tiene problemas para representar datos dispersos. |
| Agregación de la importancia de la característica | Compatible. | Admitido | Admitido | Compatible |
| Importancia de una característica individual | Compatible (sin previsión) | No compatible. Puesto que los datos dispersos no se cargan y la interfaz de usuario tiene problemas para representar datos dispersos. | Compatible | No compatible. Puesto que los datos dispersos no se cargan y la interfaz de usuario tiene problemas para representar datos dispersos. |
Los modelos de previsión no son compatibles con las explicaciones del modelo: la interpretabilidad y una mejor explicación del modelo no están disponibles para los experimentos de previsión de AutoML que recomiendan los siguientes algoritmos como el mejor modelo: TCNForecaster, AutoArima, Prophet, ExponentialSmoothing, Average, Naive, Seasonal Average y Seasonal Naive. Los modelos de regresión de previsión de AutoML admiten explicaciones. Sin embargo, en el panel de la explicación, no se admite la pestaña de "importancia de la característica individual" para la previsión debido a la complejidad de sus canalizaciones de datos.
Explicación local para el índice de datos: el panel de explicación no permite relacionar los valores de importancia locales con un identificador de fila del conjunto de datos de validación original si ese conjunto de datos supera los 5000 puntos de datos, ya que el panel reduce aleatoriamente los datos. Sin embargo, en el panel se muestran los valores de las características de los conjuntos de datos sin procesar de cada punto de datos que se pasa al panel, en la pestaña de importancia de la característica individual. Para asignar las importancias locales de nuevo al conjunto de datos original, los usuarios pueden establecer la correspondencia con los valores de las características del conjunto de datos sin procesar. Si el tamaño del conjunto de datos de validación tiene menos de 5000 muestras, la característica
indexde Azure Machine Learning Studio se corresponderá con el índice del conjunto de datos de validación.Los trazados hipotéticos y de ICE no son compatibles con Studio: no se admiten los trazados de hipótesis y de Expectativas condicionales individuales (ICE) en el Estudio de Azure Machine Learning en la pestaña de explicaciones, ya que la explicación cargada necesita un proceso activo para recalcular las predicciones y las probabilidades de las características perturbadas. Actualmente se admite en los cuadernos de Jupyter Notebook cuando se ejecuta como un widget con el SDK.
Pasos siguientes
Técnicas para la interpretación de modelos en Azure Machine Learning
Consulta de los cuadernos de ejemplos de interpretación de Azure Machine Learning